Алгоритмы
Алгоритм (algorithm) – это формально описанная вычислительная процедура, получающая исходные данные (input), называемые также входом алгоритма или его аргументом, и выдающая результат вычислений на выход (output).
Алгоритмы строятся для решения тех или иных вычислительных задач (computational problems). Формулировка задачи описывает, каким требованиям должно удовлетворять решение задачи, а алгоритм, решающий эту задачу. находит объект, этим требованиям удовлетворяющий.
В этой главе мы рассматриваем задачу сортировки (sorting problem); помимо своей практической важности эта задача служит удобным примером для иллюстрации различных понятий и методов. Она описывается так:
Вход: Последовательность 'и чисел (ai, ay...., а„).
Выход: Перестановка [а\, а^,.... и',,) исходной последовательности, для которой а\ ^ а^ ^... ^ а'„.
Например, получив на вход (31,41,59,26.41,58). алгоритм сортировки должен выдать на выход (26,31.41.41.58,59).
Подлежащая сортировке последовательность называется входом (instance) задачи сортировки.
 Многие алгоритмы используют сортировку в качестве промежуточного шага. Имеется много разных алгоритмов сортировки; выбор в конкретной ситуации зависит от длины сортируемой последовательности, от того, в какой степени она ужо отсортирована, а также от типа имеющейся памяти (оперативная память, диски, магнитные ленты).
Многие алгоритмы используют сортировку в качестве промежуточного шага. Имеется много разных алгоритмов сортировки; выбор в конкретной ситуации зависит от длины сортируемой последовательности, от того, в какой степени она ужо отсортирована, а также от типа имеющейся памяти (оперативная память, диски, магнитные ленты).
Алгоритм считают правильным (correct), если на любом допустимом (для данной задачи) входе он заканчивает работу и выдает результат, удовлетворяющий требованиям задачи. В этом случае говорят, что алгоритм решает (solves) данную вычислительную задачу. Неправильный алгоритм может (для некоторого входа) вовсе не остановиться или дать неправильный результат. (Впрочем, неправильный алгоритм может быть полезен, если ошибки достаточно редки. Подобная ситуация встретится нам в главе 33 при поиске больших простых чисел. Но это все же скорее исключение, чем правило.)
Алгоритм может быть записан на русском или английском языке, в виде компьютерной программы или даже в машинных кодах важно только, чтобы процедура вычислений была чётко описана.
Мы будем записывать алгоритмы с помощью псевдокода (pseudocode), который напомнит вам знакомые языки программирования (Си, Паскаль, Алгол). Разница в том. что иногда мы позволяем себе описать действия алгоритма «своими словами», если так получается яснее. Кроме того, мы опускаем технологические подробности (обработку ошибок, скажем), которые необходимы в реальной программе, но могут заслонить существо дела.
Сортировка вставками
Сортировка вставками (insertion sort) удобна для сортировки коротких последовательностей. Именно таким способом обычно сортируют карты: держа, в левой руке уже упорядоченные карты и взяв правой рукой очередную карту, мы вставляем её в нужное место, сравнивая с имеющимися и идя справа налево (рис. 1.1).
Запишем этот алгоритм в виде процедуры insertion-sort, параметром которой является массив А[1.. п] (последовательность длины '//,, подлежащая сортировке). Мы обозначаем число элементов в массиве А через leru/f.f^A]. Последовательность сортируется «на месте», без дополнительной памяти (in place): помимо массива мы используем лишь фиксированное число ячеек памяти. После выполнения процедуры insertion-sort массив А упорядочен по возрастанию.


На рис. 1.2 показана работа алгоритма при А = (5,2,4,6,1,3). Индекс j указывает «очередную карту» (только что взятую со стола). Участок Л[1..^'–1] составляют уже отсортированные карты (левая рука), a A[j + 1., та]–ещё не просмотренные. В цикле for индекс j пробегает массив слева направо. Мы берём элемент A[j] (строка 2 алгоритма) и сдвигаем идущие перед ним и большие его по величине элементы (начиная с {j – 1)-го) вправо, освобождая место для взятого элемента (строки 4-7). В строке 8 элемент A[j} помещается на освобождённое место.
Псевдокод
Перечислим основные соглашения, которые мы будем использовать. 1. Отступ от левого поля указывает на уровень вложенности. Например. тело цикла for (строка 1) состоит из строк 2-8, а тело цикла while (строка 5) содержит строки 6-7, но не 8. Это же правило применяется и для if-then-else. Это делает излишним специальные команды типа begin и end для начала и конца блока. (В реальных языках программирования такое соглашение применяется редко, поскольку затрудняет чтение программ, переходящих со страницы на страницу.)
2. Циклы while, for, repeat и условные конструкции if, then, else имеют тот же смысл, что и в Паскале.
3. Символ о начинает комментарий (идущий до конца строки).
4. Одновременное присваивание i j е (переменные i и j получают значение е) заменяет два присваивания j ^– е и г <– j (в этом порядке).
5. Переменные (в данном случае i, j, key) локальны внутри процедуры (если не оговорено противное).
6. Индекс массива пишется в квадратных скобках: А[j] есть j-й элемент в массиве А. Знак «..» выделяет часть массива: А[i..j] обозначает участок массива А, включающий А[i], А[i+1],...., A[j].
7. Часто используются объекты (objects), состоящие из нескольких полей (fields), или, как говорят, имеющие несколько атрибутов (attributes). Значение поля записывается как имя-поля[имя-объекта]. Например, длина, массива считается его атрибутом и обозначается lengthy так что длина массива А запишется как length[A\. Из контекста обычно ясно, что именно обозначают квадратные скобки (элемент массива или поле объекта).
Переменная, обозначающая массив или объект, считается указателем на составляющие его данные. После присваивания у <- х для любого поля / выполнено f[y] = f[x}. Более того, если мы теперь выполним оператор f[:r} <– 3, то будет не только f[x} = 3, но и f[y] = 3, поскольку после у <– х неременные х и у указывают на один и тот же объект.
Указатель может иметь специальное значение NIL, не указывающее ни на один объект.
8. Параметры передаются по значению (by value): вызванная процедура получает собственную копию параметров; изменение параметра внутри процедуры снаружи невидимо. При передаче объектов копируется указатель на данные, составляющие этот объект, а сами поля объекта–нет. Например, если х - параметр процедуры, то присваивание х у, выполненное внутри процедуры, снаружи заметить нельзя, а присваивание f[x] = 3 – можно.
Заметим в заключение, что термины «алгоритм», «программа» и «процедура» часто используются вперемешку.
Анализ алгоритмов
Рассматривая различные алгоритмы решения одной и той же задачи, полезно проанализировать, сколько вычислительных ресурсов они требуют (время работы, память), и выбрать наиболее эффективный. Конечно, надо договориться о том, какая модель вычислений используется, В этой книге в качестве модели по большей части используется обычная однопроцессорная машина с произвольным доступом (random-access machine. RAM), не предусматривающая параллельного выполнения операций. (Мы рассмотрим некоторые модели параллельных вычислений в последней части книги.)
Сортировка вставками: анализ
Время сортировки вставками зависит от размера сортируемого массива: чем больше массив, тем больше может потребоваться времени. Обычно изучают зависимости времени работы от размера входа. (Впрочем, для алгоритма сортировки вставками важен не только размер массива, но и порядок его элементов: если массив почти упорядочен, то времени требуется меньше.)
Как измерять размер входа (input size)? Это зависит от конкретной задачи. В одних случаях размером разумно считать число элементов на входе (сортировка, преобразование Фурье). В других более естественно считать размером общее число битов, необходимое для представления всех входных данных. Иногда размер входа измеряется не одним числом, а несколькими (например, число вершин и число рёбер графа).
Временем работы (running time) алгоритма мы называем число элементарных шагов, которые он выполняет–вопрос только в том, что считать элементарным шагом. Мы будем полагать, что одна строка псевдокода требует не более чем фиксированного числа операций (если только это не словесное описание каких-то сложных действий – типа «отсортировать все точки по координате»). Мы будем различать также вызов (call) процедуры (на который уходит фиксированное число операций) и её исполнение (execution), которое может быть долгим.
Итак, вернёмся к процедуре insertion-sort и отметим около каждой строки её стоимость (число операций) и число раз, которое эта строка исполняется. Для каждого j от 2 до п (здесь п = length[A] – размер массива) подсчитаем, сколько раз будет исполнена строка 5, и обозначим это число через /.у. (Заметим, что строки внутри цикла выполняются на один раз меньше, чем проверка, поскольку последняя проверка выводит из цикла.)

Строка стоимостью с, повторенная ш раз, дает вклад сш в общее число операций. (Для количества использованной памяти этого сказать нельзя!) Сложив вклады всех строк, получим

Как мы уже говорили, время работы процедуры зависит не только от л, по и от того, какой именно массив размера п подан ей на вход. Для процедуры insertion-sort наиболее благоприятен случай, когда массив уже отсортирован. Тогда цикл в строке 5 завершается после первой же проверки (поскольку г\ ^ key при i = j – 1), так что все tj равны 1, и общее время есть
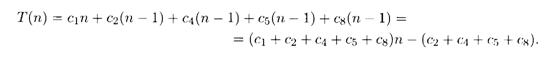
Таким образом, в наиболее благоприятном случае время Т(п), необходимое для сортировки массива размера л, является линейной функцией (linear function) от n, т.е. имеет вид Т[п) = an + b для некоторых констант а и b. (Эти константы определяются выбранными значениями c1,..., c8.)
Если же массив расположен в обратном (убывающем) порядке, время работы процедуры будет максимальным: каждый элемент A[j] придётся сравнить со всеми элементами A[1],... .A [ j – 1 ]. При этом tj = j. Поскольку

Время работы в худшем случае и в среднем
Итак, мы видим, что время работы в худшем случае и в лучшем случае могут сильно различаться. Большей частью нас будет интересовать время работы в худшем случае (worst-case running time), которое определяется как максимальное время работы для входов данного размера. Почему? Вот несколько причин.
• Зная время работы в худшем случае, мы можем гарантировать, что выполнение алгоритма закончится за некоторое время, даже не зная, какой именно вход (данного размера) попадётся.
• На практике «плохие» входы (для которых время работы близко к максимуму) могут часто попадаться. Например, для базы данных плохим запросом может быть поиск отсутствующего элемента (довольно частая ситуация).
• Время работы в среднем (о котором мы говорим дальше) может быть довольно близко к времени работы в худшем случае. Пусть, например, мы сортируем случайно расположенные п чисел с помощью процедуры insertion-sort. Сколько раз придётся выполнить цикл в строках 5-8? В среднем около половины элементов массива A[1..j–1] больше A[j], так что tj в среднем можно считать равным j/2, и время Т(п} квадратично зависит от п.
В некоторых случаях нас будет интересовать также среднее время работы (average-case running time, expexted running time) алгоритма на входах данной длины. Конечно, эта величина зависит от выбранного распределения вероятностей, и на практике реальное распределение входов может отличаться от предполагаемого, которое обычно считают равномерным. Иногда можно добиться равномерности распределения, используя датчик случайных чисел.
Порядок роста
Наш анализ времени работы процедуры insertion-sort был основан на нескольких упрощающих предположениях. Сначала мы предположили, что время выполнения i-й строки постоянно и равно Сi. Затем мы огрубили оценку до an2 + bп + с. Сейчас мы пойдём ещё дальше и скажем, что время работы в худшем случае имеет порядок роста (rate of growth, order of growth) n2, отбрасывая члены меньших порядков (линейные) и не интересуясь коэффициентом при ni. Это записывают так: Т(п) = O(n2) (подробное объяснение обозначений мы отложим до следующей главы).
Алгоритм с меньшим порядком роста времени работы обычно предпочтительнее; если, скажем, один алгоритм имеет время работы O(n2), а другой- O(n3), то первый более эффективен (по крайней мере для достаточно длинных входов; будут ли реальные входы таковыми – другой вопрос).
Построение алгоритмов
Есть много стандартных приемов, используемых при построении алгоритмов. Сортировка вставками является примером алгоритма, действующего по шагам (incremental approach): мы добавляем элементы один за другим к отсортированной части массива.
В этом разделе мы покажем в действии другой подход, который называют «разделяй и властвуй» (divide-and-conquer approach), и построим с его помощью значительно более быстрый алгоритм сортировки.
1.3.1. Принцип «разделяй и властвуй»
Многие алгоритмы по природе своей рекурсивны (recursive): решая некоторую задачу, они вызывают самих себя для решения её подзадач. Идея метода «разделяй и властвуй» состоит как раз в этом. Сначала задача разбивается на несколько подзадач меньшего размера. Затем эти задачи решаются (с помощью рекурсивного вызова–или непосредственно, если размер достаточно мал). Наконец, их решения комбинируются и получается решение исходной задачи.
Для задачи сортировки эти три этапа выглядят так. Сначала мы разбиваем массив на две половины меньшего размера. Затем мы сортируем каждую из половин отдельно. После этого нам остаётся соединить два упорядоченных массива половинного размера в один. Рекурсивное разбиение задачи на меньшие происходит до тех пор, пока размер массива не дойдёт до единицы (любой массив длины 1 можно считать упорядоченным).
Нетривиальным этапом является соединение двух упорядоченных массивов в один. Оно выполняется с помощью вспомогательной процедуры MERGE(A, p, q, r). Параметрами этой процедуры являются массив А и числа р, q. r, указывающие границы сливаемых участков. Процедура предполагает, что р £ q < r и что участки А[р..q] и A[q +1.. r ] уже отсортированы, и сливает (merges) их в один участок А[р.. r].
Ясно, что время работы процедуры MERGE есть O(n), где n–общая длина сливаемых участков (n = r – р + 1). Это легко объяснить на картах. Пусть мы имеем две стопки карт (рубашкой вниз), и в каждой карты идут сверху вниз в возрастающем порядке. Как сделать из них одну? На каждом шаге мы берём меньшую из двух верхних карт и кладём её (рубашкой вверх) в результирующую стопку. Когда одна из исходных стопок становится пустой, мы добавляем все оставшиеся карты второй стопки к результирующей стопке. Ясно, что каждый шаг требует ограниченного числа действий, и общее число действий есть O(n).

Рис. 1.3. Сортировка слиянием для массива А = (5, 2,4, 6, 1. 3, 2. 6).
Теперь напишем процедуру сортировки слиянием MERGE-SORT(А, p, r), которая сортирует участок А [р..r] массива А, не меняя остальную часть массива. При р ³ r участок содержит максимум один элемент, и тем самым уже отсортирован. В противном случае мы отыскиваем число q, которое делит участок на две примерно равные части А[р.. q] (содержит [n/2] элементов).

Весь массив теперь можно отсортировать с помощью вызова MERGE-SORT (A, I, length[A]). Если длина массива п = length[A] есть степень двойки, то в процессе сортировки произойдёт слияние пар элементов в отсортированные участки длины 2. затем слияние пар таких участков в отсортированные участки длины 4 и так далее до п (на последнем шаге соединяются два отсортированных участка длины п/2). Этот процесс показан на рис. 1.3.
1.3.2. Анализ алгоритмов типа «разделяй и властвуй»
Как оценить время работы рекурсивного алгоритма? При подсчёте мы должны учесть время, затрачиваемое на рекурсивные вызовы, так что получается некоторое рекуррентное соотношение (recurrence equation). Далее следует оценить время работы, исходя из этого соотношения.
Вот примерно как это делается. Предположим, что алгоритм разбивает задачу размера 'п на а подзадач, каждая из которых имеет в b раз меньший размер. Будем считать, что разбиение требует времени D{n), а соединение полученных решений—времени С{п}. Тогда получаем соотношение для времени работы Г(п) на задачах размера п (в худшем случае): Т {'я] = аТ{п/Ь} + D[n} + С{п}. Это соотношение выполнено для достаточно больших п, когда задачу имеет смысл разбивать на подзадачи. Для малых п, когда такое разбиение невозможно или не нужно, применяется какой-то прямой метод решения задачи. Поскольку п ограничено, время работы тоже не превосходит некоторой константы.