СОЗДАНИЕ БАЗЫДАННЫХ В СРЕДЕ SQL-сервер И ДЕЙСТВИЯ С НЕЙ
Вопросы:
1. Создание базы данных. 1
2. Изменение базы данных. 3
3. Удаление базы данных. 3
4. Создание таблицы.. 4
5. Изменение таблицы.. 5
6. Удаление таблицы.. 6
7. Индексы в стандарте языка. 6
8. Индексы в среде MS SQL Server 7
9. Удаление индекса. 10
Создание базы данных
Процесс создания базы данных в системе SQL-сервера состоит из двух этапов: сначала организуется сама база данных, а затем принадлежащий ей журнал транзакций. Информация размещается в соответствующих файлах, имеющих расширения *.mdf (для базы данных) и *.ldf. (для журнала транзакций). В файле базы данных записываются сведения об основных объектах (таблицах, индексах, представлениях и т.д.), а в файле журнала транзакций – о процессе работы с транзакциями (контроль целостности данных, состояния базы данных до и после выполнения транзакций).
Создание базы данных в системе SQL-сервер осуществляется командой CREATE DATABASE. Следует отметить, что процедура создания базы данных в SQL-сервере требует наличия прав администратора сервера.

Рассмотрим основные параметры представленного оператора.
При выборе имени базы данных следует руководствоваться общими правилами именования объектов. Если имя базы данных содержит пробелы или любые другие недопустимые символы, оно заключается в ограничители (двойные кавычки или квадратные скобки). Имя базы данных должно быть уникальным в пределах сервера и не может превышать 128 символов.
При создании и изменении базы данных можно указать имя файла, который будет для нее создан, изменить имя, путь и исходный размер этого файла. Если в процессе использования базы данных планируется ее размещение на нескольких дисках, то можно создать так называемые вторичные файлы базы данных с расширением *.ndf. В этом случае основная информация о базе данных располагается впервичном (PRIMARY) файле, а при нехватке для него свободного места добавляемая информация будет размещаться во вторичном файле. Подход, используемый в SQL-сервере, позволяет распределять содержимое базы данных по нескольким дисковым томам.
Параметр ON определяет список файлов на диске для размещения информации, хранящейся в базе данных.
Параметр PRIMARY определяет первичный файл. Если он опущен, то первичным является первый файл в списке.
Параметр LOG ON определяет список файлов на диске для размещения журнала транзакций. Имя файла для журнала транзакцийгенерируется на основе имени базы данных, и в конце к нему добавляются символы _log.
При создании базы данных можно определить набор файлов, из которых она будет состоять. Файл определяется с помощью следующей конструкции:
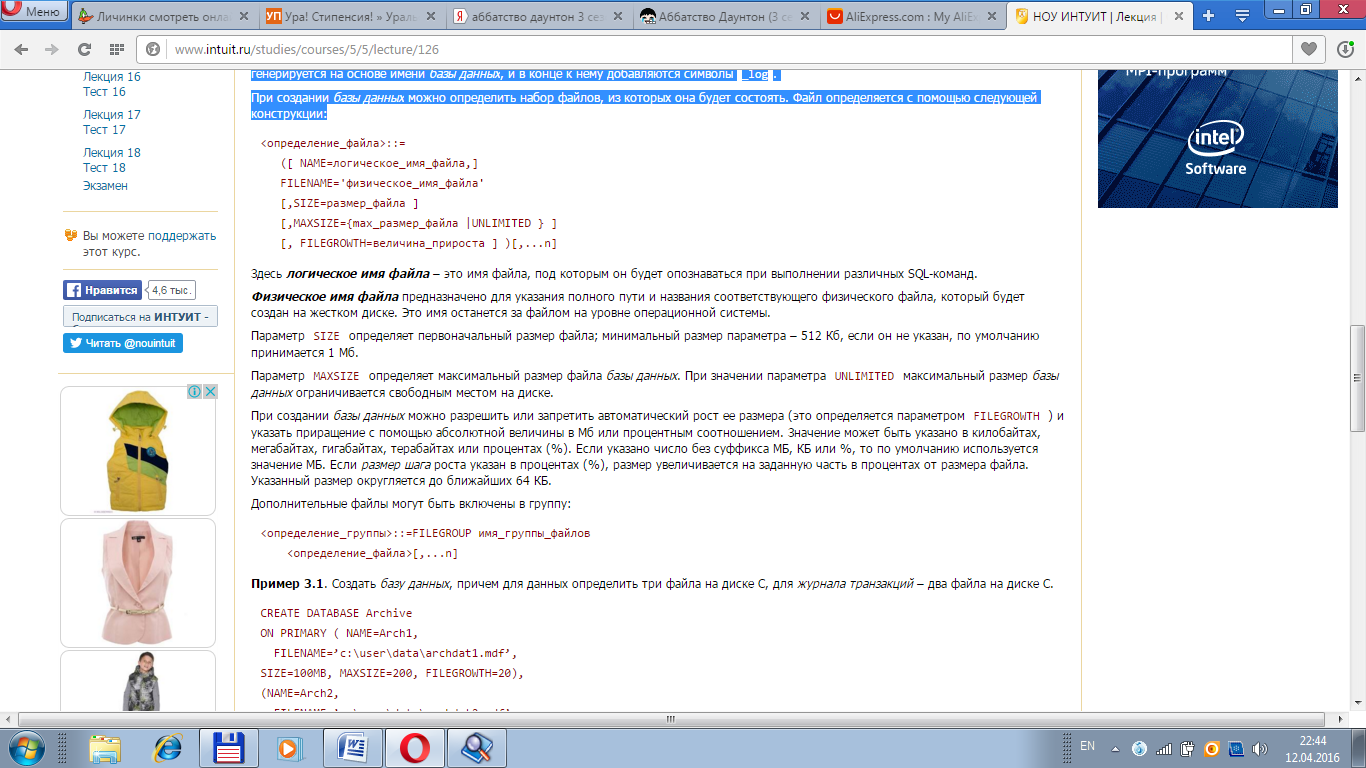
Здесь логическое имя файла – это имя файла, под которым он будет опознаваться при выполнении различных SQL-команд.
Физическое имя файла предназначено для указания полного пути и названия соответствующего физического файла, который будет создан на жестком диске. Это имя останется за файлом на уровне операционной системы.
Параметр SIZE определяет первоначальный размер файла; минимальный размер параметра – 512 Кб, если он не указан, по умолчанию принимается 1 Мб.
Параметр MAXSIZE определяет максимальный размер файла базы данных. При значении параметра UNLIMITED максимальный размер базы данных ограничивается свободным местом на диске.
При создании базы данных можно разрешить или запретить автоматический рост ее размера (это определяется параметром FILEGROWTH) и указать приращение с помощью абсолютной величины в Мб или процентным соотношением. Значение может быть указано в килобайтах, мегабайтах, гигабайтах, терабайтах или процентах (%). Если указано число без суффикса МБ, КБ или %, то по умолчанию используется значение MБ. Если размер шага роста указан в процентах (%), размер увеличивается на заданную часть в процентах от размера файла. Указанный размер округляется до ближайших 64 КБ.
Дополнительные файлы могут быть включены в группу:

Пример 3.1. Создать базу данных, причем для данных определить три файла на диске C, для журнала транзакций – два файла на диске C.
Изменение базы данных
Большинство действий по изменению конфигурации базы данных выполняется с помощью следующей конструкции:

Как видно из синтаксиса, за один вызов команды может быть изменено не более одного параметра конфигурации базы данных. Если необходимо выполнить несколько изменений, придется разбить процесс на ряд отдельных шагов.
В базу данных можно добавить (ADD) новые файлы данных (в указанную группу файлов или в группу, принятую по умолчанию) или файлы журнала транзакций.
Параметры файлов и групп файлов можно изменять (MODIFY).
Для удаления из базы данных файлов или групп файлов используется параметр REMOVE. Однако удаление файла возможно лишь при условии его освобождения от данных. В противном случае сервер не разрешит удаление.
В качестве свойств группы файлов используются следующие:
READONLY – группа файлов используется только для чтения; READWRITE – в группе файлов разрешаются изменения; DEFAULT – указанная группа файлов принимается по умолчанию.
Удаление базы данных
Удаление базы данных осуществляется командой:
DROP DATABASE имя_базы_данных [,...n]Удаляются все содержащиеся в базе данных объекты, а также файлы, в которых она размещается. Для исполнения операции удаления базы данных пользователь должен обладать соответствующими правами.
Создание таблицы
После создания общей структуры базы данных можно приступить к созданию таблиц, которые представляют собой отношения, входящие в состав проекта базы данных.
Таблица – основной объект для хранения информации в реляционной базе данных. Она состоит из содержащих данные строк и столбцов, занимает в базе данных физическое пространство и может быть постоянной или временной.
Поле, также называемое в реляционной базе данных столбцом, является частью таблицы, за которой закреплен определенный тип данных. Каждая таблица базы данных должна содержать хотя бы один столбец. Строка данных – это запись в таблице базы данных, она включает поля, содержащие данные из одной записи таблицы.
Приступая к созданию таблицы, необходимо иметь ответы на ряд вопросов:
· Как будет называться таблица?
· Как будут называться столбцы (поля) таблицы?
· Какие типы данных будут закреплены за каждым столбцом?
· Какой размер памяти должен быть выделен для хранения каждого столбца?
· Какие столбцы таблицы требуют обязательного ввода?
· Из каких столбцов будет состоять первичный ключ?
Базовый синтаксис оператора создания таблицы имеет следующий вид:

Приведенный стандарт совпадает с реализацией оператора создания таблицы в среде MS SQL Server.
Главное в команде создания таблицы – определение имени таблицы и описание набора имен полей, которые указываются в соответствующем порядке. Кроме того, этой командой оговариваются типы данных и размеры полей таблицы.
Ключевое слово NULL используется для указания того, что в данном столбце могут содержаться значения NULL. Значение NULLотличается от пробела или нуля – к нему прибегают, когда необходимо указать, что данные недоступны, опущены или недопустимы. Если указано ключевое слово NOT NULL, то будут отклонены любые попытки поместить значение NULL в данный столбец. Если указан параметр NULL, помещение значений NULL в столбец разрешено. По умолчанию стандарт SQL предполагает наличие ключевого словаNULL.
Мы использовали упрощенную версию оператора CREATE TABLE стандарта SQL. Его полная версия приводится при обсуждении вопросов обеспечения целостности данных.
Пример 3.2. Создать таблицу для хранения данных о товарах, поступающих в продажу в некоторой торговой фирме. Необходимо учесть такие сведения, как название и тип товара, его цена, сорт и город, где товар производится.

Пример 3.3. Создать таблицу для сохранения сведений о постоянных клиентах с указанием названий города и фирмы, фамилии, имени и отчества клиента, номера его телефона.
Изменение таблицы
Структура существующей таблицы может быть модифицирована с помощью команды ALTER TABLE, упрощенный синтаксис которой представлен ниже:
В среде MS SQL Server упрощенный синтаксис команды модификации таблицы имеет вид:

Команда позволяет добавлять и удалять столбцы, изменять их определения.
Одно из основных правил при добавлении столбцов в существующую таблицу гласит: когда в таблице уже содержатся данные, добавляемыйстолбец не может быть определен с атрибутом NOT NULL. Этот атрибут означает, что для каждой строки данных соответствующийстолбец должен содержать некоторое значение, поэтому добавление столбца с атрибутом NOT NULL приводит к появлению противоречия – уже существующие строки данных таблицы не будут иметь в новом столбце ненулевых значений.
Тем не менее существует способ добавления обязательных полей в существующую таблицу. Для этого необходимо:
· добавить в таблицу новый столбец, определив его с атрибутом NULL (т.е. столбец не обязан содержать каких-либо значений);
· ввести в новый столбец какие-либо значения для каждой строки данных таблицы;
· убедившись, что новый столбец содержит ненулевые значения для каждой строки данных, изменить структуру таблицы, заменив атрибут этого столбца на NOT NULL.
При изменении определений столбцов следует принимать во внимание некоторые общепринятые правила:
· размер столбца может быть увеличен до максимального значения, допускаемого соответствующим типом данных;
· размер столбца может быть уменьшен только в том случае, если содержащееся в нем наибольшее значение не будет превосходить его нового размера;
· количество разрядов числового типа данных всегда может быть увеличено;
· количество разрядов числового типа данных может быть уменьшено только в том случае, если количество разрядов наибольшего значения в соответствующем столбце не будет превосходить нового числа разрядов, определенного для этого столбца;
· количество десятичных знаков числового типа данных может быть уменьшено или увеличено;
· тип данных столбца, как правило, может быть изменен.
Некоторые реализации фактически могут ограничить разработчика в использовании некоторых опций команды ALTER TABLE. Например, может оказаться недопустимым удаление столбцов из существующей таблицы. Чтобы добиться этого, сначала потребуется удалить самутаблицу и только потом заново ее построить с нужными столбцами. Причем уже внесенные в таблицу данные будут потеряны.
Возможны трудности, связанные с удалением из таблицы столбца, который зависит от некоторого столбца другой таблицы. В таком случае сначала придется удалить ограничение столбца, а затем сам столбец.
Пример 3.4. Добавить в таблицу Клиент поле для номера расчетного счета.
ALTER TABLE Клиент ADD Рас_счет CHAR(20)Удаление таблицы
С течением времени структура базы данных меняется: создаются новые таблицы, а прежние становятся ненужными и удаляются из базы данных с помощью оператора:
DROP TABLE имя_таблицы [RESTRICT | CASCADE]Следует отметить, что эта команда удалит не только указанную таблицу, но и все входящие в нее строки данных. Если требуется удалить изтаблицы лишь данные, сохранив структуру таблицы, следует воспользоваться командой DELETE.
Оператор DROP TABLE дополнительно позволяет указывать, следует ли операцию удаления выполнять каскадно. Если в операторе указано ключевое слово RESTRICT, то при наличии в базе данных хотя бы одного объекта, существование которого зависит от удаляемой таблицы, выполнение оператора DROP TABLE будет отменено. Если указано ключевое слово CASCADE, автоматически удаляются и все прочие объекты базы данных, чье существование зависит от удаляемой таблицы, а также другие объекты, зависящие от удаляемых объектов. Общий эффект от выполнения оператора DROP TABLE с ключевым словом CASCADE может оказаться весьма ощутимым, поэтому подобные операторы следует использовать с максимальной осторожностью.
Чаще всего оператор DROP TABLE используется для исправления ошибок, допущенных при создании таблицы. Если таблица была создана с некорректной структурой, можно воспользоваться оператором DROP TABLE для ее удаления, после чего создать таблицу заново.
Индексы в стандарте языка
Индексы представляют собой структуру, позволяющую выполнять ускоренный доступ к строкам таблицы на основе значений одного или более ее столбцов. Наличие индекса может существенно повысить скорость выполнения некоторых запросов и сократить время поиска необходимых данных за счет физического или логического их упорядочивания. Индекс – это набор ссылок, упорядоченных по определенному столбцу таблицы, который в данном случае будет называться индексированным столбцом. Хотя индекс и связан с конкретным столбцом (или столбцами) таблицы, все же он является самостоятельным объектом базы данных.
Физически индекс – всего лишь упорядоченный набор значений из индексированного столбца с указателями на места физического размещения исходных строк в структуре базы данных. Когда пользователь выполняет обращающийся к индексированному столбцу запрос, СУБД автоматически анализирует индекс для поиска требуемых значений.
Однако, поскольку индексы должны обновляться системой при каждом внесении изменений в их базовую таблицу, они создают дополнительную нагрузку на систему.
Индексы обычно создаются с целью удовлетворения определенных критериев поиска после того, как таблица уже находилась некоторое время в работе и увеличилась в размерах. Создание индексов не предусмотрено стандартом SQL, однако большинство диалектов поддерживают как минимум следующий оператор:
CREATE [ UNIQUE ] INDEX имя_индекса ON имя_таблицы(имя_столбца[ASC|DESC][,...n])Указанные в операторе столбцы составляют ключ индекса. Индексы могут создаваться только для базовых таблиц, но не для представлений. Если в операторе указано ключевое слово UNIQUE, уникальность значений ключа индекса будет автоматически поддерживаться системой. Требование уникальности значений обязательно для первичных ключей, а также возможно и для других столбцов таблицы (например, для альтернативных ключей). Хотя создание индекса допускается в любой момент, при его построении для уже заполненной данными таблицымогут возникнуть проблемы, связанные с дублированием данных в различных строках. Следовательно, уникальные индексы (по крайней мере, для первичного ключа) имеет смысл создавать непосредственно при формировании таблицы. В результате система сразу возьмет на себя контроль за уникальностью значений данных в соответствующих столбцах.
Если созданный индекс впоследствии окажется ненужным, его можно удалить с помощью оператора
DROP INDEX имя_индекса