Общее описание процесса решения задачи включает, прежде всего, определение назначения, метода получения и порядка использования выходного сообщения (определение результата и порядка его получения). Формируется общее описание технологического процесса преобразования информации и условий его реализации. Определение назначения и порядка использования выходного сообщения является учебной задачей, поскольку собственно формулировка вопроса (задачи) потребителем определяется требованиями практического использования информации. Студент-заочник должен определить последствия решения задачи и особенности практического использования полученной информации. Например, исполнение запроса "Заказы на апрель" позволит уменьшить трудозатраты на выборку данных. Полученное выходное сообщение может быть использовано для организации деятельности компании в апреле текущего года, для анализа спроса с возможной последующей корректировкой бизнес-стратегии. Все это должно способствовать росту прибыли компании, увеличению интегрального эффекта за период. Описание метода получения выходной информации также содержит ряд учебных задач. В начале этого описания следует определение типа и основных характеристик запроса. По действиям пользователя в процедурах разработки и реализации различают простые и сложные запросы. Простой запрос содержит полное и точное описание процесса и условий решения задачи. При его исполнении пользователь вводит значения отдельных параметров. Например, для получения данных по заказам определенного периода осуществляется ввод начальной даты и конечной даты периода. Выполнение сложного запроса предполагает поэтапное получение результатов с уточнением метода и условий поиска. По действиям в процессе получения и использования результатов различают запросы с одномоментным (задачи на нахождение) и поэтапным потреблением информации, а также сигнальные запросы. В общем случае любые данные (исходные и результатные) могут использоваться многократно. Но варианты реализации такого использования могут отличаться весьма существенно. Поэтапное потребление информации может осуществляться путем многократного просмотра полученной результирующей таблицы большого объема в Excel (с использованием фильтров). Кроме того, поэтапное потребление осуществляется путем получения произвольного количества результирующих таблиц, накопления и консолидации данных в Excel, анализа данных для получения требуемых выводов, предложений, рекомендаций. Выполнение сигнального запроса предполагает непрерывное отображение изменений в реальном времени. По функциональной структуре различают простые и сложные (вложенные) запросы. Сложный запрос разделяется на подчиненные запросы, которые выполняются самостоятельно и образуют, как правило, иерархическую структуру. Например, получение данных для сопоставления сводного спроса и сводного предложения по ценным бумагам предполагает самостоятельное получение данных сводного спроса и сводного предложения с последующим представлением результатов в общей таблице. Кроме того, подчиненный запрос используется в качестве сервера: возвращает значение или таблицу для использования в вызывающем (главном) запросе или при формировании таблицы базы данных. По технологическим условиям реализации в Access различают запросы на выборку, на создание таблицы, на объединение, на добавление, на обновление, на удаление данных. Существуют также перекрестные запросы и запросы к серверу. Запросы в общем случае связывают друг с другом и с таблицами, содержащими в том числе гиперссылки и OLE-объекты, составляют сложные структуры (запросы) и используют их в качестве серверов-источников данных в формах, отчетах, документах. SQL-запросы часто используют в условиях отбора и в подстановке значений. Запросы в составе транзакций выполняются в сетях параллельно, при этом возникают блокировка и взаимное ожидание. Эти проблемы решатся на основе моделирования, в том числе с использованием методов теории графов. Выполнение запроса на выборку предполагает выдачу результирующей таблицы на монитор для последующего анализа в Excel, публикации в Word или вывода в формате HTML. При выполнении запроса на создание таблицы осуществляется вывод результатной информации в таблицу базы данных, которая может быть добавлена в схему данных. При выполнении запроса на обновление осуществляется получение данных из источника (процедуры, таблицы рабочей станции или сервера) и обновление объекта (таблицы базы данных рабочей станции или сервера). Пользователь может вводить минимальный объем информации и при этом вести свою персональную базу данных. По способу применения рассматривают также временные и хранимые процедуры. Последние связывают с существующими или новыми объектами и используют для решения задач. При использовании SQL-проекта пользователь работает с представлениями. Поскольку данные хранятся на сервере, то для оперативного удовлетворения типовых потребностей в информации, одновременно возникающих у многих пользователей в одно- или двухуровневой структуре, лучше использовать распределенные приложения, чем передавать по сети запросы и ответы. С позиции пользователя представление соответствует запросу на выборку. Данные о заказах, клиентах, продажах, котировках и курсах валют могут быть одновременно использованы многими. Поэтому соответствующие представления должны входить в состав проектов. Для удовлетворения индивидуальных потребностей пользователь может связать свою базу данных с таблицами на сервере и создавать собственные запросы. Таким образом, руководствуясь вышеизложенным и используя рекомендованную литературу, студент должен составить описание запроса. Затем студент на основе существующих принципов классификации экономической информации должен определить используемые исходные данные и условия их подготовки [17, 18]. Например, таблица Клиенты содержит номативно-справочные данные (является справочником). Таблица Заказы содержит оперативно-учетные данные (данные процессов приема и оформления заказов). Поскольку таблица Клиенты является главной, корректировочные данные сначала вводятся в эту таблицу. Данные таблицы Заказы корректирутся во вторую очередь по мере возникновения изменений при обеспечении целостности информации. Далее студент характеризует условия и среду реализации запроса, рассматривая возможные варианты и выбирая лучший из них. Прежде всего – тип среды систематизации, накопления и хранения данных: информационное хранилище, базу данных коллективного доступа или локальную базу данных. В информационном хранилище систематизированные данные по различным функциональным областям хранятся в течение продолжительного периода и используются всеми работниками организации (корпорации, компании, фирмы). База данных коллективного доступа, безусловно, не предназначена для использования отдельным работником. Локальная (персональная) база данных относится к определенной функциональной области и используется определенным узким кругом работников или отдельным работником. Она также используется для хранения данных в течение периода, но функционально информационным хранилищем организации (корпорации, компании, фирмы) не является. Интеграция локальной (персональной) базы данных в информационное хранилище рассматривается как самостоятельная процедура. Между локальной (персональной) базой данных и хранилищем устанавливается обмен данными, осуществляется управление изменениями. Таким образом, в одной торговой компании в условиях использования MS SQL Server и Access2000 рассматриваемый тип среды для баз данных Борей и Расходы будет различен. Студент указывает условия, которые должны иметь место, практически выполняя вариант задания в доступной для себя среде. Затем студент должен определить условия, место и способ размещения информации (источники данных). Данные могут быть размещены на сервере вычислительной сети (в хранилище или в базе данных коллективного пользования), на сервере вычислительной сети и на рабочих станциях (распределенная база данных), на сервере вычислительной сети и на рабочих станциях с управлением изменениями и обменом данными, на сервере в одноранговой сети, на рабочей станции (персональная база данных). Таким образом, рассматриваемые условия, место и способ размещения информации для баз данных Борей и Расходы будут различными. Затем с использованием литературы студент должен определить способ реализации запроса в архитектуре "клиент/сервер". Общая идея технологии “клиент-сервер” заключается в том, что клиент (часть программы или процедура) обращается за услугой к серверу (соответствующей программе), который эту услугу выполняет и возвращает результат клиенту. Соединение и взаимодействие компьютеров осуществляются в соответствии со стандартами взаимосвязи систем и сетевыми соглашениями. Однако формы реализации указанной идеи могут существенно различаться (рис. 7, 8).
В основе реализации технологии “клиент-сервер” находится разделение операций любого техпроцесса на 3 группы:
1) ввод и отображение данных, общим требованием к которым является
дружественность – компонент представления как часть приложения;
2) прикладные операции обработки данных определенной предметной
области – прикладной компонент;
3) операции управления данными – компонент доступа к ресурсам.
В зависимости от способа интеграции указанных компонентов в
информационно-вычислительных структурах и средах различают 3 основные
модели:
1) модель доступа к удаленным данным (Remote Data Access – RDA);
2) модель сервера базы данных (DataBase Server – DBS);
3) модель сервера приложений (Application Server – AS).
Компонент
представления
Прикладной
компонент
RDA
Клиент Сервер БД (RDA)
DBS
Клиент Сервер БД
AS
Клиент Сервер приложений Сервер БД

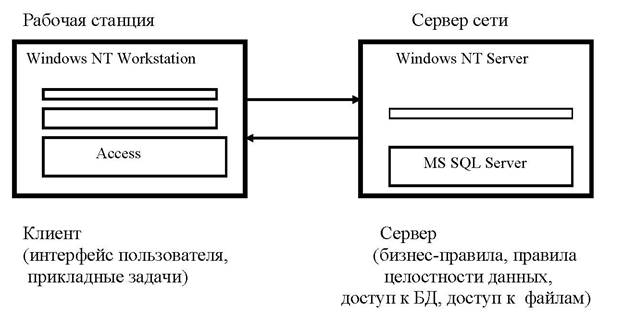
Рис. 8. Принципиальная схема решений в среде "Access + SQL Server"
Преимущества SQL Server:
1) контроль, правила целостности и защита данных повышают достоверность информации;
2) большой объем хранимой информации в условиях использования метода доступа ISAM позволяет принимать решения "по всем данным" всем руководителям и специалистам, участвующим в процессах подготовки и принятия решений;
3) одновременная многопользовательская работа;
4) снижение трафика в сети (объем передачи данных за период), в результате распределения данных повышается оперативность процессов.
В современных системах составляющие распределенной среды обработки информации (операционная система, СУБД, компоненты и приложения) реализованы в архитектуре «клиент/сервер». Таким образом, использование для решения задачи базы данных Борей или SQL-проекта NorthwindCS может быть определено по выбору студента как RDA-технология (метод или спецификация) или как DBS-технология (метод). Спецификация Remote Database Access (RDA) ISO/IEC 9579:1993 утверждена в качестве одного из стандартов на информационные системы и технологии. Известно, что любая спецификация может быть оценена как стратегическая в данное время (STR), стратегическая в будущем (FTR), нестратегическая (GAP). Данные критерии используются в теории и практике управления созданием, внедрением и развитием информационных систем. При выборе STR-спецификаций, обладающих наибольшей стабильностью, пользователи могут делать значительные инвестиции и разрабатывать долгосрочные планы относительно критически важных систем и инфраструктуры, необходимой для их поддержки. Предполагается, что изменения будут совместимы сверху вниз при общем повышении эффективности и качества решений. В состав STR-спецификаций также входят: FIPS 127-2 Database Language SQL, FIPS 160 C, FIPS 161-1 Electronic Data Interchange (EDI) и некоторые другие. При выборе FTR-спецификации существует некоторый риск в долговременном планировании. GAP-спецификации имеют оценки типа «временная мера». При их использовании любые инвестиции могут быть подвержены значительному риску [9].
RDA используется для установления дистанционного соединения между
клиентом и сервером RDA. Основная цель RDA – обеспечить взаимосвязь
прикладных программ и взаимодействие систем управления базами данных в
неоднородных функциональных средах. Cпецификация SQL является частью
RDA [9].
Услуги RDA обеспечивают установление соединения с конкретной базой
данных со стороны сервера, передачу операторов SQL в виде символьных строк
и результирующих данных.
Общее описание процесса решения задачи завершает характеристика
использованных средств Access (Мастер запросов, Конструктор запросов, SQL).
Access по своему основному назначению [5]:
1) эффективное средство создания приложений архитектуры «клиент/сервер", обеспечивающее за счет автоматизации проектных операций необходимую "скорость бизнеса", а также коллективное создание и развитие систем всеми специалистами;
2) контейнер объектов OLE и сервер OLE Automation (oбъекты OLE – документы Word и листы Excel, содержащиеся в таблицах БД).
Благодаря первому свойству Access и SQL достаточно популярны у разработчиков комплексных решений для предприятий и фирм (PIUSS и другие системы). С другой стороны, широкие возможности Access для пользователей позволяют им находить здесь новые преимущества и перспективы в рамках индивидуальной и коллективной деятельности, использования прототипов. Мастер запросов в комплексе с Конструктором запросов, Мастером отчетов, Конструктором отчетов, Мастером таблиц, Конструктором меню и Диспетчером кнопочных форм – это в сущности система автоматизированной разработки приложений (система автоматизированного проектирования обработки экономической информации). Для простого (невложенного) запроса в соответствии с определенной ранее формой выходного документа, расчетными формулами, спецификациями по группировке, сортировке и суммированию разработчиком в режиме визуализации выполняются следующие проектные операции:
1) в соответствии с формой перемещение на бланк полей из объектов
(таблиц базы данных и запросов), указанных в модели процесса;
2) ввод расчетных формул по строке выходного сообщения;
3) установка спецификаций по группировке, сортировке и суммированию.
Все остальные операции, включая построение модели данных по задаче и подготовку программного обеспечения, выполняются автоматически. Для сложного (вложенного) запроса сначала проектируется его структура, а затем каждая программная единица разрабатывается в соответствии с вышеуказанной схемой. При использовании Конструктора запросов модель данных по задаче формируется вручную. Это требует от пользователя более высокой квалификации. Автоматически формируемое в Access программное обеспечение решения задачи представляет собой SQL-код, то есть запрос на языке SQL в машинных командах. Без знания SQL можно решать лишь очень простые задачи (если при этом не допускать ошибок при построении моделей). С другой стороны, правильная диагностика и интерпретация сообщений об ошибках в полном объеме без изучения SQL невозможны. Язык SQL включает средства описания данных и средства манипулирования данными. Стандарт SQL устанавливает: определения данных, определения вида, управление доступом, ограничения целостности, манипулирование схемами и данными (выбрать, вставить, изменить, удалить), управление транзакциями, управление соединением, управление сеансом, управление диагностикой, перечень информационных схем и методы привязок языков программирования. На основе SQL осуществляется взаимодействие компонентов в рассмотренных методах RDA, DBS и AS. Все современные языки программирования, на базе которых разрабатываются решения, позволяют использовать возможности SQL. Программа на таком языке, называемом включающим, содержит SQL DECLARE SECTION с описанием данных на языке описания данных (ЯОД или DDL) и EXEC SQL с SQL-операторами обработки данных (DML,CCL,DCL). Разработчики СУБД (Oracle, Informix, Sybase, Microsoft SQL Server и Access) coздают собственные языки (PL/SQL, Transact-SQL, Sybase System 10+) на основе общего стандарта ANSI SQL. В состав общих определений возможностей SQL входят: зарезервированные слова, типы данных и функции SQL среды, а также соответствующие элементы стандарта ANSI SQL. Числа (числовые константы) с фиксированной точкой представляют в следующем виде:
10.55 -0.001 +551.702
Числа с плавающей запятой задаются путем определения мантиссы и
порядка, разделенных символом E, например:
0.551702E3 1E-3
Строковые константы заключают в кавычки:
"Финляндия" "Напитки" " LINO-Delicateses "
Дату "15 марта 2002 года" можно представить в следующем виде:
#3/15/2002#
Кроме указанных, в SQL используется большое количество типов данных. Например, LONGTEXT длиной до 1,2 Гб. Значения логического типа: "Да" (Yes) и "Нет" (No).
Операторы (инструкции) языка определения данных (DDL): CREATE TABLE (создает новую таблицу в БД), CREATE INDEX (создает индекс для таблицы для обеспечения быстрого доступа по атрибутам, входящим в индекс), ALTER TABLE (изменяет логическую структуру или ограничения целостности для таблицы), DROP TABLE (удаляет таблицу из БД), CONSTRAINT (создание ограничения-индекса, связи). Пример использования инструкции ALTER TABLE в программном режиме:
Добавление поля "Оклад" с типом данных Currency в таблицу "Сотрудники".
Sub AlterTableX1()
Dim dbs As Database
' Укажите в следующей строке путь к базе данных "Борей"
' на вашем компьютере.
Set dbs = OpenDatabase("Борей.mdb")
' Добавляет в таблицу "Сотрудники" поле "Оклад"
' с типом данных Currency.
dbs.Execute "ALTER TABLE Сотрудники " _
& "ADD COLUMN Оклад CURRENCY;"
dbs.Close
End Sub
Операторы языка обработки данных (DML): SELECT (оператор, реализующий операции реляционной алгебры и формирующий результирующую таблицу, соответствующую запросу), UPDATE (используется для обновления значений полей таблиц в БД), DELETE (используется для удаления записей из таблиц БД), SELECT …INTO (выполняет операции инструкции SELECT с размещением результирующего отношения в таблице БД), INSERT … INTO (используется для добавления записей в таблицы БД). Операция INNER JOIN реализует реляционную операцию соединения и объединения записей из двух таблиц, если связующие поля этих таблиц содержат соответствующие значения. Отличается от операций LEFT JOIN и RIGHT JOIN (внешние соединения). Применяется для формирования таблицы, используемой в указанных операторах в качестве операнда. Синтаксис:
FROM таблица_1 INNER JOIN таблица_2 ON таблица_1.поле_1 оператор
таблица_2.поле_2
Здесь "таблица_1" и "таблица_2" определяют таблицы, записи которых подлежат объединению, "поле_1" и "поле_2" – имена объединяемых полей.
Если эти поля не являются числовыми, то должны иметь одинаковый тип данных и содержать данные одного рода, однако поля могут иметь разные имена. "Оператор" – любой оператор сравнения: "=," "<," ">," "<=," ">=," или "<>". Пусть используются таблицы Партнеры и Проекты, пусть выполняется следующая операция соединения с проекцией всех полей:
FROM Партнеры INNER JOIN Проекты ON Партнеры.КодКлиента= Проекты.КодКлиента

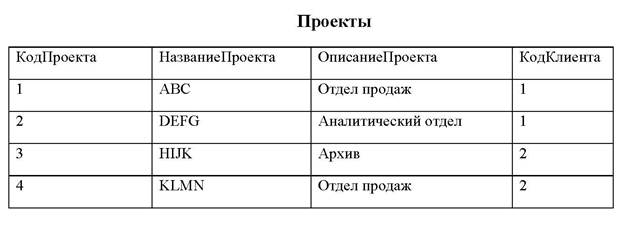

FROM Партнеры LEFT JOIN Проекты ON Партнеры.КодКлиента= Проекты.КодКлиента
получим таблицу:
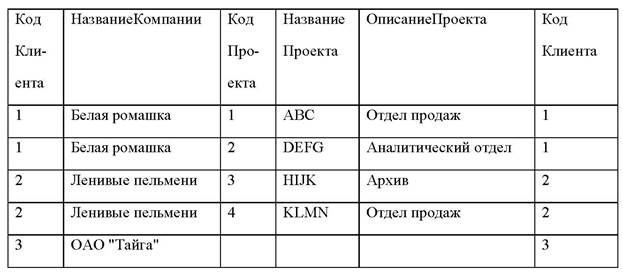
На практике широко используются вложенные конструкции INNER JOIN в разделе FROM. Например, для получения данных о затратах по проектам полученную результирующую таблицу следует соединить с таблицей Затраты:
FROM (Партнеры INNER JOIN Проекты ON Партнеры.КодКлиента= Проекты.КодКлиента)
INNER JOIN Затраты ON Проекты.КодПроекта= Затраты. КодПроекта
Язык запросов на поиск, обработку и выдачу информации (Data Query
Language) в SQL состоит из оператора SELECT.
Упрощенный синтаксис оператора SELECT [8]:
SELECT [ALL|DISTINCT] <Список полей>
FROM <Список таблиц>
[WHERE <Предикат – условие выборки>]
[GROUP BY <Список полей, по которым выполняется группировка>]
[HAVING <Предикат __________– условие для группы>]
[ORDER BY <Список полей, по которым выполняется сортировка>]
Разделы SELECT и FROM являются обязательными, а WHERE, GROUP
BY, HAVING, ORDER BY – дополнительными. Предикат ALL определяет
включение в результирующую таблицу всех строк, удовлетворяющих условию
выборки (в том числе одинаковых), а DISTINCT – различных. Заметим, что
исключение дублирования строк во всех случаях обеспечивается группировкой.
Список таблиц из раздела FROM может включать таблицу, полученную в
результате выполнения вложенных операций INNER JOIN, LEFT JOIN и
RIGHT JOIN, а также любые таблицы и запросы из соответствующего состава объектов. Если элементы списка таблиц отделяются друг от друга запятой, то результирующая таблица формируется с использованием произведения этих таблиц. Например, конструкция FROM Партнеры, Проекты определяет произведение таблиц Партнеры и Проекты (в данном случае таблицу из 12 строк, полученную путем сцепления строк этих таблиц во всех возможных вариантах).
В разделе WHERE задаются условия отбора строк из таблицы раздела FROM (выполняется реляционная операция селекции). Например, в результате выполнения конструкции
FROM Партнеры INNER JOIN Проекты ON Партнеры.КодКлиента = Проекты.КодКлиента
WHERE (((Партнеры.НазваниеКомпании)="Белая ромашка") AND
((Проекты.КодПроекта)=1))
мы получим таблицу
 Если требуется получить сведения о проектах с произвольным партнером, то в конструкцию WHERE вместо константы "Белая ромашка" следует включить параметр (переменную) с произвольным именем, заключенным слева и справа в квадратные скобки (например, КомпанияПартнер): WHERE ((Партнеры.НазваниеКомпании)= [КомпанияПартнер]) Порядок записи простых условий с помощью символов (операторов) сравнения "=" ("равно"),"<>" ("не равно"), ">" ("больше"), "<" ("меньше"), ">=" ("не меньше"), "<=" ("не больше"), а также формирования составных условий из простых с помощью логических связок AND и OR в SQL тот же, что и в известных пользователю языках программирования. Заметим, что требованиями учебника по экономической информатике определено первоочередное формирование составного условия (запись логического выражения). После этого осуществляется ввод элементов этого выражения в режиме Конструктора.
Если требуется получить сведения о проектах с произвольным партнером, то в конструкцию WHERE вместо константы "Белая ромашка" следует включить параметр (переменную) с произвольным именем, заключенным слева и справа в квадратные скобки (например, КомпанияПартнер): WHERE ((Партнеры.НазваниеКомпании)= [КомпанияПартнер]) Порядок записи простых условий с помощью символов (операторов) сравнения "=" ("равно"),"<>" ("не равно"), ">" ("больше"), "<" ("меньше"), ">=" ("не меньше"), "<=" ("не больше"), а также формирования составных условий из простых с помощью логических связок AND и OR в SQL тот же, что и в известных пользователю языках программирования. Заметим, что требованиями учебника по экономической информатике определено первоочередное формирование составного условия (запись логического выражения). После этого осуществляется ввод элементов этого выражения в режиме Конструктора.
В логическом выражении раздела WHERE может быть использован предикат Between A AND B ("принимает значения между A и B", где A и B – псевдонимы). Например, конструкция выбора строк из результирующей таблицы по условию принадлежности даты размещения заказа к октябрю 2002 года WHERE (((Заказы.ДатаРазмещения) >=#10/1/2002#) AND ((Заказы.ДатаРазмещения) <#11/1/2002#)) может быть заменена конструкцией WHERE (((Заказы.ДатаРазмещения) Between #10/1/2002# AND #10/31/2002#)) или конструкцией с вводом данных WHERE (((Заказы.ДатаРазмещения) Between [НачДата] AND [КонДата])) После соединения таблиц в FROM и отбора строк из полученной результирующей таблицы в WHERE для получения требуемого выходного сообщения достаточно указать соответствующий состав полей в разделе SELECT (определить реляционную операцию проекции). Например, SQL-инструкция SELECT Партнеры.НазваниеКомпании, Проекты.НазваниеПроекта, Проекты.ОписаниеПроекта FROM Партнеры INNER JOIN Проекты ON Партнеры.КодКлиента = Проекты.КодКлиента WHERE (((Партнеры.НазваниеКомпании)="белая ромашка")); позволит получить следующую таблицу:

Конструкция GROUP BY определяет группировку и содержит список полей, значения которых группируются. Это осуществляется чаще всего для выполнения операций над сгруппированными значениями: суммирования (функция SUM()), нахождения средней арифметической (функция AVG()), наименьшего значения (функция MIN()), наибольшего значения (функция MAX()). Функция COUNT() используется для подсчета количества строк. Например, SQL-инструкция, SELECT DISTINCTROW Оплата.КодЗаказа, Sum(Оплата.СуммаОплаты) AS [Оплачено] FROM Оплата GROUP BY Оплата.КодЗаказа; обрабатывающая записи таблицы Оплата, содержащей поля "КодОплаты", "КодЗаказа", "СуммаОплаты", "ДатаОплаты" и __________др., обеспечит получение следующего выходного сообщения путем суммирования значений поля "СуммаОплаты", соответствующих одному значению поля "КодЗаказа": 
В качестве аргумента функции SUM() может использоваться выражение (например, [Цена]*[Количество]). В разделе HAVING определяются условия отбора для полей из списка группировки в GROUP BY (аналогично WHERE-условиям).