Многие задачи статистического анализа можно решить, не прибегая непосредственно к законам распределения случайных величин, а используя лишь их статистические характеристики. Под случайной величиной понимают такую величину, значение которой изменяются случайным образам от одного испытания к другому, причем каждое из этих значений реализуется с той или иной вероятностью. Например, ежедневное количество покупателей в магазине изменяется случайным образом изо дня в день, принимаю любые натуральные значения в некотором интервале. Наиболее часто при описание случайных величин используют такие статистические характеристики, как среднее значение, дисперсия, среднеквадратичное отклонение, медиана и скос. Среднее значение случайной величины X вычисляют по формуле:

где x1 , x2, …, xn – значение случайной величины X, n – число измерений. Оно широко используется в грубоорентировочных расчетах случайной величины, когда значение случайной величины заменяют ее средним.
Пусть, например, замеры количества покупателей в течение недели в магазинах №1 и №2 дали результаты, представленные в таблице 1 и 2 соответственно.
Таблица 1
| № п/п | Дни недели | Условное обозначение | Количество покупателей | 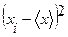
|
| 1. | Понедельник | x1 | 40*40=1600 | |
| 2. | Вторник | x2 | 20*20=400 | |
| 3. | Среда | x3 | (-20)*(-20)=400 | |
| 4. | Четверг | x4 | 50*50=2500 | |
| 5. | Пятница | x5 | (-10)*(-10)=100 | |
| 6. | Суббота | x6 | (-30)*(-30)=900 | |
| 7. | Воскресенье | x7 | (-50)*(-50)=2500 | |
| Итого |
Таблица 2
| № п/п | Дни недели | Условное обозначение | Количество покупателей | 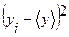
|
| 1. | Понедельник | y1 | 1*1=1 | |
| 2. | Вторник | y2 | (-2)*(-2)=4 | |
| 3. | Среда | y3 | 0*0=0 | |
| 4. | Четверг | y4 | 2*2=4 | |
| 5. | Пятница | y5 | (-3)*(-3)=9 | |
| 6. | Суббота | y6 | 3*3=9 | |
| 7. | Воскресенье | y7 | (-1)*(-1)=1 | |
| Итого |
Таким образом, в данном примере 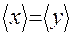 , т.е. в среднем каждый день в каждом из рассматриваемых магазинов бывает 700/7 = 100 покупателей.
, т.е. в среднем каждый день в каждом из рассматриваемых магазинов бывает 700/7 = 100 покупателей.
Важно также знать, как сильно значения изучаемой величины отличаются от ее среднего, или, иначе говоря, насколько широко разброс случайной величины. Рассеивание случайной величины вокруг ее среднего характеризует дисперсия D[x]. Чем больше дисперсия, тем «случайнее» случайная величина. Для приближенного значения дисперсии дискретной случайной величины X используют следующую формулу:
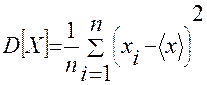
На практике часто используют и другую характеристику рассеивания – среднеквадратичное отклонение sx, вычисляемое по формуле 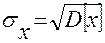 Величина sx также характеризует размах колебаний случайной величины X около среднего значения, но sx в отличие от D[X], имеет туже размерность, что и случайная величина X.
Величина sx также характеризует размах колебаний случайной величины X около среднего значения, но sx в отличие от D[X], имеет туже размерность, что и случайная величина X.
Так, например, в магазине №1 (см. данные последнего столбца табл. 1) в среднем количество покупателей (100 человек в день) отличается от средней величины на 35 человек (т.к. 8400/7=1200 и 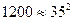 ). В магазине №2 (см. данные последнего столбца табл. 2) в среднем количество покупателей отличается от среднего значения на 2 человека (т.к. 28/7=4 и
). В магазине №2 (см. данные последнего столбца табл. 2) в среднем количество покупателей отличается от среднего значения на 2 человека (т.к. 28/7=4 и 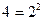 ). Таким образом, в нашем примере разброс случайной величины X. – количества покупателей в магазине №1 – около своего среднего значения достаточно велик и составляет приблизительно третью часть средней величины, в то время как разброс случайной величины Y. – количества покупателей в магазине №2 – около своего среднего значения можно пренебречь, так как оно составляет всего 2% от средней величины.
). Таким образом, в нашем примере разброс случайной величины X. – количества покупателей в магазине №1 – около своего среднего значения достаточно велик и составляет приблизительно третью часть средней величины, в то время как разброс случайной величины Y. – количества покупателей в магазине №2 – около своего среднего значения можно пренебречь, так как оно составляет всего 2% от средней величины.
Для вычисления этих и других статистических характеристик Excel располагает широким набором статистических функций. Их полный список можно получить, выбрав команду «Функция» из меню «Вставка». Применение этих функций позволяет существенно упростить статистический анализ.
Excel предусматривает также применение 18 статистических инструментов анализа, в том числе такие, как описательная статистика, гистограммы, генерация случайных чисел, корреляция, ковариация и ряд других. Эти инструменты позволяют автоматизировать анализ данных и статистических параметров. Доступ к ним можно получить, выбрав в меню «Сервис» команду «Анализ данных». Затем в диалоговом окне «Инструмент анализа» следует выбрать нужный инструмент и задать входной и выходной интервалы, а также требуемые параметры. Например, инструмент анализа «Описательная статистика» создает список одномерных статистических характеристик для данных во входном интервале. При помощи этого инструмента можно получить информацию об основной тенденции и изменчивости данных. Инструмент «Описательная статистика» генерирует, в частности, следующие выходные значения: дисперсию выборки, среднеквадратичное отклонение, медиану, моду и скос. Эти выходные данные вычисляются с помощью тех же алгоритмов, которые используются соответствующими функциями Excel. Подробнее об этих функциях можно прочитать в соответствующих разделах встроенной Справки.
Замечание: Возможно в вашей системе не установлены инструменты анализа статистических данных. В этом случае следует выбрать команду «Сервис» è «Надстройки», далее в появившемся диалоговом окне нужно установить флажок в окне «Список надстроек» для строки «Пакет анализа» и щелкнуть по кнопке «OK».