При оценке параметров уравнения регрессии применяется метод наименьших квадратов (МНК). При этом делаются определенные предпосылки относительно случайной составляющей  . В модели
. В модели
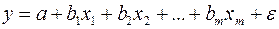
случайная составляющая представляет собой ненаблюдаемую величину. После того как произведена оценка параметров модели, рассчитывая разности фактических и теоретических значений результативного признака  , можно определить оценки случайной составляющей
, можно определить оценки случайной составляющей  . Поскольку они не являются реальными случайными остатками, их можно считать некоторой выборочной реализацией неизвестного остатка заданного уравнения, т.е.
. Поскольку они не являются реальными случайными остатками, их можно считать некоторой выборочной реализацией неизвестного остатка заданного уравнения, т.е.  .
.
При изменении спецификации модели, добавлении в нее новых наблюдений выборочные оценки остатков могут меняться. Поэтому в задачу регрессионного анализа входит не только построение самой модели, но и исследование случайных отклонений , т.е. остаточных величин.
При использовании критериев Фишера и Стьюдента делаются предположения относительно поведения остатков – остатки представляют собой независимые случайные величины и их среднее значение равно 0; они имеют одинаковую (постоянную) дисперсию и подчиняются нормальному распределению.
Статистические проверки параметров регрессии, показателей корреляции основаны на непроверяемых предпосылках распределения случайной составляющей . Они носят лишь предварительный характер. После построения уравнения регрессии проводится проверка наличия у оценок (случайных остатков) тех свойств, которые предполагались. Связано это с тем, что оценки параметров регрессии должны отвечать определенным критериям. Они должны быть несмещенными, состоятельными и эффективными. Эти свойства оценок, полученных по МНК, имеют чрезвычайно важное практическое значение в использовании результатов регрессии и корреляции.
Несмещенность оценки означает, что математическое ожидание остатков равно нулю. Если оценки обладают свойством несмещенности, то их можно сравнивать по разным исследованиям.
Оценки считаются эффективными, если они характеризуются наименьшей дисперсией. В практических исследованиях это означает возможность перехода от точечного оценивания к интервальному.
Состоятельность оценок характеризует увеличение их точности с увеличением объема выборки. Большой практический интерес представляют те результаты регрессии, для которых доверительный интервал ожидаемого значения параметра регрессии  имеет предел значений вероятности, равный единице. Иными словами, вероятность получения оценки на заданном расстоянии от истинного значения параметра близка к единице.
имеет предел значений вероятности, равный единице. Иными словами, вероятность получения оценки на заданном расстоянии от истинного значения параметра близка к единице.
Указанные критерии оценок (несмещенность, состоятельность и эффективность) обязательно учитываются при разных способах оценивания. Метод наименьших квадратов строит оценки регрессии на основе минимизации суммы квадратов остатков. Поэтому очень важно исследовать поведение остаточных величин регрессии . Условия, необходимые для получения несмещенных, состоятельных и эффективных оценок, представляют собой предпосылки МНК, соблюдение которых желательно для получения достоверных результатов регрессии.
Исследования остатков предполагают проверку наличия следующих пяти предпосылок МНК:
1) случайный характер остатков;
2) нулевая средняя величина остатков, не зависящая от 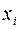 ;
;
3) гомоскедастичность – дисперсия каждого отклонения , одинакова для всех значений 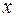 ;
;
4) отсутствие автокорреляции остатков – значения остатков распределены независимо друг от друга;
5) остатки подчиняются нормальному распределению.
Если распределение случайных остатков не соответствует некоторым предпосылкам МНК, то следует корректировать модель.
Прежде всего, проверяется случайный характер остатков – первая предпосылка МНК. С этой целью стоится график зависимости остатков от теоретических значений результативного признака (рис. 2.1). Если на графике получена горизонтальная полоса, то остатки представляют собой случайные величины и МНК оправдан, теоретические значения  хорошо аппроксимируют фактические значения .
хорошо аппроксимируют фактические значения .

Рис. 2.1. Зависимость случайных остатков от теоретических значений .
Возможны следующие случаи, если зависит от то:
1) остатки не случайны (рис. 2.2а);
2) остатки не имеют постоянной дисперсии (рис. 2.2б);
3) остатки носят систематический характер (рис. 2.2в).


а б

в
Рис. 2.2. Зависимость случайных остатков от теоретических значений .
В этих случаях необходимо либо применять другую функцию, либо вводить дополнительную информацию и заново строить уравнение регрессии до тех пор, пока остатки не будут случайными величинами.
Вторая предпосылка МНК относительно нулевой средней величины остатков означает, что  . Это выполнимо для линейных моделей и моделей, нелинейных относительно включаемых переменных.
. Это выполнимо для линейных моделей и моделей, нелинейных относительно включаемых переменных.
Вместе с тем, несмещенность оценок коэффициентов регрессии, полученных МНК, зависит от независимости случайных остатков и величин , что также исследуется в рамках соблюдения второй предпосылки МНК. С этой целью наряду с изложенным графиком зависимости остатков от теоретических значений результативного признака строится график зависимости случайных остатков от факторов, включенных в регрессию  (рис. 2.3).
(рис. 2.3).

Рис. 2.3. Зависимость величины остатков от величины фактора .
Если остатки на графике расположены в виде горизонтальной полосы, то они независимы от значений . Если же график показывает наличие зависимости и , то модель неадекватна. Причины неадекватности могут быть разные. Возможно, что нарушена третья предпосылка МНК и дисперсия остатков не постоянна для каждого значения фактора . Может быть неправильна спецификация модели и в нее необходимо ввести дополнительные члены от , например  . Скопление точек в определенных участках значений фактора говорит о наличии систематической погрешности модели.
. Скопление точек в определенных участках значений фактора говорит о наличии систематической погрешности модели.
Предпосылка о нормальном распределении остатков позволяет проводить проверку параметров регрессии и корреляции с помощью  - и
- и  -критериев. Вместе с тем, оценки регрессии, найденные с применением МНК, обладают хорошими свойствами даже при отсутствии нормального распределения остатков, т.е. при нарушении пятой предпосылки МНК.
-критериев. Вместе с тем, оценки регрессии, найденные с применением МНК, обладают хорошими свойствами даже при отсутствии нормального распределения остатков, т.е. при нарушении пятой предпосылки МНК.
Совершенно необходимым для получения по МНК состоятельных оценок параметров регрессии является соблюдение третьей и четвертой предпосылок.
В соответствии с третьей предпосылкой МНК требуется, чтобы дисперсия остатков была гомоскедастичной. Это значит, что для каждого значения фактора остатки имеют одинаковую дисперсию. Если это условие применения МНК не соблюдается, то имеет место гетероскедастичность. Наличие гетероскедастичности можно наглядно видеть из поля корреляции (рис. 2.4).


а б

в
Рис. 2.4. Примеры гетероскедастичности.
На рис. 2.4 изображено: а – дисперсия остатков растет по мере увеличения ; б – дисперсия остатков достигает максимальной величины при средних значениях переменной и уменьшается при минимальных и максимальных значениях ; в – максимальная дисперсия остатков при малых значениях и дисперсия остатков однородна по мере увеличения значений .
Наличие гомоскедастичности или гетероскедастичности можно видеть и по рассмотренному выше графику зависимости остатков от теоретических значений результативного признака . Так, для рис. 2.4а зависимость остатков от представлена на рис. 2.5.

Рис. 2.5. Гетероскедастичность: большая дисперсия для больших значений .
Соответственно для зависимости, изображенной на полях корреляции рис. 2.4б и 2.4в гетероскедастичность остатков представлена на рис. 2.6 и 2.7.

Рис. 2.6. Гетероскедастичность, соответствующая полю корреляции на рис. 2.4б.

Рис. 2.7. Гетероскедастичность, соответствующая полю корреляции на рис. 2.4в.
Для множественной регрессии данный вид графиков является наиболее приемлемым визуальным способом изучения гомо- и гетероскедастичности.
При построении регрессионных моделей чрезвычайно важно соблюдение четвертой предпосылки МНК – отсутствие автокорреляции остатков, т.е. значения остатков , распределены независимо друг от друга. Автокорреляция остатков означает наличие корреляции между остатками текущих и предыдущих (последующих) наблюдений[5]. Коэффициент корреляции между и  , где – остатки текущих наблюдений, – остатки предыдущих наблюдений (например,
, где – остатки текущих наблюдений, – остатки предыдущих наблюдений (например,  ), может быть определен как
), может быть определен как
 ,
,
т.е. по обычной формуле линейного коэффициента корреляции. Если этот коэффициент окажется существенно отличным от нуля, то остатки автокоррелированы и функция плотности вероятности  зависит от
зависит от  -й точки наблюдения и от распределения значений остатков в других точках наблюдения.
-й точки наблюдения и от распределения значений остатков в других точках наблюдения.
Отсутствие автокорреляции остаточных величин обеспечивает состоятельность и эффективность оценок коэффициентов регрессии. Особенно актуально соблюдение данной предпосылки МНК при построении регрессионных моделей по рядам динамики, где ввиду наличия тенденции последующие уровни динамического ряда, как правило, зависят от своих предыдущих уровней.
При несоблюдении основных предпосылок МНК приходится корректировать модель, изменяя ее спецификацию, добавлять (исключать) некоторые факторы, преобразовывать исходные данные для того, чтобы получить оценки коэффициентов регрессии, которые обладают свойством несмещенности, имеют меньшее значение дисперсии остатков и обеспечивают в связи с этим более эффективную статистическую проверку значимости параметров регрессии.
2.5. Обобщенный метод наименьших квадратов (ОМНК)
При нарушении гомоскедастичности и наличии автокорреляции ошибок рекомендуется традиционный метод наименьших квадратов (известный в английской терминологии как метод OLS – Ordinary Least Squares) заменять обобщенным методом, т.е. методом GLS (Generalized Least Squares).
Обобщенный метод наименьших квадратов применяется к преобразованным данным и позволяет получать оценки, которые обладают не только свойством несмещенности, но и имеют меньшие выборочные дисперсии. Остановимся на использовании ОМНК для корректировки гетероскедастичности.
Как и раньше, будем предполагать, что среднее значение остаточных величин равно нулю. А вот дисперсия их не остается неизменной для разных значений фактора, а пропорциональна величине  , т.е.
, т.е.
 ,
,
где  – дисперсия ошибки при конкретном
– дисперсия ошибки при конкретном  -м значении фактора;
-м значении фактора;  – постоянная дисперсия ошибки при соблюдении предпосылки о гомоскедастичности остатков; – коэффициент пропорциональности, меняющийся с изменением величины фактора, что и обусловливает неоднородность дисперсии.
– постоянная дисперсия ошибки при соблюдении предпосылки о гомоскедастичности остатков; – коэффициент пропорциональности, меняющийся с изменением величины фактора, что и обусловливает неоднородность дисперсии.
При этом предполагается, что неизвестна, а в отношении величин выдвигаются определенные гипотезы, характеризующие структуру гетероскедастичности.
В общем виде для уравнения  при модель примет вид:
при модель примет вид:  . В ней остаточные величины гетероскедастичны. Предполагая в них отсутствие автокорреляции, можно перейти к уравнению с гомоскедастичными остатками, поделив все переменные, зафиксированные в ходе -го наблюдения, на
. В ней остаточные величины гетероскедастичны. Предполагая в них отсутствие автокорреляции, можно перейти к уравнению с гомоскедастичными остатками, поделив все переменные, зафиксированные в ходе -го наблюдения, на  . Тогда дисперсия остатков будет величиной постоянной, т. е.
. Тогда дисперсия остатков будет величиной постоянной, т. е.  .
.
Иными словами, от регрессии по мы перейдем к регрессии на новых переменных:  и
и 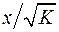 . Уравнение регрессии примет вид:
. Уравнение регрессии примет вид:
 ,
,
а исходные данные для данного уравнения будут иметь вид:
 ,
,  .
.
По отношению к обычной регрессии уравнение с новыми, преобразованными переменными представляет собой взвешенную регрессию, в которой переменные и взяты с весами  .
.
Оценка параметров нового уравнения с преобразованными переменными приводит к взвешенному методу наименьших квадратов, для которого необходимо минимизировать сумму квадратов отклонений вида
 .
.
Соответственно получим следующую систему нормальных уравнений:

Если преобразованные переменные и взять в отклонениях от средних уровней, то коэффициент регрессии  можно определить как
можно определить как
 .
.
При обычном применении метода наименьших квадратов к уравнению линейной регрессии для переменных в отклонениях от средних уровней коэффициент регрессии определяется по формуле:
 .
.
Как видим, при использовании обобщенного МНК с целью корректировки гетероскедастичности коэффициент регрессии представляет собой взвешенную величину по отношению к обычному МНК с весом  .
.
Аналогичный подход возможен не только для уравнения парной, но и для множественной регрессии. Предположим, что рассматривается модель вида
 ,
,
для которой дисперсия остаточных величин оказалась пропорциональна  . представляет собой коэффициент пропорциональности, принимающий различные значения для соответствующих значений факторов
. представляет собой коэффициент пропорциональности, принимающий различные значения для соответствующих значений факторов  и
и  . Ввиду того, что
. Ввиду того, что
 ,
,
рассматриваемая модель примет вид
 ,
,
где ошибки гетероскедастичны.
Для того чтобы получить уравнение, где остатки гомоскедастичны, перейдем к новым преобразованным переменным, разделив все члены исходного уравнения на коэффициент пропорциональности  . Уравнение с преобразованными переменными составит
. Уравнение с преобразованными переменными составит
 .
.
Это уравнение не содержит свободного члена. Вместе с тем, найдя переменные в новом преобразованном виде и применяя обычный МНК к ним, получим иную спецификацию модели:
 .
.
Параметры такой модели зависят от концепции, принятой для коэффициента пропорциональности . В эконометрических исследованиях довольно часто выдвигается гипотеза, что остатки пропорциональны значениям фактора. Так, если в уравнении

предположить, что  , т.е.
, т.е.  и
и  , то обобщенный МНК предполагает оценку параметров следующего трансформированного уравнения:
, то обобщенный МНК предполагает оценку параметров следующего трансформированного уравнения:
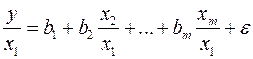 .
.
Применение в этом случае обобщенного МНК приводит к тому, что наблюдения с меньшими значениями преобразованных переменных  имеют при определении параметров регрессии относительно больший вес, чем с первоначальными переменными. Вместе с тем, следует иметь в виду, что новые преобразованные переменные получают новое экономическое содержание и их регрессия имеет иной смысл, чем регрессия по исходным данным.
имеют при определении параметров регрессии относительно больший вес, чем с первоначальными переменными. Вместе с тем, следует иметь в виду, что новые преобразованные переменные получают новое экономическое содержание и их регрессия имеет иной смысл, чем регрессия по исходным данным.
Пример. Пусть – издержки производства, – объем продукции, – основные производственные фонды, 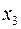 – численность работников, тогда уравнение
– численность работников, тогда уравнение

является моделью издержек производства с объемными факторами. Предполагая, что пропорциональна квадрату численности работников , мы получим в качестве результативного признака затраты на одного работника  , а в качестве факторов следующие показатели: производительность труда
, а в качестве факторов следующие показатели: производительность труда  и фондовооруженность труда
и фондовооруженность труда  . Соответственно трансформированная модель примет вид
. Соответственно трансформированная модель примет вид
 ,
,
где параметры  ,
,  ,
,  численно не совпадают с аналогичными параметрами предыдущей модели. Кроме этого, коэффициенты регрессии меняют экономическое содержание: из показателей силы связи, характеризующих среднее абсолютное изменение издержек производства с изменением абсолютной величины соответствующего фактора на единицу, они фиксируют при обобщенном МНК среднее изменение затрат на работника; с изменением производительности труда на единицу при неизменном уровне фовдовооруженности труда; и с изменением фондовооруженности труда на единицу при неизменном уровне производительности труда.
численно не совпадают с аналогичными параметрами предыдущей модели. Кроме этого, коэффициенты регрессии меняют экономическое содержание: из показателей силы связи, характеризующих среднее абсолютное изменение издержек производства с изменением абсолютной величины соответствующего фактора на единицу, они фиксируют при обобщенном МНК среднее изменение затрат на работника; с изменением производительности труда на единицу при неизменном уровне фовдовооруженности труда; и с изменением фондовооруженности труда на единицу при неизменном уровне производительности труда.
Если предположить, что в модели с первоначальными переменными дисперсия остатков пропорциональна квадрату объема продукции,  , можно перейти к уравнению регрессии вида
, можно перейти к уравнению регрессии вида
 .
.
В нем новые переменные:  – затраты на единицу (или на 1 руб. продукции),
– затраты на единицу (или на 1 руб. продукции),  – фондоемкость продукции,
– фондоемкость продукции,  – трудоемкость продукции.
– трудоемкость продукции.
Гипотеза о пропорциональности остатков величине фактора может иметь реальное основание: при обработке недостаточно однородной совокупности, включающей как крупные, так и мелкие предприятия, большим объемным значениям фактора может соответствовать большая дисперсия результативного признака и большая дисперсия остаточных величин.
При наличии одной объясняющей переменной гипотеза  трансформирует линейное уравнение
трансформирует линейное уравнение
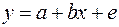
в уравнение
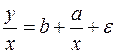 ,
,
в котором параметры 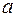 и поменялись местами, константа стала коэффициентом наклона линии регрессии, а коэффициент регрессии – свободным членом.
и поменялись местами, константа стала коэффициентом наклона линии регрессии, а коэффициент регрессии – свободным членом.
Пример. Рассматривая зависимость сбережений от дохода , по первоначальным данным было получено уравнение регрессии
 .
.
Применяя обобщенный МНК к данной модели в предположении, что ошибки пропорциональны доходу, было получено уравнение для преобразованных данных:
 .
.
Коэффициент регрессии первого уравнения сравнивают со свободным членом второго уравнения, т.е. 0,1178 и 0,1026 – оценки параметра зависимости сбережений от дохода.
Переход к относительным величинам существенно снижает вариацию фактора и соответственно уменьшает дисперсию ошибки. Он представляет собой наиболее простой случай учета гетероскедастичности в регрессионных моделях с помощью обобщенного МНК. Процесс перехода к относительным величинам может быть осложнен выдвижением иных гипотез о пропорциональности ошибок относительно включенных в модель факторов. Использование той или иной гипотезы предполагает специальные исследования остаточных величин для соответствующих регрессионных моделей. Применение обобщенного МНК позволяет получить оценки параметров модели, обладающие меньшей дисперсией.
2.6. Регрессионные модели с переменной структурой
(фиктивные переменные)
До сих пор в качестве факторов рассматривались экономические переменные, принимающие количественные значения в некотором интервале. Вместе с тем может оказаться необходимым включить в модель фактор, имеющий два или более качественных уровней. Это могут быть разного рода атрибутивные признаки, такие, например, как профессия, пол, образование, климатические условия, принадлежность к определенному региону. Чтобы ввести такие переменные в регрессионную модель, им должны быть присвоены те или иные цифровые метки, т.е. качественные переменные преобразованы в количественные. Такого вида сконструированные переменные в эконометрике принято называть фиктивными переменными.
Рассмотрим применение фиктивных переменных для функции спроса. Предположим, что по группе лиц мужского и женского пола изучается линейная зависимость потребления кофе от цены. В общем виде для совокупности обследуемых уравнение регрессии имеет вид:
 ,
,
где – количество потребляемого кофе; – цена.
Аналогичные уравнения могут быть найдены отдельно для лиц мужского пола:  и женского пола:
и женского пола:  .
.
Различия в потреблении кофе проявятся в различии средних  и
и  . Вместе с тем сила влияния на может быть одинаковой, т.е.
. Вместе с тем сила влияния на может быть одинаковой, т.е.  . В этом случае возможно построение общего уравнения регрессии с включением в него фактора «пол» в виде фиктивной переменной. Объединяя уравнения
. В этом случае возможно построение общего уравнения регрессии с включением в него фактора «пол» в виде фиктивной переменной. Объединяя уравнения  и
и  и, вводя фиктивные переменные, можно прийти к следующему выражению:
и, вводя фиктивные переменные, можно прийти к следующему выражению:
 ,
,
где  и
и  – фиктивные переменные, принимающие значения:
– фиктивные переменные, принимающие значения:


В общем уравнении регрессии зависимая переменная рассматривается как функция не только цены но и пола  . Переменная
. Переменная  рассматривается как дихотомическая переменная, принимающая всего два значения: 1 и 0. При этом когда
рассматривается как дихотомическая переменная, принимающая всего два значения: 1 и 0. При этом когда  , то
, то  , и наоборот.
, и наоборот.
Для лиц мужского пола, когда и , объединенное уравнение регрессии составит:  , а для лиц женского пола, когда
, а для лиц женского пола, когда 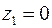 и
и  :
:  . Иными словами, различия в потреблении для лиц мужского и женского пола вызваны различиями свободных членов уравнения регрессии:
. Иными словами, различия в потреблении для лиц мужского и женского пола вызваны различиями свободных членов уравнения регрессии:  . Параметр является общим для всей совокупности лиц, как для мужчин, так и для женщин.
. Параметр является общим для всей совокупности лиц, как для мужчин, так и для женщин.
Однако при введении двух фиктивных переменных и в модель применение МНК для оценивания параметров  и
и  приведет к вырожденной матрице исходных данных, а следовательно, и к невозможности получения их оценок. Объясняется это тем, что при использовании МНК в данном уравнении появляется свободный член, т.е. уравнение примет вид
приведет к вырожденной матрице исходных данных, а следовательно, и к невозможности получения их оценок. Объясняется это тем, что при использовании МНК в данном уравнении появляется свободный член, т.е. уравнение примет вид
 .
.
Предполагая при параметре  независимую переменную, равную 1, имеем следующую матрицу исходных данных:
независимую переменную, равную 1, имеем следующую матрицу исходных данных:
 .
.
В рассматриваемой матрице существует линейная зависимость между первым, вторым и третьим столбцами: первый равен сумме второго и третьего столбцов. Поэтому матрица исходных факторов вырождена. Выходом из создавшегося затруднения может явиться переход к уравнениям

или
 ,
,
т.е. каждое уравнение включает только одну фиктивную переменную или .
Предположим, что определено уравнение
,
где принимает значения 1 для мужчин и 0 для женщин.
Теоретические значения размера потребления кофе для мужчин будут получены из уравнения
 .
.
Для женщин соответствующие значения получим из уравнения
 .
.
Сопоставляя эти результаты, видим, что различия в уровне потребления мужчин и женщин состоят в различии свободных членов данных уравнений: – для женщин и  – для мужчин.
– для мужчин.
Теперь качественный фактор принимает только два состояния, которым соответствуют значения 1 и 0. Если же число градаций качественного признака-фактора превышает два, то в модель вводится несколько фиктивных переменных, число которых должно быть меньше числа качественных градаций. Только при соблюдении этого положения матрица исходных фиктивных переменных не будет линейно зависима и возможна оценка параметров модели.
Пример. Проанализируем зависимость цены двухкомнатной квартиры от ее полезной площади. При этом в модель могут быть введены фиктивные переменные, отражающие тип дома: «хрущевка», панельный, кирпичный.
При использовании трех категорий домов вводятся две фиктивные переменные: и . Пусть переменная принимает значение 1 для панельного дома и 0 для всех остальных типов домов; переменная принимает значение 1 для кирпичных домов и 0 для остальных; тогда переменные и принимают значения 0 для домов типа «хрущевки».
Предположим, что уравнение регрессии с фиктивными переменными составило:
 .
.
Частные уравнения регрессии для отдельных типов домов, свидетельствуя о наиболее высоких ценах квартир в панельных домах, будут иметь следующий вид: «хрущевки» –  ; панельные –
; панельные –  ; кирпичные –
; кирпичные –  .
.
Параметры при фиктивных переменных и представляют собой разность между средним уровнем результативного признака для соответствующей группы и базовой группы. В рассматриваемом примере за базу сравнения цены взяты дома «хрущевки», для которых  . Параметр при , равный 2200, означает, что при одной и той же полезной площади квартиры цена ее в панельных домах в среднем на 2200 долл. США выше, чем в «хрущевках». Соответственно параметр при показывает, что в кирпичных домах цена выше в среднем на 1600 долл. при неизменной величине полезной площади по сравнению с указанным типом домов.
. Параметр при , равный 2200, означает, что при одной и той же полезной площади квартиры цена ее в панельных домах в среднем на 2200 долл. США выше, чем в «хрущевках». Соответственно параметр при показывает, что в кирпичных домах цена выше в среднем на 1600 долл. при неизменной величине полезной площади по сравнению с указанным типом домов.
В отдельных случаях может оказаться необходимым введение двух и более групп фиктивных переменных, т.е. двух и более качественных факторов, каждый из которых может иметь несколько градаций. Например, при изучении потребления некоторого товара наряду с факторами, имеющими количественное выражение (цена, доход на одного члена семьи, цена на взаимозаменяемые товары и др.), учитываются и качественные факторы. С их помощью оцениваются различия в потреблении отдельных социальных групп населения, дифференциация в потреблении по полу, национальному составу и др. При построении такой модели из каждой группы фиктивных переменных следует исключить по одной переменной. Так, если модель будет включать три социальные группы, три возрастные категории и ряд экономических переменных, то она примет вид:
 ,
,
где – потребление;


 – экономические (количественные) переменные.
– экономические (количественные) переменные.
До сих пор мы рассматривали фиктивные переменные как факторы, которые используются в регрессионной модели наряду с количественными переменными. Вместе с тем возможна регрессия только на фиктивных переменных. Например, изучается дифференциация заработной платы рабочих высокой квалификации по регионам страны. Модель заработной платы может иметь вид:
 ,
,
где – средняя заработная плата рабочих высокой квалификации по отдельным предприятиям;


………………………………………………………………………..

Поскольку последний район, указанный в модели, обозначен  , то в исследование включено
, то в исследование включено 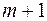 район.
район.
Мы рассмотрели модели с фиктивными переменными, в которых последние выступают факторами. Может возникнуть необходимость построить модель, в которой дихотомический признак, т.е. признак, который может принимать только два значения, играет роль результата. Подобного вида модели применяются, например, при обработке данных социологических опросов. В качестве зависимой переменной рассматриваются ответы на вопросы, данные в альтернативной форме: «да» или «нет». Поэтому