Матрицу парных коэффициентов корреляции переменных можно рассчитать, используя инструмент анализа данных Корреляция. Для этого:
1) в главном меню выберите Сервис/Анализ данных/Корреляция; щелкните по кнопке ОК;
2) заполните диалоговое окно ввода данных и параметров вывода:
Входной интервал – введите $B$1:$D$21;
Группирование – поставьте флажок по столбцам;
Метки – поставьте флажок;
Выходной интервал – введите $F$17;
Щелкните по кнопке ОК.
Результаты вычислений – матрица коэффициентов парной корреляции:
| y | x1 | x2 | |
| y | 1,000 | ||
| x1 | 0,970 | 1,000 | |
| x2 | 0,941 | 0,943 | 1,000 |
Линейные коэффициенты частной корреляции оценивают тесноту связи значений двух переменных, исключая влияние всех других переменных, представленных в уравнении множественной регрессии.
К сожалению, в ППП Excel нет специального инструмента для расчета линейных коэффициентов частной корреляции. Используя математические функции Excel и значения парных коэффициентов корреляции, рассчитайте частные коэффициенты корреляции:



Значения коэффициентов парной корреляции указывают на весьма тесную связь выработки продукции y как с коэффициентом обновления основных фондов - x1, так и с долей рабочих высокой квалификации – x2 (ryx1=0,970 и ryx2=0,941). Но в то же время межфакторная связь rx1x2=0,943 весьма тесная и превышает тесноту связи x2 с y. В связи с этим для улучшения данной модели можно исключить из нее фактор x2 как малоинформативный, недостаточно статистически надежный.
Коэффициенты частной корреляции дают более точную характеристику тесноты связи двух признаков, чем коэффициенты парной корреляции, так как очищают парную зависимость от взаимодействия данной пары признаков с другими признаками, представленными в модели. Наиболее тесно связаны y и x1: ryx1. x2=0,734,связь y и x2 гораздо слабее: ryx2. x1=0,325, а межфакторная зависимость x1 и x2 выше, чем парная y и x2: ryx2. x1=0,325< rx1x2. y=0,368. Все это приводит к выводу о необходимости исключить фактор x2 – доля высококвалифицированных рабочих – из правой части уравнения множественной регрессии.
Если сравнить коэффициенты парной и частной корреляции, то можно увидеть, что из-за высокой межфакторной зависимости коэффициенты парной корреляции дают завышенные оценки тесноты связи:
ryx1=0,970, ryx1. x2=0,734; ryx2=0,941, ryx2. x1=0,325.
Именно по этой причине рекомендуется при наличии сильной коллинеарности (взаимосвязи) факторов исключать из исследования тот фактор, у которой теснота парной зависимости меньше, чем теснота межфакторной связи.
3. Написать уравнение множественной регрессии, оценить его параметров, пояснить их экономический смысл.
Вычисление параметров линейного уравнения множественной регрессии проводится с помощью инструмента анализа данных Регрессия. Порядок действий следующий:
1) проверьте доступ к пакету анализа. В главном меню последовательно выберите Сервис/Надстройки. Установите флажок Пакет анализа;
2) в главном меню выберите Сервис/Анализ данных/Регрессия. Щелкните по кнопке ОК.
3) заполните диалоговое окно ввода данных и параметров вывода:
Входной интервал Y – диапазон, содержащий данные результативного признака. Введите $B$1:$B$21;
Входной интервал X - диапазон, содержащий данные факторов независимого признака. Введите $C$1:$D$21;
Метки – флажок, который указывает, содержит ли первая строка названия столбцов или нет. Поставьте флажок;
Константа - ноль – флажок, указывающий на наличие или отсутствие свободного члена в уравнении;
Выходной интервал – достаточно указать левую верхнюю ячейку будущего диапазона;
Новый рабочий лист – можно задать произвольное имя нового рабочего листа. Поставьте флажок Новый рабочий лист.
Если необходимо получить информацию и графики остатков, установите соответствующие флажки в диалоговом окне. Щелкните по кнопке ОК.
Используя, инструмент Регрессия, получите следующий результат:
| ВЫВОД ИТОГОВ | ||||||||
| Регрессионная статистика | ||||||||
| Множественный R | 0,9731012 | |||||||
| R-квадрат | 0,9469259 | |||||||
| Нормированный R-квадрат | 0,9406819 | |||||||
| Стандартная ошибка | 0,5986704 | |||||||
| Наблюдения | ||||||||
| Дисперсионный анализ | ||||||||
| df | SS | MS | F | Значимость F | ||||
| Регрессия | 108,70709 | 54,353547 | 151,65348 | 1,45045E-11 | ||||
| Остаток | 6,0929055 | 0,3584062 | ||||||
| Итого | 114,8 | |||||||
| Коэффициенты | Стандартная ошибка | t-статистика | P-Значение | Нижние 95% | Верхние 95% | Нижние 95,0% | Верхние 95,0% | |
| Y-пересечение | 1,8353069 | 0,471065 | 3,8960801 | 0,0011615 | 0,841445283 | 2,8291686 | 0,8414453 | 2,8291686 |
| x1 | 0,9459477 | 0,2125765 | 4,449917 | 0,0003515 | 0,497449913 | 1,3944455 | 0,4974499 | 1,3944455 |
| x2 | 0,0856178 | 0,0604833 | 1,4155606 | 0,1749637 | -0,041991018 | 0,2132266 | -0,041991 | 0,2132266 |
| ВЫВОД ОСТАТКА | ||
| Наблюдение | Предсказанное y | Остатки |
| 6,3806809 | 0,6193191 | |
| 6,7231521 | 0,2768479 | |
| 6,6195803 | 0,3804197 | |
| 6,9889824 | 0,0110176 | |
| 6,8854107 | 0,1145893 | |
| 8,002594 | -1,002594 | |
| 8,5701626 | -0,5701626 | |
| 7,7098327 | 0,2901673 | |
| 8,5611856 | -0,5611856 | |
| 9,9801072 | 0,0198928 | |
| 9,3089668 | -0,3089668 | |
| 9,7729637 | 1,2270363 | |
| 10,151343 | -1,1513428 | |
| 10,786575 | 0,2134248 | |
| 11,800187 | 0,1998132 | |
| 12,074994 | -0,0749941 | |
| 12,066017 | -0,0660171 | |
| 12,530014 | -0,530014 | |
| 13,656174 | 0,3438257 | |
| 13,431077 | 0,5689232 |

По результатам вычислений составим уравнение множественной регрессии вида: y=a+b1x2+b2x2;
y=1,8353+0,9459x1+0,0856x2.
Если значения t-критерия больше 2-3, можно сделать вывод о существенности данного параметра, который формируется под воздействием неслучайных величин. Здесь статистически значимыми являются a и b1, а величина b2 сформировалась под воздействием случайных причин, поэтому фактор x2, силу влияния которого оценивает b2, можно исключить как несущественно влияющий.
На это же указывает показатель вероятности случайных значений параметров регрессии (Р-значение, a): если он меньше принятого нами уровня (обычно 0,1; 0,05 или 0,01; это соответствует 10%; 5% или 1% вероятности), делают вывод о неслучайной природе данного значения параметра, т.е. о том, что он статистически значим и надежен. Здесь Рx2=17,5%>5%, что позволяет рассматривать x2 как неинформативный фактор и удалить его для улучшения данного уравнения.
4. С помощью F-критерия Фишера оценить статистическую надежность уравнения регрессии и R2yx1x2. Сравнить значения скорректированного и нескорректированного линейных коэффициентов множественной детерминации.
По данным таблиц дисперсионного анализа Fфакт = 151,65. Вероятность случайно получить такое значение F- критерия составляет 0,0000 (1,45045Е-11), что не превышает допустимый уровень значимости 5%; об этом свидетельствует величина Р- значения. Следовательно, полученное значение не случайно, оно сформировалось под влиянием существенных факторов, т.е. подтверждается статистическая значимость всего уравнения и показателя тесноты связи R2 yx1x2.
Нескорректированный (нормированный) коэффициент множественной детерминации R2yx1x2=0,9469 оценивает долю вариации результата за счет представленных в уравнении факторов в общей вариации результата. Здесь эта доля составляет 94,7% и указывает на весьма тесную связь факторов с результатом.
Скорректированный коэффициент множественной детерминации R2yx1x2=0,9407 определяет тесноту связи с учетом степеней свободы общей и остаточной дисперсий. Он дает такую оценку тесноты связи, которая не зависит от числа факторов в модели и потому может сравниваться по разным моделям с разным числом факторов. Оба коэффициента указывают на весьма высокую (более 90%) детерминированность результата у в модели факторами х1 и х2.
5. С помощью частных F-критериев Фишера оценить целесообразность включения в уравнение множественной регрессии фактора x1 после x2 и фактора x2 после x1.
Рассчитать частные F-критерии Фишера можно используя формулы:
Fчастн x1=(tb1)2; Fчастн x2=(tb2)2.
Fчастн х2=2, что меньше Fтабл. Следовательно, включение в модель фактора х2- доля высококвалифицированных рабочих – после того, как в уравнение включен фактор х1- коэффициент обновления основных фондов – статистически нецелесообразно: прирост факторной дисперсии за счет дополнительного признака оказывается незначительным, несущественным; фактор х2 включать в уравнение после фактора х1 не следует.
Если поменять первоначальный порядок включения факторов в модель и рассмотреть вариант включения х1 после х2,то результат расчета частного F-критерия для х1 будет иным. Fчастн.х1= 19,80 что превышает Fтабл.. Следовательно, значение частного F- критерия для дополнительно включенного фактора х1 не случайно, является статистически значимым, надежным, достоверным: прирост факторной дисперсии за счет дополнительного фактора х1 является существенным. Фактор х1 должен присутствовать в уравнении, в том числе в варианте, когда он дополнительно включается после фактора х2.
Общий вывод состоит в том, что множественная модель с факторами х1 и х2 с R2 yx1x2=0,9469 содержит неинформативный фактор х2. Если исключить фактор х2, то можно ограничиться уравнением парной регрессии:
y=a0+a1x1=1,99+1,23x1, r2yx=0,9407.
более простым, хорошо детерминированным, пригодным для анализа и прогноза.
6. Рассчитать средние частные коэффициенты эластичности и дать на их основе сравнительную оценку силы влияния факторов на результат.
 Средние частные коэффициенты эластичности
Средние частные коэффициенты эластичности  показывают, на сколько процентов от значения своей средней изменяется результат при изменении фактора хi на 1% от своей средней и при фиксированном воздействии на y всех прочих факторов, включенных в уравнение регрессии. Для линейной зависимости
показывают, на сколько процентов от значения своей средней изменяется результат при изменении фактора хi на 1% от своей средней и при фиксированном воздействии на y всех прочих факторов, включенных в уравнение регрессии. Для линейной зависимости  где
где
bj=коэффициент регрессии при хjв уравнении множественной регрессии.
Здесь 
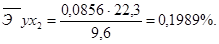
По значениям частных коэффициентов эластичности можно сделать вывод о более сильном влиянии на результат фактора х1,чем признака фактора х2: 0,6% против 0,2%.