Поток данных разбивается на маленькие блоки длины k - кадры информационных символов. Кадры информационных символов кодируются кадрами кодового слова длины n каждый. Кодирование каждого кадра информационных символов в отдельные кадры кодового слова, производится с учетом предыдущих m кадров информационных символов. Поэтому процедура кодирования связывает между собой последовательные кадры кодовых слов. Коды получаемые таким образом, называются древовидными кодами. Сверточными кодами является древовидные коды, которые обладают дополнительными свойствами линейности и постоянства во времени.
Развитие теории сверточных кодов происходило в направлениях: метод порогового декодирования, метод декодирования по максимуму правдоподобия, метод последовательного декодирования.
Метод порогового декодирования состоит в том, что при приеме вычисляются синдромы и эти синдромы или последовательности, полученные в результате линейного преобразования синдромов, подаются на входы порогового элемента, исправление ошибок: осуществляется далее с помощью символов поступающих с выхода порогового элемента. Коды, которые допускают декодирование этим методом, должны обладать свойством ортогональности.
Метод декодирования по максимуму правдоподобия эффективней метода порогового декодирования, однако сложность устройств для его реализации возрастает экспоненциально с ростом длины кода.
Метод последовательного декодирования является методом вероятностного декодирования, при котором число операций, необходимых для декодирования одного символа, является случайной величиной. Этот метод требует для декодирования одного символа тем меньше операций, чем меньше уровень шума в канале.
Когда кодовое слово сверточного кода передается по каналу, время от времени в его символах возникают ошибки. Декодер, принимая кодовое слово, должен исправить эти ошибки. Однако длина кодового слева сверточного кода столь велика, что в фиксированный момент времени декодер может хранить в памяти только его часть. Изучение процедур декодирования сверточных кодов в большинстве случаев ограничивается вопросом исправления ошибок в первом кадре. Если это кадр может быть исправлен и декодирован, то первый информационный кадр известен. При успешном исправлении j кадров проблема декодирования (j+1) го кадра аналогична проблеме декодирования первого кадра.
Если ошибка в декодировании одного кадра приводит к появлению в кодовом слове бесконечного числа дополнительных ошибок, то в декодере происходит распространение ошибок.. Если распространение ошибок может быть устранено выбором алгоритма декодирования это явление называют обычным распространением ошибок; если же распространение ошибок вызывается выбором катастрофического порождающего многочлена сверточного кода, то говорят о катастрофическом распространении ошибок.
Число символов, которые декодер может хранить в памяти называется шириной окна декодирования.
Минимальное расстояние; Хэмминга для любых начальных сегментов длины l кадров всех пар кодовых слов, отличающихся начальным кадром, называется l - м минимальным расстоянием сверточного кода 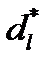 . Если l равно
. Если l равно  , то оно называется минимальным расстоянием d*.
, то оно называется минимальным расстоянием d*.
Сверточный код состоит из бесконечного числа кодовых слов бесконечной длины. Он линеен и может быть описан бесконечной порождающей матрицей.
Порождающие многочлены могут быть записаны в виде  . Для построения порождающей матрицы коэффициенты q упорядочиваются. Пусть при каждом l
. Для построения порождающей матрицы коэффициенты q упорядочиваются. Пусть при каждом l  является
является  матрицей
матрицей  . Порождающей матрицей сверточного кода является матрица
. Порождающей матрицей сверточного кода является матрица

Алгоритм декодирования Витерби является полным алгоритмом декодирования сверточных кодов. Недвоичные коды декодировать декодером Витерби труднее, и это возможно при очень малых длинах кодового ограничения.
Декодер Витерби итеративно обрабатывает кадр за кадром, двигаясь по решетке, аналогичной используемой кодером, и пытаясь повторить путь кодера. В любой момент времени декодер не знает, в каком узле находится кодер и поэтому не пытается декодировать этот узел. Вместо этого декодер по принятой последовательности определяет наиболее правдоподобный путь к каждому узлу и определяет расстояние между каждым таким путем и принятой последовательностью. Это расстояние называется мерой расходимости пути. Если все пути в множестве наиболее правдоподобных путей начинается одинаково, то декодер, как правило знает начало пути пройденного кодером.
Каждый новый узел должен пройти через один из старых узлов. Возможные пути к новому узлу можно получить, продолжая к этому узлу те старые пути, которые можно к нем проложить.