Основные понятия БНФ
n Терминальный символ – символ, состоящий только из букв алфавита описываемого языка. В общем случае символом может быть одна или несколько букв, имеющие вместе определенное значение. Например, ключевое слово END.
n Нетерминальный символ – сформулированное на русском или любом другом языке понятие описываемого языка программирования.
Нетерминальные символы заключаются в угловые скобки.
Например: <программа>, <символическое имя>, <арифметическое выражение>.
Нетерминальные символы называют металингвистическими переменными, переменные метаязыка.
Специальные метасимволы
¨ “::=” –по определению есть или представляет собой;
¨ “ | ” –или.
Примеры
< цифра > ::= 0 | 1 | 2… | 9.
< оператор > ::= < оператор присваивания > |
< оператор цикла > | < условный оператор >
Для того, чтобы раскрыть понятие языка, обозначаемое нетерминальным символом, используется правила подстановки (ПП) или металингвистические формулы, являются предложениями метаязыка.
В общем случае ПП:
U::= u,
где U, u – произвольные (конечные) последовательности нетерминальных и терминальных символов.
Обычно, в языках программирования
U – один нетерминальный символ,
u – любая (в том числе и пустая) последовательность нетерминальных и терминальных символов, раскрывающая сущность (возможно не до конца) нетерминального символа, стоящего в левой части подстановки.
Пример 1.
Описание синтаксиса языка целых чисел
- < целое >::= < цифры >|< знак > < цифры >
- < цифры >::= < цифра > | < цифры >< цифра >
- < знак >::= + | -
< цифра >::= 0/1/2…/9.
Пример 2.
Грамматика символического имени
< символическое имя >::= < буква > |
< символическое имя > < буква-цифра >
< буква-цифра >::= < буква > | < цифра >
- < буква >::= А | …| z
- < цифра >::= 0|1| … | 9.
Во многих случаях для сокращения записи и повышения наглядности описания синтаксиса используют так называемую модифицированную БНФ.
Модификация заключается в добавлении новых символов метаязыка.
Наиболее часто применяют квадратные и фигурные скобки.
Часть предложения, заключенная в квадратные скобки может либо присутствовать, либо отсутствовать.
Пример 3.
n < вещ. константа >::=
[< знак >]< целое >.< целое >[ E [< знак >] целое >]
n < знак >::= + | -
n < целое >::=< цифра > | < целое >< цифра >
n < цифра >::= 0 | 1 | … | 9.
n Часть предложения, заключенная в фигурные скобки, может либо отсутствовать, либо повторяться любое число раз.
Пример 4
¨ < символическое имя >::= < буква > {< буква > | < цифра >}
¨ < буква >::= А | … | z
¨ < цифра >::= 0 | 1 |... | 9
Пример 5
¨ < список имен >::= < имя > {, < имя > }
¨ Число повторений части предложения, заключенного в фигурные скобки, может быть ограничено снизу и сверху подстрочными и надстрочными индексами.
¨ Это записывается следующим образом:,
где m – минимальное, n- максимальное число повторений.
Например, цепочка символов:
Определяет символическое имя длиной не более 6 символов.
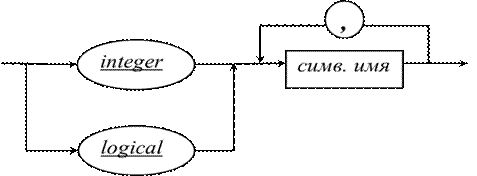
n Третий распространенный способ описания синтаксиса языков программирования – это синтаксические диаграммы, являющиеся графическим изображением БНФ.
n Нетерминальные символы изображаются на СД в прямоугольниках, терминальные в кружках или овалах (для длинных терминальных символов).
n Символы соединяются стрелками, указывающими последовательность чтения символов, образующих цепочку.
n Символ или (“ | ”) изображается на диаграмме петлей.
Пример 6
Определение символического имени
¨ Символическое имя

Цифра Буква

Пример 7
Определение синтаксиса оператора описания
Оператор описания
1.2. Порождающая грамматика (ПГ)
n Синтаксис всего языка или его части определяется последовательностью правил подстановки.
n Одно из этих правил, обозначающее наиболее общее (основное) понятие языка стоит первым,
n нетерминальный символ, обозначающий это понятие – начальный символ грамматики.
n Упомянутая последовательность правил подстановки называется порождающей грамматикой, так как она описывает процедуру получения правильных предложений языка.
n
1.2.1. Формальное определение ПГ
ФПГ G представляет собой четверку объектов:
где
¨ N - множество нетерминальных символов, обозначающих конструкции описываемого языка;
¨ T - множество терминальных символов, состоящих из букв алфавита описываемого языка;
¨ начальный символ грамматики, стоит в левой части первого правила подстановки;
¨ П – набор правил подстановки.
 Таким образом, чтобы описать синтаксис ФЯ, необходимо задать
Таким образом, чтобы описать синтаксис ФЯ, необходимо задать
1.2.2. Словарь грамматики:
n множество цепочек терминальных и нетерминальных символов, включая пустую цепочку.
n множество цепочек терминальных и нетерминальных символов, исключая пустую цепочку.
Пошаговый процесс получения конструкций языка по ФПГ называется выводом или порождением.
Вывод заканчивается, если все символы терминальные.
Пример 8. Вывод по грамматике примера 1 цепочки символов - 247.
< целое >::= < знак > < цифры >
- < цифры >
- < цифры > < цифра >
- <цифры > < цифра > < цифра >
- <цифра > < цифра > < цифра >
- 2 < цифра > < цифра >
- 24 < цифра >
- 247.
n Примеры вывода символических имён по грамматике 2:
1) < символическое имя > => < символическое имя > < буква-цифра > => < символическое имя > < буква-цифра > < буква-цифра > => < буква > < буква-цифра > < буква-цифра > => X< буква-цифра > < буква-цифра > => X < буква > < буква-цифра > => XY< буква-цифра > => XY< цифра > => XY9
2) < символическое имя > => < буква > => А
n В этом примере использован один очень простой прием – рекурсивное определение. В первом правиле подстановки < символическое имя > определяется вначале простейшим образом как < буква >, а потом, после разделителя | (“или”), нетерминальный символ < символическое имя > используется с определенным значением.
n После того, как < символическое имя > получило значение < буква > < буква-цифра >, на следующем шаге оно может быть определено как
< буква > < буква-цифра > < буква-цифра >
и так далее.
n Замечание:
n На любом шаге вывода можно по-разному раскрывать нетерминальные символы, если в правых частях правил подстановки присутствуют разделители “или”.
n Использование рекурсивного определения нетерминальных символов позволяет получить сколь угодно длинное предложение языка, так как рекурсия естественным образом обеспечивает повторяющийся (циклический) процесс.
n Вообще, если необходимо описать синтаксис сколь угодно длинной последовательности объектов, следует применять рекурсию.
< последовательность объектов >::=< объект > | < последовательность объектов > < объект>
n Пример описания синтаксиса простого языка программирования.
n В этом описании можно найти все особенности использования БНФ, в частности описания синтаксиса арифметических и логических выражений, являющееся уже классическим.
n Пример. Грамматика языка программирования
n Вначале зададим некоторое неформальное описание этого языка.
n Язык позволяет оперировать с данными целого (integer) и логического типов (logical ).
n Логические значения: true, false.
n Данное может быть константой, переменной или одномерным массивом целых чисел.
n Одномерный массив: array имя [n:m], где n,m – целые константы, определяющие нижнюю и верхнюю границы изменения индекса.
n Элемент массива записывается в виде:
имя [ индексное выражение ].
n Операторы языка:
¨ оператор присваивания: x:=E;
¨ условный оператор:
if условие then оператор else оператор fi или
if условие then оператор fi;
¨ оператор цикла: while условие do оператор od;
¨ пустой оператор.
1.2.3. Формальное описание синтаксиса языка в БНФ
n < программа >::= < описания > < оператор >
n < описания >::= < оператор описания >;|
< описания > < оператор описания >;
n < оператор описания >::= < оператор описания типа > | < оператор описания массива >
n < оператор описания типа >::=
< тип > < список типа >
n < тип >::= integer | logical
n < список типа >::= < имя > |
< список типа >,< имя >
n < оператор описания массива >::=
array < список массивов >
n < список массивов >::=
< элемент списка > | < список массивов >, < элемент списка >
n < элемент списка >::=
< имя >[< целое >:< целое >]
n < оператор >::= < оператор присваивания > |< условный оператор > | < оператор цикла > |
< пустой оператор > |
< оператор >; < оператор >
n < оператор присваивания >::=
< переменная >:= < выражение >
n < условный оператор >::= if < логическое выражение > then < оператор > fi |
if < логическое выражение > then < оператор > else < оператор > fi
n < оператор цикла >::= while < логическое выражение > do < оператор > od
n < пустой оператор >::=
n < переменная >::= < простая переменная >|
< переменная с индексом >
n < простая переменная >::= < имя >
n < переменная с индексом >::=
< имя > [ < арифметическое выражение > ]
n < выражение >::= < арифметическое выражение > | < логическое выражение >
n < арифметическое выражение >::=< слагаемое > | + < слагаемое > |
- < слагаемое > | < арифметическое выражение > + < слагаемое > |
< арифметическое выражение > -
< слагаемое >
n < слагаемое >::= < множитель > | < множитель > * < слагаемое > |
< множитель > / < слагаемое >
n < множитель >::= < целое > | < переменная >|
(< арифметическое выражение >)|
< множитель > ** < множитель >
n < логическое выражение >::=
< логическое слагаемое > | < логическое слагаемое > < логическое выражение >
n < логическое слагаемое >::=
< логический множитель > |
< логический множитель > < логическое слагаемое >
n < логический множитель >::= < логическая константа > | < простая переменная > |
< арифметическое выражение > < операция отношения > < арифметическое выражение > | (< логическое выражение >) |
< логический множитель >
n < логическая константа >::= < true > | < false >
n < операция отношения >::= |=|>|<| | |
n < имя >::= < буква > | < имя > < буква > | < имя > < цифра>
n < буква >::= A|B|…|z
< цифра >::= 0|1|…|9
Классификация языков по Хомскому
В основе этой классификации лежит форма левой и правой частей правила подстановки
U::=u.
По Хомскому языки делятся на 4 класса с номерами 0,1,2,3, причем каждый класс с большим номером является подмножеством любого класса с меньшим номером.
Класс 0. Грамматики с фразовой структурой
Правило подстановки имеет вид:
U::=u,
где U – произвольная непустая последовательность (цепочка) терминальных и нетерминальных символов;
u - произвольная (возможно и пустая) последовательность терминальных и нетерминальных символов.
Класс 0 является наиболее мощным, языки этого класса могут служить моделью естественных языков.
Класс 1. Контекстно-зависимые грамматики
Правило подстановки имеет вид:
x U y::= x u y,
где U – нетерминальный символ;
x, u, y – произвольные последовательность (цепочка) терминальных и нетерминальных символов.
Смысл этого правила в том, что замена U на u осуществляется только в контексте x...y.
Класс 2. Контекстно-свободные грамматики
Правило подстановки имеет вид:
U::= u,
где U – ровно один нетерминальный символ;
u - произвольная цепочка терминальных и нетерминальных символов.
Грамматика типа 2 отличается от грамматики типа 1 тем, что замена U на u осуществляется в любом контексте.
Грамматика типа 2 обычно используется для описания синтаксиса языков программирования.
Класс 3. Автоматные (регулярные) грамматики
Правило подстановки имеет вид:
U::= t, U::= t n
где t – ровно один терминальный символ;
n – ровно один нетерминальный символ.
Грамматика типа 3 используется для описания синтаксиса простых языков программирования (узкоспециализированных или подмножеств языков программирования).
n Следует иметь в виду, что если хотя бы одно правило подстановки в грамматике относится к более высокому классу (с меньшим номером), чем остальные, то и вся грамматика относится к этому классу.
n Наибольший интерес в теории языков программирования представляют контекстно-свободные и автоматные грамматики. Одна из причин этого - сравнительная простота распознавания конструкций этих языков, что используется для разработки трансляторов.
1.4. Синтаксический анализ языковых конструкций
n Синтаксический анализ языковых конструкций представляет собой задачу, противоположную задаче порождения (вывода).
n Задача синтаксического анализа (задача разбора) формулируется следующим образом: определить, соответствует ли заданная конструкция некоторого языка грамматике этого языка или другими словами, является ли заданная конструкция правильным (не содержащим грамматических ошибок) предложением языка.
n Задача разбора имеет широкое практическое применение, каждый транслятор языка программирования имеет в своём составе блок синтаксического анализа.
Прежде чем рассматривать алгоритмы синтаксического анализа, введём понятие синтаксического дерева, как графического способа изображения вывода конкретного предложения языка.
1.4.1. Дерево
n представляет собой иерархическую структуру, состоящую из узлов разных уровней;
n каждый из узлов некоторого уровня (кроме последнего) связан с несколькими узлами следующего уровня и не более, чем с одним узлом предыдущего уровня.
На I уровне может быть только один узел, называемый корнем. Узлы последнего уровня называются листьями. Куст узла – множество подчиненных ему узлов нижних уровней. 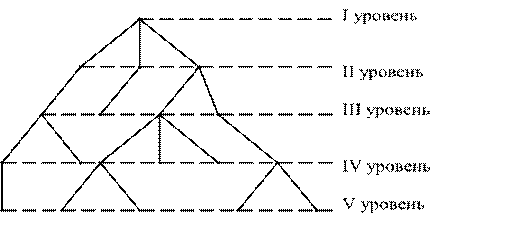
n В синтаксических деревьях узлы представляют собой нетерминальные и терминальные символы,
n листья являются терминальными символами, а остальные узлы – нетерминальными.
n Корень дерева – начальный символ грамматики. Куст представляет собой правую часть правила подстановки для данного нетерминального символа.
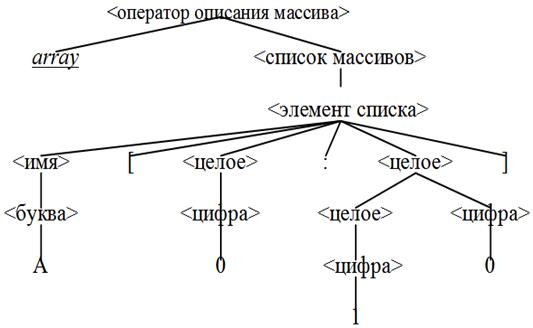
Пример 1. Синтаксическое дерево для описания массива array A[0:10]
 | |||
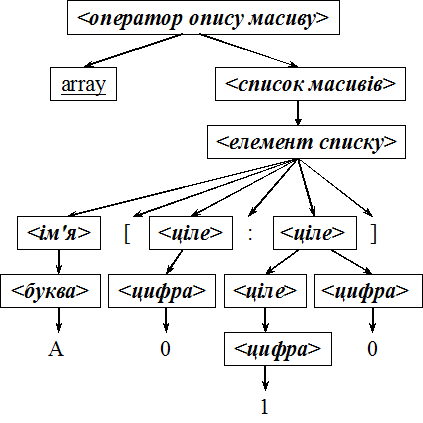 |
n Последовательность листьев этого дерева, читаемая слева направо, представляет собой предложение array A[0:10 ].
n Пример 2. Синтаксическое дерево для арифметического выражения A1*(A+B)

n Достоинством синтаксических деревьев является наглядность описания синтаксиса как самого предложения, так и его отдельных составляющих.
n С другой стороны, для реальных конструкций языков программирования дерево оказывается очень громоздким.
n Поэтому, если дерево используется для получения наглядности описания, то, либо опускаются некоторые промежуточные уровни, несущественные для этого описания, либо оно составляется для простых предложений.
n Идея построения деревьев широко используется в трансляторах, так как существуют эффективные методы отображения деревьев в памяти ЭВМ.
n Синтаксический анализ предложений, записанных на языках программирования, фактически сводится к построению синтаксических деревьев различными методами.
n Существуют два базовых алгоритма синтаксического анализа (решения задачи разбора):
n нисходящий разбор (развёртка);
n восходящий разбор (свёртка).
n При нисходящем разборе синтаксическое дерево строится от корня к листьям.
n Отличительная черта – целенаправленность, так как, отправляясь от нетерминального символа, мы стремимся найти такую подстановку, которая привела бы к части требуемой цепочки терминальных символов.
n В простейших случаях синтаксический анализатор (распознаватель) пытается достичь этого путём направленного перебора различных вариантов.
n Распознаватель рассматривает дерево сверху вниз и слева направо и выбирает первый нетерминальный символ, не имеющий подчиненных узлов (являющийся “листом”).
n В списке правил подстановки отыскивается правило (или набор правил), которое в левой части содержит этот нетерминальный символ, а в правой части (в правых частях) – очередные (считая слева направо) символы анализируемого предложения.
n Если такое правило есть, дерево наращивается и описанный процесс повторяется. Если правило не найдено, распознаватель возвращается на один или несколько шагов назад, пытаясь изменить выбор сделанный ранее.
n Процесс разбора заканчивается в одном из двух случаях:
n построено дерево, все листья которого являются терминальными символами, и при чтении слева направо образуют анализируемое предложение. В этом случае результат распознавания положителен, то есть синтаксис рассматриваемого предложения соответствует грамматике языка;
n распознаватель переработал все возможные варианты последовательностей подстановок, но так и не пришёл к дереву, описанному в 1.
n Это означает, что анализируемое предложение не принадлежит данному языку (то есть содержит ошибки).
n Следует подчеркнуть, что ошибка считается выявленной только в том случае, когда рассмотрены все допустимые варианты подстановки.
Пример. Провести нисходящий синтаксический разбор числа +2.4 по грамматике
1) < константа >::= < КФТ > | < знак > < КФТ >
2) < КФТ >::=.< целое > | < целое >. | < целое >.< целое >
3) < целое >::= < цифра > | < цифра > < целое >
4) < знак >::= + | –
5) < цифра >::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
n Процесс разбора покажем в виде последовательности шагов, на каждом из которых строится какая-то часть дерева.
n Шаг 1. Нетерминальный символ < константа > – корень дерева.
n Шаг 2. Поскольку выражение 1) не содержит в правой части терминальных символов, выбираем первую слева цепочку символов:
n < константа >::= < КФТ >.
n Получаем
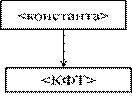
Шаг 3. В правиле 2) первая цепочка начинается с терминального символа “.”, а так как первый символ анализируемого предложения – “+”, эта цепочка не подходит. Выбираем следующую

¨ Шаг 4. В правиле 3) выбираем первую цепочку <цифра>:

¨ Шаг5. Для определения нетерминального символа <цифра> по правилу 5) есть 10 терминальных символов, но ни один из них не совпадает с “+”.
¨ Поэтому осуществляем возврат на один шаг назад и, снова пользуясь правилом 3), получаем:

¨ Шаг6. Из двух ветвей дерева выбираем, согласно алгоритму, левую и снова пытаемся применить правило 5).
¨ Так как невозможно, возвращаемся назад к дереву, полученному на шаге 2 (поскольку попытки применения правила 3) исчерпаны.
¨ В правиле 2) выбираем цепочку <целое>.<целое>. Получаем:

На этом пути мы, очевидно, сделаем ещё 2 шага, прежде чем убедимся в его ложности.
Шаг9. Возвращается к правилу 1) и выбираем для подстановки вторую цепочку < знак >< КФТ >

¨ Шаг10. Применяем правило 4) к нетерминальному символу <знак>. Получаем.

n Полученный терминальный символ совпадает с первым символом анализируемого предложения, следовательно, ветвь полученного дерева правильна.
n Далее пытаемся получить следующий символ –“2”.
n Шаг 11. Раскрываем нетерминальный символ <КФТ> по правилу 2), при этом выбираем вторую цепочку, так как в первой символ “.” не совпадает с символом “2”.

¨ Шаги 12, 13. Применяем правила 3) и 5).

n Получили сразу два терминальных символа анализируемого предложения “ 2 ” и “. ”. Однако дерево уже построено, так как все листья являются терминальными символами. Если бы все варианты подстановок были уже испытаны, можно было бы сделать вывод, что в предложении +2.4 допущена ошибка. Поскольку это не так, делаем два шага назад, возвращаясь к дереву, полученному на Шаге 11.
n Шаг 14. Снова применяем правило 3), но его вторую цепочку.

Очевидно, что на этом пути мы сделаем ещё 3 шага, прежде чем зайдём в тупик.
Пропускаем эти три шага и возвращаемся, наконец, к дереву, полученному на шаге 10.
¨ Шаг 18. Применяем к символу <КФТ> на этом дереве правило 2) (третью цепочку).

¨ Шаги 19, 20, 21, 22.
¨ Раскрываем последовательно левый и правый символы <целое>

Листья этого дерева (слева направо) образуют исходное предложение +2.4, следовательно оно соответствует заданной грамматике, т.е. не содержит ошибок.
Всегда следует иметь ввиду, что только неукоснительное, точное следование алгоритму нисходящего разбора позволяет гарантировать правильность разбора, особенно для сложных грамматик. Попытки пропустить несколько шагов как очевидные или сделать их “в уме” часто приводят к ошибкам.
n Примечание. Описанный алгоритм нисходящего разбора неприменим, если грамматика является леворекурсивной, то есть содержит правила подстановки вида
U::= Uu,
поскольку при этом попытки раскрыть самый левый нетерминальный символ приведут к бесконечному порождению нетерминального символа U. В таком случае необходимо видоизменить алгоритм, сделав его, например, правосторонним, или изменить грамматику.
1.4.2. Синтаксический анализ конструкций языков программирования
n В алгоритме нисходящего разбора не обязательно строить дерево. На каждом шаге можно записывать цепочку нетерминальных и терминальных символов, полученных после очередной подстановки.
n При восходящем разборе дерево строится от листьев к корню, то есть алгоритм, отправляясь от заданной строки, пытается, применяя правила подстановки справа налево, привести её к начальному символу грамматики.
n Часть строки, которую можно привести к не терминальному символу, называется фразой.
n Если приведение осуществляется применением одного правила подстановки, фраза называется непосредственно приводимой.
n Самая левая непосредственно приводимая фраза называется основой.
n Алгоритм восходящего разбора
В исходном предложении отыскивается основа (то есть просмотр, как и в нисходящем разборе, идет слева направо) и приводится к нетерминальному символу.
n Эта операция применяется до тех пор, пока либо получен единственный символ, являющийся начальным символом грамматики (в этом случае разбор заканчивается успешно), либо в полученной цепочке не может быть найдена фраза.
n В этом случае делается возврат на один или несколько шагов назад и выбирается другая основа.
n Если все возможные варианты перебраны, а корень дерева так и не получен, делается вывод о наличии ошибки в разбираемом предложении, и алгоритм прекращает работу.
n Таким образом, восходящий разбор представляет собой перебор вариантов, однако не целенаправленный, так как нет возможности отбрасывать заведомо неправильные подстановки, как это имеет место в нисходящем разборе (цепочка “.<целое>” в правиле 2), неподходящие цифры в правиле 5) в предыдущем примере.
n Процесс восходящего разбора записывают либо в виде построения дерева от листьев к корню, либо в виде последовательности цепочек терминальных и нетерминальных символов, начинающейся с анализируемого предложения, заканчивающейся (если предложение не содержит ошибок) начальным символом грамматики.
n Пример. Провести восходящий синтаксический разбор выражения 5*I+J по грамматике
n 1) <выражение>::= <слагаемое> | <слагаемое>+<имя> | <слагаемое>–<имя> | <слагаемое>+<целое> | <слагаемое>–<целое>
n 2) <слагаемое>::= <имя> | <целое> | <целое>*<имя>
n 3) <целое>::= <цифра> | <целое><цифра>
n 4) <имя>::= I | J | K | L | M | N
n 5) <цифра>::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
n Разбор представим в виде последовательности шагов, на каждом из которых будет получена цепочка символов, непосредственно приводимые фразы будем подчёркивать. Справа в скобках указаны номера правил, по которым произведена подстановка.
n Шаг 1. Исходное предложение.
n Шаг 2. <цифра> *I+J 5)
n Шаг 3. <целое> *I+J 3)
n Шаг 4. <слагаемое> *I+J 2)
n Шаг 5. <выражение>* I +J 1)
n Шаг 6. <выражение>* <имя> +J 4)
n Шаг 7. <выражение>* <слагаемое> +J 2)
n Шаг 8. <выражение>*<выражение>+ J 1)
n Шаг9. <выражение>*<выражение>+ <имя> 4)
n Шаг10. <выражение>*<выражение>
n + <слагаемое> 2)
n Шаг11. <выражение>*<выражение>+
n <выражение> 1)
n В полученной цепочке нет фразы. Изменить выбор непосредственно приводимой фразы можно, вернувшись к цепочке, полученной на шаге 7:
n <выражение>*<слагаемое>+ J.
n Шаг 12. <выражение>* <слагаемое> +
n <имя> 4)
n Шаг 13. <выражение>*<выражение> 1)
n В полученной цепочке нет фразы.
n Возвращаемся к шагу 12 <выражение>*<слагаемое>+ <имя>.
n Шаг 14. выражение>* <слагаемое> +
n <слагаемое> 2)
n Шаг 15. <выражение>*<выражение>+
n <слагаемое> 1)
n Получили ту же цепочку, что и на шаге 10. Возвращаемся к шагу 14, сделаем один ложный шаг, затем к шагу 6: <выражение>*<имя>+ J.
n Шаг 17. <выражение>* <имя> +<имя> 4)
n Шаг 18. <выражение>*<слагаемое>+
n <имя> 2)
n Возвращаемся к шагу 17.
n Шаг 19. <выражение>* <имя> +
n <слагаемое> 2)
n Шаг 21. <выражение>*I+<имя> 4)
n Возвращаемся к шагу 4: <слагаемое>* I +J
n Шаг 25. <слагаемое> *<имя>+J 4)
n Далее проделаем ещё 18 ложных шагов, после чего вернёмся к шагу 3: <целое>* I +J.
n Шаг 44. <целое>*<имя> +J 4)
n Шаг 45. <слагаемое> +J 2)
n Шаг 46. <выражение>+ J 1)
n …
Шаг 49. <выражение>+<выражение> 1)
Возвращаемся к шагу 45.
Шаг 50. <слагаемое>+<имя> 4)
Шаг 51. <выражение>
n Главным недостатком как нисходящего, так и восходящего алгоритмов разбора является большое количество шагов, что определяется переборным характером алгоритмов.
2. Требования к выполнению работы
Задана конструкция языка программирования. Необходимо:
· разработать порождающую грамматику. Для описания правил подстановки использовать:
· Формы Бэкуса-Наура (нечетные варианты);
· Модифицированные формы Бэкуса-Наура (четные варианты);
· С помощью разработанной порождающей грамматики выполнить вывод конструкций для фрагментов программы, представляющих заданные конструкции.
· Выполнить синтаксический анализ заданных конструкций, используя алгоритм:
· Нисходящего разбора (нечетные варианты);
· Восходящего разбора (четные варианты);.
Примечание:
1. Фрагменты программ, состоящие из вариантов использования заданных конструкций языка придумать самостоятельно. Как минимум по одному фрагменту для корректного использования конструкции и с ошибкой.
2. Неформальное описание заданных конструкций языка найти самостоятельно.
3. Варианты заданий
Группа а
1. Директивы препроцессора.
2. Описание функций в языке С.
3. Определение констант в языке Паскаль.
4. Описание переменных в языке Бейсик.
5. Инициализация строковых значений языке С.
6. Логические выражения языке С.
7. Вывод строк языке С.
8. Описание переменных в языке Паскаль.
9. Ввод с клавиатуры в языке Паскаль.
10. Условный оператор в языке С.
11. Оператор цикла FOR Паскаль.
12. Оператор-переключатель в языке Бейсик.
13. Операторы цикла с пост- и предусловием в языке С.
14. Описание структур в языке Паскаль.
15. Описание пользовательских типов в языке С.
16. Описание функции main в языке С.
17. Функции работы с динамической памятью в языке Паскаль.
18. Функции работы с файлами в языке Бейсик.
19. Описание и вызов функций, аргументом которых является одномерный массив, в языке С.
20. Функции управления цветом и заливкой в графическом режиме (язык С).
21. Описание класса в языке С++.
22. Описание переменных в языке С.
23. Определение констант в языке Бейсик.
Группа б
1. Функции вывода графических фигур (язык С).
2. Описание производного класса в языке С++.
3. Описание переменных в языке Паскаль.
4. Описание функций и процедур в языке Бейсик.
5. Инициализация массивов в языке С.
6. Арифметические выражения языке С.
7. Вывод на экран в языке С++.
8. Вывод строк языке С.
9. Условный оператор в языке Паскаль.
10. Оператор цикла FOR в языке С.
11. Инициализация строковых значений языке С.
12. Оператор-переключатель в языке Паскаль.
13. Операторы цикла с пост- и предусловием в языке Бейсик.
14. Описание структур в языке С.
15. Описание пользовательских типов в Паскаль.
16. Функции работы с динамической памятью в языке С.
17. Функции работы с файлами в языке Паскаль.
18. Описание и вызов функций, аргументом которых является двумерный массив, в языке С.
19. Функции обработки нажатия клавиш в языке С.
20. Перегрузка операций в языке С++.
21. Определение констант в языке С.
22. Описание функций и процедур в языке Паскаль.
23. Логические выражения языке С