Лекция № 12
Тема: «Организация многоразрядных МП»
Текст лекции по дисциплине: «Цифровые устройства и
микропроцессоры»
КАЛИНИНГРАД
Г
Содержание
Введение.
Учебные вопросы (основная часть):
1. Особенности архитектуры современных МП
2. Тенденции развития современных МП
Заключение
Литература:
Основная литература
Л1. А.К.Нарышкин «Цифровые устройств и микропроцессоры»: учеб. пособие для студ. Высш. Учебн. Заведений/ А. К. Нарышкин, 2 – е изд. - Издательский центр «Академия», 2008г.с. 239-252
Дополнительная литература
Л.7. В.В.Корнеев, А.В.Киселев «Современные микропроцессоры». М.- НОЛИДЖ, 2003г. с. 50-72, 95-129
Учебно-материальное обеспечение:
1. Полилюкс
2. Слайды
Текст лекции
Введение
Развитие технологии и схемотехники микроэлектронных схем привело к созданию больших интегральных схем (БИС). Такие схемы представляют собой универсальные по назначению, функционально законченные устройства. По своим функциям и структуре данные устройства напоминают упрощенный вариант процессора обычной ЭВМ, но имеют несравнимо меньшие размеры. Такие БИС получили название микропроцессоров (МП).
Исходя из предполагаемого набора задач, которые должны были исполняться на этих процессорах, и преемственности решаемых программ в настоящее время существует множество типов архитектур.
1. Особенности архитектуры современных МП
Одной из основных характеристик МП является тип его архитектуры.
К архитектуре микропроцессора относят систему команд и способы адресации, возможность совмещения выполнения команд во времени, наличие дополнительных устройств в составе микропроцессора, принципы и режимы его работы и др.
При попытке классифицировать архитектуры современных микропроцессоров, неизбежно возникает проблема, связанная со стремительным и бурным развитием технологий их производства. На каждом этапе развития микропроцессоров в силу различных возможностей элементной базы и предпочтений фирм-производителей доминирует определенная взаимосвязанная совокупность архитектурных идей. В дальнейшем эти идеи могут быть скомбинированы с другими, и представлять собой уже иную архитектуру. В силу указанных причин, предлагаемая ниже классификация не в полной мере будет отражать современный уровень развития архитектур МП.
Под архитектурой МП принято понимать совокупность представлений о составе его компонентов, организации обмена информацией внутри МП и с внешней средой, реализуемых системой команд.
Выделяют понятия:
-микроархитектура;
-макроархитектура
Микроархитектура микропроцессора - это аппаратная организация и логическая структура микропроцессора, регистры, управляющие схемы, арифметико-логические устройства, запоминающие устройства и связывающие их информационные магистрали.
Макроархитектура - это система команд, типы обрабатываемых данных, режимы адресации и принципы работы микропроцессора.
В целом, архитектуру микропроцессора можно классифицировать по следующим признакам.
1. По количеству обрабатываемых потоков данных
По количеству обрабатываемых потоков данных все существующие микропроцессоры условно можно разделить на три класса.
Первыми двумя являются микропроцессоры с векторно-конвейерной архитектурой и ассоциативные процессоры с SIMD-архитектурой (Single Instruction-Multiple Data). В этих МП все обрабатывающие процессорные элементы выполняют команды одного потока, выдаваемые одним общим устройством управления. По большому счету, все ниже рассматриваемые архитектуры относятся именно к SIMD-архитектуре.
К третьему классу МП, выделяемых по данному признаку классификации, можно отнести мультипроцессорные системы с архитектурой MIMD (Multiple Instruction-Multiple Data). Такая архитектура обрабатывает одновременно много потоков данных множеством потоков команд.
2. По решаемым задачам:
По решаемым задачам различают регистровую архитектуру микропроцессора, стековую архитектуру микропроцессора, архитектурумикропроцессора, ориентированную на оперативную память.
Регистровая архитектура микропроцессора (архитектура типа «регистр регистр») − определяет наличие достаточно большого регистрового файла внутри БИС микропроцессора. Этот файл образует поле памяти с произвольной записью и выборкой информации. Микропроцессоры с регистровой архитектурой имеют высокую эффективность решения научно-технических задач. Это связано с высокой скоростью работы сверхоперативного ОЗУ (СОЗУ), которое позволяет эффективно использовать скоростные возможности арифметико-логического блока. Однако при переходе к решению задач управления эффективность таких микропроцессоров падает, так как при переключениях программ необходимо разгружать и загружать регистры СОЗУ.
Стековая архитектура микропроцессора − дает возможность создать поле памяти с упорядоченной последовательностью записи и выборки информации. Эта архитектура эффективна для организации работы с подпрограммами, что необходимо для решения сложных задач управления, или при работе с языками высокого уровня. Хранение адресов возврата позволяет организовать в стеке эффективную обработку последовательностей вложенных подпрограмм. Однако стек на кристалле микропроцессора с малой информационной емкостью быстро переполняется, а стек большой емкости требует значительных ресурсов. Реализация стека в ОЗУ решает эти проблемы.
Архитектура микропроцессора, ориентированная на оперативную память (архитектура типа «память память») − обеспечивает высокую скорость работы и большую информационную емкость рабочих регистров и стека при их организации в ОЗУ. Эта архитектура отнесена к типу «память память», поскольку в МП с такой архитектурой все обрабатываемые числа после операции в микропроцессоре вновь возвращаются в память, а не хранятся в рабочих регистрах.
Наибольшее распространение получила именно последняя архитектура. Особенно это относится к системам, работающим в реальном масштабе времени и к системам обработки данных, ориентированных на использование в системах управления.
3. По типу обрабатываемых команд.
По типу обрабатываемых команд выделяют два класса - RISC (Reduce Instruction Set Computer) архитектура МП с скоращенным набором команд и CISC (Complete Instruction Set Computer) архитектура МП с расширенным набором команд. К этому признаку можно отнести и архитектуру EPIC (Explicitly Parallel Instruction Computing) - архитектуру с вычислениями с явным параллелизмом команд.
Критерием оптимизации системы команд первых процессоров была минимизация длины программ для решения требуемых задач. При этом вводились команды, которые использовали в качестве операндов как регистры и ячейки памяти, так и сложные схемы формирования адресов с использованием индексных регистров. Набор команд ограничивался форматами «регистр регистр, регистр», «память регистр» и «регистр память». В связи со сказанным и с тем, что компиляторы не в состоянии эффективно использовать сложные команды формировалась концепция процессоров с сокращенным набором команд - RISC-процессоров. Появлению RISC-процессоров так же способствовали особенности архитектуры конвейерных процессоров: наличие отдельных наборов команд для работы с памятью и отдельных наборов команд для преобразования информации в регистрах процессора. Каждая такая команда единообразно разбивается на небольшое количество этапов с одинаковым временем исполнения (выборка команды, дешифрация команды, исполнение, запись результата). Это, в свою очередь, позволяет построить эффективный конвейер процессора, способный каждый такт выдавать результат исполнения очередной команды.
Основными чертами RISC-концепции являются:
– одинаковая длина команд;
– одинаковый формат команд;
– операндами команд могут быть только регистры;
– команды выполняют только простые действия;
– наличие большого количества регистров общего назначения (РОН) (РОН могут быть использованы любой командой);
– наличие конвейеров;
– выполнение команды не дольше, чем за один такт;
– простая адресация.
К RISC процессорам относятся процессоры архитектуры MIPS, SPARC, PowerPC, DEC Alpha, HP PA-RISC, Intel 960, AMD 29000 и др.
Очевидно, что RISC-процессоры эффективны там, где можно продуктивно использовать структурные способы уменьшения времени доступа к оперативной памяти. Если программа генерирует произвольные последовательности адресов обращения к памяти и каждая единица данных используется только для выполнения одной команды, то фактически производительность процессора определяется временем обращения к основной памяти. В этом случае использование сокращенного набора команд только ухудшает эффективность, и более оптимальными, с точки зрения производительности, являются CISC-процессоры.
В отличии от RISC-процессоров, в CISC-процессорах, как правило, команды имеют много разных форматов и требуют для своего представления различного числа ячеек памяти. Это обусловливает определение типа команды в ходе ее дешифрации при исполнении, и, в целом, усложняет устройство управления процессора и препятствует повышению тактовой частоты до уровня, достижимого в RISC-процессорах на той же элементной базе. В наборе команд CISC часто присутствуют, например, команды организации циклов, команды вызова подпрограммы и возврата из подпрограммы, сложная адресация, позволяющая реализовать одной командой доступ к сложным структурам данных. Основной недостаток CISC - большая сложность реализации процессора при малой производительности. Примеры CISC процессоров - семейство Motorola 680x0 и процессоры фирмы Intel от 8086 до Pentium 4.
Несмотря на указанные недостатки, в настоящее время на рынке МП доминируют CISC-процессоры. Это связано с тем, что развитие микропроцессоров происходит при постоянном стремлении сохранения преемственности программного обеспечения (ПО).
Однако, сохранение преемственности ПО и существующее требование повышения производительности МП противоречат друг другу. Для разрешения данного противоречия ведущими производителями МП была реализована успешная попытка решения проблемы повышения производительности в рамках CISC-архитектуры. Сохраняя преемственность по системе команд с CISC-микропроцессорами, разработчики создали новые устройства с использованием элементов RISC-архитектуры. В микропроцессор встраивается аппаратный транслятор, превращающий команды CISC-микропроцессора в команды внутреннего RISC-процессора. При этом одна команда из сложного набора может порождать до четырех команд RISC-процессора. Характерным примером таких «смешанных» МП являются последние МП фирмы AMD и фирмы Intel.
В настоящее время, по заявлениям разработчиков - фирм Intel и Hewlett-Packard, архитектурой той же значимости, что CISC и RISC является EPIC архитектура.
Особенностями EPIC архитектуры являются:
– большое количество регистров; масштабируемость архитектуры до большого количества функциональных устройств;
– явный параллелизм в машинном коде; поиск зависимостей между командами производит не процессор, а компилятор;
– предикация (Predication) - команды из разных ветвей условного ветвления снабжаются предикатными полями (полями условий) и запускаются параллельно;
– загрузка по предположению (данные из медленной основной памяти загружаются заранее).
К процессорам с EPIC-архитектурой относят Merced, работы над которым вела фирма Intel и McKinley, который разрабатывался в HP.
4. По виду исполняемых команд.
По виду исполняемых команд различают скалярные процессоры и векторные процессоры.
Классификация по данному признаку находит своё обоснование по типу исполняемых команд. Если входными операндами команды МП и её результат являются целочисленные операнды или операнды с плавающей точкой (скаляры) то такой МП относят к классу скалярных МП. При этом в МП предусмотрено более одного конвейера, позволяющего одновременно выполнять более одной разной инструкции (команды). Впервые реализована в МП Pentium (2 конвейера из 5 стадий каждый), у МП Pentium Prо уже 3 конвейера.
Если входные операнды обрабатываемой команды МП и, возможно, результат являются вектором (массивом) чисел, то такой МП является векторным (или векторно-конвейерным). Появление векторных команд и, соответственно, векторных процессоров, обусловлено стремлением ускорить обработку массивов данных за счёт исключения затрат времени на выборку и дешифрацию команд обработки, одинаковых для всех компонентов входных массивов.
5. По возможности параллельной обработки данных.
По возможности параллельной обработки данных выделяют суперскалярные, с длинным словом команды (VLIW), мультитредовые микропроцессоры.
Современные микропроцессоры содержат десять и более обрабатывающих устройств, каждое из которых представляет собой конвейер. В случае эффективной загрузки параллельно функционирующих устройств возможно получение в одном такте нескольких результатов операций, представленных скалярами.
Эффективная загрузка параллельно функционирующих конвейеров обеспечивается либо аппаратурой процессора, либо компилятором, либо совместно аппаратурой и компилятором. В компиляторах используется изощренная техника извлечения параллелизма из последовательных программ. Аппаратура микропроцессоров ориентирована на выделение более простых форм параллелизма, в том числе естественного.
При отображении внутреннего параллелизма обработки данных микропроцессора на архитектурном уровне в системе команд выделяют два крайних подхода.
Первый подход состоит в том, что никакого указания на параллельную обработку внутри процессора система команд не содержит. Такие процессоры относятся к классу суперскалярных. Такое название, с одной стороны, отличает эти процессоры от векторных процессоров, а с другой стороны, подчеркивает присущий этим процессорам внутренний параллелизм, обеспечивающий получение в одном такте нескольких скалярных результатов.
В отличии от скалярных МП в данной архитектуре предусмотрен дополнительно хотя бы один конвейер, включающий на одной из стадий несколько параллельных исполнительных блоков, осуществляющих «спекулятивное» исполнение инструкции.
В суперскалярных процессорах в рамках модели последовательных программ реализуется параллельное исполнение команд этих программ. После извлечения последовательного потока команд между командами устанавливаются только действительно необходимые зависимости по данным. При этом, чтобы сохранить порядок при наступлении прерывания, сохраняется достаточно информации о очередности следования команд в исходной программе.
Типичный суперскалярный процессор выбирает команды и исследует их по мере выполнения. Это действие проводится с целью выявления и обработки команд перехода, идентификации типа команды для ее дальнейшего направления на соответствующий исполнительный блок или в буфер памяти. Эффективность использования суперскалярных архитектур, как правило, ограничивается наличием в программах условных переходов. Это приводит к резкому возрастанию требований к ресурсам и ограничивает количество исполняемых команд. Считается, что пределом распараллеливания при суперскалярной обработке является запуск одновременно на исполнение в каждом такте 7— 8 команд.
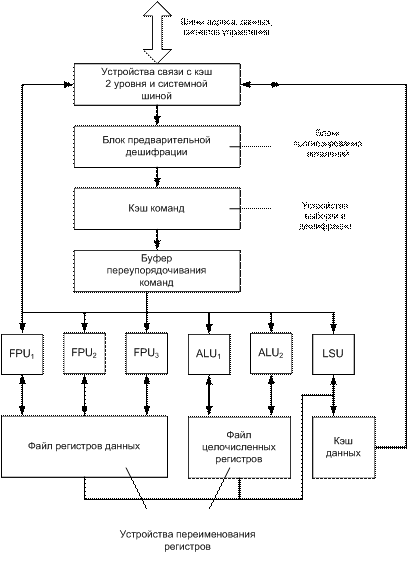
Рис. 12.1 Структура суперскалярного микропроцессора
На рисунке 12.1 показаны основные компоненты суперскалярного микропроцессора. Функциональными модулями такого МП являются модули выполнения операций с плавающей точкой (FPU) и фиксированной точкой (ALU), устройство загрузки/сохранения, файлы регистров, раздельная кэш-память команд и данных, а так же вспомогательные модули, обеспечивающие динамическое планирование вычислительного процесса, устройство связи с кэш-памятью второго уровня, блок переупорядочивания команд и блок предварительной дешифрации.
Второй подход к отображению присущего микропроцессору внутреннего параллелизма обработки данных на архитектурном уровне в системе команд полностью открывает пользователю все возможности параллельной обработки. В специально отведенных полях команды каждому из параллельно работающих обрабатывающих устройств предписывается действие, которое устройство должно совершить. Такие процессоры называются процессорами с длинным командным словом (VLIW).
Достоинства VLIW заключаются в следующем. Во-первых, компилятор может более эффективно исследовать зависимости между командами и выбирать параллельно исполняемые команды, чем это делает аппаратура суперскалярного процессора, ограниченная размером окна исполнения.
Во-вторых, VLIW-процессор имеет более простое устройство управления и потенциально может иметь более высокую тактовую частоту.
Однако у VLIW-процессоров есть серьезный фактор, снижающий их производительность. Это команды ветвления, зависящие от данных, значения которых становятся известны только в динамике вычислений.
Очередь команд VLIW-процессора не может быть очень большой ввиду отсутствия у компилятора информации о зависимостях, формируемых динамически, в процессе выполнения. Этот недостаток препятствует возможности переупорядочивания операций в VLIW-процессоре. Кроме того, такой процессор требует большого размера памяти имен, многовходовых регистровых файлов, большого числа перекрестных связей. Возможен также останов, когда во время выполнения возникла ситуация, отличающаяся от состояния в момент генерации плана выполнения (например, во время выполнения произошло неудачное обращение в кэш).
Суперскалярные микропроцессоры и микропроцессоры с длинным командным словом имеют один счетчик команд и, в силу этого, могут быть названы однотредовыми. Такой подход ограничивает производительность вычислительной структуры.
Дальнейшее повышение производительности МП в настоящее время связывается со статическим и динамическим анализом кода с целью выявления параллелизма уровня программных сегментов. При этом, для параллельного исполнения команды одной или нескольких программ, в микропроцессор вводится несколько счетчиков команд и другое дополнительное оборудование. Такие микропроцессоры с несколькими счетчиками команд получили название мультитредовые.
Мультитредовая архитектура решает проблему борьбы с простоями функциональных устройств процессора, возникающими из-за невозможности выполнения следующей команды. Это достигается путем переключения на другой регистровый файл. В результате процессор получает другие данные для продолжения вычислений, переходя к выполнению другого треда (процесса).
Мультитредовый процессор может исполнять процессы, принадлежащие одной или нескольким программам. Если процессор исполняет одну программу, то говорят о его производительности, если несколько программ - о пропускной способности.
В результате применения таких процессоров производительность МП, при прочих равных условиях, может возрасти в десятки раз.
6. По виду используемой памяти (по количеству используемых шин).
По виду используемой памяти различают Принстонскую архитектуру, (архитектуру фон Неймана или одношинную архитектуру), гарвардскую архитектуру(двухшинную архитектуру), SHARC архитектуру (супергарвардскую архитектуру, с использованием специального шинного коммутатора).
Одношинная или Принстонская архитектура – архитектура с общей, единой шиной для данных и команд, а значит и одна общая память как для данных, так и для команд (рис. 12.2).
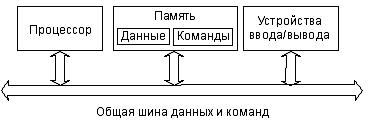
Рис. 12.2. Архитектура с общей шиной данных и команд.
Двухшинная или Гарвардская архитектура отличается наличием отдельной памяти данных и отдельной памяти команд со своими шинами (рис. 12.3).

Рис. 12.3. Архитектура с раздельными шинами данных и команд.
Архитектура с раздельными шинами данных и команд достаточно сложная, она заставляет процессор работать одновременно с двумя потоками кодов, обслуживать обмен по двум шинам одновременно. Программа может размещаться только в памяти команд, данные — только в памяти данных. Такая узкая специализация ограничивает круг задач, решаемых системой, так как не дает возможности гибкого перераспределения памяти. Память данных и память команд в этом случае имеют не слишком большой объем, поэтому применение систем с данной архитектурой ограничивается обычно не слишком сложными задачами.
Супергарвардская архитектура (SHARC) (рис. 12.4) является примером гармоничного сочетания принципов построения распределенных и связанных систем, объединяя в себе простоту и эффективность масштабирования распределенных систем с удобством программирования систем с разделяемой памятью.
В SHARC-микропроцессоре объединены высокоэффективное процессорное ядро, выполняющее обработку данных в формате с плавающей точкой, интерфейс с хост-процессором, контроллер ПДП, последовательные порты, коммуникационные линки (связи) и разделяемая шина.
Шинный коммутатор соединяет ядро процессора с независимым процессором ввода/вывода, двухвходовой памятью и портом шины мультипроцессорной системы.
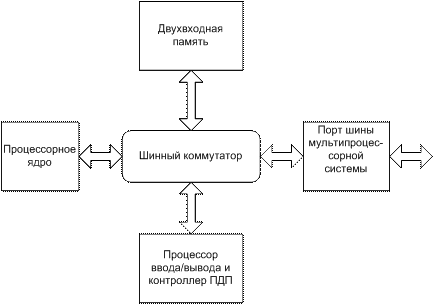
Рис. 12.4. Супергарвардская архитектура (SHARC).
7. По производителю
По производителю можно выделить следующие основные классы МП:
· Микропроцессоры с архитектурой х86:
- МП компании Intel: i8086, i80286, i80386, i80486, линия Pentium (Р5), Pentium Pro (Р6) и процессоры на его основе Pentium II, Pentium III, Pentium 4 (и их упрощённый вариант Celeron), Pentium М и другие разновидности этих МП, Merced (P7) и усовершенствованные модели IA-64;
- МП компании NexGen: модели линейки Nx586, Nx686 и другие модели, выпущенные совместно с компанией AMD;
- МП компании AMD: К5, К6 (K6-II), K7 (линия Athlon (Duron)), семейство Hammer;
- МП компании Cyrix: 5х86, 6х86, 6х86МХ, и модели WinChip, WinChip2, VIA Cyrix III после слияния с компанией VIA;;
- МП компании Transmeta: семейство Crusoe – ТМ3120, ТМ 5400, ТМ 8000 и др.;
· Микропроцессоры с архитектурой Power PC:
- МП компании Motorola и IBM: Power PC 603, 604, 620, 750/740 (G3), G4, G5, Power PC 970, Power 3, Power 4;
· Микропроцессоры с архитектурой Alpha:
- МП компании DEC: линия Alpha (21064, 21164, 21264, 21364 (компании HP)).
· Микропроцессоры с архитектурой SPARC:
- МП компании Sun Microsystems: линия SPARC (Micro SPARC, Super SPARC, Hiper SPARC и 64-разрядный МП Ultra SPARC).
· Микропроцессоры с архитектурой MAJC:
- МП компании Sun: линия MAJC (MAJC5200, MAJC5200+)
· Микропроцессоры с архитектурой PA:
- МП компании HP: PA-8000, PA-8500, PA-8700, PA-8800 (Mako), PA-8900.
· Микропроцессоры с архитектурой MIPS
- МП компании Silicon Graphics: линия MIPS R-x(R10000, R12000, R14000, R16000, R18000, R20000).
Таким образом, в настоящее время существует множество типов архитектур. Исторически архитектуры процессоров возникли исходя из предполагаемого набора задач, которые должны были исполняться на этих процессорах, и преемственности решаемых программ. Сегодня, имеющиеся аппаратные ресурсы, позволяют собрать в одном процессоре все известные архитектурные приемы повышения производительности, сообразуясь только с взаимной совместимостью. Поэтому, как считают некоторые современные ученые, скорее всего, до появления единой архитектуры процессора ещё достаточно далеко.
2. Тенденции развития современных МП
Анализ конкретных семейств микропроцессоров разных производителей подтверждает общие тенденции их развития: повышение тактовой частоты, увеличение объема и пропускной способности подсистемы памяти, увеличение количества параллельно функционирующих исполнительных устройств. Совокупная реализация в одном микропроцессоре рекордных значений по всем этим тенденциям невозможна из-за фундаментальных физических ограничений, а также из-за ограничений технологического процесса изготовления и экономических ограничений на стоимость одного микропроцессора и микроэлектронного производства в целом. Поэтому каждый конкретный тип микропроцессора есть результат многих компромиссов, принятых его создателями. Рассмотрим более подробно суть этих компромиссов на примерах сопоставительного анализа развития семейств микропроцессоров.
Повышение тактовой частоты
Для повышения тактовой частоты используются более совершенный технологический процесс с меньшими проектными нормами, увеличение числа слоев металлизации, более совершенная схемотехника меньшей каскадности и с более совершенными транзисторами, а также более плотная компоновка функциональных блоков кристалла. Так, все производители перешли на технологию КМОП, хотя Intel, например, использовали БиКМОП для первых представителей семейства Pentium. Еще более экзотическая попытка была предпринята компанией Exponential Technology, которая пыталась развить биполярную схемотехнику для производства процессоров с архитектурой Power PC и х86. Однако на частоте 466 МГц с кристалла площадью 150 мм2 выделялось около 80 Вт, что создало серьезную проблему теплоотвода (без этого кристалл превращается в светящуюся раскаленную пластину металла). Компания пыталась добиться повышения тактовой частоты до обещанного уровня, но не справилась с этим, по ее утверждению, из-за экономических проблем.
Вообще говоря, известно, что биполярные схемы и КМОП на высоких частотах имеют примерно одинаковые показатели тепловыделения, но КМОП схемы более технологичны, что и определило их преобладание в микропроцессорах.
Уменьшение размеров транзисторов, сопровождаемое снижением напряжения питания с 5 Вт до 2, 5-3 Вт и ниже, увеличивает быстродействие и уменьшает выделяемую тепловую энергию. Все производители микропроцессоров перешли с проектных норм 0,7-0,5 мкм на 0,35 мкм, а сейчас уверенно стремятся к 0, 25, 0,18, 0,1 мкм.
Проблема уменьшения длины межсоединений на кристалле решается путем увеличения числа слоев металлизации. Так, Cyrix при сохранении 0,6 мкм КМОП технологии за счет увеличения с 3 до 5 слоев металлизации сократила размер кристалла на 40% и уменьшила выделяемую мощность, исключив существовавший ранее перегрев кристаллов.
Уменьшение длины межсоединений актуально для повышения тактовой частоты работы, так как существенную долю длительности такта занимает время прохождения сигналов по проводникам внутри кристалла. Так, в Alpha 21264 предприняты специальные меры по кластеризации обработки, призванные локализовать взаимодействующие элементы микропроцессора.