Лабораторная работа №2
Проектирование нейронной сети прогнозирования.
Необходимо спроектировать нейронные сети для прогноза оплат и задолженностей по ЖКХ в трех районах Татарстана: Елабужском, Лаишевском и г. Наб. Челны. Для прогноза на каждый месяц необходимо использовать данные по этим же показателям за два предыдущих месяца. Для каждого района сроится своя сеть. Исходные данные содержаться в файле Доля оплаты 2004.xls:

Для построения такого рода прогнозов, как правило, используется метод «скользящего окна»: над данными по конкретному району проводится следующее преобразование — выстраиваются в ряд значения оплат и задолженностей за январь, февраль и март. Следующий ряд смещается по дате на один месяц вправо: данные за февраль, март и апрель, и так далее. Необходимо сформировать три файла (для каждого района) с исходными данными следующего вида:
o Входные данные – Доли оплаты и задолженности за два предыдущих месяца.
o Выходные данные – доли оплаты и задолженности за следующий месяц.
 Для формирования используется прилагающийся файл Доля оплаты 2004.xls. Информация по другим районам, находящаяся в файлах, не используется.
Для формирования используется прилагающийся файл Доля оплаты 2004.xls. Информация по другим районам, находящаяся в файлах, не используется.
Например: Лаишево.
| Входные значения | Доля оплаты-1 | Доля задол-женности-1 | Доля оплаты-2 | Доля задол-женности-2 | Доля оплаты-3 | Доля задол-женности-3 | Выходные значения |
| август-сентябрь-2003г. | 0,52 | 4,45 | 0,25 | 5,25 | 0,69 | 6,07 | октябрь-2003г. |
| сентябрь-октябрь-2003г. | 0,25 | 5,25 | 0,69 | 6,07 | 0,31 | 6,45 | ноябрь-2003г. |
| октябрь-ноябрь-2003г. | 0,69 | 6,07 | 0,31 | 6,45 | 0,53 | 6,3 | декабрь-2003г. |
| ноябрь-декабрь-2003г. | 0,31 | 6,45 | 0,53 | 6,3 | 0,42 | 6,38 | январь-2004г. |
| декабрь-2003г.-январь-2004г. | 0,53 | 6,3 | 0,42 | 6,38 | 0,81 | 7,25 | февраль-2004 |
| ... | ... | ... | ... | ... | ... | ||
| октябрь-ноябрь-2004г. | 0,47 | 3,38 | 3,54 | 0,82 | 3,65 | декабрь 2004г. |
Далее сеть проектируется и обучается в пакетах Excel Neural Package и Deductor по тем же схемам, которые были описаны и изучены в предыдущей лабораторной работе. В пакете Statistica существует возможность проектирования специальной сети для временного прогнозирования без необходимости специальной подготовки данных.
Работа в системе Statistica.
Данные формируются для каждого района в виде столбцов, каждый из которых содержит сведения об оплате и задолженности за один месяц (с января по декабрь). Например, для Лаишевского района:
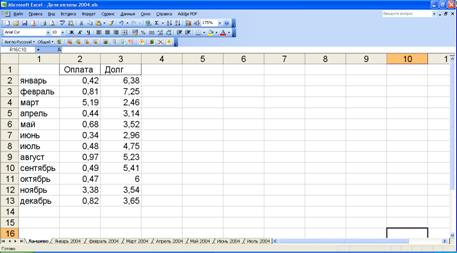
Затем эта страница данных импортируется в Statistica, как было показано на прошлом занятии.


Запустив мастер анализа – Нейронные сети, на вкладке «Быстрый» выбираем в качестве типа сети временные ряды.

Нажав кнопку «Ок» перейдем к выбору входных и выходных переменных. Из-за специфики задачи здесь «Оплата» и «Долг» являются одновременно и входными, и выходными переменными:

Подтвердив выбор, и вновь нажав на «Ок», переходим в режим создания сети. На вкладке «Быстрый» выбираем многослойный персептрон, задаем его параметры на вкладке «Элементы», и переходим к вкладке «Временные ряды». Здесь необходимо указать, сколько предыдущих значений будет использоваться для прогноза (у нас два значения)- «Окно прогноза», и на сколько шагов (месяцев) вперед делается прогноз (у нас на один месяц, т.е. на 1 шаг) – «Прогноз вперед»:

После этого в следующем окне настраиваются пааметры обучения многослойного персептрона (см. предыдущую работу), и запускается процесс обучения.

В конце в окне результатов будут отображены всевозможные варианты просмотра и использования готовой сети.
Использовать готовую сеть можно перейдя на вкладку «Дополнительно» и выбрав пункт «Наблюдение пользователя».

В заключение необходимо протестировать сохраненные в пакетах Excel Neural Package, Deductor и Statistica сети на данных из файла Доля оплаты 2005.xls. Для этого сформировать исходные данные для Excel Neural Package, Deductor, как было указано в примере, но только за 2005 год (первая строка – январь-февраль, вторая – февраль-март и т.д. до октябрь-ноябрь). Для Statistica – в виде двух столбцов. В качестве выходных данных указать пустые (заполненные нулями) колонки. Загрузить сохраненные сети (для каждого района свою) и просчитать на них подготовленные данные. Полученные результаты сравнить с истинными, для чего оформить отдельный файл «ТЕСТ-Имя района», где будут указаны истинные значения данных, полученные при расчете данные и разница между ними.
ПРИЛОЖЕНИЕ: Прогнозирование временных рядов в пакете STATISTICA Neural Networks (статья).
В задачах анализа временных рядов целью является прогноз будущих значений переменной, зависящей от времени, на основе предыдущих значений ее и/или других переменных (Bishop, 1995).
Как правило, прогнозируемая переменная является числовой, поэтому прогнозирование временных рядов - это частный случай регрессии. Однако такое ограничение не заложено в пакет STATISTICA Neural Networks, так что в нем можно прогнозировать и временные ряды номинальных (т.е. классифицирующих) переменных.
Обычно очередное значение временного ряда прогнозируется по некоторому числу его предыдущих значений (прогноз на один шаг вперед во времени). В пакете STATISTICA Neural Networks можно выполнять прогноз на любое число шагов. После того, как вычислено очередное предполагаемое значение, оно подставляется обратно и с его помощью (а также предыдущих значений) получается следующий прогноз - это называется проекцией временного ряда. В пакете STATISTICA Neural Networks можно осуществлять проекцию временного ряда и при пошаговом прогнозировании. Понятно, что надежность такой проекции тем меньше, чем больше шагов вперед мы пытаемся предсказать. В случаях, когда требуется совершенно определенная дальность прогноза, разумно будет специально обучить сеть именно на такую дальность.
В пакете STATISTICA Neural Networks для решения задач прогноза временных рядов можно применять сети всех типов (тип сети должен подходить, в зависимости от задачи, для регрессии или классификации). Сеть конфигурируется для прогноза временного ряда установкой параметров Временное окно и Горизонт. Параметр Временное окно задает число предыдущих значений, которые следует подавать на вход, а параметр Горизонт указывает, как далеко нужно строить прогноз. Количество входных и выходных переменных может быть произвольным. Однако, чаще всего в качестве входной и одновременно (с учетом горизонта) выходной выступает единственная переменная. При конфигурировании сети для анализа временных рядов изменяется метод пре-процессирования данных (извлекаются не отдельные наблюдения, а их блоки), но обучение и работа сети происходят точно так же, как и в задачах других типов.
В задачах анализа временных рядов обучающее множество данных, как правило, бывает представлено значениями одной переменной, которая является входной/выходной (т.е. служит для сети и входом, и выходом).
В задачах анализа временных рядов особую сложность представляет интерпретация понятий обучающего, контрольного и тестового множеств, а также неучитываемых данных. В обычной ситуации каждое наблюдение рассматривается независимо, и никаких вопросов здесь не возникает. В случае же временного ряда каждый входной или выходной набор составлен из данных, относящихся к нескольким наблюдениям, число которых задается параметрами сети Временное окно и Горизонт. Из этого следуют два обстоятельства:
Категория, которое будет отнесен набор, определяется категорией выходного наблюдения. Например, если в исходных данных первые два наблюдения не учитываются, а третье объявлено тестовым, и значения параметров Временное окно и Горизонт равны соответственно 2 и 1, то первый используемый набор будет тестовым, его входы будут браться из первых двух наблюдений, а выход - из третьего. Таким образом, первые два наблюдения, хотя и помечены как не учитываемые, используются в тестовом множестве. Более того, данные одного наблюдения могут использоваться сразу в трех наборах, каждый из которых может быть обучающим, контрольным или тестовым. Можно сказать, что данные "растекаются" по обучающему, контрольному и тестовому множествам. Чтобы полностью разделить эти множества, пришлось бы сформировать отдельные блоки обучающих, контрольных и тестовых наблюдений, отделенные друг от друга достаточным числом неучитываемых наблюдений.
Несколько первых наблюдений можно использовать только в качестве входных данных. При выборе наблюдений во временном ряду номер наблюдения всегда соответствует выходному значению. Поэтому первые несколько наблюдений вообще невозможно выбрать (для этого были бы нужны еще несколько наблюдений, расположенных перед первым наблюдением в исходных данных), и они автоматически помечаются как неучитываемые.