Основные понятия и определения.
Под параллельной ЭВМ будем понимать ЭВМ, состоящую из множества связанных определенным образом вычислительных блоков, которые способны функционировать совместно и одновременно выполнять множество арифметико-логических операций, принадлежащих одной задаче (программе).
Применительно к вычислительным системам термин"архитектура" может быть определен как распределение функций, реализуемых системой, по отдельным ее уровням
Параллелизм – это возможность одновременного выполнения нескольких арифметико-логических или служебных операций.
Определение понятия "архитектура ЭВМ"
Термин "архитектура ЭВМ" трактуется самым различным образом. Поэтому необходимо определить, что под ним будет подразумеваться.
1. Понятие "архитектура параллельной ЭВМ" включает совокупность свойств, определяющих состав и связи оборудования (структуру ЭВМ), типы используемых параллельных вычислительных алгоритмов (алгоритмику) и средства программирования (языки, трансляторы, операционные системы).
2. Применительно к вычислительным системам термин "архитектура" может быть определен как распределение функций, реализуемых системой, по отдельным ее уровням и точное определение ее границ между этими уровнями. Таким образом, если архитектуре системы отведен некоторый уровень, то в первую очередь необходимо установить какие системные функции полностью или частично выполняются компонентами системы, находящимися выше или ниже заданного уровня. После решения этой задачи следующий шаг заключается в точном определении интерфейсов для рассматриваемого уровня.
Таким образом, архитектура вычислительной системы предполагает многоуровневую организацию. Специфическим свойством архитектуры вычислительной системы является возможность выделения в ней набора уровней абстракции.
Последняя разновидность архитектуры может быть определена как мультипроцессорная архитектура (она не представлена на рисунке, поскольку отражает скорее вертикальный, чем горизонтальный разрез системы). Такая архитектура предусматривает распределение функций между группой процессоров с разграничением функций вычислительной системы между этими процессорами и определением соответствующих интерфейсов.
Приведенный здесь общий обзор архитектуры различных уровней организации вычислительной системы позволяет теперь определить термин "архитектура ЭВМ"
Основные этапы развития параллельной обработки
Идея параллельной обработки возникла одновременно в появлением
Часть 1. Параллельные процессы и вычислительные системы
Тема 1.1. Основные принципы параллельной обработки
Известны два основных метода повышения быстродействия ЭВМ: использование все более совершенной элементной базы и параллельное выполнение вычислительных операций.
Параллелизм как магистральное направление развития архитектуры ЭВМ приходит на смену «классическим» принципам построения последовательных машин, базирующихся на модели ЭВМ, предложенной Дж. Фон Нейманом. Несоответствие между принципами организации памяти в последовательной ЭВМ фон Неймана и описаниями данных и их преобразований на логическом уровне определяется как семантический разрыв. Для согласования многомерных в общем случае описаний данных с возможностями их представления в последовательной линейной памяти необходимы какие-то специальные средства. Эти средства в виде некоторых соглашений (правил), механизмов и процессов реализуются на разных уровнях языковыми, программными и аппаратными компонентами архитектуры ЭВМ. Таким образом, наводится мост между реальным многомерным и параллельным миром и последовательным в своей основе подходом к его представлению в машинных моделях.
Уровни и формы параллелизма
Рассмотрим два самых общих соображения. Во-первых, можно ожидать, что во всех без исключения реальных задачах, для решения которых необходимо использовать ЭВМ, присутствует естественный внутренний параллелизм, то есть возможность в той или иной форме распараллелить действия, связанные с преобразованием данных. Во-вторых, каждая конкретная вычислительная машина или система своими аппаратными и программными средствами поддерживает те или иные виды параллелизма обработки данных. Для наиболее общих случаев создание ЭВМ с параллельными структурами идет пока (на 1989 год) по пути реализации тех или иных универсальных видов параллелизма.
При анализе параллелизма, реализуемого на ЭВМ, выделяют несколько уровней:
1. Уровень заданий, на котором рассматривается параллельное выполнение отдельных фаз (частей) заданий, требующих различных программ и ресурсов системы.
2. Алгоритмический (программный) уровень, на котором учитывается параллелизм независимых по командам или по данным частей алгоритма.
3. Командный уровень, включающий параллелизм, реализуемый при совмещении выполнения отдельных команд или фаз команд.
4. Арифметический (разрядный) уровень, на котором обеспечивается параллельное выполнение элементарных логических операций над двоичными разрядами.
Формы параллелизма
Форма параллелизма обычно достаточно просто характеризует некоторый класс прикладных задач и предъявляет определенные требования к структуре, необходимой для решения этого класса задач параллельной ЭВМ.
Изучение ряда алгоритмов и программ показало, что можно выделить следующие основные формы параллелизма:
1. естественный или векторный параллелизм;
2. параллелизм независимых ветвей;
3. параллелизм смежных операций или локальный параллелизм.
Векторный параллелизм.
Наиболее распространенной в обработке структур данных является векторная операция (естественный параллелизм). Вектор – одномерный массив, который образуется из многомерного массива, если один из индексов не фиксирован и пробегает все значения в диапазоне его изменения. В параллельных языках этот индекс обычно обозначается знаком. Пусть, например, А, В, С - двумерные массивы. Тогда можно записать такую векторную операцию: С(*,j) = A(*,j) + B(*,j).
Возможны операции и большей размерности, чем векторные: над матрицами и многомерными массивами. Однако в параллельные ЯВУ включаются только векторные операции (сложение, умножение, сравнение и т.д.), потому что они носят универсальный характер, тогда как операции более высокого уровня специфичны и число их слишком велико для включения в любой язык. Операции высоких порядков выражаются в виде некоторой процедуры вычислений через векторные операции.
Области применения векторных операций над массивами обширны: цифровая обработка сигналов (цифровые фильтры); механика, моделирование сплошных сред; метеорология; оптимизация; задачи движения; расчеты электрических характеристик БИС и т.д.
Параллелизм независимых ветвей. Суть параллелизма независимых ветвей состоит в том, что в программе решения большой задачи могут быть выделены независимые программные части – ветви. Под независимостью ветвей понимается независимость по данным.
В параллельных языках запуск параллельных ветвей осуществляется с помощью оператора FORK M1, M2,…,ML, где M1, M2, …, ML – имена независимых ветвей. Каждая ветвь заканчивается переходом на оператор JOIN(R), выполнение которого вызывает вычитание единицы из ячейки памяти R. Так как в R предварительно записано число, равное количеству ветвей, то при последнем срабатывании оператора JOIN (все ветви выполнены) в R оказывается нуль и управление передается в ячейку, находящуюся за оператором JOIN.
В последовательных языках аналогов оператором FORK и JOIN нет, ветви размещаются в общей программе и выполняются друг за другом.
Параллелизм ветвей имеет ряд приложений: вычислительная математика, системы управления, моделирование, экономика и т.д.
Локальный параллелизм. При исполнении программы регулярно встречаются ситуации, когда исходные данные для i-й операции вырабатываются заранее, например, при выполнении (i-2)-й или (i-3)-й операции. Тогда при соответствующем построении вычислительной системы можно совместить во времени выполнение i-й операции с выполнением (i-1)-й, (i-2)-й, … операции. В таком понимании локальный параллелизм похож на параллелизм независимых ветвей, которые очень отличаются длиной и требуют разных вычислительных систем.
Количественной характеристикой локального параллелизма является число операций r, которое можно выполнить одновременно:
∞
r = ∑(1-d)(l-1)/2
k=1
где d – вероятность того, что результат некоторой операции будет использован в любой следующей за ней операции; l – длина рассматриваемой цепочки команд. Как правило, d=0,1…0.5; l=1,6…4.
Тема 1.2. Классификация параллельных ВС
Попытки систематизировать все множество архитектур начались после публикования М.Флинном первого варианта классификации вычислительных систем в конце 60-х годов и непрерывно продолжаются по сей день. Ясно, что навести порядок в хаосе очень важно для лучшего понимания исследуемой предметной области, однако нахождение удачной классификации может иметь целый ряд существенных следствий.
В самом деле, вспомним открытый в 1869 году Д.И.Менделеевым периодический закон. Выписав на карточках названия химических элементов и указав их важнейшие свойства, он сумел найти такое расположение, при котором четко прослеживалась закономерность в изменении свойств элементов, расположенных в каждом столбце и в каждой строке. Теперь, зная положение какого-либо элемента в таблице, он мог с большой степенью точности описывать его свойства, не проводя с ним никаких непосредственных экспериментов. Другим, поистине фантастическим следствием, явилось то, что данный закон сразу указал на несколько "белых пятен" в таблице и позволил предсказать существование (!) и свойства (!!) неизвестных до тех пор элементов. В 1875 году французский ученый Буабодран, изучая спектры минералов, открыл предсказанный Менделеевым галлий и впервые подробно описал его свойства. В свою очередь Менделеев, никогда прежде не видевший данного химического элемента, не только смог указать на ошибку в определении плотности, но и вычислил ее правильное значение.
Сушествующая классификация растительного и животного мира, в отличие от периодического закона, носит скорее описательный характер. С ее помощью намного сложнее предсказывать существование нового вида, однако знание того, что исследуемый экземпляр принадлежит такому-то роду/семейству/отряду/классу позволяет оправданно предположить наличие у него вполне определенных свойств.
Подобную классификацию хотелось бы найти и для архитектур параллельных вычислительных систем. Основной вопрос - что заложить в основу классификации, может решаться по-разному, в зависимости от того, для кого данная классификация создается и на решение какой задачи направлена. Так, часто используемое деление компьютеров на персональные ЭВМ, рабочие станции, мини--ЭВМ, большие универсальные ЭВМ, минисупер--ЭВМ и супер--ЭВМ, позволяет, быть может, примерно прикинуть стоимость компьютера. Однако она не приближает пользователя к пониманию того, что от него потребуется для написания программы, работающий на пределе производительности параллельного компьютера, т.е. того, ради чего он и решился его использовать. Как это ни странно, но от обилия разных параллельных компьютеров страдает, прежде всего, конечный пользователь, для которого, вроде бы, они и создавались: он вынужден каждый раз подбирать наиболее эффективный алгоритм, он испытывает на себе "прелести" параллельного программирования и отладки, решает проблемы переносимости и затем все повторяется заново.
Хотелось бы, чтобы такая классификация помогла ему разобраться с тем, что представляет собой каждая архитектура, как они взаимосвязаны между собой, что он должен учитывать для написания действительно эффективных программ или же на какой класс архитектур ему следует ориентироваться для решения требуемого класса задач. Одновременно удачная классификация могла бы подсказать возможные пути совершенствования компьютеров и в этом смысле она должна быть достаточно содержательной. Трудно рассчитывать на нахождение нетривиальных "белых пятен", например, в классификации по стоимости, однако размышления о возможной систематике с точки зрения простоты и технологичности программирования могут оказаться чрезвычайно полезными для определения направлений поиска новых архитектур.
Классификация Флинна
Самой ранней и наиболее известной является классификация архитектур вычислительных систем, предложенная в 1966 году М.Флинном. Классификация базируется на понятии потока, под которым понимается последовательность элементов, команд или данных, обрабатываемая процессором. На основе числа потоков команд и потоков данных Флинн выделяет четыре класса архитектур: SISD,MISD,SIMD,MIMD.


| SISD (single instruction stream / single data stream) - одиночный поток команд и одиночный поток данных. К этому классу относятся, прежде всего, классические последовательные машины, или иначе, машины фон-неймановского типа, например, PDP-11 или VAX 11/780. В таких машинах есть только один поток команд, все команды обрабатываются последовательно друг за другом и каждая команда инициирует одну операцию с одним потоком данных. Не имеет значения тот факт, что для увеличения скорости обработки команд и скорости выполнения арифметических операций может применяться конвейерная обработка - как машина CDC 6600 со скалярными функциональными устройствами, так и CDC 7600 с конвейерными попадают в этот класс. |
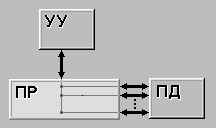
| SIMD (single instruction stream / multiple data stream) - одиночный поток команд и множественный поток данных. В архитектурах подобного рода сохраняется один поток команд, включающий, в отличие от предыдущего класса, векторные команды. Это позволяет выполнять одну арифметическую операцию сразу над многими данными - элементами вектора. Способ выполнения векторных операций не оговаривается, поэтому обработка элементов вектора может производится либо процессорной матрицей, как в ILLIAC IV, либо с помощью конвейера, как, например, в машине CRAY-1. |
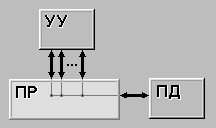
| MISD (multiple instruction stream / single data stream) - множественный поток команд и одиночный поток данных. Определение подразумевает наличие в архитектуре многих процессоров, обрабатывающих один и тот же поток данных. Однако ни Флинн, ни другие специалисты в области архитектуры компьютеров до сих пор не смогли представить убедительный пример реально существующей вычислительной системы, построенной на данном принципе. Ряд исследователей относят конвейерные машины к данному классу, однако это не нашло окончательного признания в научном сообществе. Будем считать, что пока данный класс пуст. |
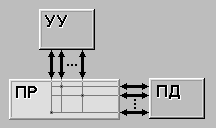
| MIMD (multiple instruction stream / multiple data stream) - множественный поток команд и множественный поток данных. Этот класс предполагает, что в вычислительной системе есть несколько устройств обработки команд, объединенных в единый комплекс и работающих каждое со своим потоком команд и данных. |
Итак, что же собой представляет каждый класс? В SISD, как уже говорилось, входят однопроцессорные последовательные компьютеры типа VAX 11/780. Однако, многими критиками подмечено, что в этот класс можно включить и векторно-конвейерные машины, если рассматривать вектор как одно неделимое данное для соответствующей команды. В таком случае в этот класс попадут и такие системы, как CRAY-1, CYBER 205, машины семейства FACOM VP и многие другие.
Бесспорными представителями класса SIMD считаются матрицы процессоров: ILLIAC IV, ICL DAP, Goodyear Aerospace MPP, Connection Machine 1 и т.п. В таких системах единое управляющее устройство контролирует множество процессорных элементов. Каждый процессорный элемент получает от устройства управления в каждый фиксированный момент времени одинаковую команду и выполняет ее над своими локальными данными. Для классических процессорных матриц никаких вопросов не возникает, однако в этот же класс можно включить и векторно-конвейерные машины, например, CRAY-1. В этом случае каждый элемент вектора надо рассматривать как отдельный элемент потока данных.
Класс MIMD чрезвычайно широк, поскольку включает в себя всевозможные мультипроцессорные системы: Cm*, C.mmp, CRAY Y-MP, Denelcor HEP,BBN Butterfly, Intel Paragon, CRAY T3D и многие другие. Интересно то, что если конвейерную обработку рассматривать как выполнение множества команд (операций ступеней конвейера) не над одиночным векторным потоком данных, а над множественным скалярным потоком, то все рассмотренные выше векторно-конвейерные компьютеры можно расположить и в данном классе.
Предложенная схема классификации вплоть до настоящего времени является самой применяемой при начальной характеристике того или иного компьютера. Если говорится, что компьютер принадлежит классу SIMD или MIMD, то сразу становится понятным базовый принцип его работы, и в некоторых случаях этого бывает достаточно. Однако видны и явные недостатки. В частности, некоторые заслуживающие внимания архитектуры, например dataflow и векторно--конвейерные машины, четко не вписываются в данную классификацию. Другой недостаток - это чрезмерная заполненность класса MIMD. Необходимо средство, более избирательно систематизирующее архитектуры, которые по Флинну попадают в один класс, но совершенно различны по числу процессоров, природе и топологии связи между ними, по способу организации памяти и, конечно же, по технологии программирования.
Наличие пустого класса (MISD) не стоит считать недостатком схемы. Такие классы, по мнению некоторых исследователей в области классификации архитектур, могут стать чрезвычайно полезными для разработки принципиально новых концепций в теории и практике построения вычислительных систем.
Тема 1.3. Определение производительности многопроцессорных вычислительных систем
Многопроцессорные системы – это сложные системы, содержащие несколько процессоров, модулей памяти, устройств ввода-вывода и сетевых соединений. Поэтому оценить производительность многопроцессорной системы достаточно сложно. Фактически одни и те же системы могут решать различные задачи разными способами, а это еще более усложняет определение оценки. Разные задачи имеют различные возможности по распараллеливанию.
Определим два вида многопроцессорной производительности. Предположим, что есть система, содержащая n процессоров. Более того, допустим, что задача, которую мы подразделяем на процессоры, может одновременно работать на n процессорах. Обозначим общее время выполнения программы на n