Число различных запросов (причин) прерывания может достигать нескольких десятков, а то и сотен. В таких случаях часто запросы разделяют на отдельные классы (уровни).
Совокупность запросов, инициирующих одну и ту же прерывающую программу, образует класс или уровень прерывания.
Разделение запросов на классы прерывания производится следующим образом.
Запросы всех источников прерывания поступают на регистр запросов прерывания РгЗП, устанавливая соответствующие его разряды (флажки) в состо- яние 1.
Запросы классов прерывания
















 ЗКi формируются логическими эле-
ЗКi формируются логическими эле-





 ментами ИЛИ.
ментами ИЛИ.
















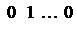 Ещё одна схема ИЛИ формиру-
Ещё одна схема ИЛИ формиру-
ет общий сигнал прерывания ОСП,
поступающий в устройство управ-
ления МП.
 | |||
 |

 Информация о действитель-
Информация о действитель- 
 ной причине прерывания, поро-
ной причине прерывания, поро-
дившей запрос данного класса, со-
держится в коде прерывания.
Коды прерывания образуются совокупностью состояний соответствующих разрядов регистра запросов прерывания.
После принятия запроса прерывания на исполнение и передачи управления прерывающей программе соответствующий триггер регистра РгЗП сбрасывается.
Объединение запросов в классы прерывания позволяет уменьшить объём аппаратуры, но связано с замедлением работы системы прерывания.
8.7. Способы организации приоритетного обслуживания
запросов прерывания.
Жёсткая фиксация приоритета является простейшим способом установления приоритетных соотношений между запросами прерывания.
В этом случае приоритет определяется порядком присоединения линий сигналов запросов к входам системы прерывания.
При появлении нескольких запросов прерывания первым воспринимается запрос, поступивший на вход с меньшим номером.
Изменить приоритетные соотношения можно только пересоединением линий сигналов запросов на входах системы прерывания.
Процедура прерывания с опросом источников прерывания заключается в следующем.
Каждому источнику запросов соответствует разряд (флажок) в регистре запросов прерывания. При наличии запроса или нескольких запросов прерывания формируется общий сигнал прерывания. Этот сигнал инициирует процедуру опроса регистра прерывания для установления источника наибольшего приоритета.
Процедура опроса состоит в определении местоположения крайней слева единицы (крайнего флажка) в регистре запросов прерывания.
Используются программный, циклический и цепочечный способы опроса.
Процесс прерывания с программным опросом флажков протекает под управлением специальной программы, описывающей следующий алгоритм:



Программный опрос ис-
точников прерываний занима-
 ет сравнительно много време-
ет сравнительно много време-
 ни.
ни.

 Для уменьшения этого
Для уменьшения этого


 времени процедуру опроса
времени процедуру опроса
 реализуют аппаратным пу-
реализуют аппаратным пу-



 тём.
тём.
 | |||
 |


Схема циклического опро -
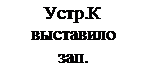
 са запросов (источников)
са запросов (источников)




 прерываний имеет вид: (рис.)
прерываний имеет вид: (рис.)

































































 Опрос kлиний запросов
Опрос kлиний запросов
прерывания (или флажков)
регистра запросов прерыва-
ния производится последо-
вательно (циклически) с по-
мощью n-разрядного счётчи-
ка (2n ³ k).








































 Счётчик тактируется
Счётчик тактируется
сигналами генератора так-



 товых импульсов (ГТИ).
товых импульсов (ГТИ).



















 Поиск приоритетного
Поиск приоритетного
запроса прерывания начи-
нается со сброса счётчика и
RS-триггера в нулевое сос-
тояние, при этом импульсы
генератора начинают поступать на счётный вход счётчика.
При помощи дешифратора и элементов И в каждом такте поиска проверяется наличие запроса прерывания, номер которого совпадает с кодом счётчика.
Если на данном входе нет запроса прерывания, то после увеличения состояния счётчика на 1 проверяется следующий по порядку вход. Если же имеется запрос, RS-триггер переключается в 1, при этом в процессор посылается общий сигнал прерывания ОСП и прекращается тактирование счётчика, т.е. завершается цикл просмотра входов системы прерывания.
Содержимое счётчика представляет собой код номера старшего по приоритету выставленного запроса. Этот код используется для формирования начального адреса прерывающей программы.
После передачи управления прерывающей программе счётчик и триггер сбрасываются в нулевое состояние, и процедура опроса возобновляется, начиная с первого входа.
Циклический (последовательный) опрос входов системы прерывания в аппаратурном отношении сравнительно прост. Однако время реакции и при этом методе всё-таки велико, особенно при большом числе источников запросов. Поэтому в ряде МП, например работающих в реальном масштабе времени, применяют однотактные схемы.
Цепочечная однотактная схема ("дейзи-цепочка") позволяет определить номер выставленного запроса старшего приоритета за один такт: (рис. на следующей странице).
 | |||||
 | |||||
 | |||||





































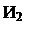













 Как и в преды-
Как и в преды-
дущей схеме при-
оритет запросов
прерывания уме-
ньшается с возра-
станием их номе-
ра.
 Процедура
Процедура
определения при-
оритетного запроса инициируется сигналом "приоритет", поступающим на цепочку последовательно включённых схем И.
При отсутствии запросов этот сигнал пройдёт через цепочку и ОСП не сформируется.
Если среди выставленных запросов прерывания наибольший приоритет имеет i-й запрос, то распространение сигнала "приоритет" правее схемы И с номером i блокируется. На i-ом выходе цепочечной схемы будет сигнал yi=1, на всех других 0.
В процессор поступит ОСП, при этом шифратор по сигналу yi=1 сформирует код номера i-го запроса, принятого к обслуживанию.
По сигналу процессора "подтверждение прерывания" (на схеме не показан) этот код передаётся в процессор и используется для формирования начального адреса прерывающей программы.
Дополнительную часть схемы, обозначенную пунктиром, мы обсудим чуть позже.
Процедура прерывания с опросом, даже если опрос выполняется аппаратурными средствами, требует сравнительно больших временных затрат. Более гибким и динамичным является векторное прерывание.
При векторном прерывании исключается опрос источников прерывания (флажков регистра запросов).
Прерывание называется векторным, если источник прерывания, выставляя запрос прерывания, посылает в процессор код адреса, по которому расположен соответствующий вектор прерывания во внешней памяти.
Программно-управляемый приоритет позволяет изменять по мере надобности приоритетные соотношения программным путём.
Необходимость такого изменения приоритетных соотношений обусловлена изменением относительной степени важности программ в ходе вычислительного процесса и, как следствие, невозможностью жёсткой фиксации приоритетов.
Широко используются два способа реализации программно-управляемо-го приоритета прерывающих программ, в которых используются, соответственно, порог прерывания и маски прерывания.
Порог прерывания позволяет в ходе вычислительного процесса изменять (задавать) минимальный уровень приоритета запросов (порог прерывания), которым разрешается прерывать текущую программу.
Порог прерывания задаётся командой программы, устанавливающей в соответствующем регистре код порога прерывания.
Цепочечная схема выделяет наиболее приоритетный запрос прерывания. Цифровой компаратор (дополнительная часть цепочечной схемы, обозначенная пунктиром) сравнивает его приоритет с порогом прерывания и, если он оказывается выше порога, вырабатывает ОСП, начиная тем самым процедуру прерывания.
Маска прерывания представляет собой двоичный код, разряды которого поставлены в соответствие запросам или классам прерывания.
Схема программного управления приоритетом на основе маски прерывания имеет вид:




































 Маска загружается командой
Маска загружается командой
программы в регистр маски
(РгМ).
Состояние 1 в данном раз-
ряде регистра маски разрешает,
а состояние 0 запрещает (маски-
рует) прерывание текущей про-
граммы от соответствующего
запроса.
Таким образом, программа,
изменяя маску в регистре мас-
маски, может устанавливать
произвольные приоритетные
соотношения между програм-
мами без перекоммутации ли-
ний, по которым поступают запросы прерывания.
Каждая прерывающая программа может установить свою маску. При формировании маски единицы устанавливаются в разряды, соответствующие запросам с более высоким, чем у данной программы, приоритетом.
Логические элементы И выделяют поступившие незамаскированные запросы прерывания, из которых схема, аналогичная цепочечной, выделяет наиболее приоритетный и формирует код его номера.
С замаскированным запросом в зависимости от причины прерывания поступают двояко: либо он игнорируется, либо запоминается с целью осуществить затребованные действия после снятия запрета.
Например, если прерывание вызвано окончанием операции в периферийном устройстве, то его следует запомнить. В противном случае процессор останется неосведомлённым о том, что это устройство освободилось.
Прерывание же, вызванное переполнением разрядной сетки следует при его маскировании игнорировать. В противном случае этот запрос может повлиять на ту часть программы или другую программу, к которым это переполнение не относится.
8.8. Процесс выполнения команд. Рабочий цикл МП.
Функционирование микропроцессора состоит из последовательности рабочих циклов.
Каждый цикл соответствует выполнению одной команды программы и содержит от трёх до пяти этапов (операций), каждый из которых может состоять из нескольких тактов (микрокоманд).
Общеечисло тактов отдельного цикла зависит от типа соответствующей ему команды.
Рассмотрим обобщённую схему рабочего цикла процессора для четырёх групп команд: 1) основных (арифметические, логические и пересылочные
операции); 2) передачи управления (условные и безусловные переходы);
3) ввода-вывода; 4) системных (устанавливают состояние процессора, маску прерывания и др.).
На схеме символ Тi обозначает i-й этап.
 | ||||||
 | ||||||
 | ||||||
 | ||||||





















 | |||||
 | |||||
 |












 Рабочий цикл начинается с распознавания состояния процессора. Устанавливается одно из альтернативных состояний «счет» или «ожидание».
Рабочий цикл начинается с распознавания состояния процессора. Устанавливается одно из альтернативных состояний «счет» или «ожидание».
 | |||||||||||
 | |||||||||||
 | |||||||||||
 | |||||||||||
 | |||||||||||
 | |||||||||||
Далее проверяется наличие незамаскированных прерываний.
В состоянии "ожидание" никакие программы не выполняются. Процессор ждёт прихода запроса прерывания, после чего управление переходит к соответствующей прерывающей программе, переводящей процессор в состояние "счёт".
В состоянии "счёт" при наличии незамаскированных прерываний происходит выход из нормального рабочего цикла и переход к процедуре обработки запросов прерывания.
При отсутствии в состоянии "счёт" запросов прерывания последовательно выполняются этапы рабочего цикла, которые начинаются с выборки очередной команды и определении по коду операции принадлежность её к той или иной группе.
На этапе выборки очередной команды образуется адрес следующей команды согласно естественному порядку следования. При этом содержимое счётчика команд увеличивается на число, равное числу байт в очередной команде.
При выполнении основных команд производится подготовка операндов (формирование исполнительных адресов и выборка операндов из памяти), их обработка в АЛУ и запоминание результата.
Кроме того, формируется признак результата операции, который используется командами условного перехода при организации ветвлений в программах.
При выполнении команд передачи управления проверяетсязаданное командой (например, её полем маски) условие.
Если условие не выполняется, то следующую команду указывает адрес, установленный в счётчике команд согласно естественному порядку следования.
В случае выполнения условия или наличия одного из вариантов команд безусловного перехода в счётчик команд передаётся адрес, задаваемый командой передачи управления.
Команды ввода-вывода инициируют операцию обмена информацией между МП и внешней памятью или периферийным устройством.
Сама операция выполняется каналом под управлением его собственной программы. Поэтому на долю МП остаётся только процедура опроса состояний канала и периферийного устройства – свободны они для операции ввода-вывода или нет.
Если свободны, МП выдаёт в канал информацию, необходимую для начала операции ввода-вывода.
В противном случае МП переключается в состояние "ожидание" и ждёт сигнала прерывания от этого канала.
Системные команды осуществляют переключения состояния процессора путём загрузки нового вектора состояния или его части.
8.9. Конвейерная обработка команд и данных.
Принцип конвейерной обработки начнём рассматривать с конвейера команд.
Пусть рабочий цикл МП состоит из k этапов, причём i-й этап имеет продолжительность ti. Тогда при последовательном выполнении этапов длительность цикла определяется суммой ТПОСЛ = 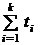 , а общая производительность процессора РПОСЛ = 1/ операций/с.
, а общая производительность процессора РПОСЛ = 1/ операций/с.
Скорость работы МП может быть увеличена, если для выполнения каждого этапа ввести отдельный аппаратурный блок:
 | |||||||
 |  |  | |||||





 Блоки соединить так, чтобы резуль-
Блоки соединить так, чтобы резуль-






