Краткие теоретические сведения.
Обязательным условием хорошо спланированного экспериментального исследования является проведение рандомизации. Дословный перевод английского "random" означает "сделанный или выбранный наугад, случайный, беспорядочный". По некоторым данным, на сегодняшний день около 20% статей, публикуемых в ведущих медицинских журналах мира, содержат результаты рандомизированных исследований. Под рандомизацией понимают процедуру, обеспечивающую случайное распределение больных в экспериментальную и контрольную группы. Следует особо подчеркнуть, что рандомизацию проводят уже после того, как больной включен в испытание в соответствии с протоколом клинического исследования. Специалисты, занимающиеся этой проблемой, подчеркивают, что случайное, или рандомизированное, разделение не является синонимом беспорядочного, при котором процесс разделения не поддается математическому описанию. Рандомизация считается плохо организованной при разделении больных на группы по номеру истории болезни, страхового полиса или дате рождения. Лучше всего пользоваться таблицей случайных чисел, методом конвертов или путем централизованного компьютерного распределения вариантов лечения. К сожалению, упоминание о процессе рандомизации не означает правильного ее проведения. Очень часто в статьях не указывается способ рандомизации, что ставит под сомнение хорошую организацию исследования.
Некоторые исследователи предпочитают перед началом испытания распределить пациентов по подгруппам с одинаковым прогнозом и только потом рандомизировать их отдельно в каждой подгруппе (стратификационная рандомизация). Корректность стратификационной рандомизации признается далеко не всеми.
Пример выполнения
Имеются данные о пациентах, поступивших в больницу для трансплантации сердца. Данные содержатся в файле Heart.sta и имеют вид:

Рисунок 20
Первые три столбца в этой таблице есть даты трансплантации сердца (в следующей последовательности: месяц-день-год), 4, 5 и 6 столбцы – даты, когда соответствующий пациент либо умер, либо был изъят из наблюдения (иными словами, цензурирован, например, с пациентом была утрачена связь).
Переменная Цензурировано – Censored является индикатором цензурирования с кодом, который показывает, является соответствующее наблюдение завершенным или цензурированным (0-завершенно, т.е. пациент умер; 1-цензурированное). Переменная Age – возраст пациента, Antigen – показатель несовместимости антигенов, Mismatch – степень несовместимости тканей.
Переменная Hospital представляет собой фиктивную группирующую переменную, которая показывает, к какой из трех больниц относится пациент.
Рандомизация
Рандомизация – формирование случайной выборки по исходной таблице данных. Из имеющихся данных будем выделять произвольные подмножества различными методами.
Подмножество
В меню Данные выберем команду Подмножество.

Рисунок 21
Условия выбора наблюдений. Выберем переменные и определим условия выбора наблюдений в активном файле данных.
Предположим, что нас интересуют данные по больным, находящихся только в больнице ST_AND. Нажав кнопку Наблюдения, укажем заданное нами условие и нажмем OK.

Рисунок 22

Рисунок 23
В результате, получим данные, относящиеся только к интересующей нас больнице.

Рисунок 24
Случайный выбор
В меню Данные выберем команду Случайный выбор.
В этом диалоге находятся три вкладки: Простой выбор, Стратифицированный и Параметры.
Вкладка Простой выбор
1) Простая случайная выборка. При выборе этого правила, данные будут выбираться случайным образом.
Существует два способа выбора подмножества в общей совокупности: указав процент наблюдений или указав приблизительное число наблюдений (данный параметр устанавливается в меню Опции). Предположим, мы хотим проанализировать 40% пациентов.

Рисунок 25
После нажатия кнопки OK, получим следующие результаты:

Рисунок 26
Поставив флажок в поле Выбор с возвращением, получим следующий результат: при включении наблюдения в подмножество, это наблюдение снова попадает в исходное множество наблюдений (таким образом, одно наблюдение может встретиться несколько раз в итоговом подмножестве).
2) Систематический случайный выбор. Используя данный метод, подмножество будет составляться с помощью систематического случайного выбора.
Например, если ввести число 5 в поле K=, то среди первых пяти наблюдений будет случайным образом выбрано одно, а затем STATISTICA будет выбирать каждое пятое наблюдение в исходном множестве данных.

Рисунок 27
3) Разделенный случайный выбор. При выборе данного метода, все наблюдения будут случайным образом разделены на два файла данных. Необходимо указать процент наблюдений или приблизительное число наблюдений (данный параметр устанавливается в меню Опции).

Рисунок 28
Вкладка Стратифицированный
С помощью данной опции будет создана стратифицированная случайная выборка на основе текущего файла данных. Можно указать несколько стратифицирующих переменных, которые содержат целочисленные кодовые значения, определяющие отдельные группы (страты).
Стратифицированная выборка будет построена на основе комбинации всех кодов во все стратифицирующих переменных.
Например, выбрав в качестве переменных расслоения CENSORED и HOSPITAL, будут созданы различные доли выборок для комбинаций COMPLETE-HILLVIEW, COMPLETE- ST_AND, COMPLETE-BINER, CENSORED-HILLVIEW, CENSORED-ST_AND, CENSORED-BINER.
Опция Равные вероятности отмечается для выбора одной и той же доли наблюдений во всех группах. Предположим, общий (для всех групп) процент наблюдений в выборках составляет 50% (возможно также задание приблизительного числа наблюдений).

Рисунок 29
Таким образом будет создана стратифицированная случайная выборка.
Рассмотрим некоторые опции вкладки Параметры:
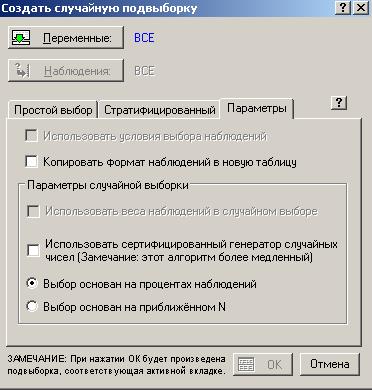
Рисунок 30
1) Использовать условия выбора наблюдений. Если вы выбрать эту опцию, то условия выбора наблюдений, заданные при нажатии кнопки Наблюдения в диалоге будут применяться перед созданием подмножества.
Чтобы игнорировать условия выбора наблюдений, следует убрать отметку этой опции
2) Копировать формат наблюдений в новую таблицу. Отметив эту опцию, формат ячеек будет копироваться в новое подмножество.
3) Использовать веса наблюдений в случайном выборе. Если в текущей Таблице данных заданы веса наблюдений, можно интерпретировать эти веса как множители наблюдений. В этом случае, соответствующая дробная выборка будет эффективно подогнана к весам наблюдений.
4) Использовать сертифицированный генератор случайных чисел. STATISTICA использует очень точный и качественный генератор случайных чисел в тех случаях, когда необходимо провести некоторые процедуры.
Однако в большинстве процедур случайного выбора или стратифицированного случайного выбора можно использовать более простые и быстрые методы случайного выбора наблюдений. В частности, при работе с очень большими файлами данных можно убрать отметку этой опции для ускорения работы.
5) Выбор основан на процентах наблюдений. При выборе этой опции файл данных разделяется на основе процента наблюдений.
6) Выбор основан на приближенном N. При выборе этой опции файл данных разделяется на основе числа наблюдений.