МИНИСТЕРСТВО ОБРАЗОВАНИЯ РОССИЙСКОЙ ФЕДЕРАЦИИ
ЮЖНЫЙ ФЕДЕРАЛЬНЫЙ УНИВЕРСИТЕТ
ФАКУЛЬТЕТ ВЫСОКИХ ТЕХНОЛОГИЙ
Курсовая работа
Технологии корреляционно-регрессивного
анализа и их практическое
использование.
Выполнила: Богаченко К.С.
2 курс 5группа
Руководитель: Остроух Е.Н.
г. Ростов-на-Дону
Содержание
I. Теоретическая часть
1. Технологии корреляционно-регрессивного анализа……………………… 3
2. Этапы корреляционно-регрессивного анализа…………………………… 5
· Нулевой этап……………………………………………………….5
· Первый этап (Корреляционный анализ)…………………………5
· Второй этап ……………………………………………………......5
· Третий этап………………………………………………………..6
· Четвертый этап………………………………………………….....7
3. Основные методы поиска наилучшего решения………………………… 8
II. Практическая часть
1. Симплекс метод………………………………………………10
2. Транспортная задача…………………………………………14
I. Теоретическая часть
Технологии корреляционно-регрессивного анализа
Экономические данные почти всегда представлены в виде таблиц. Числовые данные в таблицах обычно имеют между собой явные (известные) или неявные (скрытые) связи.
Явно связаны показатели, которые получены методом прямого счёта, т.е. вычислены по заранее известным формулам. Например, проценты выполнения на уровне, удельные веса, отклонения в сумме, отклонения в процентах, темпы роста, темпы прироста, индексы и т.д. Связи второго типа заранее неизвестны, поэтому при помощи наблюдений стараются выявить скрытые зависимости и выразить их в виде формул, МС, математически смоделировать явления или процессы. Для этого служит корреляционно-регрессивный анализ.
Математические модели строим и используем для 3-х целей:
1. для объяснения;
2. для предсказания;
3. для управления.
Пользуясь методами корреляционно-регрессивного анализа, можно измерить густоту связей показателей с помощью коэффициента корреляции. При этом связи могут быть сильными, слабыми, умеренными, различными по направлению — прямые и обратные. Если связи существенны, то их математическое выражение изменяется в виде регрессивной модели с оценкой систематической значимости модели. Значимое уравнение используется для прогнозирования изучаемого явления или показателя.
Корреляционно-регрессивный анализ связи между переменными показателями как один набор переменных(Х), может влиять на другой набор (У).
Пример 1.
Методами, изучающими пути продвижения товаров и потери в пути, можно проверить предположение о том, что число консервных банок, испорченных при перевозке в вагонах, зависит от скорости вагонов при толчках. Это даёт возможность при перепроектировки упаковки и расфасовки товаров изменить способы доставки, и погасить естественную убыль. Собраны данные о скорости 13 вагонов (независимые переменные Х) и количество испорченных банок в каждом из них (зависимые переменные У). Если при обработке этих данных выявится сильная связь между Х и У, то необходимо будет построить её механическую модель для прогнозирования потерь при перевозке и нормировании товаров.
Пример 2.
Хиромантия утверждает, что данные «линии жизни» на левой ладони человека связана с продолжительностью его жизни. Методом прямого наблюдения собранны данные об истинном возрасте 50-ти умерших по данным «линии жизни», чтобы с помощью корреляционно-регрессивного анализа измерить силу связи и найти научное объяснение хиромантии.
Пример 3.
Управляющий операцией одной из фирм принял ряд решений по мероприятиям на стадионе с учётом вероятной их посещаемости – сколько в каждом случае нужно открыть киосков и сколько работников вызвать на работу. Оказалось, что одна из главных независимых переменных, которую можно встроить в прогнозируемую модель, типа множественной линейной регрессивной модели – это число билетов проданных на стадионе к моменту, когда до игры остаётся 24 часа.
Пример 4.
Замечено, что объём продаж, зависит от площади предприятия. Найти уравнение этой зависимости, чтобы по известной площади универмага (Х) можно было реализовать общие продажи в нём (У). Конечно, важно иметь данные о типе предприятия, т.к. связь может быть неодинакова для крупных и мелких предприятий.
Итак, такой подход используется в маркетинге, торговле, медицине. Получив знание о скрытых связях, можно улучшить аналитическую поддержку принятия решений и повысить их обоснованность. В маркетинге широко применяется, как однофакторные, так и множественные регрессивные модели. Корреляционно-регрессивный анализ – один из главных методов в маркетинге, наряду с расчётами, а также математическим и графическим моделированием трендов (тенденции).
Этапы корреляционно-регрессивного анализа
Нулевой этап.
Цель-- сбор данных. Данные должны быть наблюдаемы, т.е. получены в результате замера, а не расчёта. Наблюдение следует спланировать. Сколько необходимо данных для получения хорошего уравнения? Их должно быть в 4-6 раз больше, чем число факторов, влияние которых нужно выразить математически (по другим оценкам в 7-8 раз больше). Это обеспечит эффективное погашение случайных отклонений от закономерного характера связей признака.
Первый этап.
Корреляционный анализ.
Цель – определить характер связи (прямая, обратная) и силу связи (отсутствие связи; связь слабая, умеренная, сильная или малая). Характер и степень выраженности связей определяется коэффициентом корреляции, который используется для отбора существенных факторов, а также для планирования эффективности и последовательности расчёта параметра регрессивных уравнений. Присутствие одного фактора вычисляется коэффициентом корреляции, а при наличии нескольких факторов строится корреляционная матрица, из которой выявляется 2 вида связи:
1. связь зависимой переменной;
2. связь между независимыми переменными.
Выше выявленные факторы, действительно влияют на последующую зависимую переменную, и необходимо выбрать (ранжировать) их по убыванию связи; во-вторых, минимизировать число факторов модели, исключив часть факторов, которые функционально связаны с другими факторами (связь независимых переменных между собой).
Второй этап.
Это этап расчета параметра и построения регрессивных моделей. Он заключается в том, чтобы найти наиболее точную меру выявления связи. Эту меру обобщенно выражаем математической моделью множественной регрессивной зависимости:
у = а0 + в1+х1+х2*2+…вnхn
Величина У – отклик, Х1,Х2 …Хn –факторы, а0-const, В - коэффициент регрессии. На втором этапе корреляционно-регрессивного анализа после выбора коэффициентов, переход к третьему этапу — интеллектуальному, для которого почти все данные по оценке значимости уравнения подготавливает ЭВМ.
Третий этап.
На 3-ем этапе вычисляется величина (параметр) значимости, т.е. пригодность постулированной модели для анализа (разработки) в целях предсказания значений отклика. При этом программа рассчитывает по модели теоретическое значение для ранее наблюдаемых значений зависимой величины и вычисляет отклонение теоретических знаний от наблюдаемых значений. На основе этого программа строит ряд графиков, в том числе график подборки (он иллюстрирует насколько хорошо подобраны линии регрессии к наблюдаемым данным), график элементов.
В остатках не должно наблюдаться закономерности, т.е. коррекция с каким-либо значением на этом этапе исключительно важную роль играет коэффициент детерминации.
MF- критерий значимости регрессии. R Squared (R2)—коэффициент детерминации – квадрат множественности коэффициента корреляции между наблюдаемыми значениями. У и его теоретическое значение, вычисленное на основе модели с определённым набором факторов. Коэффициент детерминации измеряет действительность модели. Он может принимать значение от 0 до 1. Эта величина особенно полезна для сравнения ряда различных моделей и выбора наилучшей из них.
R2 – для вариации прогнозируемой (теоретической) величины у относительно наблюдаемых значений У1, объясненном за счёт включенных в модель факторов. Очень хорошо, если R2 ≥80%. Остальные для наблюдаемых значений У зависят от других, не участвовавших в модели факторов. Задача последователя находить факторы, увеличивающие R2 и давать объяснения вариации прогнозов, чтобы получить идеальное уравнение. Дубликаты исходных данных следует удалять из исходной таблицы до начала расчёта регрессии.
R2= 1 лишь при полном согласии экспериментальных (наблюдаемых) и теоретических (расчётных) данных, т.е. когда теоретическое значение точно совпадает с наблюдаемым.
В EXCEL – выполняется F-критерий значимости регрессии для уравнения в целом. Это рассчитано по наблюдаемым данным значениям.FP (F—расчетный, наблюдаемый) следует сравнивать соответствующим критическим значением FK(F—критический, табличный).FK выбирается из публикуемых статистических таблиц на заданном уровне (на том, на котором вписывались периметры моделей, например, 95%). Если наблюдаемое значение FP окажется меньше критического FK, то уравнение нельзя решить, т.е. не отвергнуть нуль – гипотеза относительной значимости всех коэффициентов регрессии постулируемой модели, т.е. коэффициент практически равен нулю.
Наблюдаемое значение F должно не просто превышать выбранную процентную точку F—распределения, а превосходить её в 4 раза.
Например, пусть F (10; 20; 0,95)=2,35, тогда наблюдаемое значение F-Х отношения должно превосходить 9,4, для того чтобы можно было расценивать полученное уравнение как удовлетворительную модель для предсказания.
Четвертый этап.
На 4-ом этапе корреляционно-регрессивного исследования полученную модель систематического значения применяют для прогнозирования (предсказания), управления или объяснения.
Основные методы поиска наилучшего решения
Существует несколько способов и алгоритмов выбора наилучшего уравнения регрессии:
1. Метод всех возможных регрессий,
2. Метод выбора «наилучшего подмножества» предикторов
3. Метод исключения
4. Шаговый регрессионный метод.
5. Гребневая регрессия.
6. Пресс.
7. Регрессия на главных компонентах.
8. Регрессия на собственных значениях.
9. Ступенчатый регрессионный метод.
10. Устойчивая регрессия.
11. Другие, более ранние методы (метод деления пополам, метод складного ножа и т.д.).
Техногенный и шаговый методы наиболее эффективны при использовании ЭВМ.
Методу исключения следуют не все, а только наилучшие регрессионные уравнения, в чём и состоит его экономичность. На первом этапе в рассчитываемые уравнения включают все независимые переменные. Затем, рассматривают корреляционную матрицу, находят независимую переменную, самую слабую (по модулю) связь с зависимой (т.е. с наименьшим по модулю значением коэффициента корреляции) и исключают её из уравнения. Заново пересматривают уравнение с меньшим числом независимых переменных. Если по сравнению с предыдущим расчётом значимость уравнения в целом (FP) и коэффициент детерминации(R2) повышен, то исключение сделано верно. Затем отыскивают в корреляционной матрице следующую переменную с наименьшим значением коэффициента корреляции, поступают аналогично. Исключение независимых переменных (по одной) и пересчет уравнений продолжают до тех пор, пока не обнаружат снижение значимости уравнения и доли вариации(R2) по сравнению с последними предшествующими расчётами. Это служит сигналом нецелесообразности последнего исключения.
Шаговый метод —действует в противоположном направлении, начиная с однофакторной модели. При этом ориентируются на данные корреляционной матрицы, т.е. на первом шаге расчёта в уравнении включают не все факторы, а только один с наибольшим по модулю значением коэффициента корреляции между независимой и зависимой переменными значениями. На каждом следующем шаге из оставшихся, не включенными в уравнение независимых переменных, в предыдущую модель добавляют только одну независимую переменную наиболее связанную с зависимой, и заново пересчитывают все параметры регрессии. После пересчёта сравнивают полученные оценки нового уравнения с оценками предыдущего шага. Так продолжается до тех пор, пока не получат наилучшее уравнение с наибольшим расчётным значением F и R2.
При поддержке множественного регрессивного анализа средствами EXCEL можно отслеживать очерёдность для каждого шага: номер шага, набор независимых переменных, вид уравнения, новые оценочные данные, коэффициент (F—расчётный и F—критический) и т.д.
| № А Г А | Количество факторов | Участвующие независимые переменные | Вид полученной модели | FP | FK | R2 | Выводы о роли включенного или исключенного фактора, о значимости модели, отборе лучшей модели |
II. Практическая часть
1. Симплекс метод
Постановка задачи
Фирма производит две модели А и В сборных книжных полок. Их производство ограничено наличием сырья высококачественных досок и временем машинной обработки. Для каждого изделия А требуется 3 м2 досок, а для изделия В- 4 м2. Фирма может получить от своих поставщиков до 1700 м2 досок в неделю. На каждое изделие А требуется 12 минут машинного времени, а на изделие В – 30. В неделю можно использовать 160 часов машинного времени. Если каждое изделие модели А приносит 2$ прибыли, а изделие В – 4$ прибыли, сколько изделий каждой модели фирме необходимо выпускать в неделю?
Цель - составить план производства требуемых изделий, обеспечивающий максимальную прибыль от их реализации, свести данную задачу к задаче линейного программирования, решить её симплекс - методом.
Построение математической модели
| Целевая функция | ||||
| Имя | Формула | |||
| F | ||||
| A | B | Сумма | ||
| Ресурсы | ||||
| Время | 1/5 | 1/2 | ||
| Прибыль |
Построение математической модели осуществляется в три этапа:
1. Определение переменных, для которых будет составляться математическая модель.
Так как требуется определить план производства изделий А и В, то переменными модели будут:
x1 - объём производства изделия А, в единицах;
x2 - объём производства изделия В, в единицах.
2. Формирование целевой функции.
Так как прибыль от реализации единицы готовых изделий А и В известна, то общий доход от их реализации составляет 2x1 + 4x2 ($). Обозначив общий доход через F, можно дать следующую математическую формулировку целевой функции: определить допустимые значения переменных x1 и x2 , максимизирующих целевую функцию F = 2x1 + 4x2 .
3. Формирование системы ограничений.
При определении плана производства продукции должны быть учтены ограничения на время и ресурсы для изготовления всех изделий. Это приводит к следующим двум ограничениям: 3x1 + 4x2 £ 1700; 1/5x1 + 1/2x2 £ 160.
Так как объёмы производства продукции не могут принимать отрицательные значения, то появляются ограничения неотрицательности: x1, x2 ³ 0.
Таким образом, математическая модель задачи представлена в виде: определить план x1, x2, обеспечивающий максимальное значение функции при наличии ограничений:
 при:
при:

Приведем задачу к каноническому виду и добавим переменные:

Определим начальный опорный план:

L1=0
Оформим данный этап задачи в виде симплекс-таблицы.
Первая симплекс-таблица.



Рис.1.1.Первая симплекс-таблица
Опорный план является оптимальным, если для задачи максимизации все его оценки отрицательны, т.е. в последней строке все элементы неположительные или нулевые. В данном случае  не является оптимальным, значит, критерий можно улучшить процесс.
не является оптимальным, значит, критерий можно улучшить процесс.
Берем из последней строки положительный элемент и просматриваем над ним столбец (элементы должны быть положительными). Применяем соотношение  для j-го столбца, выбираем элемент, при котором это выражение минимально. Знаменатель самого минимального элемента называем ведущим. Осуществим, как показано на рис. 1.1, перевод:x1 - в базис, x3 - в переменные.
для j-го столбца, выбираем элемент, при котором это выражение минимально. Знаменатель самого минимального элемента называем ведущим. Осуществим, как показано на рис. 1.1, перевод:x1 - в базис, x3 - в переменные.
Пересчитаем элементы исходной таблицы по следующему правилу:
1) Числа, стоящие в одной строке с ведущим элементом, делим на этот элемент;
2) Все остальные элементы пересчитываем по правилу четырехугольника.
Вторая симплекс-таблица.



Рис.1.2.Вторая симплекс-таблица

L2=3400/3
Опорный план не является оптимальным. Выбираем ведущий элемент и пересчитываем таблицу.
Третья симплекс-таблица.

Рис.1.3.Третья симплекс-таблица
Опорный план является оптимальным, т.к. все его оценки отрицательны (рис. 1.3), т.е. в последней строке все элементы неположительные или нулевые.

L3=1400
Решение данной задачи в Ms Excel
Для решения задачи необходимо, чтобы на компьютере был установлен программный продукт Microsoft Excel версии 1997-2003.
Необходимо произвести установку надстройки ”Поиск решения”. Для этого следует выполнить следующее действие: из пункта меню выбрать Сервис/Надстройки, в открывшемся окне отметить галочкой “Поиск решения” и нажать ОК (Рис. 1.4).

Рис. 1.4. Установка надстройки ”Поиск решения”
Для решения задачи необходимо ввести входные данные (рис. 1.5):

Рис. 1.5. Входные данные
Установив курсор на ячейке В16, выполнить действия Сервис/Поиск решения/Выполнить/Сохранить найденные решения (Рис. 1.6). После этого в ячейку В16 будет выведен ответ. В ячейках В8,B9 автоматически строится оптимальный план.

Рис. 1.6. Поиск решения
2. Транспортная задача
Транспортная задача заключается в нахождении такого плана поставок, при котором его цена минимальна.
Необходимо решить транспортную задачу, с входными данными. Условия задачи задаются в виде таблицы:
| Потребители | Поставщики | |||
| В1 | В2 | Вn | ||
| C11 X11 | C12 X12 | … | C1n X1n | А1 |
| C21 X21 | C22 X22 | … | C2n X2n | А2 |
| … | … | … | … | … |
| b1 | b2 | … | bn |
Матрица (cij)m*n называется матрицей тарифов. Планом транспортной задачи называется матрица х=(xij)m*n, где каждое число обозначает количество единиц груза, которое надо доставить из i–го пункта отправления в j–й пункт назначения.
Решение транспортной задачи начинается с нахождения опорного плана. Для этого существуют различные способы. Например, способ “северо-западного угла”, метод минимального элемента. Клетки таблицы, в которых стоят ненулевые перевозки, являются базисными. Их число должно равняться m + n - 1.
Для решения транспортной задачи используется метод потенциалов. Идея метода потенциалов для решения транспортной задачи сводиться к следующему. Представим себе что каждый из пунктов отправления Ai вносит за перевозку единицы груза (всё ровно куда) какую-то сумму ai; в свою очередь каждый из пунктов назначения Bj также вносит за перевозку груза (куда угодно) сумму bj. Эти платежи передаются некоторому третьему лицу (“перевозчику“). Обозначим ai + bj = či,j (i=1..m;j=1..n) и будем называть величину či,j “псевдостоимостью” перевозки единицы груза из Ai в Bj. Заметим, что платежи ai и bj не обязательно должны быть положительными; не исключено, что “перевозчик” сам платит тому или другому пункту какую-то премию за перевозку. Также надо отметить, что суммарная псевдостоимость любого допустимого плана перевозок при заданных платежах (ai и bj) одна и та же и от плана к плану не меняется.
До сих пор мы никак не связывали платежи (ai и bj) и псевдостоимости či,j с истинными стоимостями перевозок C i,j. Теперь мы установим между ними связь. Предположим, что план (xi,j) невырожденный (число базисных клеток в таблице перевозок ровно (m + n -1). Для всех этих клеток xi,j >0. Определим платежи (ai и bj) так, чтобы во всех базисных клетках псевдостоимости были ровны стоимостям:
č i,j = ai + bj = с i,j , при xi,j >0.
Что касается свободных клеток (где xi,j = 0), то в них соотношение между псевдостоимостями и стоимостями может быть какое угодно.
Оказывается соотношение между псевдостоимостями и стоимостями в свободных клетках показывает, является ли план оптимальным или же он может быть улучшен. Существует специальная теорема: Если для всех базисных клеток плана (xi,j > 0)
ai + bj = č i,j= с i,j,
а для всех свободных клеток (xi,j =0)
ai + bj = č i,j≤ с i,j,
то план является оптимальным и никакими способами улучшен быть не может.
Задача (входные данные представлены в виде таблицы)
| Потребители | Поставщики | ||||
| В1 | В2 | В3 | В4 | В5 | |
Находим количество единиц груза методом северо-западного угла.
| Потребители | Поставщики | ||||
| В1 | В2 | В3 | В4 | В5 | |
L1=395
С помощью методов потенциалов определяем, что полученный план не является оптимальным. Пересчитываем таблицу, для этого строим цикл.
| Потребители | Поставщики | ||||
| В1 | В2 | В3 | В4 | В5 | |
 __ 5 __ 5
| + 6 | ||||
| + 23 | __ 7 | ||||
Вторая таблица транспортной задачи
| Потребители | Поставщики | ||||
| В1 | В2 | В3 | В4 | В5 | |
L2=380
Опорный план не является оптимальным, пересчитываем таблицу, строя цикл.
| Потребители | Поставщики | ||||
| В1 | В2 | В3 | В4 | В5 | |
 + 5 + 5
| __ 3 | ||||
| __ 23 | + 8 | ||||
| __ 1 | + 5 | ||||
Третья таблица транспортной задачи.
| Потребители | Поставщики | ||||
| В1 | В2 | В3 | В4 | В5 | |
L3=335
Полученный опорный план является оптимальным. И никакими способами улучшен быть не может.
Решение транспортной задачи в Ms Excel. Для решения задачи необходимо ввести входные данные(рис.2.1).

Рис. 2.1.Входные данные
Установив курсор на ячейке Q8, выполнить действия Сервис/Поиск решения/Выполнить/Сохранить найденные решения (Рис. 2.2). После этого в ячейку Q8 будет выведен ответ. В ячейках В5-E5 автоматически строится оптимальный план.
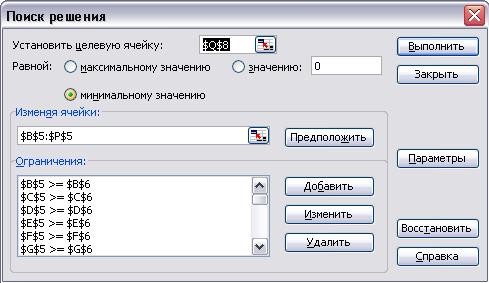
Рис. 2.2. Поиск решения