Теоретический материал
Индексы позволяют максимально эффективно находить информацию в огромных базах данных.
SQL Server 2008 поддерживает два базовых типа индексов: кластеризованные и некластеризованные. Индексы обоих типов реализуются как сбалансированное дерево (B-дерево), в котором уровень листьев находится на нижнем уровне структуры. Разница между индексами двух типов состоит в том, что кластеризованный индекс обеспечивает физическое упорядочивание данных на диске. Кластерный индекс является разреженным – указатели в листьях B-дерева ссылаются на страницу данных.
Некластеризованный индекс является плотным и содержит только столбцы, включенные в ключ индекса. В плотных индексах указатели в листьях B-дерева ссылаются на строки реальных данных. Если для таблицы не определен кластеризованный индекс, она называется кучей (heap) или неотсортированной таблицей. В последнем случае таблица физически организуется (отсортирована) в порядке добавления новых записей в отличии от таблиц с кластеризованными индексами, которые упорядочиваются по значениям ключа сортировки. Можно сказать, что таблица может быть представлена в одной из двух форм, в виде кучи или в виде кластеризованного индекса [1].
Кластеризованные индексы
Кластеризованные индексы можно создавать на основе одного или нескольких столбцов таблицы – такой индекс называется индексным ключом и у него есть ряд ограничений:
- индекс не может охватывать не более 16 столбцов;
- максимальный размер индексного ключа – 900 байт.
Столбцы кластеризованного индекса называются ключом кластеризации (clustering key). Кластеризованный индекс оказывает особое влияние на SQL Server, так как заставляет его упорядочивать данные в таблице согласно ключу кластеризации. Поскольку таблица может упорядочиваться лишь одним способом, в ней можно задать лишь один кластеризованный индекс.
Кластеризованные индексы задают порядок сортировки данных в таблице. Однако кластеризованные индексы не обеспечивают порядок физической сортировки. Кластеризованный индекс не приводит к физическому упорядочиванию данных на диске, потому что это привело бы к большому числу операций дискового ввода-вывода при разбиении страниц. Он лишь гарантирует, что индексированная цепочка страниц упорядочена логически, что позволяет SQL Server при поиске данных переходить прямо по цепочке страниц. В процессе движения сервера SQL Server по индексированной цепочке страниц строки данных считываются в порядке ключа кластеризации [2].
Некластеризованный индекс
Некластеризованный индекс не накладывает никаких ограничений на упорядочивание записей в таблице, поэтому в одной таблице можно создать много некластеризованных индексов, но у этих индексов такие же ограничения, как и у кластеризованных индексов:
- индекс не может охватывать не более 16 столбцов;
- максимальный размер индексного ключа – 900 байт.
Конечный уровень некластеризованного индекса содержит указатель на нужные данные. Если в таблице есть кластеризованный индекс, конечный уровень некластеризованного индекса указывает на ключ кластеризации. Если же кластеризованного индекса нет, страницы конечного уровня указывают на строки данных в таблице [2].
Общий синтаксис создания реляционного индекса таков:
CREATE [UNIQUE] [CLUSTERED | NONCLUSTERED] INDEX имя_индекса
ON <объект> (column [ASC | DESC] [, … n])
[INCLUDE (имя_столбца [, … n])]
[WHERE <предикат_фильтра> ]
[WITH (<параметры_реляционного_индекса> [, … n])]
[ON {имя_схемы_секции (имя_столбца) | имя_файловой_группы | default }]
[FILESTREAM_ON { имя_файловой_группы_filestream | имя_схемы_секции | «NULL»}][; ] [3]
Составной индекс
Составной индекс может быть создан на основании нескольких полей. В этом случае справедливы ограничения описанные ранее. Если индекс построен по полям с фиксированным размером, сумма длин этих полей должна не превышать эти 900 байт, если индекс построен по полям с переменной длинной, сумма максимальных размеров полей может превышать 900 байт, но само значение сумм по каждой записи не может быть больше 900 байт. Например, в таблице есть два поля переменной длины по 500 байт. SQL Server позволяет создать составной ключ на базе этих двух полей, если нет записей, сумма длин по обоим полям которых превышает 900 байт. Стоит обратить внимание на тот момент, что составной индекс для (Column1, Column2) является отличным от (Column2, Column1), а так же от индексов, созданных по двум этим полям в отдельности.
Фрагментация индексов
Файлы операционной системы обычно со временем фрагментируются из-за многократных операций записи. Индексы тоже могу становится фрагментированными, но фрагментация индексов отличается от фрагментации файлов.
При создании индекса все значения ключа индекса записываются в упорядоченном виде на страницах индекса. При удалении строки из таблицы SQL Server должен удалить соответствующею запись в индексе, что создает "дыры" на странице индекса. SQL Server не возвращает освобожденное пространство из-за слишком высокой стоимости операции обнаружения и повторного использования "дыр" в индексе. Если значение в базовой таблице изменяется, SQL Server перемещает запись с указателем в другое место, что создает еще одну "дыру". При переполнении страниц индексов и потребности разбиения страниц снова происходит фрагментация индекса. Со временем индексы таблицы, в которых происходит изменение данных, становятся фрагментированными [2].
Для управления степенью фрагментации индекса обычно используют параметр, который называется коэффициентом заполнения (fill factor). Для устранения фрагментации можно так же задействовать инструкцию ALTER INDEX. Параметр fill factor - это параметр индекса, который определяет долю свободного пространства, которое резервируется на каждой странице конечного уровня при создании или перестроении индекса. Зарезервированное пространство позволяет в дальнейшем размещать дополнительные значения, снижая таким образом число разбиений страниц Коэффициент заполнения измеряется в целых процентах, например значение 75 означает, что каждая создаваемая страница конечного уровня должно содержать 25% свободного пространства для размещения будущих значений [1].
Дефрагментация индексов
Поскольку SQL Server не возвращает пространство в систему, надо периодически освобождать пустое пространство в индексе, чтобы сохранить тот выигрыш в производительности, из-за которого индекс изначально создавался. Для дефрагментации индексов используют инструкцию ALTER INDEX [2].
ALTER INDEX { index_name | ALL }
ON <object>
{ REBUILD
[ [PARTITION = ALL]
[ WITH (<rebuild_index_option> [,...n ]) ]
| [ PARTITION =partition_number
[ WITH (<single_partition_rebuild_index_option>
[,...n ])
]
]
]
| DISABLE
| REORGANIZE
[ PARTITION =partition_number ]
[ WITH (LOB_COMPACTION = { ON | OFF }) ]
| SET (<set_index_option> [,...n ])
}
[; ] [3]
При дефрагментации индексов можно выбрать параметры REBUILD или REORGANIZE.
Первый параметр перестраивает все уровни индекса и заполняет страницы в соответствии с параметром fill factor. При перестроении кластеризованного индекса перестраивается только он, однако если задать параметр ALL, будет перестроен как кластеризованный, так и все некластеризованные индексы таблицы. Перестроение индекса обновляет всю структуру сбалансированного дерева, поэтому, если не задан параметр ONLINE, таблица блокируется до завершения перестроения [2]. Например, для того, чтобы перестроить индекс IX_BillID, таблицы BillItem, необходимо выполнить следующий запрос:
ALTER INDEX IX_BillID
ON BillItem
REBUILD
Параметр REORGANIZE устраняет дефрагментацию только на конечном уровне. Страницы промежуточного уровня и корневая страница не дефрагментируются. Операция REORGANIZE всегда выполняется в оперативном режиме, поэтому не вызывает долгосрочной блокировки таблицы. [2] Например, чтобы реорганизовать индекс IX_BillID, таблицы BillItem, необходимо выполнить следующий запрос:
ALTER INDEX IX_BillID
ON BillItem
REORGANIZE
Работа с индексами в MS SQL Server Management Studio
Для того что бы посмотреть какие индексы созданы нужно, открыть вкладку Index таблицы Bill на панели Object Explorer. Полный путь до вкладки: Databases ® EducationDatabase ® Tables ® [имя таблицы] ® Indexes показан на рисунке 1.1. Согласно рисунку для данной таблицы создан один кластеризованный индекс PK_Bill.
Проверьте наличие кластеризованных индексов во всех таблицах базы данных самостоятельно.
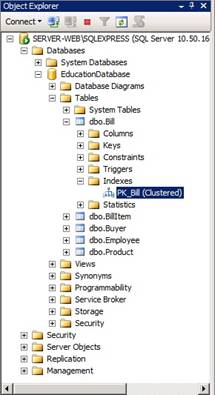
Рисунок 1.1 – Object Explorer, раскрытая вкладка Indexes
Создадим дополнительный индекс по полю внешнего ключа BillID таблицы BillItem. Создать индекс можно двумя способами:
Выполнение запроса CREATE INDEX. Создадим запрос в новой вкладке, нажав кнопку New Query стандартной панели инструментов. Панель инструментов показана на рисунке 1.2.

Рисунок 1.2 – Панель инструментов
После открытия новой вкладки, выполним запрос, показанный на рисунке 1.3. Для того что бы выполнить запрос, необходимо нажать кнопку Execute на панели инструментов (рисунок 1.2), или нажать клавишу F5 на клавиатуре.
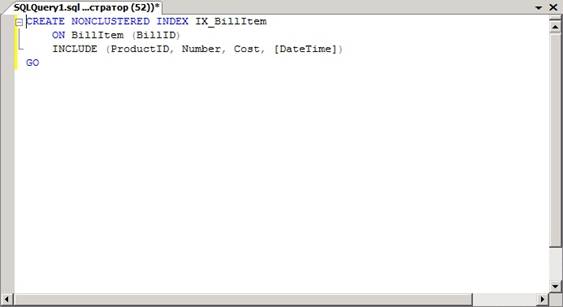
Рисунок 1.3 – Запрос CREATE INDEX
С помощью графического интерфейса Microsoft SQL Server Management Studio. В контекстном меню, вкладки Indexes выбираем пункт New Index, как показано на рисунке 1.4.

Рисунок 1.4 – Контекстное меню вкладки Indexes
В открывшемся окне необходимо указать имя индекса, атрибуты сортировки и тип индекса (кластерный, некластерный или первичный индекс XML). Если в таблице уже существует кластеный индекс, то при попытке создать новый кластерный индекс система выдаст предупреждение о возможности удаления существующего индекса и создания нового. При создании кластерного индекса происходит перестроение всех некластерных индексов.
Кроме того, в окне создания индекса можно указать признак поддержки уникальности значений в индексируемых полях. Наличие такого индекса будет препятствовать добавлению дублированных значений в индексированные поля.
Содержание работы
1. Проверьте наличие индексов по ключевым полям таблицы. При необходимости создайте кластеризованные индексы. Для создания нового индекса воспользуйтесь командой CREATE INDEX, или в среде Microsoft SQL Management Studio в разделе Tables/имя_таблицы/Indexes используйте команду New Index…
2. Создайте некластеризованные индексы по полям внешних ключей таблиц базы данных. Объясните, для чего нужны такие индексы?
3. Создайте некластеризованные индексы по информационным полям: Name и Date во всех таблицах базы данных. Объясните, для чего нужны такие индексы?
4. Для кластерного индекса и индекса по полю Date таблицы записей в чеке получите сведения о расширенных свойствах индексов. Объяснить значение информации, представленной в разделе «Fragmentation» на странице «Properties». Объясните, как вычислена глубина дерева индекса, число листьев, коэффициент фрагментации.
5. Перестройте кластеризованный индекс таблицы BillItem, используя команду ALTER INDEX или с помощью команды Rebuild в контекстном меню индекса.
6. Подготовьте материал для включения в отчетную презентацию по курсу Базы данных: специальный курс.