Первым стандартным системным интерфейсом для ПК на основе ЦП IA-32 следует считать ISA (Industry Standard Architecture - Архитектура промышленного стандарта). ISA представляет собой шину, используемую в IBM PC -совместимых ПК для обеспечения питания и взаимодействия плат расширения с системной платой, в которую они вставляются. Полное описание шины, включая ее временные характеристики, было издано в виде стандарта IEEE P996-1987.
Первый вариант этой архитектуры для ЦП 8086/8088 с тактовой частотой 4,77 МГц представлял собой 62-контактную шину с 8 линиями данных, 20 линиями адреса, сигналами для прерываний и запросов и подтверждения DMA, а также линиями питания и сигналами синхронизации.
У процессора 80286, применявшегося в IBM PC AT, была 16-разрядная шина данных, поэтому системная шина была расширена дополнительным 36-контактным соединителем, который обеспечивал еще восемь линий данных, еще четыре линии адреса, дополнительные линии прерываний и каналов DMA. На эту шину был выведен тактовый сигнал с частотой 8 МГц. Таким образом, теоретическая максимальная скорость передачиданных на шине ISA составляет 16 Мбайт/с, хотя чаще утверждается, что она составляет 8 Мбайт/с, поскольку один цикл шины обычно требуется для передачи адреса, а другой - для передачи 16 разрядов данных. На самом деле, типичная скорость передачи данных на этой шине составляет от 1 до 2,5 Мбайт/с. Это значение обусловлено конфликтами на шине с другими устройствами, главным образом, с памятью, а также задержками буферизации из-за асинхронного характера шины (быстродействие процессора и шины различается).
Появление 32-битных процессоров Intel-386 и Intel-486 показало, что быстродействие магистрали ISA является сдерживающим фактором на пути повышения производительности компьютеров. В 1989 году группой компаний (Compaq, Hewlett Packard, NEC и др.) было предложено эволюционное развитие архитектуры ISA - шина EISA (Extended ISA). С одной стороны, EISA имела все преимущества высокопроизводительной 32-битной шины, а с другой - была полностью совместима с ISA "сверху вниз" и не требовала перехода на новую элементную базу. Разработчики магистрали EISA позаботились не только об информационной и электрической, но и о конструктивной совместимости с ISA. Разъем EISA состоит из двух рядов контактов, один из которых (верхний) предназначен для сигналов ISA, а другой (нижний) - для дополнительных сигналов EISA (16 дополнительных разрядов данных, 8 дополнительных разрядов адреса, сигналы управления пакетной передачей данных и сигналы управления арбитражем магистрали). Таким образом, в разъемы EISA можно вставлять также 8- или 16-разрядные платы ISA. Предельная скорость передачи (33 МГц) достигается в пакетном режиме, когда адрес предоставляется только в начале пакета и предполагается, что все последующие данные будут поступать в расположенные по порядку ячейки памяти. На магистрали может находиться несколько задатчиков (ЦП, контроллер DMA, контроллер регенерации динамической памяти и др.). Управление предоставлением магистрали централизованно выполняется специальным арбитром по циклическому принципу. Для арбитража используются особые линии магистрали, индивидуальные для каждого разъема.
Альтернативная системная архитектура MCA (Micro Channel Architecture - Микроканальная архитектура) была предложена IBM в 1987 году в серии ПК PS/2. Основным достоинством MCA по сравнению с ISA было увеличение разрядности шины данных до 32 бит. При мультиплексированном использовании шины адреса (32 бит) допускается расширение шины данных до 64 бит. Как и в EISA, в MCA предусмотрена возможность включения многих задатчиков, но арбитраж при этом является не централизованным, а распределенным, причем приоритеты могут устанавливаться программным путем.
MCA не зависит от типа процессора и является полностью асинхронной. Эта магистраль, кроме ПК IBM PS/2, применялась также в рабочих станциях IBM RS/6000 и в высокопроизводительных компьютерах серии Power Parallel SP2 (например, Deep Blue).
Для магистрали MCA предусмотрена автоматическая конфигурация системы. При этом пользователь может изменять и назначать приоритеты различных устройств. Для увеличения скорости передачи в режиме DMA используется специальный блочный режим (burst mode).
Однако эта шина не нашла широкого распространения, возможно, потому, что компания IBM (по крайней мере, первоначально) взимала слишком большую лицензионную пошлину за ее применение, а также потому, что существовавшие тогда платы адаптеров ПК невозможно было использовать на этой шине, вследствие чего потребителям приходилось приобретать все новые платы, а производителям -заново их разрабатывать.
В типичной системе на основе Intel-386/486 (рис. 14.1) использовались раздельные шины для памяти и устройств ввода-вывода, что позволяло максимально задействовать возможности оперативной памяти и обеспечивало максимальную скорость работы с ней. Однако в таком случае устройства, подключенные через описанные системные интерфейсы, не могут достичь скорости обмена, сравнимой с процессором. В основном это требуется для видеоадаптеров и контроллеров накопителей. Для решения проблемы была предложена архитектура на основе локальных шин (рис. 14.2), которые непосредственно связывали процессор с контроллерами периферийных устройств.
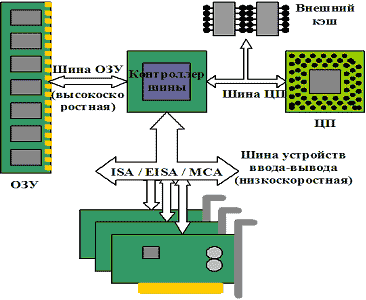
Рис. 14.1. Типичная система с низкоскоростной шиной устройств ввода-вывода

Рис. 14.2. Система с архитектурой локальной шины (VLB)
Наиболее распространенными локальными шинами считались VLB и PCI. VLB (VESA3 Local Bus) представляет собой расширение шины процессора без промежуточных буферов, что резко ограничивает ее нагрузочную способность (2-3 устройства). VLB имеет 32-разрядную шину данных и 32-разрядную шину адреса. Арбитр магистрали не предусмотрен. Достоинством VLB является простота и низкая стоимость. Позднее была также разработана спецификация VLB2, ориентированная на системы на основе Intel Pentium, (64-разрядная шина данных, тактовая частота до 50 МГц, поддержка Plug & Play), однако широкого применения эта разработка не нашла, т.к. была вытеснена шиной PCI.
Интерфейс PCI
Доминирующее положение на рынке ПК занимают системы на основе шины PCI (Peripheral Component Interconnect - Взаимодействие периферийных компонентов). Этот интерфейс был предложен фирмой Intel в 1992 году (стандарт PCI 2.0 - в 1993) в качестве альтернативы локальной шине VLB /VLB2. Следует отметить, что разработчики этого интерфейса позиционируют PCI не как локальную, а как промежуточную шину (mezzanine bus), т.к. она не является шиной процессора. Поскольку шина PCI не ориентирована на определенный процессор, ее можно использовать для других процессоров. Шина PCI была адаптирована к таким процессорам, как Alpha, MIPS, PowerPC и SPARC. Именно PCI сменила NuBus на платформе Apple Macintosh.
Шины ISA, EISA или MCA могут управляться шиной PCI с помощью моста сопряжения (рис. 14.3), что позволяет устанавливать в ПК платы устройств ввода-вывода с различными системными интерфейсами. Например, в чипсете Intel Triton использовалась микросхема PIIX4, помимо контроллера IDE предоставляющая мост для шины ISA.

Рис. 14.3. Система на основе PCI
Существуют три варианта плат PCI: с уровнями сигналов 3,3 В, с уровнями сигналов 5 В и универсальные. Ключ в разъеме гарантирует, что платы с одним уровнем сигнала и невзаимозаменяемые не будут по ошибке вставлены в разъем с другим уровнем сигнала. Платы с пониженным напряжением питания в основном используются в мобильных компьютерах.
Существует 32-разрядная и 64-разрядная реализация шины PCI. В 64-разрядной реализации используется разъем с дополнительной секцией. 32-разрядные и 64-разрядные платы можно устанавливать в 64-разрядные и 32-разрядные разъемы и наоборот. Платы и шина определяют тип разъема и работают должным образом. При установке 64-разрядной платы в 32-разрядный разъем остальные выводы не задействуются и просто выступают за пределы разъема.
На шине PCI сигналы адреса и данных мультиплексированы, поэтому для передачи каждых 32 или 64 разрядов требуется два шинных цикла: один - для пересылки адреса, а второй - для пересылки данных. Однако возможен также пакетный режим, при котором вслед за одним циклом передачи адреса разрешается осуществить до четырех циклов передачи данных (до 16 байт в PCI -32). После этого устройство должно подать новый запрос на обслуживание и снова получить управление над шиной (и выполнить адресный цикл). Поэтому шина PCI -32 с тактовой частотой 33 МГц имеет пиковую скорость обычной передачи около 66 Мбайт/с (два шинных цикла для передачи 4 байт) и пиковую скорость пакетной передачи около 105 Мбайт/с.
PCI поддерживает процедуру прямого доступа к памяти ведущего устройства на шине (bus mastering DMA), хотя некоторые реализации PCI могут и не предоставлять такую возможность для всех разъемов PCI. Процессор может функционировать параллельно с периферийными устройствами, являющимися ведущими на шине.
Кроме того, платы PCI поддерживают:
· автоматическую конфигурацию Plug&Play (не требуют назначения адресов расширений BIOS вручную);
· совместное использование прерываний (когда один и тот же номер прерывания может использоваться разными устройствами);
· контроль четности сигналов шины данных и адресной шины;
· конфигурационную память от 64 до 256 байт (код производителя, код устройства, код класса (функции) устройства и др.).
Персональные компьютеры могут иметь две или больше шин PCI. Каждой шиной управляет свой мост PCI, что позволяет устанавливать в компьютер больше плат PCI (вплоть до 16 - ограничение адресации). Если управление второй шиной PCI осуществляется с первой шины, то это называется каскадной или иерархической схемой. В этом случае первая шина будет также нести нагрузку второй шины. Если управление каждой шиной PCI осуществляется непосредственно с шины процессора, это называется равноправной схемой. Обычно мост PCI выполняет также функции контроллера внешней кэш-памяти, контроллера основной памяти и обеспечивает сопряжение с процессором. В системах на основе Pentium II/III эти функции распределены между двумя мостами: "северным" (North Bridge) и "южным" (South Bridge), что связано с наличием дополнительного высокоскоростного системного интерфейса для подключения видеокарты (AGP).
В 1995 году был выпущена улучшенная версия интерфейса - PCI 2.1, которая предоставила следующие возможности:
· поддержка тактовой частоты шины 66 МГц;
· таймер обработки множественных запросов MTT (Multi-Transaction Timer) позволяет устройствам, осуществляющим прямой доступ к памяти, удерживать шину для "прерывистой" передачи пакетов, при этом не требуется повторно добиваться права управления шиной, что особенно полезно при передаче видеоданных;
· пассивное разъединение (Passive Release) позволяет устройствам, осуществляющим прямой доступ к памяти по шине PCI, передавать данные в то время, когда ведется передача данных по шине ISA (обычно это приводило к блокированию передачи по шине PCI, поскольку она использовалась для подключения центрального процессора к шине ISA);
· задержанные транзакции PCI позволяют передаваемым данным ведущего устройства на шине PCI получать приоритет над ожидающими в очереди данными для передачи с PCI на ISA (которые будут переданы позже);
· повышение производительности записи благодаря оснащению PCI-чипсета буферами большего объема, поэтому транзакции могут выстраиваться в очередь, когда шина PCI занята, и происходит сбор байтов, слов и двойных слов, которые могут объединяться в единую 8-байтную операцию записи.
C 2005 года в ПК на основе Pentium 4 вместо PCI используют новый системный интерфейс - PCI Express.