functuon1();
}
{
Using namespace NameSpase2
functuon2();
}
Однако можно в разных пространствах имен определить одну и туже функцию, или точнее функции с одинаковым именем
{
Using namespace NameSpase1
functuon1();
}
{
Using namespace NameSpase2
functuon1();
}
Нужно только следить за тем, чтобы в одно и тоже время использовались разные пространства имен.
Если директива using находится в начале файла, как это делалось до сих пор, то ее действие распространяется на весь файл.
Директиву using часто используют в блоке тела определения функции.
Как пользоваться пространством имен, вероятно, понятно. Вопрос в том, как создать пространство имен? Ответ очень простой. Как всегда. Просто нужно объявить это пространство.
namespace Имя_пространства_имен
Если объявление пространств имен стоит перед некоторым блоком, то этот блок, точнее объявленные в нем идентификаторы, будут помещены в указанное пространство имен. Приведем пример.
//Начнем необычно, с описания функции
int sum(int x, int y){return x+y;}
/*имя функции sum и имена переменных x и y хранятся в глобальном пространстве имен*/
#include <iostream>
using namespace std; /*далее используется пространство имен std */
/*прототип функции greeting(), которую опишем позднее поместим в пространство имен NameSpase1 */
namespace NameSpase1 // объявляется пространство имен NameSpase1
{
void greeting();
/*таким образом, созданное пространство имен содержит только одну функцию */
}
Namespace NameSpase2
{
void greeting(); /*это пространство имен содержит функцию с тем же
именем*/
}
void big_greeting(); /*эта функция не попадает ни в одно из созданных подпространств,т.е. принадлежит пространству имен std */
Int main()
{
{
using namespace NameSpase2;
/*в этом блоке используются имена, определенные в пространстве имен NameSpase2, std и в глобальном пространстве имен */
greeting();
}
{
using namespace NameSpase1;
/*в этом блоке используются имена, определенные в пространстве имен NameSpase1, std и в глобальном пространстве имен */
greeting();
}
/*начиная со следующей строки, используются только те определения которые заданы в пространстве имен std и глобальном пространстве имен */
big_greeting();
cout<<endl<<sum(10,15)<<endl;
char w;
cin>>w;
return 0;
}
//ОПРЕДЕЛЕНИЕ ФУНКЦИЙ
/*определение функции greeting() поместим в пространство имен NameSpase1 */
Namespace NameSpase1
{ //открывается блок пространста имен NameSpase1
Void greeting()
{
cout<<"Privet1"<<endl; //функция содержит только один оператор
}
} //закрывается блок пространста имен NameSpase1
/*определение функции greeting() поместим в пространство имен NameSpase2 */
Namespace NameSpase2
{ //открывается блок пространста имен NameSpase2
Void greeting()
{
cout<<"Privet2"<<endl; //эта функция тоже содержит один оператор
}
} //закрывается блок пространста имен NameSpase2
void big_greeting() /* определение данной функции не принадлежит ни одному из созданных пространств имен, следовательно дальнейший код помещается в глобальное пространство имен */
{
cout<<"Big greeting";
}
В результате выполнения программы получим следующее

Как следует из рассмотренного примера, используя разные пространства имен можно вызывать разные функции с одинаковыми именами. Областью действия, или как говорят областью видимости директории using является код расположенный между этой директорией и концом блока в котором она находится. Если директория using находится за пределами всех блоков, то она применяется ко всей части файла, следующего после нее. Примером тому может являться using namespace std;
Теперь обратимся к так называемому квалифицированию пространств имен. Предположим, что в нашем распоряжении имеется два пространства имен. Пусть это будут NameSpase1 и NameSpase2.В первом из них определена функция function1, во втором function2. Кроме того, в кажом из этих пространств определена функция My_function. Естественно, что это могут быть разные функции с одинаковым именем. Для работы с двумя функциями function1 и function2 нужно использовать две директивы
using namespace NameSpase1;
using namespace NameSpase2;
однако это приведет к противоречию, возникающему в связи с тем, что функция My_function будет определена дважды. В этом случае необходимо указать, что из пространства имен NameSpase1 будет использоваться только function1,а из пространства имен NameSpase2 будет использоваться только function2 и больше ничего. Это можно сделать используя оператор разрешения области видимости:: (двойное двоеточие).
using NameSpase1:: function1;
using NameSpase2:: function2;
Иначе говоря директива вида
using Пространство_имен:: Одно_имя;
представляет доступ к определению имени Одно_имя из пространства имен Пространство_имен, оставляя остальные имена недоступными. Выделение нужных имен из пространства имен, называется квалифицированием.
Теперь представим себе, что нужно всего лишь один или небольшое количество раз использовать определение имени function1 из пространства имен NameSpase1. В таком случае можно имя функции использовать вместе с именем пространства имен, т.е. вызывать функцию так NameSpase1::function1(). Такой способ относится не только к функциям, но и ко всем элементам, входящим в пространство имен. Например, в пространстве имен std определена структура struct1, которую нужно указать в виде параметра некоторой функции MyFunction. Тогда это может выглядеть следующим образом
int MyFunction(struct1);
Здесь мы не только выделили структуру из пространства имен, но и задали тип параметра struct1.
Наконец рассмотрим как ведут себя классы в пространстве имен. Для этого создадим какой-нибудь класс. Рассмотрим например задачу вычисления доходности ценных бумаг. Но сначала поясним, что такое доходность. Пусть, например, мы приобрели вексель по которому в определенный день векселедатель обязуется уплатить некую сумму, которая называется номиналом векселя, который мы обозначим буквой N. Естественно, что покупая вексель мы предполагаем получить доход, т.е. мы купили вексель по цене меньшей номинала (покупка с дисконтом), эту величину обозначим буквой C. Разность между номиналом и ценой покупки это и есть доход - D. Вообще говоря, понятие доход мало о чем говорит. Лучше говорить об относительном доходе, т.е. о доходе отнесенному к затратам (N-C)/C. Обычно относительный доход выражают в процентах

Эта величина показывает какой доход приносит каждый рубль вложенный в ценную бумагу. Но эта величина тоже не говорит об эффективности нашей денежной операции. Одно дело если мы получим такой доход через несколько дней и совсем другое дело если нужно ждать месяцы или даже годы. Иначе говоря, нужно знать какой относительный доход дает ценная бумага каждый день, т.е скорость приносимого дохода. Другими словами, величина
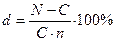 ,
,
где n количество дней с момента покупки до погашения, лучше всего характеризует эффективность сделки. Эту величину уже можно было бы назвать приведенной доходностью, или ежедневным относительным доходом. Однако в экономике принято интересоваться величиной относительного дохода за год, что позволяет сравнить доходность от ценных бумаг с банковским процентом. Поэтому формула расчета доходности выглядит так

Здесь число 365 означает количество дней в году.
Не знаю, поняли вы или нет все хитросплетения экономической мысли, но вполне очевидно одно – в году может быть 366 дней и тогда числитель полученной выше формулы будет иным. Вот именно на этом мы сыграем при исследовании классов в пространстве имен. Сейчас мы создадим два класса, отличающихся только числом дней в году.
#include <iostream>
using namespace std;
//вот первый класс
namespace ns365{ //объявление пространства имен ns365
class incom //объявление класса
{public:
double calculator(double nominal,double price,int days);
}; // конец объявления класса
/*описание функции incom, входящей в класс incom1 */
double incom::calculator(double nominal,double price,int days)
{return (((nominal-price)/price)*100*365/days);}
}
//объявление второго классас тем же именем
namespace ns366{ //объявление пространства имен ns366
class incom {
public:
double calculator(double nominal,double price,int days);
}; // конец объявления класса
/*описание функции incom, входящей в класс incom2 */
double incom::calculator(double nominal,double price,int days)
{return (((nominal-price)/price)*100*366/days);}
}
void main()
{
int daysYear=365, days;
double nominal, price,yield; // yield значит доходность
while (days>0) //организация бесконечного цикла
{
cout<<"Nominal=";
cin>>nominal;
cout<<"Price=";
cin>>price;
cout<<"Number days before repayment=";
cin>>days;
cout<<"Days in year=";
cin>>daysYear;
if (daysYear==365){
ns365::incom inc; //объявление объекта из пространства имен incom1
cout<<"yield="<<inc.calculator(nominal,price,days)<<"%"<<endl;
}
if (daysYear==366){
ns366::incom inc; //объявление объекта из другого
//пространства имен incom2
cout<<"yield="<<inc.calculator(nominal,price,days)<<"%"<<endl;
}
}
}
В данном примере мы создали два практически одинаковых класса. У них одинаковые имена и более того они содержат одноименные функции. Но компьютер различает их благодаря тому, что они помещены в разные пространства имен.
Использование в программировании пространства имен представляет собой относительно новую технологию. Поэтому не все компиляторы поддерживают директиву using.
10. Строки
Сейчас мы будем рассматривать новый тип переменных, который называется строки. Строки или строковые значения мы неоднократно использовали, когда организовывали вывод сообщений на печать. Например:
cout<<"Привет!";
В данном случае текст, заключенный в двойные кавычки это и есть строка. Теперь вспомним, что базовые типы могут быть константами и переменными. Строка из рассмотренного примера похожа на константу, поскольку ее значение уже трудно изменить. Сразу возникает вопрос, а существуют ли такие строки, символы в которых могут изменяться? Ответ положительный: да, такие строки вполне можно сделать. Для этого просто нужно задать символьный массив элементы которого можно изменять. Например, объявим массив:
char myString[20]={'П','р','и','в','е','т'};
Здесь мы объявили массив, состоящий из 20 элементов, хотя использовали только 6. Важно отметить, что в отличие от числового массива, где неиспользованные позиции массива остаются неизменными (т.е. в них находится то, что осталось в памяти от предыдущей программы), неиспользованные символы в строковом массиве автоматически заполняются пробелами. Для символьных массивов существуют и другие исключения. Так для вывода на экран всей строки можно использовать оператор cout<<, а для ввода cin>> без указания на вывод каждого элемента массива. В последнем случае нужно иметь в виду, что все пробельные символы (пробелы и символы новой строки) пропускаются. Например, программа
#include <iostream>
using namespace std;
void main()
{
char myString[20]=”Privet{'P','r','i','v','e','t'}”; // объявление
// и инициализация массива
cout<< myString; // массив символов выводится не поэлементно,
// а как одна величина
}
позволяет получить на экране слово Privet. Причем курсор остановится сразу после последней буквы. Программа
#include <iostream>
using namespace std;
void main()
{
char myString[20]= ”Privet”;
{'P','r','i','v','e','t'};
for(int i=0;i<20;i++)
cout<< myString[i];
}
также выводит Privet, но курсор останавливается на 20-ой позиции. Все незанятые символами позиции заполняются пробелами.
Рассмотрим еще один пример с использованием оператора ввода.
#include <iostream>
using namespace std;
void main()
{
char a[100],b[100];
cout<<"Input anithing"<<endl;
cin>>a>>b;
cout<<a<<b<<"\nTHE END";
}
Результате выполнения программы следующий.: Сначала на экране появится сообщение
Input anithing
Мигающий курсор говорит о том, что выполняемая программа готова к вводу. После ввода какого-либо слова введите один или несколько побелов, нажмите Enter, что означает конец ввода в массив a, и теперь введите слово в массив b. В итоге получится нечто похожее
Слово1Слово2
THE END
Если вы хотите ввести текст на кириллице, то не забудьте подключить библиотеку windows.h и установить кодировку для ввода SetConsoleCP(1251) и вывода SetConsoleOutputCP(1251).
Этот пример показывает, что оператор ввода cin не учитывает символ пробела.
Попробуйте ввести через пробел два слова в один и тот же массив, и вы увидите, что второе слово в него не войдет. Это говорит о том, что пробел используется для каких то других целей. Действительно, пробел означает, что ввод в массив закончен.
Для ввода строк включающих пробелы используется функция getline(str,int), в которой первый аргумент это вводимая строка, а второй это целое число, указывающее максимальное количество вводимых символов, учитывая пробелы, но не переводы строк.
#include <iostream>
using namespace std;
void main()
{
char a[100];
cout<<"Input anithing"<<endl;
cin.getline(a,80); //количество вводимых символов ограничено
cout<<a<<"THE END";
В данном случае результат будет таков:
Input anithing
Вводятся отдельные слова через пробел. После нажатия на Enter на экране появится
Слово1 Слово2THE END
Если количество введенных символов превысит значение, указанное во втором аргументе функции getline то чтение прекращается. Строго говоря, количество вводимых символов даже на единицу меньше чем число во втором аргументе. Это объясняется тем, что последнюю позицию занимает так называемый нуль-символ, информирующий о конце строки, но об этом мы поговорим чуть позднее.
Вероятно, сейчас не вполне понятен вызов функции getline. О том, почему вызов осуществляется именно так, мы расскажем тогда, когда познакомимся с классами и потоками ввода-вывода.
Вернемся к первому примеру. Обратим внимание, что наше приветствие выводится без восклицательного знака. Исправим эту ошибку. С этой целью добавим оператор ввода элемента на 6-ой позиции, и с его помощью введем восклицательный знак.
#include <iostream>
using namespace std;
void main()
{
char myString[20]={'P','r','i','v','e','t'};”Privet”;
cout<< myString;
cin>>myString[6]; //Здесь нужно ввести восклицательный знак
cout<< myString;
}
Последний пример показывает, что элементы символьного массива можно изменять.
Символьный мМассив можно инициализировать при объявлении
char myString[20]="Privet";
В этом случае после последней буквы компилятор автоматически добавит символ '\0' означающий конец строки. Для рассмотренного примера это будет 6-я позиция. Этот символ используется во многих функциях работающих со строковыми переменными, поэтому это способ предпочтительнее. Однако следует иметь в виду, что если мы теперь введем восклицательный знак, то символ '\0' будет замещен знаком '!'. С другой стороны, если не удалить символ '\0', то все свободные элементы массива будут недоступны. Например, после инициализации можно заменить любой символ массива с myString[0] до myString[5],но начиная с myString[7] до myString[20] элементы массива недоступны. Недоступность означает, что эти символы невозможно прочитать.
Строковые значения и строковые переменные не похожи на значения и переменные других типов, поэтому обычные операторы с ними не работают. Например, для строковых переменных знак присвоения работает только при объявлении переменной, т.е. код
char myString[10];
myString="Privet!";
является неверным в силу того, что myString это массив и, следовательно, указанный код должен выглядеть так:
char myString[10];
myString[0]='P';
myString[1]='r';
myString[2]='i';
myString[3]='v';
myString[4]='e';
myString[5]='t';
myString[6]='!';
myString[7]='\0';
Хотя ввод с клавиатуры можно выполнить, т.е.
#include<iostream>
using namespace std;
void main(){
char myString[20];
cin>>myString;
cout<<myString;
}
Наиболее распространенной ошибкой при работе со строками является применение оператора равенства «==», который не справедлив для сравнения равенства двух строк, ведь строка это массив. Строки можно сравнивать лишь поэлементно.
Для работы со строками используются библиотечные функции, некоторые из которых приведены в таблице.
| Функция | Описание | Замечания |
| strcpy(str1,str2) | Копирует str2 в str1 | Не проверяет достаточно ли места в str1 для копирования |
| strcat(str1,str2) | Присоединяет str2 к окончанию str1 | Не проверяет достаточно ли места в str1 для присоединения str2. |
| strlen(str) | Возвращает целое число равное длине строки без учета нуль-символа. | |
| strcmp(str1,str2) | Сравнивает строки. Поочередно сравниваются коды символов двух строк. Если они совпадают, возвращает 0. Если значение кода символа str1 меньше str2, возвращает отрицательное число. Если значение кода символа str1 больше str2, возвращает положительное число |
Указанные функции находятся в библиотеке cstring. Поэтому программа, использующая эти функции должна содержать директиву
#include <cstring>
Предостережения, отмеченные в замечаниях таблицы, имеют весьма важныое значение. Так, например, если достаточно длинную строку str2 копировать в строку с недостаточной длиной str1, то все элементы массива str1 будут заполнены, однако функция на этом не остановится и продолжит заполнять ячейки памяти которые следуют за последним элементом массива str1, даже если они заняты другой информацией заменять которую нельзя. Естественно, что чаще всего это влечет сбой в работе программы.
Очень часто перед программистом стоит задача перевода строк в числа. Например, строка "12345" и число 12345 это совершенно разные типы. Для перевода строки в число используется функция atoi(str). По-русски название функции произносится как "эй ту ай" ("A" to "I" - alphabetic to integer). Функция atoi возвращает целое число, соответствующее символам строки. Если невозможно установить соответствие символов аргумента с целым числом, то функция возвращает значение 0. Например:
atoi("12345")возвращает 12345
atoi("#12345") возвращает 0, потому, что символ # не является цифрой.
Функция atoi находится в библиотеке с заголовочным файлом cstdlib, поэтому в программах в которых используется эта функция должна присутствовать директива
#include <cstdlib>
В эту библиотеку входит также функция atol, которая возвращает значение типа long. Кроме того, в библиотеку входит функция atof, которая возвращает значение типа double если строка содержит только цифры и точку. В противном случае возвращается 0.0, что говорит о том, что число не определено.
В качестве примера рассмотрим программу, с помощью которой можно из вводимых букв и цифр выделить цифры. Правда, количество цифр не должно превосходить пяти, но читатель без труда может изменить это количество, поняв суть программы. В программе используется новая библиотечная функция isdigit(char), которая возвращает значение true, если аргумент является десятичной цифрой. В противном случае возвращается false. Кроме того, используется функция cin.get(char), которая в отличии отличие от cin читает все символы, включая пробелы и символ возврата строки '\n'. Обращаться с этой функцией следует аккуратно, т.к. применение ее два раза подряд может привести к ошибке. Например, введя в первый раз число и нажав клавишу "Enter" автоматически повлечет ввод символа '\n' с помощью второй записи функции. В силу этих причин в предлагаемом ниже примере специально применена вспомогательная функция newLine.
#include <iostream>
#include <cstdlib>
#include <cctype>
using namespace std;
void read(int& n ); /* Читает строку, отбрасывая все символы кроме цифр. Преобразует строку в целое число и присваивает его переменной n. */
void newLine(); /* Отбрасывает все символы оставшиеся в текущей строке, в том числе символ \n. */
void main(){
int n;
char answer;
do {
cout<<endl<<"Input sum and click Enter"<<endl;
read(n);
cout<<"The number equal "<<n<<" is'n it?"<<endl;
cout<<"Once more? (yes/no): ";
cin>>answer;
newLine();
}while((answer!='n')||(answer!='N'));
}// конец main
//*****************************************************
void read(int& n){
char digitString[6]; //массив для формирования числа
char next;
int index=0;
cin.get(next); //вводит символ включая пробелы
while (next!='\n')
{
if ((isdigit(next))&&(index<5))
{
digitString[index]=next;
index++;
}
cin.get(next);
} // конец while
digitString[index]='\0'; // ввод символа конца строки
n=atoi(digitString); //перевод символов в число
} //конец функции read()
//------------------------------------------
// Функция ввода строки
void newLine()
{char symbol;
do
{
cin.get(symbol);
}while(symbol!='\n');
}
Вот результат

4.3 Демонстрационные программы
Рассмотрим одну простую программу, которая сравнивает три строки.
#include <string.h>
#include <iostream.h>
int main(void)
{
char *buf1 = "aaa", *buf2 = "bbb", *buf3 = "ccc";/ *объявили
* указатели символьных массивов
* и инициализировали их */
int ptr;
ptr = strcmp(buf2, buf1);
if (ptr > 0)
cout<<("buffer 2 is greater than buffer 1\n");
else
cout<<("buffer 2 is less than buffer 1\n");
ptr = strcmp(buf2, buf3);
if (ptr > 0)
cout<<("buffer 2 is greater than buffer 3\n");
else
cout<<("buffer 2 is less than buffer 3\n");
return 0;
}
4.10. Класс string
Стандартом ANSI C++ предусмотрена специальная библиотека string. Эта библиотека состоит из одного класса string, в который входят более ста функций членов. Некоторые из этих функций выполняют операции со строками значительно эффективнее, чем функции, которые мы привели ранее в таблице. Например, для копирования одной строки в другую используется оператор =, а для объединения (конкатинации) строк оператор +. В качестве иллюстрации приведем маленькую программу.
#include <iostream>
#include <string> //требуется для работы с классом string
using namespace std;
int main()
{
string s1="Hellow", s2="my friend!", s3;
s3=s1+s2;
cout<<s3;
}
В результате выполнения программы на экране появится строка:
Hellowmy friend!
Обратите внимание – операция конкатинации не вносит дополнительных пробелов, поэтому слова Hellow и my записаны слитно.
Класс string исключает проблемы со строками, которые возможны при использовании библиотеки stdlib.
В классе string есть несколько конструкторов. По умолчанию объект типа string инициализируется пустой строкой. Кроме того есть конструктор с одним аргументом, являющимся стандартной С строкой. Чтобы действительно понять, что сказано в этом абзаце обратимся к рассмотренному выше примеру, но при этом немного модернизируем его.
#include <iostream>
#include <string>
using namespace std;
int main()
{
string s1,s3; //инициализация пустой строкой
s1="Hellow";
string s2(" my friend!");//инициализация строкой
s3=s1+s2;
cout<<s3;
}
В следующей таблице приведены наиболее часто встречающиеся функции класса string.
| Функция-член | Описание |
| Конструкторы | |
| string str; | Конструктор по умолчанию. Создает объект пустой строки, т.е. в объекте str ничего не записано. |
| string str("string"); | Создает объект класса string со значением "string" |
| string str(aString); | Создает объект класса string с именем str и значением, являющимся копией значения параметра aString типа string. |
| Доступ к элементам | |
| str[i] | Обращение для чтения и записи к символу с индексом i строки с именем str. |
| str.substr(position, length) | Возвращает часть строки, начинающуюся с позиции position и имеющую длину length (только для чтения). |
| str.c_str() | Представляет доступ только для чтения к строке, представленной объектом str. |
| str.at(i) | Обращение для чтения и записи к символу строки str, который имеет индекс i. |
| Присвоение/изменение | |
| str1=str2; | Выделяет для строки str1 объем памяти, равный длине строки str2, и инициализирует строку str1 значением строки str2. |
| str1+=str2 | Символы строки str2 добавляютяс в конец строки str1, для которой выделяется необходимый объем памяти. |
| s.empty() | Если строка s является пустой возвращает true, если s не пустая – false. |
| srt1+str2 | Возвращает строку, которая является объединением строк str1 и str2. Для результирующей строки выделяется необходимый объем памяти. |
| str.insert(pos, str2) | Помещает строку str2 в строку str, начиная с позиции pos. |
| str.remove(pos, len) | Удаляет из строки str подстроку длиной len, начинающуюся с позиции pos. |
| Сравнения | |
| str1 == str2 str1!= str2 | Проверяет равны строки или нет. Возвращает соответствующее логическое значение. |
| str1 < str2 str1 > str2 str1 <= str2 str1 >= str2 | Лекcикографическое сравнение строк. При лексикографическом сравнении последовательно сравниваются коды символов строки. Те символы считаются "больше", чьи коды "больше" и наоборот. |
| str.find(str1) | Возвращает индекс начала подстроки str1, входящей в строку str. |
| str.find(str1, pos) | Возвращает индекс начала подстроки str1, входящей в строку str. Поиск начинается с позиции pos. |
| str.find_first_not_of(str1, pos) | Определяет, в какой позиции в строке str встречается первый символ, отсутствующей в строке str1. Поиск начинается с позиции pos. |
| Копирование | |
| strncpy(char *str1,const char *str2, size count) | Копирует count символов из строки с адресом str2 в массив str1. str2 должен указывать на строку с завершающим нулевым символом. Если длина строки с указателем str2 меньше значения count, то в конце строки-результата str1 добавляются недостающие нулевые символы. Наоборот, если длина строки с указателем str2 больше значения count, резулбтирующая строка с указателем str1 автоматически не получит завершающего нуля. Возвращаемое значение указатель str1. |
До настоящего времени в своих программах при выводе русских текстов мы использовали функцию изменения кодировки консоли SetConsoleOutput(1251). Но можно поступить иначе. Среди функций, входящих в библиотеку windows есть такие, которые перекодируют символы из одной кодовой таблицы в другую. В частности, CharToOem (OEM stands for original equipment manufacturer) – функция, которая может перекодировать символы ANSI т.е. кодировку 1251 в ОЕМ, а функция OemToChar перекодировать их обратно. Работают эти функции следующим образом. Сначала нужно занести каким угодно образом текст в память. После этого запустить функцию, указав адрес начала переводимой строки, и начальный адрес в который будет записан перевод, т.е. синтаксис функции имеет вид:
bool сharToOem(начальный_адрес_строки_предназначенной_для_перевода, адрес_куда_пишется перевод)
Вот пример программы:
#include <iostream>
#include <windows.h>
#include <string>
using namespace std;
void main(){
string str = "Строка для перекодировки";
CharToOem(&str[0], &str[0]);
cout << str<<endl;
}
Если вспомнить, что имя массива на самом деле является указателем, то можно перекодировку осуществлять с помощью массива.
#include <iostream>
#include <windows.h>
#include <string>
using namespace std;
void main(){
char str[100] = "Строка для перекодировки";
CharToOem(str, str);
cout << str<<endl;
}
Можно еще проще
#include <iostream>
#include <windows.h>
#include <string>
using namespace std;
void main(){
char str[100];
CharToOem("Строка для перекодировки", str);
cout << str<<endl;
}
Класс AnsiString
В VCL для представления текстовых строк используются не символьные массивы и не шаблон стандартной библиотеки, а строки Object Pascal. Кроме того, многие свойства компонентов представлены множествами этого языка. Для моделирования таких объектов C++Builder реализует классы AnsiString и Set. Рассмотрим краткое описание этих классов.
Класс AnsiString
Для начала краткая информация. AnsiString - класс динамической строки емкостью до 232-1 символов. Базой для создания этого класса послужил паскалевский тип String, который был расширен в соответствии с возможностями C++. Особенностью его является то, что два экземпляра этого класса могут физически занимать один и тот же участок памяти. Экземпляр этого класса содержит счетчик ссылок к нему, когда этот счетчик обнуляется, экземпляр автоматически уничтожается. Если попытаться изменить экземпляр, к которому имеется более одной ссылки, то будет создана новая копия этой строки, которая и будет изменяться. Это уменьшает портебность программы в памяти, но и уменьшает скорость обработки. Наследием Паскаля является также то, что символы в нем нумеруются с 1, а не с 0, как это принято в C/C++.
Создание строки
Благодаря наличию перегруженных конструкторов строку можно создавать из большого количества базовых типов языка C++, например:
AnsiString empty_string; /* пустая строка */
AnsiString one = 1; /* строка one будет содержать "1" */
AnsiString one_and_half = 1.5; /* в one_and_half содержится строка "1.5" */
AnsiString one_charachter = 'a'; /* в one_charachter содержится строка "a" */
AnsiString dup_string = AnsiString::StringOfChar('A',5); /* dup_string получит значение "AAAAA" */
AnsiString simply_string = "string";
AnsiString shorten("Длинная строка",7); /* в shorten попадут только первые 7 символов */
Получение символа из строки
Получить символ из строки типа AnsiString можно с помощью индексного оператора:
AnsiString ansi_string = "Строка";
char character = ansi_string[1]; /* получаем самый первый символ */
ansi_string[6] = 'и'; /* заменим 6-й на букву 'и' */
Получение символьного массива, содержащего значение AnsiString
Функции библиотеки Builder C++ требуют, чтобы строки передавались им в виде символьных массивов. В AnsiString для этого предназначены функции c_str и data. Разница между ними в том, что для пустой строки c_str() возвращает "", а data - NULL. Это отличие может быть проиллюстрировано следующим примером:
AnsiString ansi_string;
char * str1 = ansi_string.c_str();
char * str2 = (char *)ansi_string.data();
Копирование значения AnsiString в символьный массив Unicode
Для этого предназначена функция WideChar, а размер требуемого массива можно узнать, воспользовавшись функцией WideCharBufSize
AnsiString ansi_string = "Строка AnsiString"; /* наша строка */
wchar_t * UnicodeString = new wchar_t[ansi_string.WideCharBufSize()]; /* массив-получатель */
ansi_string.WideChar(UnicodeString,ansi_string.WideCharBufSize());
// используем полученную строку, затем удаляем
delete [] UnicodeString;
Как узнать, сколько символов в строке?
Для этого надо воспользоваться функцией Length.
Как удалить в строке концевые пробелы?
Это делают функции Trim, TrimLeft и TrimRight соответственно с обоих концов, только с начала и только с конца.
Работа с фрагментами строки
AnsiString предоставлякт возможность поиcка(Pos), вставки(Insert), удаления(Delete) и получения копии(SubString) фрагмента текста в строке:
AnsiString ansi_string = "Строка";
int index = ansi_string.Pos("ка"); /* найдем окончание слова */
if(index!= 0) {
ansi_string.Insert("чеч",index); /* теперь строка имеет вид "Строчечка" */
ansi_string.Delete(index,2); /* а теперь - "Строчка" */
}
Как зарезервировать строке определенный размер
Иногда бывает нужно зарезервировать для строки пространство, достаточное для хранения определенного количества символов. Сделать это можно при помощи функции SetLength
Класс AnsiString определяется в заголовке dstring.h. Конструктор этого класса перегружен, так что строки можно инициализировать различными способами - другой строкой, строкой С (указателем на char), а также целыми типами. В последнем случае строка будет содержать текстовое представление числа.
Пример
#include <vcl.h>
#include <iostream.h>
#include<windows.h>
main(){
AnsiString FNames[10];
SetConsoleOutputCP(1251);
FNames[0]="Иванов";
FNames[1]="Петров";
cout<<FNames[0].c_str()<<endl<<FNames[1].c_str()<<endl;
char z;
cin>>z;
}
Оператор вывода не может быть применен к строке AnsiString, что показано в приведенном примере.
Методы
Мы не будем приводить здесь полное описание всех методов AnsiString, а расскажем только о важнейших.
· int _fastcall AnsiCompare(const AnsiStringfi rhs) const;
Этот метод производит сравнение строки с указанной строкой. Сравнение производится в соответствии с текущим локалом Windows, т. е., например, в русифицированной системе сравнение строк с русским текстом должно давать правильный результат. (Честно говоря, я этого не проверял.) Соответственно результат сравнения может отличаться от результата операций сравнения, которые производятся исходя из ASCII-значений символов.
· int _fastcall AnsiPos(const AnsiStringS subStr) const;
Метод возвращает позицию указанной подстроки. Первому символу строки соответствует 1. Нулевой результат означает, что подстрока не найдена.
· char* _fastcall с str() const;
Возвращает указатель на ограниченную нулем строку С (символьный массив). Если строке ничего не присвоено, возвращается указатель на пустую строку.
· const void* fastcall data() const { return Data; } Аналогичен предыдущему, но возвращает нулевой указатель в случае неприсвоенной строки.
· AnsiString& _fastcall Delete(int index, int count); Удаляет заданное число символов начиная с указанной позиции. Позиция 1 соответствует первому символу строки.
· static AnsiString _fastcall FloatToStrF(long double value, TStringFloatFormat format, int precision, int digits);
Производит преобразование числа с плавающей точкой в текстовую форму в соответствии с указанным форматом.
· AnsiString& _fastcall Insert(const AnsiString& sir, int index);
Вставляет строку в указанной позиции (1 - перед первым символом). Если индекс меньше 1, он считается единицей.
· static AnsiString fastcall IntToHex(int value,int digits);
Преобразует число в строку с представлением его в виде щестнадцате-ричных цифр. Второй параметр указывает минимальное число цифр. Аналогичен Pos, но допускает многобайтовые символы.
· bool _fastcall IsDelimiter (const AnsiString& delimiters, int index) const;
Проверяет, входит ли символ в позиции index в указанную строку delimiters.
· bool _fastcall IsEmptyO const;
Возвращает true, если строка пустая.
· int _fastcall LastDelimiter (const AnsiString& delimiters) const;
Возвращает позицию последнего из символов строки, входящих в указанную строку ограничителей.
· int _fastcall Length() const;
Возвращает число байтов в строке.
· static AnsiString fastcall LoadStr(int ident);
Загружает строку строковым ресурсом исполняемого файла. Если ресурса с указанным идентификатором не существует, возвращается пустая строка.
· AnsiString _fastcall Lowercase() const;
Возвращает строку, преобразованную в нижний регистр в соответствии С Текущим ЛОКалом Windowa. He сохраняет исходную строку.
· int _fastcall Pos(const AnsiString& subStr) const;
Возвращает позицию указанной подстроки.
· int _cdecl printf(const char* format,...);
Формирует строку в соответствии со стандартным форматом С. Возвращает длину строки-результата.
· AnsiString& _fastcall SetLength(int newLength);
Устанавливает новую длину строки, перераспределяя память под ее символьный массив. В новый массив копируетс