Об этой модели распределения оперативной памяти уже шла речь ранее, но тогда перед нами стояла задача лишь ввести читателя в курс дела, в этом же разделе будут обсуждаться более подробно современные подходы страничной организации памяти.
Данная модель основывается на том, что все адресное пространство может быть представлено совокупностью блоков фиксированного размера (Рис. 124), которые называются страницами. Есть виртуальное адресное пространство — это то пространство, в котором оперирует программа, и физическое адресное пространство — это то пространство, которое есть в наличии у компьютера. Соответственно, при страничном распределении памяти существуют программно-аппаратные средства, позволяющие устанавливать соответствие между виртуальными и физическими страницами. Механизм преобразования виртуального адреса в физический обсуждался выше, он достаточно прост: берется номер виртуальной страницы и заменяется соответствующим номером физической страницы. Также отмечалось, что для этих целей используется т.н. таблица страниц, которая целиком является аппаратной, что на самом деле является большим упрощением. Если рассмотреть современные машины с современным объемом виртуального адресного пространства, то окажется, что эта таблица будет очень большой по размеру. Соответственно, возникает важный вопрос, как осуществлять указанное отображение виртуальных адресов в физические.

Рис. 124. Страничное распределение.
Ответ на поставленный вопрос, как всегда, неоднозначный и имеет несколько вариантов. Первое решение, приходящее на ум, — это полное размещение таблицы преобразования адресов в аппаратной части компьютера, но это решение применимо лишь в тех системах, где количество страниц незначительное. Примером такой системы может служить машина БЭСМ-6, которая имела 32 виртуальные страницы, и вся таблица с 32 строками располагалась в процессоре. Если же таблица получается большой, то возникают следующие проблемы: во-первых, высокая стоимость аппаратной поддержки, а во-вторых, необходимость полной перезагрузки таблицы при смене контекстов. Но при этом скорость преобразования оказывается довольно высокой.
Альтернативой служит решение, предполагающее хранение данной таблицы в оперативной памяти, тогда каждое преобразование происходит через обращение к ОЗУ, что совсем неэффективно. К аппаратуре предъявляются следующие требования: должен быть регистр, ссылающийся на начало таблицы в ОЗУ, а также должно аппаратно поддерживаться обращение в оперативную память по адресу, хранящемуся в указанном регистре, извлечение данных из таблицы и осуществление преобразования.
Возможно оптимизировать рассмотренный подход за счет использования кэширования L1 или L2. С одной стороны, поскольку к таблице страниц происходит постоянное обращение, странички из данной таблицы «зависают» в КЭШе. Но, если в компьютере используется всего один КЭШ и для потока управления, и для потока данных, то в этом случае через него направляется еще и поток преобразования страниц. Поскольку эти потоки имеют свои особенности, то добавление дополнительного потока со своими индивидуальными характеристиками приведет к снижению эффективности системы.
Стоит также отметить, что в современных системах таблицы страниц каждого процесса могут оказаться достаточно большими, мультипрограммные ОС поддерживают обработку сотен или даже тысяч процессов, поэтому держать всю таблицу страниц в оперативной памяти также оказывается дорогим занятием. С другой стороны, если в ОЗУ хранить лишь оперативную часть этой таблицы, то возникают проблемы, связанные со сменой процессов: необходимо будет часть таблицы откачивать на внешнюю память, а часть — наоборот, подкачивать, что является достаточно трудоемкой задачей. Соответственно, возникает проблема организации эффективной работы с таблицей страниц, чтобы возникающие накладные расходы не приводили к деградации системы.
Помимо указанных подходов размещения таблицы страниц, каждый из которых имеет свои преимущества и недостатки, в реальности применяют смешанные, или гибридные, решения.
Что касается используемых алгоритмов и способов организации данных для модели страничного распределения памяти, то традиционно применяются решения, связанные с иерархической организацией этих таблиц.
Типовая структура записи таблицы страниц (Рис. 125) содержит информацию о номере физической страницы, а также совокупность атрибутов, необходимых для описания статуса данной страницы. Среди атрибутов может быть атрибут присутствия/отсутствия страницы, атрибут режима защиты страницы (чтение, запись, выполнение), флаг модификации содержимого страницы, атрибут, характеризующий обращения к данной странице, чтобы иметь возможность определения «старения» страницы, атрибут блокировки кэширования и т.д. Итак, в каждой записи может присутствовать целая совокупность атрибутов, которые аппаратно интерпретируемы: например, при попытке записать данные в страницу, закрытую на запись, произойдет прерывание.

Рис. 125. Модельная структура записи таблицы страниц. Здесь: α — присутствие/ отсутствие; β — защита (чтение, чтение/запись, выполнение); γ — изменения; δ — обращение (чтение, запись, выполнение); ε — блокировка кэширования.
В качестве одного из первых решений оптимизации работы с памятью стало использование т.н. TLB-таблиц (Translation Look-aside Buffer — таблица быстрого преобразования адресов, Рис. 126). Данный метод подразумевает наличие аппаратной таблицы относительно небольшого размера (порядка 8 – 128 записей). Данная таблицы концептуально содержит три столбца: первый столбец — это номер виртуальной страницы, второй — это номер физической страницы, в которой находится указанная виртуальная страница, а третий столбец содержит упомянутые выше атрибуты.
Теперь, имея виртуальный адрес, состоящий из номера виртуальной страницы (VP) и смещения в ней (offset). Страница изымает из этого адреса номер виртуальной страницы и осуществляет оптимизированный поиск (т.е. поиск не последовательный, а параллельный) этого номера по TLB-таблице. Если искомый номер найден, то система автоматически на уровне аппаратуры осуществляет проверку соответствия атрибутов, и если проверка успешна, то происходит подмена номера виртуальной страницы номером физической страницы, и, таким образом, получается физический адрес.
Если же при поиске происходит промах (номер виртуальной странице не найден), то в этом случае система обращается в программную таблицу, выкидывает самую старую запись из TLB, загружает в нее найденную запись из программной таблицы, и затем вычисляется физический адрес. Таким образом, получается, что TLB-таблица является некоторым КЭШем.
Модели отработки промаха могут быть различными. Возможна организация отработки промаха без прерываний, когда система самостоятельно, имея регистр начала программной таблицы страниц, обращается к этой таблице и осуществляет в ней поиск. Возможна модель с прерыванием, когда при промахе возникает прерывание, управление передается операционной системе, которая затем начинает работать с программной таблицей страниц, и т.д. Заметим, что вторая модель менее эффективная, поскольку прерывания ведут к увеличению накладных расходов.
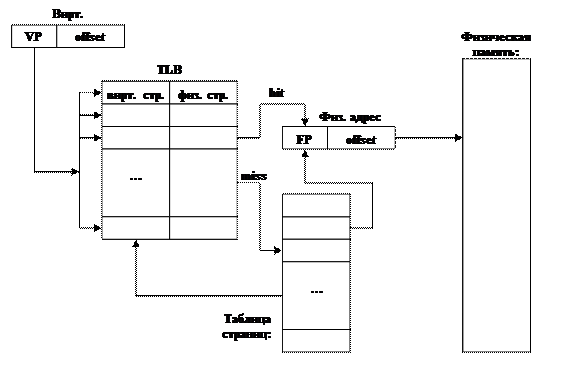
Рис. 126. TLB-таблица (Translation Look-aside Buffer).
Итак, рассмотренная модель использования TLB-таблиц является реальной по сравнению с той моделью, которая была описана в начале курса. Одной из главных проблем этого подхода является проблема, связанная с большим размером таблицы страниц. Отметим, что большой размер этой таблицы плох по двум причинам: во-первых, при смене контекста система так или иначе обязана поменять эту таблицу, а также содержимое TLB, т.к. это все хранит информацию об одном процессе, а во-вторых, это проблема, связанная с организацией мультипроцессирования — необходимо решать, где размещать все таблицы различных процессов.
Одним из решений, позволяющих снизить размер таблицы страниц, является модель иерархической организации таблицы страниц (Рис. 127). В этом случае информация о странице представляется не в виде одного номера страницы, а в виде совокупности номеров, используя которые посредством обращения к соответствующим таблицам, участвующим в иерархии (это может быть 2-х-, 3-х- или даже 4-хуровневая иерархия), можно получить номер соответствующей физической страницы.
Пускай имеется 32-разрядный виртуальный адрес, который в свете рассмотренной ранее модели может, например, содержать 20-разрядный номер виртуальной страницы и 12-разрядного значения смещения в ней. Если же используется двухуровневая иерархическая организация, то этот же виртуальный адрес можно трактовать, к примеру, как 10-разрядный индекс во «внешней» таблице групп, или кластеров, страниц, 10-разрядное смещение в таблице второго уровня и, наконец, 12-разрядное смещение в физической странице. Соответственно, чтобы получить номер физической страницы необходимо по индексу во «внешней» таблице групп страниц найти необходимую ячейку, содержащую начальный адрес таблицы второго уровня, затем по этому адресу и по значению смещения в виртуальном адресе находится нужная запись в таблице страниц второго уровня, которая уже и содержит номер соответствующей физической страницы.

Рис. 127. Иерархическая организация таблицы страниц.
Используя данный подход, может оказаться, что всю таблицу страниц хранить в памяти вовсе необязательно: из-за принципа локализации будет достаточно хранить сравнительно небольшую «внешнюю» таблицу групп страниц и некоторые таблицы второго уровня (они также имеют незначительные размеры), все необходимые таблицы второго уровня можно подкачивать по мере надобности.
Подобные рассуждения можно распространить на больше число уровней иерархии, но, начиная с некоторого момента, эффективность системы начинает сильно падать с ростом числа уровней иерархии (из-за различных накладных расходов), поэтому обычно число уровней ограничено четырьмя.
Существует иное решение, позволяющее также обойти проблему большого размера таблицы страниц, которое основано на использовании хеширования (использования т.н. хеш-таблиц), базирующееся, в свою очередь, на использовании хеш-функции, или функции расстановки (Рис. 128). Эти функции используются в следующей задаче: пускай имеется некоторое множество значений, которое необходимо каким-то образом отобразить на множество фиксированного размера. Для осуществления этого отображения используют функцию, которая по входному значению определяет номер позиции (номер кластера, куда должно попасть это значение). Но эта функция имеет свои особенности: при ее использовании возможны коллизии, связанные с тем, что различные значения могут оказаться в одном и том же кластере.

Рис. 128. Использование хеш-таблиц.
Модель преобразования адресов, основанная на хешировании, достаточно проста. Из виртуального адреса аппаратно извлекается номер виртуальной страницы, который подается на вход некоторой хеш-функции, отображающей значение на аппаратную таблицу (т.н. хеш-таблицу) фиксированного размера. Каждая запись в данной таблице хранит начало списка коллизий, где каждый элемент списка является парой: номер виртуальной страницы — соответствующий ему номер физической страницы. Итак, перебирая соответствующий список коллизии, можно найти номер исходной виртуальной страницы и соответствующий номер физической страницы. Подобное решение имеет свои достоинства и недостатки: в частности, возникают проблемы с перемещением списков коллизий.
Еще одним решением, позволяющим снизить размер таблицы страниц, является модель использования т.н. инвертированных таблиц страниц (Рис. 129). Главной сложностью данного решения является требование к процессору на аппаратном уровне работать с идентификаторами процессов (их PID). Примерами таких процессоров могут служить процессоры из линеек SPARC и PowerPC.

Рис. 129. Инвертированные таблицы страниц.
В этой модели виртуальный адрес трактуется как тройка значений: PID процесса, номер виртуальной страницы и смещение в этой странице. При таком подходе используется единственная таблица страниц для всей системы, и каждая строка данной таблицы соответствует физической страницы (с номером, равным номеру этой строки). При этом каждая запись данной таблицы содержит информацию о том, какому процессу принадлежит данная физическая страница, а также какая виртуальная страница этого процесса размещена в данной физической странице. Итак, имея пару PID процесса и номер виртуальной странице, производится поиск ее в таблице страниц, и по смещению найденного результата определяется номер физической страницы.
К достоинствам данной модели можно отнести наличие единственной таблицы страниц, обновление которой при смене контекстам сравнительно нетрудоемкое: операционная система производит обновление тех строк таблицы, для которых в соответствующие физические страницы происходит загрузка процесса. Отметим, что «тонким местом» данной модели является организация поиска в таблице. Если будет использоваться прямой поиск, то это приведет к существенным накладным расходам. Для оптимизации этого момента возможно надстройка над этим решением более интеллектуальных моделей — например, модели хеширования и/или использования TLB-таблиц.
Революционным достоинством страничной организации памяти стало то, что исполняемый в системе процесс может использовать очень незначительную часть физического ресурса памяти, а все остальные его страницы могут размещаться во внешней памяти (быть откачанными). Очевидно, что и страничная организация памяти имеет свои недостатки: в частности, это проблема фрагментации внутри страницы. В связи с использованием страничной организации памяти встает еще одна проблема — это проблема выбора той страницы, которая должна быть откачана во внешнюю память при необходимости загрузить какую-то страницу из внешней памяти. Эта задача имеет множество решений, некоторые из которых будут освещены ниже.
Первым рассмотрим алгоритм NRU (Not Recently Used — не использовавшийся в последнее время). Этот алгоритм основан на том, что с любой страницей ассоциируются два признака, один из которых отвечает за обращение на чтение или запись к странице (R-признак), а второй — за модификацию страницы (M-признак), когда в страницу что-то записывается. Значение этих признаков устанавливается аппаратно. Имеется также возможность посредством обращения к операционной системе обнулять эти признаки.
Итак, алгоритм NRU действует по следующему принципу. Изначально для всех страниц процесса признаки R и M обнуляются. По таймеру или по возникновению некоторых событий в системе происходит программное обнуление всех R-признаков. Когда системе требуется выбрать какую-то страницу для откачки из оперативной памяти, она поступает следующим образом. Все страницы, принадлежащие данному процессу, делятся на 4 категории в зависимости от значения признаков R и M.
- Класс 0: R = 0, M = 0. Это те страницы, в которых не происходило обращение в последнее время и в которых не сделано ни одно изменение.
- Класс 1: R = 0, M = 1. Это те страницы, к которым в последний период не было обращений (поскольку программно обнулен R-признак), но в этой странице в свое время произошло изменение.
- Класс 2: R = 1, M = 0. Это те страницы, из которых за последний таймаут читалась информация.
- Класс 3: R = 1, M = 1. Это те страницы, к которым за последнее время были обращения, в т.ч. обращения на запись, т.е. это активно используемые страницы.
Соответственно, алгоритм предлагает выбирать страницу для откачивания случайным способом из непустого класса с минимальным номером.
Следующий алгоритм, который мы рассмотрим, — это алгоритм FIFO. Если в системе реализован этот алгоритм, то тогда при загрузке очередной страницы в память операционная система фиксирует время этой загрузки. Соответственно, данный алгоритм предполагает откачку той страницы, которая наиболее долго располагается в ОЗУ.
Очевидно, что данная стратегия зачастую оказывается неэффективной, поскольку возможна откачка интенсивно используемой страницы. Поэтому существует целый ряд модификаций алгоритма FIFO, нацеленных на сглаживание обозначенной проблемы.
Модифицированный алгоритм может иметь следующий вид. Выбирается самая «старая» страница, затем система проверяет значение признака доступа к этой странице (R-признак). Если R = 0, то эта страница откачивается. Если же R = 1, то этот признак обнуляется, а также переопределяется время загрузки данной страницы текущим временем (иными словами, данная страница перемещается в конец очереди), после чего алгоритм начинает свою работу с начала.
Данный алгоритм имеет недостатки, связанные с ростом накладных расходов при перемещении страниц по очереди. Поэтому этот алгоритм получил свое развитие, в частности, в виде алгоритма «Часы».
Алгоритм «Часы» подразумевает, что все страницы образуют циклический список (Рис. 130). Имеется некоторый маркер, ссылающийся на некоторую страницу в списке, и этот маркер может перемещаться, например, только по часовой стрелке.
Функционирование алгоритма достаточно просто: если значение R-признака в обозреваемой маркером странице равно нулю, то эта страница выгружается, а на ее место помещается новая страница, после чего маркер сдвигается. Если же R = 1, то этот признак обнуляется, а маркер сдвигается на следующую позицию.

Рис. 130. Замещение страниц. Алгоритм «Часы».
Следующая группа алгоритмов позволяют учитывать более адекватно старение и использование страниц и, соответственно, осуществлять выбор страницы для откачки.
Алгоритм LRU (Least Recently Used — «наименее недавно» – наиболее давно используемая страница) основан на достаточно сложной аппаратной схеме и действует по следующей схеме.
Пускай имеется N страниц. Для решения задачи в компьютере имеется битовая матрица, размером N × N, которая изначально обнуляется. Когда происходит обращение к i-ой странице, то все биты i-ой строки устанавливаются в 1, а весь i-ый столбец обнуляется. Соответственно, когда понадобится выбрать страницу для откачки, то выбирается та страница, для которой соответствующая строка хранит наименьшее двоичное число.
Рассмотренный алгоритм хорош тем, что достаточно адекватно учитывает интенсивность использования страниц, но этот алгоритм требует сложной аппаратной реализации.
Альтернативой указанному алгоритму может служить алгоритм NFU (Not Frequently Used — редко использовавшаяся страница), основанный на использовании программных счетчиков страниц.
Данный алгоритм подразумевает, что с каждой физической страницей с номером i ассоциирован программный счетчик Counti. Изначально для всех i происходит обнуление счетчиков. А затем, по таймеру происходит увеличение значений всех счетчиков на величину интенсивности использования, т.е. на величину R-признака: Counti = Counti + Ri. Иными словами, если за последний таймаут было обращение к странице, что значение счетчика возрастает, иначе — не изменяется. Соответственно, для откачки выбирается страница с минимальным значением счетчика Counti.
Данная модель также является достаточно адекватной, но она имеет ряд важных недостатков. Первый связан с тем, что счетчик хранит историю: например, какая-то страница в некоторый период времени интенсивно использовалась, и значение счетчика стало настолько большим, что при прекращении работы с данной страницей значение счетчика достаточно долго не даст откачать эту страницу. А второй недостаток связан с тем, что при очень интенсивном обращении к странице возможно переполнение счетчика.
Чтобы сгладить указанные недостатки, существует модификация данного алгоритма, основанного на том, что каждый раз по таймеру значение счетчика сдвигается на 1 разряд влево, после чего последний (правый) разряд устанавливается в значение R-признака.