Лекция 2. Понятие об имитационном моделировании
В процессе имитационного моделирования (ИМ) создается модель или устройство (имитатор), позволяющие получать информацию о сложных объектах без непосредственного контакта с ними. Естественно, имитатор или модель должны в основных чертах воспроизводить поведение реальной системы.
ИМ является эффективным методом исследования реальных систем, позволяющим получить информацию о поведении экономических, технических, биологических и социальных систем с помощью их компьютерных моделей.
С помощью ИМ, как правило, нельзя получить единственное наилучшее (оптимальное) решение, но возможно определить удовлетворяющее нас решение на базе статистической обработки получаемых результатов.
ИМ широко применяется в экономике, технике, естественных науках и социологических исследованиях. ИМ позволяет решать:
Ø сложные производственно-технические задачи (моделирование процессов функционирования предприятия, объединения или отрасли, систем связи, управления запасами в условиях риска);
Ø экономические задачи (оценка спроса на продукцию, прогнозирование цен и сегментов рынка, формирование портфеля инвестиционных проектов в условиях риска);
Ø задачи социальной сферы (анализ динамики народонаселения, влияние экологии на здоровье, прогноз группового поведения и др.);
Ø задачи военной сферы – например, отработка взаимодействия подразделений в ходе боевых действий.
В процессе имитационного моделирования используются случайные выборки, в связи с чем результаты расчетов подвержены экспериментальным ошибкам и должны подвергаться статистической проверке.
В основе многих современных имитационных моделей лежит универсальный метод статистического моделирования Монте-Карло. В процессе его реализации оценки параметров изучаемых систем получаются
с помощью генерации случайных чисел.
ИМ оказывается практически единственным методом исследования сложных процессов и систем, в которых случайные факторы взаимосвязаны, а функциональные связи между параметрами очень сложны или неизвестны.
В литературе отмечается (см. например, [3]) ряд преимуществ ИМ над аналитическими моделями. Они определяются тем, что:
1. в аналитических моделях трудно учесть влияние плохо прогнозируемых факторов (случайный спрос и цена на товары, большое число элементов системы, сложный характер их взаимодействия и т.п.);
2. нестационарное поведение сложных систем плохо описывается аналитическими моделями;
3. в процессе реализации имитационных моделей можно использовать широкий круг программного обеспечения – от обычных электронных таблиц до специализированных программ и систем поддержки принятия решений.
Можно выделитьдва основных типа имитационных моделей - непрерывные, описывающие системы, свойства которых непрерывно меняются во времени, и дискретные, характеризующиеся тем, что изменения
в системе происходят в некоторые фиксированные моменты времени.
Имитация случайных событий и величин производится посредством генерации случайных чисел, равномерно распределенных на отрезке [0,1]. Генерация любого такого числа влечет за собой конкретную реализацию процесса. Используя равномерное распределение, можно получить ответы на следующие вопросы [10]:
Произошло ли событие A?
Пусть вероятность  события
события  известна. Откладывая на отрезке [0,1] отрезок длины и генерируя случайное число
известна. Откладывая на отрезке [0,1] отрезок длины и генерируя случайное число  , будем считать, что событие произошло, если
, будем считать, что событие произошло, если  , если же
, если же  то – нет (на рисунке изображен как раз такой случай, т.к.
то – нет (на рисунке изображен как раз такой случай, т.к.  ).
).

Какое из нескольких событий произошло?
Будем считать, что события  несовместны и образуют полную группу. В этом случае сумма их вероятностей равна единице. Разделим отрезок [0,1] на
несовместны и образуют полную группу. В этом случае сумма их вероятностей равна единице. Разделим отрезок [0,1] на  участков длины
участков длины  и будем считать, что произошло то из событий, на чей участок при данной имитации попало число .
и будем считать, что произошло то из событий, на чей участок при данной имитации попало число .

3. Какое значение приняла случайная величина 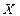 ?
?
Если дискретна, т.е. принимает возможные значения 
с вероятностями , то случай алгоритм полностью аналогичен описанному в предыдущем пункте.
Если же случайная величина непрерывна, для генерации ее значений можно перейти от ее плотности вероятности  к функции распределения
к функции распределения 

сгенерировать равномерно распределенное случайное число и найти значение  , которому соответствует
, которому соответствует 

4. Какую совокупность значений приняли случайные величины  ?
?
Для независимых случайных величин достаточно раз повторить процедуру, описанную в пункте 3. В случае их зависимости необходимо учитывать условный закон распределения каждой случайной величины.
При компьютерном моделировании используется алгоритм генерации псевдослучайных чисел; при “ручном” – таблицы случайных чисел.
Пример: моделирование объема спроса на ноутбуки. Менеджер небольшой фирмы, реализующей ноутбуки, желает оценить спрос на ноутбуки марки A в течение ближайших 15 дней. Отчетные данные за последние 100 дней приведены в первых двух столбцах таблицы 20.1.
Таблица 20.1
| Число продаж | Частота реализации | Вероятность реализации | Значение функции распределения | Интервал случайных чисел |
| 5/100 = 0,05 | 0,05 | От 1 до 5 | ||
| 10/100 = 0,1 | 0,15 | От 6 до 15 | ||
| 20/100 = 0,2 | 0,35 | От 16 до 35 | ||
| 30/100 = 0,3 | 0,65 | От 36 до 65 | ||
| 20/100 = 0,2 | 0,85 | От 66 до 85 | ||
| 15/100 = 0,15 | 1,00 | От 86 до 100 | ||
| ИТОГО | 1,00 |
Необходимо построить модель, имитирующую спрос.
Решение. Произведем имитацию спроса на машины в автосалоне в течение последующих 15 дней, используя генератор случайных чисел (второй столбец таблицы 20.2)
Таблица 20.2
| Номер дня | Случайное число | Имитируемый дневной спрос |
Таким образом, суммарный спрос за 10 дней составляет 39 автомобилей, средний ежедневный спрос – 39/10 = 3,9.
ИМ позволяет оценивать площади сложных фигур и – что еще более важно для практических приложений – многомерные интегралы. Точность соответствующих расчетов возрастает при увеличении числа генерируемых случайных точек.
С помощью генерации равномерно распределенных случайных чисел можно моделировать поведение систем, параметры которых описываются другими законами распределения (например, нормальным, показательным и т.д.).