Реализация метода построения регрессионных моделей с автокоррелированными остатками возможна в ситуации, когда параметр 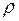 является известной величиной.В практике такие ситуации встречаются крайне редко. Поэтому возникает необходимость в процедурах построения таких моделей, когда неизвестно. Опишем несколько таких процедур.
является известной величиной.В практике такие ситуации встречаются крайне редко. Поэтому возникает необходимость в процедурах построения таких моделей, когда неизвестно. Опишем несколько таких процедур.
Расчет с использованием статистики Дарбина – Уотсона. Известно, что статистику Дарбина – Уотсона можно представить в виде
 .
.
Из этого соотношения легко получить оценку параметра , приняв за нее автокорреляцию 
 . (3.119)
. (3.119)
Такой метод оценивания рекомендуют применять при достаточно большом числе наблюдений.
Метод Кохрейне – Оркатта. Метод представляет собой итерационную процедуру из нескольких шагов:
1. С помощью обычного МНК строится регрессионная модель  и рассчитывается вектор остатков
и рассчитывается вектор остатков  .
.
2. По полученным остаткам  строится авторегрессионное уравнение
строится авторегрессионное уравнение  , оценка параметра которого
, оценка параметра которого  принимается за искомый параметр.
принимается за искомый параметр.
3. С помощью найденного значения осуществляется преобразование исходных данных, и находятся МНК-оценки 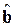 регрессионной модели;
регрессионной модели;
4. Рассчитывается новый вектор остатков  ;
;
5. Процедура повторяется, начиная со второго шага.
Процедура заканчивается, когда очередное приближение мало отличается от предыдущего.
Метод Кохре йна – Оркатта предусмотрен большинством современных компьютерных пакетов.
Метод Хилдрета – Лу. Этот метод основан на подборе параметра из интервала его возможных значений (-1; 1). Подбор осуществляется следующим образом. Последовательно для каждого значения параметра , определяемого с некоторым шагом (например, 0,1 или 0,05), исходные данные преобразуются по формулам (3.109), (3.110) и рассчитываются МНК-оценки. В качестве финального выбирается то значение параметра , при котором сумма квадратов отклонений  минимальна. Для нахождения уточненного значения в окрестности полученного таким образом параметра, устраивается более мелкая сетка, и процесс повторяется.
минимальна. Для нахождения уточненного значения в окрестности полученного таким образом параметра, устраивается более мелкая сетка, и процесс повторяется.
Метод Дарбина. Для реализации этого метода уравнение линейной регрессии записывается в виде
 . (3.120)
. (3.120)
Смысл записанного таким образом уравнения в том, что 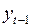 включается в число регрессоров, а – число оцениваемых параметров.
включается в число регрессоров, а – число оцениваемых параметров.
Введем обозначения  и
и  и перепишем (3.120) следующим образом:
и перепишем (3.120) следующим образом:
 . (3.121)
. (3.121)
Оценив параметры и  уравнения (3.121) с помощью обычного МНК, можем получить оценки исходного уравнения регрессии в виде
уравнения (3.121) с помощью обычного МНК, можем получить оценки исходного уравнения регрессии в виде
 ;
;  . (3.122)
. (3.122)
В этом методе первое наблюдение исключается из расчетов, так как (3.120) записывается для  .
.
3.3.4. Прогнозные расчеты при автокоррелированных остатках
В расчетах по модели с автокоррелированными остатками для повышения надежности прогнозных оценок можно использовать информацию об ошибках. Если ошибки в регрессионной модели образуют авторегрессионный процесс первого порядка
 ,
,  , (3.123)
, (3.123)
где  – последовательность независимых нормально распределенных случайных величин с нулевым средним, постоянной дисперсией
– последовательность независимых нормально распределенных случайных величин с нулевым средним, постоянной дисперсией  и
и  , то в качестве прогнозной оценки можно вместо
, то в качестве прогнозной оценки можно вместо 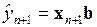 взять
взять
 . (3.124)
. (3.124)
Так как
 , (3.125)
, (3.125)
то
 . (3.126)
. (3.126)
Можно получить выражение для дисперсии остатка  , для чего вычислим квадрат этой ошибки
, для чего вычислим квадрат этой ошибки

 . (3.127)
. (3.127)
Дисперсия равна математическому ожиданию полученного выражения
 . (3.128)
. (3.128)
Таким образом, если в прогнозных расчетах учитывается автокорреляция ошибки, то дисперсия прогнозной оценки уменьшается.
Чтобы этот результат можно было использовать в практике прогнозных расчетов, необходимо значения параметров  и в формуле (3.124) заменить оценками, полученными с помощью одной из выше описанных процедур построения регрессии с автокоррелированными остатками
и в формуле (3.124) заменить оценками, полученными с помощью одной из выше описанных процедур построения регрессии с автокоррелированными остатками
 . (3.129)
. (3.129)
Среднеквадратическая ошибка прогноза рассчитывается по формуле (3.128), в которой дисперсия  заменяется оценкой
заменяется оценкой  , получаемой по остаткам построенной регрессии.
, получаемой по остаткам построенной регрессии.
3.4. Регрессионные модели с лаговыми переменными
3.4.1. Общий вид моделей с лагами в независимых переменных
Особое место в решении прогнозных задач отводится моделям с лаговыми переменными. Это вполне естественно, так как воздействие многих экономических факторов на результирующий показатель проявляется не мгновенно, а с некоторым запаздыванием. При выработке экономической стратегии модели подобного типа позволяют получить ответ на вопрос: «Что необходимо делать сегодня, чтобы получить желаемый результат в будущем?» Можно указать ряд причин, порождающих механизмы запаздывания во взаимодействии экономических факторов:
1) Институциональные причины. Прежде всего, к этим причинам относятся контрактные отношения между различными хозяйствующими субъектами, предполагающие поддержание некоторой стабильности на протяжении определенного отрезка времени. Стабильность в отношениях создает стабильность экономического взаимодействия, порождающего, в свою очередь, лаговый механизм получения результатов.
2) Психологические причины. Проявление этих причин осуществляется через инерционное поведение людей. Так, люди тратят свои доходы не сразу, а постепенно. Они следуют определенному, привычному для них, образу жизни, в частности, стремятся к поддержанию достигнутого уровня жизни, приобретая привычные блага даже в момент падения своих доходов. Следовательно, в самом поведении человека, в принимаемых им решениях проявляется своеобразный лаговый механизм.
3) Технологические причины. Эти причины непосредственно связаны с инерционностью проявления научно-технического прогресса. Очевидно, что эффект от замены старого оборудования новым проявляется не мгновенно, а через некоторое время.
4) Механизм взаимодействия экономических показателей. Многие экономические явления, обладая инерционностью, продолжают оказывать свое воздействие на соответствующие показатели в течение длительного периода времени. Например, инфляция, проявившись однажды, воздействует на такие макроэкономические показатели, как уровень спроса, безработицы, сбережений, достаточно длительное время. Известный мультипликатор Кейнса оказывает положительное влияние на экономику в течение определенного временного интервала.
Формальным представлением запаздываний во взаимодействии экономических показателей являются модели с различной структурой лагов. В качестве примеров рассмотрим модель с конечным числом лагов
 (3.130)
(3.130)
и модель с бесконечным числом лагов
 , (3.131)
, (3.131)
где  – значение моделируемого показателя в момент времени
– значение моделируемого показателя в момент времени  ;
;
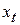 – значение фактора в момент времени ;
– значение фактора в момент времени ;
 – случайная величина;
– случайная величина;
 – параметры моделей
– параметры моделей
Методы построения этих моделей различны, поскольку зависят от числа лагов – конечного или бесконечного. И в той, и другой модели коэффициент  принято называть краткосрочным мультипликатором, так как с его помощью оценивается изменение среднего значения
принято называть краткосрочным мультипликатором, так как с его помощью оценивается изменение среднего значения  под воздействием единичного изменения переменной
под воздействием единичного изменения переменной  в тот же самый момент времени. Сумма всех коэффициентов
в тот же самый момент времени. Сумма всех коэффициентов  называют долгосрочным мультипликатором. С его помощью характеризуют изменение под воздействием единичных изменений переменной в каждом из учитываемых моделью временных периодов. Любая частичная сумма
называют долгосрочным мультипликатором. С его помощью характеризуют изменение под воздействием единичных изменений переменной в каждом из учитываемых моделью временных периодов. Любая частичная сумма  (
( ) называется промежуточным мультипликатором.
) называется промежуточным мультипликатором.
Для оценивания коэффициентов с конечным числом лагов можно использовать обычный МНК, так как, по сути, она представляет собой уравнение множественной регрессии. Правда, при построении этих моделей часто приходится сталкиваться с проблемами мультиколлинеарности. Для оценки коэффициентов модели с бесконечным числом лагов разработаны специальные методы, к рассмотрению которых мы переходим.
3.4.2. Метод Койка
Метод Койкаоснован на естественном предположении о том, что степень влияния лаговой переменной убывает по мере возрастания лага. Причем, такое убывание происходит согласно закону, описываемому геометрической прогрессией, т.е. коэффициенты при  соответственно равны
соответственно равны  . Таким образом, в общем случае
. Таким образом, в общем случае  -й коэффициент модели с бесконечным числом лагов можно записать в виде
-й коэффициент модели с бесконечным числом лагов можно записать в виде
 ,
, 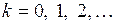 ,
,  . (3.132)
. (3.132)
Используя такое представление коэффициентов, модель с бесконечным числом лагов можно преобразовать в следующее уравнение:
 . (3.133)
. (3.133)
В результате проведенного преобразования получена модель всего с тремя неизвестными коэффициентами  , которые можно определить различными способами. Один из методов предусматривает подбор параметра
, которые можно определить различными способами. Один из методов предусматривает подбор параметра  из интервала
из интервала  . Для этого параметру последовательно присваиваются значения с некоторым фиксированным шагом
. Для этого параметру последовательно присваиваются значения с некоторым фиксированным шагом  (например,
(например,  ) и для каждого так полученного значения рассчитывается
) и для каждого так полученного значения рассчитывается
 , (3.134)
, (3.134)
где  – количество лагов, участвующих в расчете.
– количество лагов, участвующих в расчете.
Величина определяется из условия, что дальнейшее добавление лаговых значений практически не изменяет величину  , т.е. изменение , вызванное добавлением
, т.е. изменение , вызванное добавлением  -го лага, меньше ранее заданного положительного числа. Замена лаговых переменных одной интегрированной сводит задачу построения модели с лаговыми переменными к оцениванию коэффициентов уравнения
-го лага, меньше ранее заданного положительного числа. Замена лаговых переменных одной интегрированной сводит задачу построения модели с лаговыми переменными к оцениванию коэффициентов уравнения
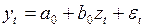 (3.135)
(3.135)
и выбору того значения , при котором коэффициент детерминации уравнения (3.135) будет наибольшим. Полученные таким образом параметры подставляются в уравнение (3.133), которое готово для проведения прогнозных расчетов.
Второй метод построения модели с бесконечным числом лагом основан на преобразовании Койка. Для выполнения этого преобразования запишем уравнение для момента времени 
 . (3.136)
. (3.136)
Умножим полученное уравнение на и вычтем его из (3.133). Получим следующее уравнение:
 , (3.137)
, (3.137)
которое можно переписать в виде
 , (3.138)
, (3.138)
где  – скользящая средняя.
– скользящая средняя.
Полученное уравнение является результатом преобразования Койка. Оно не содержит бесконечного числа лагов с убывающими по закону геометрической прогрессии коэффициентами и представляет собой уравнение с авторегрессионным членом (3.138). Для его построения необходимо оценить всего три коэффициента . Модель (3.138), несмотря на компактность своей записи, позволяет анализировать краткосрочные и долгосрочные эффекты переменных. В краткосрочном периоде значение можно считать фиксированным. Тогда краткосрочный мультипликатор равен .
Долгосрочный мультипликатор вычисляется по формуле суммы бесконечно убывающей геометрической прогрессии. Если далее предположить, что в долгосрочном периоде  стремится к некоторому своему равновесному значению
стремится к некоторому своему равновесному значению  , то значение
, то значение  также стремится к своему равновесному значению
также стремится к своему равновесному значению  . Для равновесного состояния уравнение (3.138) без учета случайного отклонения примет вид
. Для равновесного состояния уравнение (3.138) без учета случайного отклонения примет вид
 (3.139)
(3.139)
и можно определить равновесное значение
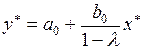 . (3.140)
. (3.140)
Коэффициент, стоящий при в (3.140), является долгосрочном мультипликатором, так как он в соответствии с известной формулой является суммой бесконечно убывающей геометрической прогрессии, т.е.
 . (3.141)
. (3.141)
Очевидно, что при сила воздействия долгосрочного мультипликатора превосходит силу воздействия краткосрочного.
Применение МНК для оценки параметров лаговой модели, полученной с помощью преобразования Койка, не всегда корректно в силу следующих обстоятельств. Во-первых, переменная , которая используется как независимая переменная, имеет стохастическую природу, как и , что нарушает одну из предпосылок МНК. Кроме того, она скорее коррелирует со случайной составляющей  , чем не коррелирует. Во-вторых, несмотря на то, что для
, чем не коррелирует. Во-вторых, несмотря на то, что для  предпосылки МНК выполняются, но для имеет место явная автокорреляция, которую можно тестировать -статистикой Дарбина. Если не применять специальных методов оценивания, то, возможно, что полученные оценки коэффициентов этой модели окажутся смещенными и несостоятельными.
предпосылки МНК выполняются, но для имеет место явная автокорреляция, которую можно тестировать -статистикой Дарбина. Если не применять специальных методов оценивания, то, возможно, что полученные оценки коэффициентов этой модели окажутся смещенными и несостоятельными.
3.4.3. Распределенные лаги Алмон
Распределенные лаги Алмон. На коэффициенты уравнения регрессии, при построении которого используется преобразование Койка, накладываются достаточно жесткие ограничения, которые связаны с предположением о том, что значения коэффициентов при лаговых переменных убывают в геометрической последовательности. Целесообразность этих предположений, как показывает практика, не во всех случаях себя оправдывает. Весьма реальна ситуация, когда, например, значения лаговой переменной с запаздыванием на 2 и 3 периода оказывают на зависимую переменную более сильное влияние, чем текущее и предшествующее текущему значение, т.е.  . Для моделирования подобных ситуаций достаточно гибким инструментом является аппарат распределенных лагов Алмон.
. Для моделирования подобных ситуаций достаточно гибким инструментом является аппарат распределенных лагов Алмон.
Модель Алмон строится в предположении, что значения коэффициентов  могут быть аппроксимированы полиномами соответствующей степени от величины лага
могут быть аппроксимированы полиномами соответствующей степени от величины лага  , т.е.
, т.е.
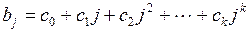 . (3.142)
. (3.142)
Реализация этого предположения позволяет каждый из коэффициентов лаговой модели представить в виде:



 (3.143)
(3.143)

 .
.
Подставить в уравнение (3.142) вместо коэффициентов полиномы, их аппроксимирующие, получим выражение
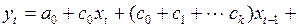

 (3.144)
(3.144)
 .
.
После перегруппировки слагаемых это выражение переписывается в виде


 (3.145)
(3.145)
 .
.
Если ввести новые переменные
 ,
,  ,
,  ,...,
,..., 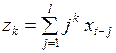 , (3.146)
, (3.146)
и заменить ими в (3.145) выражения в круглых скобках, то модель с распределенными лагами может быть представлена в виде регрессионной модели
 , (3.147)
, (3.147)
коэффициенты которой можно оценить с помощью МНК.
Все проведенные рассуждения и преобразования имеют смысл, если известна величина максимального лага  и определен порядок полинома, описывающего структура лага. В практических ситуациях, как правило, такая информация отсутствует. Поэтому величину лага и порядок полинома определяют в процессе построения модели.
и определен порядок полинома, описывающего структура лага. В практических ситуациях, как правило, такая информация отсутствует. Поэтому величину лага и порядок полинома определяют в процессе построения модели.
Последовательность процедур, выполняемых при использовании метода Алмон для построения моделей с распределенными лагами, следующая:
1) определяется максимальный лаг ;
2) определяется степень полинома ;
3) рассчитываются с помощью (3.146) значения переменных  ;
;
4) оцениваются с помощью МНК параметры уравнения линейной регрессии (3.147);
5) рассчитываются параметры исходной модели с помощью соотношений (3.143).
Практическая реализация этих процедур требует определенных усилий. Проблема в том, что для некоторых из выше приведенных пунктов нет единых рекомендаций их выполнения. Это касается 1), 2) и 4) пунктов. Логика построения этих моделей требует, чтобы величина максимального лага и степень полинома были определены до непосредственного построения модели, но процедуры их определения нельзя отнести к тривиальным.
Известно, что ошибки при определении этих величин приводят к построению неадекватных моделей. Причем, если установленный лаг оказался меньше реального, то это приводит к неверной спецификации модели, так как эта ситуация эквивалентна тому, что в регрессионной модели (4.147) учтены не все факторы и, следовательно, остатки будут коррелировать с зависимой переменной. А это значит, что не соблюдается предпосылка МНК о случайности остатков. Невыполнение этого условия приводит к получению смещенных и неэффективных оценок регрессионных коэффициентов.
В тех же случаях, когда превосходит реальную величину возникает ситуация аналогичная включению в модель статистически незначимого фактора. Нежелательный эффект от такой ошибки выражается в снижении эффективности получаемых с помощью МНК оценок. Но все же в этом случае оценки несмещенные и, поэтому ошибка с завышением величины лага приводит к меньшим искажениям модели, чем ошибка с заниженной его величиной.
Есть несколько подходов, которые решение этой проблемы переводят в практическую плоскость. Первый связан с построением нескольких альтернативных уравнений регрессии, в которых используется различные величины лагов, и выборе наилучшего из построенных уравнений. Очень важно, чтобы среди альтернативных вариантов оказались те уравнения, которые построены для максимально возможных лагов. Только в этом случае можно надеяться на получение истинной величины лага.
Второй подход основан на простом способе, предусматривающем измерение тесноты связи между зависимой переменной и всевозможными лаговыми значениями независимой переменной. В соответствии с этим подходом величина лага определяется по статистически значимой связи с переменной, имеющей максимальный лаг.
Вопрос о порядке полинома решается, в основном, путем сравнения моделей построенных с использованием полиномов различной степени. В практических расчетах обычно ограничиваются построением моделей, структура лага которых задается полиномом степени не выше трех. Выбирается та модель, которая тестируется как наиболее адекватная.
Последняя проблема, возникающая при построении модели (4.147), связана с обычно имеющей место мультиколлинеарностью переменных  , проявление которой сказывается на надежности получаемых оценок для
, проявление которой сказывается на надежности получаемых оценок для  . Однако их искажение значительно меньше, чем, если бы эти оценки были получены обычным МНК для регрессии на исходные лаговые переменные
. Однако их искажение значительно меньше, чем, если бы эти оценки были получены обычным МНК для регрессии на исходные лаговые переменные  . Для снижения эффекта мультиколлинеарности можно применять рекомендуемые для этих целей процедуры, но не все. Например, исключение некоторой части сильно коррелирующих между собой факторов здесь не применимо.
. Для снижения эффекта мультиколлинеарности можно применять рекомендуемые для этих целей процедуры, но не все. Например, исключение некоторой части сильно коррелирующих между собой факторов здесь не применимо.
4. АВТОРЕГРЕССИОННЫЕ ПРОЦЕССЫИ ИХ МОДЕЛИ
4.1. Стационарность
Рассмотренные в Главе 2 трендовые модели временных рядов строились в предположении, что изменения уровней временного ряда происходит по определенному закону, который можно записать в виде некоторой элементарной функции от времени. Функция подбиралась в соответствии с типом роста временного ряда. При таком подходе к построению модели статистические характеристики временного ряда не учитывались. В рассматриваемых здесь моделях авторегрессии динамика выражается не через функцию от времени, а через зависимость между текущими и предыдущими уровнями временного ряда. Такой подход требует, чтобы используемые для построения модели данные обладали определенным свойством, которое принято называть стационарностью.
Временной ряд называется стационарным, если он обладает постоянной средней и дисперсией, а ковариация зависит только от временного интервала между двумя отдельными наблюдениями. Если для исходного временного ряда не выполняется хотя бы одно из этих условий, то возникают проблемы с построением рассматриваемого здесь типа прогнозных моделей.
4.2. Модель авторегрессии
Принято считать, что если временной ряд характеризует процесс, при котором его текущее значение находится в линейной зависимости от предыдущих значений, то процесс называется авторегрессионным. Для таких процессов вводится понятие «порядок авторегрессии». Например, если текущее наблюдаемое значение является линейной функцией всего лишь одного значения непосредственно предшествующего наблюдения, то такой процесс называют авторегрессионным процессом первого порядка, его модель записывают в виде
 (4.1)
(4.1)
и обозначают AR (1). Это понятие легко обобщается на случай авторегрессии порядка n, т.е. AR (n). Например, модель процесса AR (3) может быть записана следующим образом:
 . (4.2)
. (4.2)
Уравнение (4.2) представляет собой многофакторную модель регрессии, в которой в качестве независимых переменных используются прошлые значения зависимой переменной. При построении таких моделей возникает вопрос определения степени автокорреляции временного ряда. Этот вопрос будет рассмотрен ниже.
4.3. Понятие интеграции
Построение авторегрессионной модели предполагает стационарность временного ряда, данные которого используются для оценки ее параметров. Причин приводящих к нарушению условий стационарности достаточно много. Различны и варианты нарушения этих условий. Чаще других нарушаются условия постоянства среднего и дисперсии. Рассмотрим случай, когда условия стационарности нарушаются наличием линейного тренда в поведении среднего. Если в среднем наблюдается тренд, то вычисляются первые разности


 , (4.3)
, (4.3)
в которых, как видно из выполненных преобразований, тренд отсутствует и делается попытка построения модели по временному ряду  . Если полученный временной ряд
. Если полученный временной ряд  стационарен, и для него можно построить авторегрессионные модели, то исходный ряд называется интегрированным рядом первого порядка и обозначается I (1). Если ряд из первых разностей не стационарен (например, случай квадратичного тренда) и для получения стационарного ряда требуется расчет разностей второго порядка
стационарен, и для него можно построить авторегрессионные модели, то исходный ряд называется интегрированным рядом первого порядка и обозначается I (1). Если ряд из первых разностей не стационарен (например, случай квадратичного тренда) и для получения стационарного ряда требуется расчет разностей второго порядка  , то исходный ряд называется интегрированным рядом второго порядка и обозначается I (2). Если же сам исходный ряд является стационарным и не требуется вычисление разностей, то такой ряд называется интегрированным рядом нулевого порядка или I (0).
, то исходный ряд называется интегрированным рядом второго порядка и обозначается I (2). Если же сам исходный ряд является стационарным и не требуется вычисление разностей, то такой ряд называется интегрированным рядом нулевого порядка или I (0).
Как отмечалась выше, стационарный временной ряд I (0) имеет конечную дисперсию. Кроме того, изменения запаздывающей переменной будут иметь только промежуточное влияние на временной ряд и, следовательно, коэффициенты автокорреляции будут постепенно убывать. Причем характер убывания таков, что сумма коэффициентов корреляции имеет конечный предел. Если же ряд I (1), то изменения будут иметь постоянный характер, а дисперсия такого ряда с течением времени возрастает до бесконечности.
Построение модели без учета порядка интегрированности временного ряда может привести к заметным искажениям и неправильным выводам.
Путем взятия разностей не всегда удается нестационарный ряд преобразовать в стационарный. Например, если временной ряд отражает динамику сезонного явления, то его преобразование к стационарному ряду осуществляется путем исключения сезонной компоненты, а не взятием разностей. Применение процедуры взятия разностей к нестационарному временному ряду, описываемому моделью
 ,
,  , (4.4)
, (4.4)
оказывается бесполезным, так как ряд из разностей
 (4.5)
(4.5)
продолжает оставаться нестационарным
Особо рассматриваются случаи построения моделей по временным рядам, в которых причиной нестационарности является неоднородность дисперсии.
4.4. Модели скользящей средней
Кроме авторегрессионных, при моделировании временных рядов используются модели скользящей средней. Сразу заметим, что рассматриваемые здесь модели не имеют ничего общего со схожим термином, относящимся к технике сглаживания данных.
Модель скользящей средней – это модель, в которой моделируемый показатель задается линейной функцией от прошлых ошибок, т.е. разностей между прошлыми фактическими наблюдениями и прошлыми смоделированными (рассчитанными по модели) значениями. Модель скользящей средней записывается в виде
 , (4.6)
, (4.6)
где
 . (4.7)
. (4.7)
Как правило, модели скользящей средней самостоятельно не используются, но между ними и моделями авторегрессии есть взаимосвязь, их совместное применение обеспечивает более компактное представление рассматриваемых здесь моделей.
4.5. Авторегрессионные модели скользящей средней
Для временных рядов разработаны модели, в которых комбинируется авторегрессионное представление временного ряда с моделью скользящей средней. Эти модели принято называть авторегрессионными моделями скользящей средней и обозначать ARMA (p, q), где p – количество запаздывающих переменных в авторегрессионном процессе, а q – количество переменных в модели скользящей средней. Например, модель ARMA (3, 2) может быть записана следующим образом:
 , (4.8)
, (4.8)
где  – ненаблюдаемая ошибка в данном уравнении.
– ненаблюдаемая ошибка в данном уравнении.
4.6. Авторегрессионные интегрированные модели скользящей средней
Авторегрессионные интегрированные модели скользящей средней (ARIMA) отличаются от моделей ARMA тем, что перед их построением определяется порядок разности между уровнями временного ряда для получения в случае необходимости стационарного ряда. Процесс, порождаемый моделями ARIMA, характеризуется тремя параметрами: p – порядок авторегрессии; d – порядок предварительно определяемых разностей; q – порядок скользящей средней в модели. Таким образом, ARIMA, включая в себя описания процессов авторегрессии, скользящего среднего и интегрирования, является обобщением, позволяющим многие динамические процессы рассматривать как процессы ARIMA.
При построении моделей ARIMA очень важно в моделируемом временном ряде выделить эти три составляющие для того, чтобы определить структуру моделируемого процесса. С этой целью построение модели осуществляют в несколько этапов. На первом этапе ведется расчет разностей для получения стационарного ряда. Затем для полученного стационарного ряда пытаются построить модель ARMA. Фактически выделение этих составляющих позволяет разбить все динамические ряды на классы со специфическими свойствами.
Например, рассмотрим абсолютно случайный процесс, в котором  зависит только от среднего уровня ряда и ошибки, т.е.
зависит только от среднего уровня ряда и ошибки, т.е.
 , (4.9)
, (4.9)
где  (independent identically distributed) независимые, одинаково распределенные с нулевым средним и дисперсией
(independent identically distributed) независимые, одинаково распределенные с нулевым средним и дисперсией  ошибки.
ошибки.
В этом процессе не наблюдается зависимость от прошлых значений , в нем не фигурируют разности  , и нет зависимости от ошибок в прошлых периодах. Поэтому этот процесс классифицируется как процесс ARIMA (0, 0, 0).
, и нет зависимости от ошибок в прошлых периодах. Поэтому этот процесс классифицируется как процесс ARIMA (0, 0, 0).
Если процесс состоит только из авторегрессионной составляющей, то его модель может быть записана следующим образом:
 , , (4.10)
, , (4.10)
где  и
и  – случайная составляющая.
– случайная составляющая.
Рассматриваемый процесс фактически является AR (1) процессом и классифицируется как процесс ARIMA (1, 0, 0).
В случае, когда  , процесс не является стационарным и только с помощью вычисления разностей может быть полностью трансформирован в стационарный. Модель такого процесса представима в виде
, процесс не является стационарным и только с помощью вычисления разностей может быть полностью трансформирован в стационарный. Модель такого процесса представима в виде
 , , (4.11)
, , (4.11)
а сам процесс классифицируется как ARIMA (0, 1, 0).
Если единственной составляющей процесса является скользящая средняя, то мы имеем дело с процессом ARIMA (0, 0, 1), модель которого отражает зависимость от значений ошибки и записывается в виде:
 , . (4.12)
, . (4.12)
В случае, когда процесс комбинируется из авторегрессионной составляющей и скользящей средней, его модель записывается следующим образом:
 , (4.13)
, (4.13)
и классифицируется как ARIMA ( 1, 0, 1).
4.7. Коэффициент автокорреляции и проверка его значимости
Степень автокоррелируемости процессов измеряется коэффициентом автокорреляции, который устанавливает корреляционную связь между текущими и прошлыми наблюдениями временного ряда и рассчитывается по формуле
 , (4.14)
, (4.14)
где – количество лагов (запаздываний). В соответствии с этой формулой коэффициент автокорреляции первого порядка рассчитывается при  , второго порядка – при
, второго порядка – при  и т.д. При построении модели определяются коэффициенты автокорреляции всех порядков, и затем проводится статистическая проверка их значимости, чтобы установить с какими лагами следует включать в модель переменные.
и т.д. При построении модели определяются коэффициенты автокорреляции всех порядков, и затем проводится статистическая проверка их значимости, чтобы установить с какими лагами следует включать в модель переменные.
Значимость коэффициентов автокорреляции принято проверять с помощью двух критериев: критерия стандартной ошибки и Q -критерия Бокса –Пирса.
Первый критерий используется для проверки значимости отдельного коэффициента автокорреляции. С его помощью удается выявить среди запаздывающих переменных те, которые необходимо включить в модель. Второй критерий позволяет сделать вывод о