Теорема Шеннона об эффективности кодирования.
Любое сообщение состоящие из символов некого алфавита, всегда можно закодировать таким образом, что среднее число бит приходящееся на символ будет сколько угодно близко к энтропии или будет стремиться к энтропии, но не может быть меньше энтропии.
Алгоритм Шеннона-Фано.
Алгоритм Шеннона — Фано — один из первых алгоритмов сжатия, который впервые сформулировали американские учёные Шеннон и Фано. Данный метод сжатия имеет большое сходство с алгоритмом Хаффмана, который появился на несколько лет позже. Алгоритм использует коды переменной длины: часто встречающийся символ кодируется кодом меньшей длины, редко встречающийся — кодом большей длины. Коды Шеннона — Фано префиксные, то есть никакое кодовое слово не является префиксом любого другого. Это свойство позволяет однозначно декодировать любую последовательность кодовых слов.
Алгоритм:
1) Символы алфавита 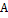 сортируются в порядке убывания вероятностей их появления в сообщении.
сортируются в порядке убывания вероятностей их появления в сообщении.
2) Полученный список разбивается на две части таким образом, чтобы суммы вероятностей были примерно одинаковы, первая группа получает в коде первый бит – единицу, вторая – 0. Затем каждая группа разбивается так, чтобы сумма вероятностей была примерно одинаковой.
3) И так до тех пор, пока разбиение не перестанет быть возможным.
Пример.



Алгоритм Хаффмана.
Алгоритм Хаффмана — алгоритм оптимального префиксного кодирования алфавита. Это один из классических алгоритмов, известных с 60-х годов. Использует только частоту появления одинаковых байт в изображении. Сопоставляет символам входного потока, которые встречаются большее число раз, цепочку бит меньшей длины. И, напротив, встречающимся редко — цепочку большей длины.
Алгоритм:
1. Символы алфавита сортируются в порядке убывания вероятностей их появления в сообщении.
2. Два символа с наименьшей вероятностью заменяются псевдо символом с вероятностью равной сумме вероятностей замененных символов. И так до тех пор пока не получиться вероятность равная 1.
3. Далее строиться кодовое дерево, по которому определяется код каждого символа.
 Пример.
Пример.

Обобщенная структура канала передачи (хранения) информации.

Кодер канала – реализует алгоритмы помеха-устойчивого кодирования такие, чтобы при кодировании можно обнаружить ошибку или исправить ее.
Помехоустойчивые коды с проверкой на четность.
 Добавили контрольный символ, разрешенное слово должно иметь четное количество едениц.
Добавили контрольный символ, разрешенное слово должно иметь четное количество едениц.
1) Источник информации.

2) Кодирование канала.

3) Канал связи.

Двоичное слово той же длины, что и передаваемое сообщение.

 передаваемого сообщение и вектора ошибки.
передаваемого сообщение и вектора ошибки.
4) Декодирование канала.

Декодирование формирует опознаватель.
 – опознаватель.
– опознаватель.




Код Хэмминга.
Код Хэмминга нужен для того, чтобы исправлять одиночные ошибки.
Коды Хэмминга — наиболее известные и, вероятно, первые из самоконтролирующихся и самокорректирующихся кодов. Построены они применительно к двоичной системе счисления.
Если ошибок нет, то вектор ошибки нулевой.
Опознаватель – двоичное число, имеющее номер ошибочного разряда.

Опознаватели проверяют на наличие ошибки.


 Перечисляется где возможные ошибки при одиночной ошибке. Опознаватели проверяют одну группу разрядов на наличие ошибки.
Перечисляется где возможные ошибки при одиночной ошибке. Опознаватели проверяют одну группу разрядов на наличие ошибки.
Для каждой группы должен быть контрольный разряд. Получается 3 группы, в каждой надо найти ошибку
Из опознавателей  контрольные разряды
контрольные разряды  .
.
 – контрольный разряд.
– контрольный разряд.
 – информационный разряд.
– информационный разряд.

 – кодер канала.
– кодер канала.
