Методические рекомендации по выполнению лабораторной работы по МДК.01.01 Системное программирование для студентов 2 курса
Составитель: Токаева Я.Ю.,
преподаватель колледжа
Работа с таблицами. Представление в памяти массивов и матриц. Методические рекомендации по выполнению лабораторной работы по МДК.01.01 Системное программирование для студентов 2 курса /Составитель: Токаева Я.Ю./ ‒ Череповец: Череповецкий металлургический колледж имени академика И.П. Бардина, 2019. – 47 с.
Рецензенты:
Данная методическая разработка рассмотрена на заседании цикловой комиссии «Информационные технологии и вычислительная техника» и рекомендована к применению.
Председатель: /Молоткова Л.Н./
__________________2019 г.
Протокол №___
Содержание
| Цель работы | ||
| Средства обучение | ||
| Теоретическое обоснование | ||
| Задание | ||
| Ход работы | ||
| Рекомендации по оформлению отчета | ||
| Контрольные вопросы | ||
| Литература | ||
| Приложение А – Варианты заданий |
Лабораторная работа № 17 «Работа с таблицами. Представление в памяти массивов и матриц»
1 Цель работы: закрепление на практике принципов работы с массивами, матрицами и таблицами в языке Ассемблер на примере реализации основных операций над ними.
2 Средства обучения:
· ПЭВМ;
· методические рекомендации.
Теоретическое обоснование
Хотя Ассемблер позволяет проверять и обрабатывать биты, но, как правило, программы предназначены для обработки и хранения данных и взаимодействуют с ячейками памяти, кратным байтам (байты, слова, двойные слова, учетверенные слова, параграфы и т.д.).
Рассмотрим составные объекты данных ‒ совокупности простых объектов, объединенных под одним именем. Иногда с такими составными объектами работают как с неделимыми, но иногда могут потребоваться и их отдельные компоненты. Составные объекты данных можно разбить на два класса в соответствии с методом определения компонент.
Массивы ‒ это такие совокупности, в которых компоненты определяются по их положению внутри совокупности.
Структуры ‒ это совокупности, в которых компоненты определяются по именам.
Из этого следует, что все компоненты массивов должны иметь одинаковый тип, в то время как компоненты структуры могут быть разных типов. Значением массива является набор значений его компонент, а значением структуры ‒ набор ссылок на ее компоненты. Основные операции, которые можно применять к массивам, как к множествам ‒ объединение, пересечение, дополнение, разность, слияние, декартово произведение.
Основные операции, которые можно применять к элементам массивов ‒ вставка, удаление, сортировка, поиск элемента по заданному ключу, поиск подмассива в массиве и т.д.
Массивы предназначены для хранения данных одного типа и для удобного доступа к содержимому этих данных. Элемент массива определяется своей позицией. Позиция ‒ это отсчет смещения от начала массива. Элементы некоторого массива сами могут быть массивами ‒ тогда позиция элементов будет определяться в координатной системе более чем одного измерения. Элемент многомерного массива будет определяться несколькими индексами, например, в n-мерном массиве элементы определяются индексами. Число индексов n, требуемых для определения элемента массива, называется размерностью массива.
Одномерный массив напоминает очередь, в которой все люди обезличены, но у каждого на ладони написан порядковый номер, соответствующий расположению этого человека в очереди. Массивы отличаются от одиночных переменных одинакового типа тем, что каждая отдельная переменная имеет индивидуальное имя, а все элементы массива имеют групповое имя и различаются между собой, как люди в очереди, порядковыми номерами или индексами.
Вместо десяти переменных величиной в слово:
X1 DW 10
X2 DW 9
…
X10 DW 1
можно использовать одномерный массив:
X DW 10, 9, 8, 7, 6, 5, 4, 3, 2, 1
перечислив элементы массива после директивы описания данных. При этом в переменной хранится не одно значение, а последовательность из 10 значений типа WORD. К каждому из них можно обращаться, указывая его номер (индекс), который может быть не только числовой константой, но и любым допустимым выражением, возвращающим значение типа WORD. Элементы массива располагаются в памяти строго последовательно, друг за другом, при компиляции все упоминания переменной заменяются на физический адрес первого элемента этого массива в оперативной памяти, а все обращения к элементам массива заменяются на машинные команды сложения адреса с индексом ‒ смещением соответствующего элемента относительно начала этой последовательности. Такое смещение для первого элемента будет 0. Для второго ‒ 1 и т.д. Структура хранения, соответствующая одномерному массиву ‒ вектор. Для вычисления адреса i-ого элемента вектора используют следующую формулу:
Адрес(X[i])=Адрес(X)+(type X)*i
где Адрес(X) ‒ положение в памяти первого элемента вектора, type X ‒ размер элемента вектора в байтах. Система команд микропроцессоров семейства x86 позволяет работать с массивами размерностью 1, 2, 4 и 8 байтов. Перечисление элементов массива через запятую удобно в том случае, если таких элементов не очень много (не более двадцати). Для большого количества элементов, в том случае, если они имеют одно и тоже значение, или массив не инициализирован, используют директиву DUP. В этом случае синтаксис описания массивов в ассемблере таков:
<имя массива> D< тип> <число элементов>DUP (<значение>)
Например, директива:
X DW 20 DUP (?)
отводит в памяти 40 байт под неинициализированный массив слов X. Конструкция DUP допускает вложенность.
Директива:
A DB 20 DUP (1,2,3,0Eh,0Fh)
отводит в памяти место под массив A из ста байт. В этом массиве элементы будут заполнены 20 раз повторяющимися значениями 1,2,3,0Eh,0Fh.
Если массив должен быть проинициализирован элементами, которые имеют характер арифметической/геометрической прогрессии, тогда можно воспользоваться директивами REPT и = (таблица 1).
Таблица 1 – Арифметическая и геометрическая прогрессия
| До макрогенерации | После макрогенерации | В теле программы |
| X DB 0 K=0 REPT 999 K=K+1 DB K ENDM | X DB 0 K=0 K=K+1 DB K …999 таких пар K=K+1 DB K | X DB 0,1,2,...,998,999 |
Для инициализации значений элементов массива в процессе выполнения программы используют цикл.
Одиночная переменная выбирается из массива переменных при помощи указания индекса: a[2], a[i+1], a[0], a[i*j], причем индекс должен находится внутри границ диапазона.
Такая индексированная переменная для объектов определенного типа может употребляться повсюду, где могли бы находится простые переменные того же типа: 2*a[2], (a[i+1])2, sin(a[i*j]). С индексом также можно производить все допустимые выражения, которые возвращают целочисленные значения (например, после деления необходимо округлять результат вычисления) a[ ].
Все скалярные операции над массивами сводятся к скалярным поэлементным операциям.
Структура хранения, соответствующая двухмерному массиву, ‒ это матрица. Пусть имеется матрица Y, в которой N строк и M столбцов и все элементы матрицы ‒ двойные слова:
Y DD N DUP (M DUP(?))
Поскольку реальная память компьютера ‒ это одномерный массив, массивы размещаются в непрерывной области памяти, для обращения к элементу массива, имеющему несколько индексов, в позиции одномерной памяти назначают соответствие между последовательными ячейками памяти и элементами массива. Такое соответствие называется функцией отображения. Зависимость адреса элемента матрицы Y[i,j], расположенного в линейной памяти компьютера от индексов элемента i и j, можно выразить вот так:
Адрес(Y[i,j])=Адрес(Y)+M*(type Y)*i+(type Y)*j=Адрес(Y)+(type Y)*(M*i+j),
где Адрес(Y) ‒ положение в памяти первого элемента матрицы, type Y=4 ‒ размер элемента матрицы в байтах, а M — ширина строки. Или вот так:
Адрес(Y[i,j])=Адрес(Y)+(type Y)*i+N*(type Y)*j=Адрес(Y)+(type Y)*(i+N*j),
где N ‒ высота столбца.
Аналогично осуществляется локализация элементов в массивах большей размерности. Например, трехмерный массив Z, все элементы которого байты, размерностью N×M×K:
Z DB N DUP (M DUP (K DUP (?)))
Рассмотрим расположение в памяти трехмерного массива байтов A размером 3×2×2 относительно первого элемента массива A[0,0,0] (таблица 2).
Таблица 2 – Расположение элементов массива в памяти
| элемент | позиция | элемент | позиция | элемент | позиция | элемент | позиция |
| A[0,0,0] | A[0,1,0] | A[0,0,1] | A[0,1,1] | ||||
| A[1,0,0] | A[1,1,0] | A[1,0,1] | A[1,1,1] | ||||
| A[2,0,0] | A[2,1,0] | A[2,0,1] | A[2,1,1] |
Если трехмерный массив байтов A имеет размерность I×J×K, тогда адресация элемента A[i,j,k] (где 0 ≤ i < I, 0 ≤ j < J, 0 ≤ j < J) этого массива в одномерную память осуществляется с помощью следующей функции отображения:
Адрес(A[i,j,k])=Адрес(A)+i+I*j+I*J*k=Адрес(A)+i+I*(j+J*k)
В общем случае функция отображения для многомерного массива байтов A размером I×J×K…M×N, где где 0 ≤ i < I, 0 ≤ j < J, 0 ≤ j < J,..., 0 ≤ m < M, 0 ≤ n < N:
Адрес(A[i,j,k,...,m,n])=Адрес(A)+i+I*(j+J*(k+K*(...(m+M*n)...)))
Для указания элемента массива требуется имя массива и индексы. Нумерация элементов массива начинается с нуля. В общем случае, для получения адреса элемента необходимо начальный (базовый) адрес массива сложить с произведением индекса (номер элемента) этого элемента на размер элемента массива:
база + (индекс*размер элемента)
Для доступа к элементам одномерного массива используют индексную адресацию со смещением (смещение ‒ адрес нулевого элемента массива и индекс, который находится в индексном регистре).
Для доступа к элементам двухмерного массива используют базово-индексную адресацию со смещением (смещение ‒ адрес нулевого элемента массива, произведение ширины строки на номер столбца в базовом регистре и индекс в строке, который находится в индексном регистре).
По мере увеличения размерности массива возрастает сложность вычисления адреса. Даже для трехмерного байтового массива вычисление индекса требует трех умножений. Для упрощения вычисления адреса массива постараемся уменьшить количество операций умножения.
Во-первых, при заполнении элементов массива одинаковым значением, или для получения суммы/произведения значения всех элементов массива, или для поиска минимального/максимального элемента массива, вычислять индекс каждого элемента ни к чему. Для этих задач подходит и одномерное представление массива.
;получить в edx:eax сумму значений элементов массива A[N][M][Q]
xor eax,eax;eax=0
cdq;edx=0
mov ecx,N*M*Q;ecx = количество элементов массива A
a0: add eax,A[ecx*4-4]
adc edx,0
loop a0
Во-вторых, если действительно необходим доступ к элементам n-мерного массива ‒ создадим блок описания массива:
;номер индекса содержимое
index_1 equ I
index_2 equ I*J
index_3 equ I*J*K
......
index_m equ I*J*K*...*M
Значение произведений index_2=I*J,..., index_m=I*J*K*...*M будет вычисляться заранее, еще во время трансляции нашей программы, и в процессе выполнения программы мы не будем затрачивать на это время. При обращении к элементу массива адресный полином:
Адрес(A)+i+I*(j+J*(k+K*(...(m+M*n)...)))
будет заменен на сумму произведений:
Адрес(A)+i+index_1*j+index_2*k+...+index_m*n
В-третьих, умножение в некоторых случаях можно заменять на комбинацию из сдвигов вправо и сложения, либо на команду LEA, а также использовать возможность умножения внутри команд на 2, 4 или 8.
До сих пор рассматривались команды, в которых для операндов из памяти указывались их точные адреса (имена), например:
MOV ECX,[A]
Если исполнительный адрес берется непосредственно из 8-, 16-или 32-разрядного поля смещения в коде конкретной команды, такая адресация называется прямой.
Однако в общем случае в команде вместе с адресом может быть указан в квадратных скобках некоторый регистр, например:
MOV ECX,A[EBX]
Тогда команда будет работать не с указанным в ней адресом A, а с адресом Aисп, который вычисляется по следующей формуле:
Aисп=(A + [EBX]) mod 232
где [EBX] обозначает содержимое регистра EBX. Прежде чем выполнить команду, процессор прибавит к адресу A, указанному в команде, текущее содержимое регистра EBX, получит некоторый новый адрес Aисп и именно из ячейки с этим новым адресом возьмет новый операнд. Если в результате сложения получилась слишком большая сумма, то от нее возьмут только последние 32 бита (на это указывает операция mod в приведенной формуле).
Замена адреса A на Aисп называется модификацией адреса, а регистр, участвующий в модификации, называется регистром-модификатором.
В качестве модификатора для микропроцессоров ниже i386 можно было использовать только один из четырех регистров: BX, BP, SI или DI. Для микропроцессоров i386 и выше можно использовать любой 32-битный РОН (регистр общего назначения).
В команде ADD A[ESI],5 в роли модификатора выступает регистр ESI. Пусть в регистре ESI находится число 100. Тогда Aисп=A+[ESI]=A+100. Значит, по данной команде к числу из ячейки с адресом A+100 будет прибавлено 5.
Если исполнительный адрес вычисляется как сумма некоторого заданного смещения и содержимого индексного регистра, то такой способ адресации называется индексной адресацией. Индексная адресация часто используется для организации доступа к элементам массивов. Если исполнительный адрес вычисляется как сумма некоторого заданного смещения и содержимого базового регистра, то такой способ адресации называется относительной адресацией.
Пусть имеется массив:
X DD 100 DUP (?)
В регистр EAX требуется записать сумму его элементов. Для нахождения суммы делаем EAX равным 0, а затем в цикле выполним операцию EAX=EAX+X[i] при изменяющимся от 0 до 99. Поскольку адрес элемента X[i] равен X+4*i, то команда, соответствующая этой операции, должна быть следующей ADD EAX,[X+4*i], но транслятор не может напрямую закодировать такую команду.
Адрес меняется вместе с изменением индекса i. Разобьем переменный адрес X+4*i на постоянную составляющую X и переменную 4*i.
Постоянную составляющую запишем в команду, а переменную составляющую поместим в регистр-модификатор (например, в ECX) и название этого регистра записываем в команду в качестве модификатора:
ADD EAX,X [ECX*4-4]
Фрагмент программы нахождения суммы элементов массива X:
XOR EAX,EAX;начальное значение суммы EAX=0
MOV ECX,100;счетчик цикла и индекс массива
L: ADD EAX,X[ECX*4-4];EAX=EAX+X[i]
LOOP L;цикл 100 раз
Пусть имеется некоторая ячейка размером в слово, адрес которой не известен, но известно, что этот адрес находится в регистре EBX, и необходимо записать в эту ячейку число 300. Если бы адрес X этой ячейки был бы известен, то использовалась бы команда mov [X],300.
Команды могут работать с исполнительными адресами, возьмем такой адрес и такой модификатор, чтобы в сумме они дали этот заранее неизвестный адрес ‒ в данном случае это нулевой адрес и регистр EBX:
Aисп=0+[EBX]=0+X=X.
Задача решается командой:
mov word ptr[ebx],300
Особенность используемого способа модификации в том, что адрес представлен в виде суммы двух слагаемых, одно из которых записано в команду, а другое в регистр-модификатор. Но если ранее оба слагаемых были ненулевые, то теперь одно из слагаемых, которое помещалось в команду, нулевое, и поэтому весь адрес упрятан в регистр.
В команде указывается лишь место (регистр), где находится адрес.
Способ задания адреса через промежуточное звено называется косвенной ссылкой или косвенной адресацией.
При косвенной ссылке обычно приходится уточнять размер ячейки, на которую она указывает. Если в ячейку, адрес которой находится в регистре EBX, надо записать 0, тогда использовать для этого команду mov[ebx],0 нельзя, так как в ней непонятны размеры операндов: 0 может быть как байтом или словом, так и двойным словом, адрес из EBX также может быть адресом как байта или слова, так и двойного слова. А вот число 300000 в регистре EBX может быть только двойным словом и неоднозначности не возникает. Поэтому с помощью оператора PTR надо указать, операнды какого размера имеются в виду:
mov byte ptr[ebx],0;пересылка байта
mov word ptr[ebx],0;пересылка слова
mov dword ptr[ebx],0;пересылка двойного слова
Идея модификации обобщается на случай нескольких регистров-модификаторов. Для этого в командах указывается вместе с адресом несколько регистров-модификаторов. Максимальное количество модификаторов ‒ два, причем для микропроцессоров ниже i386 один из них обязательно должен быть регистром BX или BP, а другой обязательно SI или DI.
Например: mov ax,A[bx][si]. Для микропроцессоров i386 и выше для модификации по двум регистрам в качестве базового регистра можно использовать любой из 32-разрядных РОН, а в качестве индексного регистра ‒ любой из 32-разрядных РОН, кроме регистра ESP.
Индексный регистр можно также умножить на коэффициент scale равный 1, 2, 4 или 8.
Для 16-битного режима исполнительный адрес вычисляется по формуле:
Aисп = (A + [BX] + [SI]) mod 216.
Для 32-битного режима исполнительный адрес вычисляется по формуле:
Aисп = (A + [РОН1] + [РОН2]*scale) mod 232.
Модификация по двум регистрам обычно используется при работе с двумерными массивами. Например, в матрицу A размером 10×20 требуется записать в регистр AL количество таких строк этой матрицы, в которых начальный элемент строки встречается в ней еще раз:
A DB 10 DUP (20 DUP (?))
При расположении элементов матрицы в линейной модели памяти адрес элемента A[i, j] равен A+20*i+j. Для хранения величины 20*i отведем регистр EBX. Для хранения величины j отведем регистр ESI.
A[EBX] ‒ начальный адрес i-ой строки, A[EBX+ESI] ‒ адрес j-го элемента этой строки.
MOV AL,0;Количество искомых строк
;Внешний цикл по строкам
MOV ECX,10;Счетчик внешнего цикла
XOR EBX,EBX;Смещение от A до начала строки 20*i
L: MOV AH,A[EBX];Начальный элемент строки
PUSH ECX;Сохранить счетчик внешнего цикла
;Внутренний цикл по столбцам
MOV ECX,19;Счетчик внутреннего цикла
XOR ESI,ESI;Индекс элемента внутри строки j
L1: INC ESI;j=j+1
CMP A[EBX+ESI],AH;A[i,j]=AH?
LOOPNE L1;Цикл,пока A[i,j]<>AH, но не более 19 раз
JNE L2;AH не повторился перейти на L2
INC AL;Учет строки
;Конец внутреннего цикла
L2: POP ECX;Восстановить счетчик внешнего цикла
ADD EBX,20;На начало следующей строки
LOOP L;Цикл 10 раз
Если исполнительный адрес вычисляется как сумма некоторого заданного смещения, содержимого регистра базы и индексного регистра, такой способ адресации называется относительной индексной адресацией. В ходе выполнения программы могут меняться два компонента адреса.
Предположим, что мы работаем в 16-битном режиме. Пусть A обозначает адресное выражение, а E ‒ любое выражение (адресное или константное), тогда в языке ассемблера допустимы следующие три основные формы записи адресов в командах, которые задают следующие исполнительные адреса:
A: Aисп = A
E[M]: Aисп = (E+[M]) mod 216 M: BX, BP, SI, DI
Модификация по одному регистру: в качестве модификатора можно использовать только один из четырех регистров: BX, BP, SI или DI:
E[M1][M2]: Aисп=(E+[M1]+[M2])mod 216 M1: BX или BP; M2: SI или DI
Модификация по двум регистрам: один из них обязательно должен быть регистром BX или BP, а другой обязательно SI или DI.
Если E=0, то 0 можно опустить: 0[M]=M.
Модификация не меняет тип адреса. Если X ‒ имя байтовой переменной, то TYPE X[SI] = BYTE. Если перед модификатором указано константное выражение (1[BX]), то тип такого адреса считается неопределенным.
Кроме трех указанных способов записи адресов допускаются и другие, являющиеся производными от трех основных.
Для 32-разрядного режима:
· модификация по одному регистру:
Aисп = (E+[РОН]*scale) mod 232
· модификация по двум регистрам:
Aисп = (E+[РОН1]+[РОН2]*scale) mod 232
Соглашение об использовании квадратных скобок при записи операторов команд:
1. Запись в квадратных скобках имени регистра-модификатора (в 16-битном режиме BX, BP, SI или DI; в 32-битном режиме все 32-разрядные РОН'ы) эквивалентна выписыванию содержимого
этого регистра (имя регистра без квадратных скобок обозначает сам регистр).
2. Любое выражение можно заключить в квадратные скобки, от этого смысл не изменится, но снятие квадратных скобок может изменить смысл.
MOV ECX,[2]
MOV ECX,[A]
MOV ECX,[A+2[EBX]]
Выписывание рядом двух выражений в квадратных скобках означает сумму этих выражений:
[X][Y]=[X]+[Y]=[X+Y]
Используя эти соглашения вместе со свойством коммутативности сложения и отталкиваясь от трех основных способов записи адресов в командах, можно получить новые варианты записи адресов.
Эквивалентные формы записи одного и того же адреса:
A+1, [A+1], [A]+[1], [A][1], A[1], 1[A], [A]+1, …
Для типичного алгоритма хорошее поведение ‒ это O(2log2(n)) и плохое поведение ‒ это O(n2). Идеальное поведение для упорядочения ‒ O(n). n ‒ это количество записей, которые необходимо упорядочить. Для всех случаев рассматривается последовательность из 26 элементов-двойных слов:
array dd 10,450,320,120,180,600,50,230,340,460,550,500,130
dd 80,390,410,20,800,670,60,730,610,310,0,360,200
Блочная сортировка (Корзиночная сортировка, Bucket sort).
Сортируемые элементы делятся на конечное число отдельных блоков (корзин). Каждый блок затем сортируется отдельно. Затем элементы помещаются обратно в массив. Этот тип сортировки может обладать линейным временем исполнения O(n); требуется дополнительная память-массив до сортировки.
Массив после сортировки:
3 9 21 25 29 37 43 49
Пузырьковая сортировка.
Это простейший алгоритм сортировки с точки зрения понимания и реализации, но эффективен лишь для небольших массивов. Лучший случай при упорядочении массива из n элементов ‒ если массив отсортирован за n-1 сравнений. В худшем случае ‒ если массив отсортирован в обратном порядке ‒ при сортировке произойдет n(n-1)/2 сравнение. (Для n=26 элементов лучший случай ‒ 25, средний – 289, худший ‒ 325).
Сортировка состоит из повторяющихся проходов по сортируемому массиву. В каждом проходе элементы последовательно сравниваются попарно и, если порядок в паре неверный, выполняется обмен элементов. За первый проход просматривают все n элементов. Во втором проходе сравнивают n-1 элементов, начиная со второго, так как первый элемент находится уже на своем месте. В третьем проходе ‒ начинают с третьего элемента и т.д. Проходы по массиву повторяются до тех пор, пока на очередном проходе не окажется, что обмены больше не нужны ‒ массив полностью рассортирован. В каждом проходе элемент, стоящий не на своём месте, «всплывает» до нужной позиции, как пузырёк в воде.
.data
R dd n-1;количество неотсортированных элементов минус один
.code
mov esi,offset array;позиционируемся на массив
a2: mov ecx,R
xor ebx,ebx;флаг - были/не были перестановки в проходе
a3: mov eax,[esi+ecx*4-4];получаем значение очередного элемента
cmp [esi+ecx*4],eax;сравниваем со значением соседнего элемента
jnb a4;если больше или равен - идем к следующему элементу
setna bl;была перестановка - устанавливаем флаг
xchg eax,[esi+ecx*4];меняем значение элементов местами
mov [esi+ecx*4-4],eax
a4: loop a3;двигаемся вверх до границы массива
add esi,4;сдвигаем границу отсортированного массива
dec ebx;проверяем, были ли перестановки
jnz exit;если перестановок не было - заканчиваем сортировку
dec R;уменьшаем количество неотсортированных элементов
jnz a2;если есть еще неотсортированные элементы - начинаем новый проход
exit:
Сортировка перемешиванием (сортировка коктейлем, шейкер-сортировка, bidirectional bubble sort).
Разновидность пузырьковой сортировки. Отличается тем, что просмотры элементов выполняются один за другим в противоположных направлениях, при этом большие элементы стремятся к концу массива, а меньшие ‒ к началу. (Для n=26 элементов лучший случай – 25, средний ‒ 259 (лучше пузырьковой сортировки на 20 %), худший ‒ 325).
.data
H dd 0;верхняя граница неотсортированного массива
L dd n-1;нижняя граница неотсортированного массива
.code
xor esi,esi;нижняя граница неотсортированного массива
xor ebx,ebx;флаг - были/не были перестановки в проходе
mov ecx,L;количество неотсортированных элементов снизу минус один
a4: inc esi
call Compare_and_Swapping;сравнение и обмен значений элементов
loop a4;двигаемся вниз до границы массива
dec ebx;проверяем, были ли перестановки
jnz exit;если перестановок не было - сортировка закончена
dec L;уменьшаем количество неотсортированных элементов снизу
jz exit;достигли границы массива
dec esi;esi=L
mov ecx,esi
sub ecx,H;количество неотсортированных элементов сверху минус один
jecxz exit;если граница снизу равна границе сверху - выходим
a2: call Compare_Swapping;сравнение и обмен значений элементов
dec esi
loop a2;двигаемся вверх до границы массива
dec ebx;проверяем, были ли перестановки
jnz exit;если перестановок не было - заканчиваем сортировку
inc H;уменьшаем количество неотсортированных элементов сверху
inc esi;esi=H
mov ecx,L
sub ecx,esi;если граница снизу больше, чем граница сверху – значит
ja a4;есть еще неотсортированные элементы - начинаем новый проход
exit: …
Compare_Swapping proc;сравнение и обмен значений соседних элементов
mov eax,array[esi*4];получаем значение очередного элемента
cmp array[esi*4-4],eax;сравниваем его с соседним элементом
jna a3;если меньше или равен - идем к следующему элементу
seta bl;если была перестановка - взводим флаг
xchg eax,array[esi*4-4];меняем значения элементов местами
mov array[esi*4],eax
a3: ret
Compare_Swapping endp
Пирамидальная сортировка (Сортировка кучи, Heap sort).
Список превращается в кучу, берется наибольший элемент и добавляется в конец списка. Алгоритм сортировки делает в худшем, в среднем и в лучшем случае (т.е. гарантированно) операций при сортировке элементов. Можно рассматривать как усовершенствованную пузырьковую сортировку, в которой min-heap элемент всплывает/max-heap тонет по многим путям.
Структура данных для хранения сортирующего дерева:
16 11 9 10 5 6 8 1 2 4
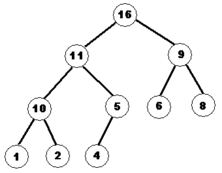
Рисунок 1 – Пример сортирующего дерева
Сортировка пирамидой использует сортирующее дерево высоты h, у которого выполнены условия:
1. Все узлы имеют высоту h или h-1 ‒ дерево сбалансированное.
2. При этом уровень h-1 полностью заполнен, а уровень h заполнен слева направо.
3. Выполняется «свойство пирамиды»: каждый элемент меньше, либо равен родителю.
4. Удобная структура данных для сортирующего дерева ‒ такой массив A, где A[i] ‒ элемент-предок, а элементы-потомки ‒ это A[2i] и A[2i+1], то есть каждый элемент-предок находится слева от своих элементов-потомков
Алгоритм состоит из двух основных фаз:
1. Элементы массива выстраиваются в виде сортирующего дерева:
A[i] ≥A[2i] и A[i] ≥A[2i+1] при 1 ≤ i ≤ n/2
Эта фаза требует O(n) операций.
2. Корневые элементы удаляются по одному и каждый раз дерево перестраивается. На первом шаге элементы A[1] и A[n] обмениваются значениями, а процедура heap_sort преобразует элементы от A[1] до A[n-1] в сортирующее дерево. Затем переставляют A[1] и A[n-1], элементы от A[1] до A[n-2] снова преобразуются в сортирующее дерево. Процесс продолжается до тех пор, пока в сортирующем дереве не останется ни одного элемента. Тогда элементы от A[1] до A[n] – это упорядоченная последовательность.
Эта фаза требует O(2log2(n)) операций.
.data
L dd n/2-1;левая граница неотсортированного массива
R dd n-1;правая граница неотсортированного массива
.code
;массив преобразуется в отображение пирамиды - вызвать процедуру
;down_heap n/2 раз для преобразования массива в пирамиду
b0: call down_heap
dec L;while (L > 0) L--;
jnz short b0
;собственно пирамидальная сортировка
dec L;L=0
dec R;R=n-2
b1: mov edx,R;отправляем значение максимального
mov eax,array;элемента в конец массива
xchg eax,array[edx*4+4]; array[0] <--> array[R];
mov array,eax
call down_heap;восстанавливаем пирамиду - на ее
;вершине появляется новое максимальное значение
dec R;уменьшаем индекс последнего элемента
jnz short b1;while (R > 0) R--;
b2:...
;-----------------------------------------------------
down_heap proc; процедура вставки элемента на свое место в пирамиду
mov eax,L
mov ebx,eax;i = L;
shl eax,1;j = 2*L;
mov esi,array[eax*2];item = array[L];
cmp eax,R;if(j<R && array[j] < array[j+1]) j++;
jnb short a0
mov edx,array[eax*4]
cmp edx,array[eax*4+4];array[j] < array[j+1]?
jnb short a0
; условие j<R && array[j]<array[j+1] выполнилось
inc eax;j++
a0: cmp eax,R;while(jЈR && item < array[j])
ja short a1
mov edi,array[eax*4]
cmp esi,edi;item < array[j]?
jnb short a1
; условие j<=R && item < array[j] выполнилось
mov array[ebx*4],edi;array[i] = array[j];
mov ebx,eax;i = j;
shl eax,1;j = 2*j;
cmp eax,R
jnb short a0;if(j<R && array[j] < array[j+1]) j++;
mov edx,array[eax*4]
cmp edx,array[eax*4+4]
jnb short a0
; условие j<R && array[j] < array[j+1] выполнилось
inc eax;j++
jmp short a0
a1: mov array[ebx*4],esi;array[i] = item;
retn
down_heap endp
Для n=26 элементов лучший случай ‒ 25, средний – 109 (лучше пузырьковой сортировки почти в 3 раза), худший ‒ 325.
Сортировка прямым включением (Сортировка вставками, Insertion sort).
Преимущества:
· простота реализации;
· эффективен на небольших наборах данных;
· эффективен на наборах данных, которые уже частично отсортированы;
· сортировка не меняет порядок элементов, которые уже отсортированы;
· можно сортировать список по мере его получения.
На каждом шаге алгоритма выбирается один из элементов входных данных, начиная со второго, и вставляется на нужную позицию в уже отсортированной левой части списка до тех пор пока набор входных данных не будет исчерпан. Выбор очередного элемента, выбираемого из исходного массива ‒ произволен, можно использовать практически любой алгоритм выбора. Для n=26 элементов лучший случай – 25, средний ‒ 172 (лучше пузырьковой сортировки на 40%), худший – 325.
mov esi,4;i=1
a4: push esi
a3: mov eax,array[esi-4]
cmp eax,array[esi]
jb a2
xchg eax,array[esi]
sub esi,4;двигаемся к началу массива
mov array[esi],eax
jnz a3
a2: pop esi
add esi,4;двигаемся к концу массива
cmp esi,n*4;просмотрели весь массив?
jb a4
Алгоритм можно улучшить, пользуясь тем, что готовая последовательность уже упорядочена. Место вставки нового элемента можно найти значительно быстрее, если применить бинарный поиск, исследовав сперва средний элемент упорядоченной последовательности и продолжая деление пополам, пока не будет найдено место вставки. Для n=26 элементов лучший случай ‒ 25, средний и худший – 106 (лучше пузырьковой сортировки почти в 3 раза).
mov ebx,1;ebx - граница неотсортированного массива
b1: mov edi,ebx
mov edx,edi;edi индекс первого элемента отсортированного массива
xor esi,esi;esi индекс последнего элемента отсортированного массива
mov eax,array[ebx*4]
cmp eax,array[ebx*4-4]
jnb b2
b6: cmp esi,edi;проверка esi>edi на завершение поиска
jg b5;проверены все элементы, вставляем новый элемент
shr edx,1;индекс центрального элемента равен (edi+esi)/2
cmp array[edx*4],eax;сравниваем с искомым значением
ja b3;array[edx*4]<eax
jz b5;array[edx*4]=eax
inc edx;учтем только что проверенное значение
mov esi,edx;изменяем нижнюю границу поиска
add edx,edi;создаем индекс центрального элемента
jmp short b6;переходим к следующему элементу
b3: dec edx;учтем только что проверенное значение
mov edi,edx;изменяем верхнюю границу поиска
add edx,esi;создаем индекс центрального элемента
jmp b6;переходим к следующему элементу
b5: mov ecx,ebx;сдвигаем отсортированные элементы, чтобы
sub ecx,esi;освободить место для нового элемента
shl esi,2; esi=esi*4
push eax
b7: mov eax,array[esi+ecx*4-4];сдвиг отсортированных элементов
mov array[esi+ecx*4],eax
loop b7
pop eax
mov array[esi],eax;вставляем новый элемент
b2: inc ebx
cmp ebx,n
jb b1
Сортировка прямым выбором.
Алгоритм сортировки, относящийся к неустойчивым алгоритмам сортировки. На массиве из n элементов время выполнения в худшем, среднем и лучшем случае (n2-n)/2.
Шаги алгоритма:
1. находим минимальное значение в текущем списке;
2. производим обмен этого значения со значением на первой позиции;
3. сортируем «хвост» списка, исключив из рассмотрения уже отсортированный первый элемент.
mov edi,offset array;edi = указатель на массив
mov ecx,N;ecx = количество элементов
a0: lea ebx,[edi+ecx*4];ebx = максимальный индекс в проходе+1
mov eax,[edi];eax=min=величина первого элемента в проходе
a1: sub ebx,4;двигаемся по проходу вверх
cmp eax,[ebx]
jbe a2;min > array[ebx]?
xchg eax,[ebx];swap(array[ebx],min)
a2: cmp ebx,edi
jnz a1;проход закончился?
stosd;mov [edi],eax edi=+4 на первой позиции минимальный элемент
loop a0
Пирамидальная сортировка сильно улучшает базовый алгоритм, используя структуру данных «куча» для ускорения нахождения и удаления минимального элемента.
Существует также двунаправленный вариант сортировки методом вставок, в котором на каждом проходе отыскивается и устанавливается на своё место и минимальное, и максимальное значения.
Сортировка Шелла.
Алгоритм сортировки, идея которого состоит в сравнении элементов, стоящих не только рядом, но и на расстоянии друг от друга.
При сортировке Шелла сначала сравниваются и сортируются между собой элементы, отстоящие друг от друга на некотором расстоянии d1. После этого процедура повторяется при значениях d2 меньших, чем d1, сортировка завершается упорядочиванием элементов при dn=1 (то есть, обычной сортировкой вставками).
Пусть дан список A=(a1, a2, a3, …, a15) и выполняется его сортировка методом Шелла, а в качестве значений d1, d2 и d3 выбраны 5, 3, 1. На первом шаге сортируются подсписки A, составленные из всех элементов A, различающихся на 5 позиций. В полученном списке на втором шаге вновь сортируются подсписки из отстоящих на 3 позиции элементов. Процесс завершается обычной сортировкой вставками получившегося списка.
Выбор длины промежутков.
Среднее время работы алгоритма зависит от длин промежутков (d), на которых будут находится сортируемые элементы исходного списка на каждом шаге алгоритма. Существует несколько подходов к выбору этих значений (n ‒ длина сортируемого списка):
· при выборе последовательности значений d1=n/2, d2= d1/2, …, 1 в худшем случае алгоритм выполнит O(n2) – сравнений 140:
Table dd 32768,16384,8192,4096,2048,1024,512,256,128,64,32,16,8,4,2,1
· все значения (3j-1)/2<n, j 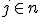 n; такая последовательность шагов приводит к алгоритму класса O(n3/2) ‒ сравнений 108:
n; такая последовательность шагов приводит к алгоритму класса O(n3/2) ‒ сравнений 108:
Table dd 797161,265720,88573,29524,9841,3280,1093,364,121,40,13,4,1
· все значения 2i3j<n, i, j n, в порядке убывания; в таком случае сложность алгоритма понижается до O(nlog2n)
· последовательность из 9*2S-9*2s/2+1, если S четное и 8*2S-6*2(s+1)/2+1если S нечетное. При использовании таких приращений среднее количество операций O(n7/6), в худшем случае – порядка O(n4/3)
· последовательности вида Nk+1=2*Nk+1 ‒ сравнений 118:
Table dd 32767,16383,8191,4095,2047,1023,511,255,127,63,31,15,7,3,1
· последовательность Дж. Инсерпи и Р. Седгевика ‒ сравнений 115:
Table dd 198768,86961,33936,13776,4592,1968,861,336,112,48,21,7,3,1
;------------------------------------------------
mov ecx,-17;в таблице приращений 16 элементов
entry: inc ecx
jz exit; если последний элемент в таблице - выход из программы
cmp [Table+ecx*4+64],n; ищем максимальное приращение (gap),
jge entry;соответствующее размеру нашего массива
a6: mov edx,[Table+ecx*4+64];получаем очередное приращение из таблицы
shl edx,2;выбрали интервал,у нас двойные слова,поэтому edx=edxґ4
a2: mov ebx,edx;i=gap
a3: mov esi,ebx
sub esi,edx;j=i-gap
a4: mov eax,array[esi];for(i=gap;i<dim;i++)/*проход массива*/
cmp eax,array[esi+edx];сравнение пар,отстоящих
jbe a5;на gap друг от друга
xchg eax,array[esi+edx];swap(a[j],a[j+gap])
mov array[esi],eax
sub esi,edx;j-=gap
jge a4
a5: add ebx,4;i++
cmp ebx,n*4;i < dim
jb a3;for(j=i-gap; j>=0 && a[j] > a[j+gap]
inc ecx
jnz a6
exit:
Сортировка Хоара (быстрая сортировка).
Сортировка даёт в средн<