Линейные однонаправленные списки являются динамической структурой данных, каждый элемент которой состоит из информативной и ссылочной части. Ниже представлено описание динамической строки символов.
type
TypeOfElem= Char;
Assoc= ^DynElem;
DynElem= record
Elem: TypeOfElem;
NextElem: Pointer
end;
DynStr= Assoc;
На практике, для обработки динамических строк вводят два указателя: на начало и конец (текущий элемент) цепочки.
var HeadOfStr: Pointer; ElemOfStr: DynStr;
Для создания цепочки выполняется последовательность операторов, связанная с начальным указателем.
new(ElemOfStr); ElemOfStr^.Elem:= ▒▓; ElemOfStr^.NextElem:= nil; HeadOfStr:= ElemOfStr;
Для создания каждого следующего элемента списка должна быть выполнена следующая последовательность операторов:
new(ElemOfStr^.NextElem); ElemOfStr:= ElemOfStr^.NextElem; ElemOfStr^.Elem:= ▒▓;
ElemOfStr^.NextElem:= nil; {признак конца списка}
Для поиска заданного элемента строки необходимо просмотреть последовательные звенья цепочки и сравнить значение информативного поля каждого из них с заданным. Этот процесс может окончиться при получении следующих результатов:
1. очередной элемент списка содержит заданный элемент; тогда значение функции √ истинно, а также известно значение ссылки на это звено;
2. список исчерпан и заданное значение информационного поля элемента не найдено; при этом значение функции ложно.
function FoundElem(st: DynStr; Info: TypeOfElem; var Result: Pointer): Boolean;
var q: DynStr;
begin
FoundElem:= False;
Result:= nil;
q:= st^.NextElem;
while (q <> nil) and (Result= nil) do begin
if q^.Elem= Info then begin
FoundElem:= True;
Result:= q
end;
q:= q^.NextElem
end
end;
Операция удаления элемента списка должна решать две задачи:
1. изменение ссылки предыдущего элемента так, чтобы она указывала на следующий;
2. уничтожение элемента с помощью функции dispose.
procedure DelElem(ElemOfStr: DynStr);
var q, p: DynStr;
begin
if ElemOfStr^.NextElem <> nil then begin
q:= ElemOfStr^.NextElem;
p:= ElemOfStr^.NextElem;
ElemOfStr^.NextElem:= p^.NextElem;
dispose(q);
end
end;
Для вставки элемента в список необходимо выполнить следующую последовательность действий:
1. создать новый динамический объект, который будет представлять элемент списка;
2. инициализировать информационное поле нового элемента;
3. полю ссылки нового элемента присвоить значение поля ссылки того элемента, после которого вставляется новый;
4. полю ссылки элемента, после которого вставляется новый присвоить значение ссылки на новый элемент.
procedure InclElem(Info: TypeOfElem; ElemOfStr: DynStr);
var q:DynStr;
begin
if not (ElemOfStr= nil) then begin
new(q);
q^.NextElem:= ElemOfStr^.NextElem;
q^.Elem:= Info;
ElemOfStr^.NextElem:= q
end
end;
Рассмотрим процедуру вставки нового элемента в список в позицию, зависящую от значения информационного поля нового элемента. Такой алгоритм наполнения списка повлечет за собой его упорядоченность. Очевидно, что в момент вставки нового элемента нужно рассмотреть четыре ситуации, связанные со следующими состояниями списка:
1. пустой список; в этом случае для вставки первого элемента потребуется лишь скопировать содержимое ссылки на начало списка в связывающее поле записи и после этого скопировать ссылку на запись в область памяти, которая указывает на начало списка;
2. список не пуст, а из сравнения информационных полей элементов списка с соответствующим полем нового элемента следует, что его нужно вставить в начало; в этом случае применяется последовательность действий, описанная в п. 1;
3. список не пуст, а элемент нужно вставить в конец; в этой ситуации необходимо скопировать ссылку на новую запись в связывающее поле записи, стоящей в данный момент в конце списка, затем положить значение связываемого поля новой записи равным nil;
4. список не пуст, а элемент необходимо вставить между двумя элементами списка; здесь необходимо скопировать значение связующего поля того элемента, который должен предшествовать новому в поле связи нового элемента, а затем скопировать ссылку на новый элемент в связующем поле того элемента, который должен предшествовать новому в списке.
Данные четыре операции покроются тремя вариантами вставки: в начало списка, в конец списка и между двумя элементами списка. Общий алгоритм процедуры должен выглядеть следующим образом (ниже Тек_Ссылка означает ссылку на текущий элемент, а Пред_Ссылка √ значение ссылки на предшествующий):
1. Установить значение Тек_Ссылка так, чтобы оно указывало на начало списка, положить значение Пред_Ссылка = nil и установить признак того, что положение вставляемого элемента не определено.
2. Пока в списке остаются еще не просмотренные элементы и положение нового элемента не определено выполнять следующее: - если новый элемент следует за тем, на который указывает Тек_Ссылка, то положить значение Пред_Ссылка равным Тек_Ссылка и изменить значение Тек_Ссылка так, чтобы оно указывало на следующий элемент; - иначе установить признак того, что положение вставляемого элемента не определено.
3. Если Пред_Ссылка= nil, то вставить элемент в начало списка. Если и Пред_Ссылка и Тек_Ссылка не равны nil, то вставить новый элемент между теми элементами, на которые указывают Пред_Ссылка и Тек_Ссылка. Если Пред_Ссылка не равна nil, а Тек_Ссылка= nil, то вставить новый элемент в конец списка.
procedure InclWithSort(NewElem: DynStr; var HeadOfStr: Pointer);
var
CurrAssoc, PredAssoc: DynStr; {соответственно Тек_Ссылка и Пред_Ссылка}
IsFounded: Boolean;
begin
CurrAssoc:= HeadOfStr;
PredAssoc:= nil;
IsFounded:= False;
while (CurrAssoc <> nil) and not IsFounded do begin
if NewElem^.Elem > CurrAssoc^.Elem then begin
{перейти к следующему элементу}
PredAssoc:= CurrAssoc;
CurrAssoc:= CurrAssoc^.NextElem
end
else IsFounded:= True
end;
{позиция вставки нового элемента найдена}
if PredAssoc= nil then begin
{вставка нового элемента в начало списка}
NewElem^.NextElem:= HeadOfStr;
HeadOfStr:= NewElem
end;
if (PredAssoc <> nil) and (CurrAssoc <> nil) then begin
{вставка элемента между элементами, на которые указывают ссылки PredAssoc
CurrAssoc}
NewElem^.NextElem:= PredAssoc^.NextElem;
PredAssoc^.NextElem:= NewElem
end;
if (PredAssoc <> nil) and (CurrAssoc= nil) then begin
{вставка в конец списка}
PredAssoc^.NextElem:= NewElem;
NewElem^.NextElem:= nil
end
end;
2.2 Двунаправленные списки
Линейный список неудобен тем, что при попытке вставить некоторый элемент перед текущим элементом, требуется обойти почти весь список, начиная с заголовка, чтобы изменить значение указателя в предыдущем элементе списка. Чтобы устранить данный недостаток вводится второй указатель в каждом элементе списка. Первый указатель связывает данный элемент со следующим, а второй √ с предыдущим. Такая организация динамической структуры данных получила название линейного двунаправленного списка (двусвязного списка). На рис. 2 приведена графическая интерпретация двунаправленного списка.
Интересным свойством такого списка является то, что для доступа к его элементам вовсе не обязательно хранить указатель на первый элемент. Достаточно иметь указатель на любой элемент списка. Первый элемент всегда можно найти по цепочке указателей на предыдущие элементы, а последний - по цепочке указателей на следующие. Но наличие указателя на заголовок списка в ряде случаев ускоряет работу со списком
2.3 Циклические списки
Линейные списки характерны тем, что в них можно выделить первый и последний элементы, причем для однонаправленного линейного списка обязательно нужно иметь указатель на первый элемент. Циклические списки также как и линейные бывают однонаправленными и двунаправленными. Основное отличие циклического списка состоит в том, что в списке нет пустых указателей (см. рис 3).
Последний элемент списка содержит указатель, связывающий его с первым элементом. Для полного обхода такого списка достаточно иметь указатель только на текущий элемент.
В двунаправленном циклическом списке система указателей аналогична системе указателей двунаправленного линейного списка (см. рис 4).
Двунаправленный циклический список позволяет достаточно просто осуществлять вставки и удаления элементов слева и справа от текущего элемента. В отличие от линейного списка, элементы являются равноправными и для выделения первого элемента необходимо иметь указатель на заголовок. Однако во многих случаях нет необходимости выделять первый элемент списка и достаточно иметь указатель на текущий элемент.
Разберем решение типичной задачи, связанной с обработкой списков.
Текст задания
С использованием списков, заданный во входном файле текст (за которым следует точка) распечатать в обратном порядке.
Решение
program reverse;
type List= ^Elem;
Elem= record
Info: Char;
Next: List
end;
var
L, p: List;
c: char;
begin
{ввод литер текста и запись их в обратном порядке в список L (без заглавного звена)}
L:= nil; {ссылка на построенную часть списка}
read(c);
while c <> '.' do begin
{добавить с в начало списка}
new(p);
p^.Info:= c;
p^.Next:= L;
L:= p;
read(c)
end;
{печать литер из L}
while L <> nil do begin
write(L^.Info);
L:= L^.Next
end;
writeln
end.
Очереди и стеки
Очередь и стек представляют собой структуры данных с фиксированными механизмами занесения и выбора элементов. Возможны реализации очереди и стека на базе регулярных или списковых структур данных. Соответственно представлению изменяется реализация механизмов обработки структур. Однако определяющими являются следующие принципы: очередь предполагает занесение нового элемента в конец, а выбор с начала списка (FIFO √ First In First Out); в стек элемент заносится в начало и выбирается также сначала (LIFO √ Last In First Out).
3.1 Очередь на базе списка
Из механизма FIFO следует, что в очереди доступны два элемента √ первый и последний простая очередь (см. рис. 5).
Структура данных, представляющая очередь, могла бы выглядеть следующим образом:
type
TypeOfElem= {};
Assoc= ^ElementOfQueue;
ElementOfQueue= record
Elem: TypeOfElem;
NextElem: Pointer
end;
Queue= Assoc;
3.2 Создание (очистка) очереди
Для создания новой пустой или очистки существующей очереди достаточно присвоить указателям на первый и последний элементы значение nil.
procedure CreateQueue (var FirstElem, LastElem: Queue);
begin
FirstElem:= nil;
LastElem:= nil
end;
3.3 Проверка очереди на пустоту
Условием пустоты очереди является значения указателей на первый и последний элементы, равные nil.
function QueueIsClear(var FirstElem, LastElem: Queue): Boolean;
begin
QueueIsClear:= (FirstElem= nil) and (LastElem= nil)
end;
3.4 Включение элемента в очередь
Для включения элемента в очередь, необходимо создать новый элемент типа очередь, затем инициализировать его информационное поле. В заключение изменить его указатель и указатель на последний элемент очереди так, чтобы последним стал новый элемент.
procedure IncludeInQueue(var FirstElem, LastElem: Queue; NewElem: TypeOfElem);
var
ServiceVar: Queue;
begin
{создание нового элемента}
new(ServiceVar);
ServiceVar^.Elem:= NewElem;
ServiceVar^.NextElem:= nil;
if (FirstElem= nil) and (LastElem= nil) then begin
{создать очередь из одного элемента}
FirstElem:= ServiceVar;
LastElem:= ServiceVar
end
else begin
{созданный элемент поместить в конец очереди}
LastElem^.NextElem:= ServiceVar;
LastElem:= ServiceVar
end
end;
3.5 Выбор элемента из очереди
При выборе элемента из очереди информационное поле первого ее элемента должно быть присвоено результирующей переменной, а сам элемент должен быть исключен из очереди и удален. Здесь необходима также проверка на то, являлся ли этот элемент в очереди единственным, и если да, то необходимо соответствующим образом изменить указатель на последний элемент.
procedure SelectFromQueue(var FirstElem, LastElem: Queue; var Result: TypeOfElem);
var
ServiceVar: Queue;
begin
if not ((FirstElem= nil) and (LastElem= nil)) then begin
Result:= FirstElem^.Elem;
ServiceVar:= FirstElem;
{убираем 1-ый элемент из очереди}
FirstElem:= FirstElem^.NextElem;
{был ли это последний элемент}
if FirstElem= nil then
LastElem:= nil;
dispose(ServiceVar)
end
end;
3.6 Стек на базе списка
Из механизма LIFO следует, что в стеке доступен только последний занесенный его элемент √ так называемая вершина стека. Главный элемент, представляющий весь список как единый объект, в случае стека оказывается лишним, его роль выполняет вершина стека. Элемент, занесенный в стек раньше других имеет ссылку nil (см. рис. 6).
Структура данных, представляющая стек, могла бы выглядеть следующим образом:
type
TypeOfElem= {};
Assoc= ^ElementOfStack;
ElementOfStack= record
Elem: TypeOfElem;
NextElem: Pointer
end;
Stack= Assoc;
Рассмотрим реализацию основных операций над стеком.
3.7 Создание (очистка) стека
Для создания нового пустого или очистки существующего стека достаточно присвоить указателю на первый его элемент (вершину) значение nil.
procedure CreateStack (var StackHead: Stack);
begin
StackHead:= nil
end;
3.8 Проверка стека на пустоту
Условием пустоты стека является значение его вершины, равное nil.
function StackIsClear(var StackHead: Stack): Boolean;
begin
StackIsClear:= (StackHead= nil)
end;
3.9 Занесение элемента в стек
Для включения элемента в стек, необходимо создать новый элемент типа стек, затем инициализировать его информационное поле. В заключение изменить его указатель и указатель на первый элемент стека так, чтобы первым стал новый элемент.
procedure IncludeInStack(var StackHead: Stack; NewElem: TypeOfElem);
var
ServiceVar: Stack;
begin
{создание нового элемента}
 new(ServiceVar);
ServiceVar^.Elem:= NewElem;
{созданный элемент сделать вершиной стека}
ServiceVar^.NextElem:= StackHead;
StackHead:= ServiceVar
end;
3.10 Выбор элемента из стека
При выполнении этой операции информационное поле элемента, находящегося в вершине стека, должно быть присвоено в качестве значения некоторой переменой, а сам элемент должен быть исключен из стека и уничтожен.
procedure SelectFromStack(var StackHead: Stack; var Result: TypeOfElem);
var
ServiceVar: Assoc;
begin
if StackHead <> nil then begin
{выбор элемента из вершины}
Result:= StackHead^.Elem;
{запоминание ссылки на старую вершину}
ServiceVar:= StackHead;
{исключение из стека и уничтожение элемента}
StackHead:= StackHead^.NextElem;
dispose(ServiceVar)
end
end;
Необходимо обратить внимание на введение вспомогательной переменной ссылочного типа ServiceVar для осуществления удаления элемента. Типична ошибка, связанная с попыткой решить эту задачу через dispose(StackHead).
Разберем решение типичной задачи, связанной с обработкой стека.
Текст задания
Используя стек (считать уже описанными тип Stack с информационным элементом типа Char, функцию StackIsClear (проверка пустоты стека) и процедуры CreateStack (очистка стека), IncludeInStack (вставка элемента в стек), SelectFromStack (выборка элемента из стека)) решить следующую задачу: в текстовом файле f записана без ошибок формула следующего вида:
<формула>::= <цифра>|M(<формула>,<формула>)|m(<формула>,<формула>)
цифра::= 0|1|2|3|4|5|6|7|8|9
где M обозначает функцию max, а m √ min. Вычислить (как целое число) значение данной формулы (например, M(5, m(6, 8)): 6).
Решение
program StackSample;
type
FileType= File of Char;
var
Source: FileType;
function formula(var t: FileType): integer;
type
TypeOfElem= Char;
Assoc= ^ElementOfStack;
ElementOfStack= record
Elem: TypeOfElem;
NextElem: Pointer
end;
Stack= Assoc;
var
S: Stack;
c, op, x, y: char;
procedure CreateStack (var StackHead: Stack);
begin
StackHead:= nil
end;
function StackIsClear(var StackHead: Stack): Boolean;
begin
StackIsClear:= (StackHead= nil)
end;
procedure IncludeInStack(var StackHead: Stack; NewElem: TypeOfElem);
var
ServiceVar: Stack;
begin
{создание нового элемента}
new(ServiceVar);
ServiceVar^.Elem:= NewElem;
{созданный элемент сделать вершиной стека}
ServiceVar^.NextElem:= StackHead;
StackHead:= ServiceVar
end;
procedure SelectFromStack(var StackHead: Stack; var Result: TypeOfElem);
var
ServiceVar: Assoc;
begin
if StackHead <> nil then begin
{выбор элемента из вершины}
Result:= StackHead^.Elem;
{запоминание ссылки на старую вершину}
ServiceVar:= StackHead;
{исключение из стека и уничтожение элемента}
StackHead:= StackHead^.NextElem;
dispose(ServiceVar)
end
end;
begin
reset(t);
CreateStack(S);
while not eof(t) do begin
read(t, c);
{обработка очередной литеры текста (литеры ╚(╩ и ╚,╩ игнорируются)}
if c in ['0'..'9','M','m'] then IncludeInStack(S, c)
else
if c= ')' then begin {конец формулы вида p(x, y)}
{в конце стека находится тройка op x y, она удаляется
из стека, выполняется операция op и результат
записывается в стек}
SelectFromStack(S, y);
SelectFromStack(S, x);
SelectFromStack(S, op);
case op of
'M'{max}: if x > y then c:= x else c:= y;
'm'{min}: if x < y then c:= x else c:= y
end;
IncludeInStack(S, c)
end
end; {of while}
{в стеке осталась одна цифра √ значение всей формулы; цифра переводится в целое число}
SelectFromStack(S, c);
formula:= ord(c) - ord('0')
end;
begin
assign(Source, 'c:\temp\source.txt');
writeln(Formula(Source));
end.
Двоичные деревья
Элементы двоичного дерева помимо информативной части имеют две ссылки √ на нижний левый и на нижний правый элементы. Принцип построения двоичного дерева заключается в том, что очередной элемент в зависимости от значения информативной части должен попасть в правое (если информационная часть включаемого элемента больше информационной части корня) или левое (в противном случае) поддерево. При этом в рамках выбранного поддерева определение местоположения нового элемента производится аналогично (см. рис. 7).
Данную структуру целесообразно описать следующим образом:
type
TypeOfElem= {};
Assoc= ^ElemOfTree;
ElemOfTree= record
Elem: TypeOfElem;
Left, Right: Pointer
end;
4.1 Поиск элемента в дереве
function FoundInTree(Elem: TypeOfElem; var Tree, Result: Pointer): Boolean;
var
ServiceVar: Assoc;
b: Boolean;
begin
b:= False;
ServiceVar:= Tree;
if Tree <> nil then
repeat
if ServiceVar^.Elem= Elem then b:= True
else
if Elem < ServiceVar^.Elem then ServiceVar:= ServiceVar^.Left
else ServiceVar:= ServiceVar^.Right
until b or (ServiceVar= nil);
FoundInTree:= b;
Result:= ServiceVar
end;
4.2 Включение элемента в дерево
Включение элемента в дерево реализуется путем во-первых, поиска вершины √ предка нового элемента, во-вторых, непосредственным включением элемента в дерево по найденной позиции. Опишем процедуру поиска предка для нового элемента.
function SearchNode(Elem: TypeOfElem; var Tree, Result: Assoc): Boolean;
var
ServiceVar1, ServiceVar2: Assoc;
b: Boolean;
begin
b:= False;
ServiceVar1:= Tree;
if Tree <> nil then
repeat
ServiceVar2:= ServiceVar1;
if ServiceVar1^.Elem= Elem then {элемент найден} b:= True
else begin
{запоминание обрабатываемой вершины}
ServiceVar2:= ServiceVar1;
if Elem < ServiceVar1^.Elem then ServiceVar1:=
ServiceVar1^.Left
else ServiceVar1:= ServiceVar1^.Right
end
until b or (ServiceVar1= nil);
SearchNode:= b;
Result:= ServiceVar2
end;
Как видно из описания, эта функция подобна ранее рассмотренной функции поиска элемента дерева (FoundInTree), но в качестве побочного эффекта фиксируется ссылка на вершину, в которой был найден заданный элемент (в случае успешного поиска), или ссылка на вершину, после обработки которой поиск прекращен (в случае неуспешного поиска). Сама процедура включения элемента в дерево будет иметь следующее описание.
procedure IncludeInTree(Elem: TypeOfElem; var Tree: Assoc);
var
Result, Node: Assoc;
begin
if not SearchNode(Elem, Tree, Result) then begin
{формирование новой вершины в дереве}
new(Node);
Node^.Elem:= Elem;
Node^.Left:= nil;
Node^.Right:= nil;
if Tree= nil then
{если дерево пусто, то созданный элемент сделать вершиной дерева}
Tree:= Node
else
{подсоединить новую вершину к дереву}
if Elem < Result^.Elem then Result^.Left:= Node
else Result^.Right:= Node
end
end;
Двоичное дерево можно рассматривать как рекурсивную структуру данных, состоящую из корневой записи, указывающей на левое и правое поддерево. Оба поддерева имеют такую же структуру: корень поддерева и правое и левое поддеревья. При этом, для представления дерева рекурсивной динамической структурой целесообразно модифицировать описание типа дерева, данное выше. А именно, удобнее изменить тип ссылок на левое и правое поддеревья с нетипизированного (Pointer) на типизированный:
type
TypeOfElem1= {};
Assoc1= ^ElemOfTree1;
ElemOfTree1= record
Elem: TypeOfElem1;
Left, Right: Assoc1
end;
Опишем процедуру вставки элемента рекурсивно.
procedure IncludeInTree2(NewElem: Assoc1; var SubTree: Assoc1);
begin
if SubTree= nil then begin
SubTree:= NewElem;
NewElem^.Left:= nil;
NewElem^.Right:= nil;
end
else
if NewElem^.Elem < SubTree^.Elem then
IncludeInTree2(NewElem, SubTree^.Left)
else
IncludeInTree2(NewElem, SubTree^.Right)
end;
4.3 Удаление элемента дерева
Проблема реализации данной операции состоит в том, что в общем случае, в удаляемую вершину входит одна связь, а выходят две. Поэтому, необходимо найти подходящий элемент дерева, который можно было бы вставить на место удаляемого. Этот элемент является либо самым правым элементом левого поддерева (для достижения этого элемента необходимо перейти в следующую вершину по левой ветви, а затем, переходить в очередные вершины по правым ветвям до тех пор, пока очередная такая ссылка не будет равна nil), либо самый левый элемент правого поддерева (для достижения этого элемента необходимо перейти в следующую вершину по правой ветви, а затем, переходить в очередные вершины по левым ветвям до тех пор, пока очередная такая ссылка не будет равна nil). Процедура исключения элемента из двоичного дерева должна различать тои случая:
1. элемента с заданной информативной частью в дереве нет; 2. элемент с заданной информативной частью имеет не более одной ветви; 3. элемент с заданной информативной частью имеет две ветви.
procedure DeleteElemOfTree(var Tree: Assoc1; Elem: TypeOfElem1);
var
ServiceVar1: Assoc1;
procedure Del(var ServiceVar2: Assoc1);
begin
if ServiceVar2^.Right= nil then begin
ServiceVar1^.Elem:= ServiceVar2^.Elem;
ServiceVar1:= ServiceVar2;
ServiceVar2:=ServiceVar2^.Left
end
else Del(ServiceVar2^.Right)
end;
begin
{удаление элемента с информативным полем равным Elem из дерева Tree}
if Tree= nil then
{первый случай процедуры удаления}
writeln('Элемент не найден')
else
{поиск элемента с заданным ключом}
if Elem < Tree^.Elem then DeleteElemOfTree(Tree^.Left, Elem)
else
if Elem > Tree^.Elem then
DeleteElemOfTree(Tree^.Right, Elem)
else begin
{элемент найден, необходимо его удалить}
ServiceVar1:= Tree;
{второй случай процедуры удаления}
if ServiceVar1^.Right= nil then
Tree:= ServiceVar1^.Left
else
if ServiceVar1^.Left= nil then
Tree:= ServiceVar1^.Right
else
{третий случай процедуры удаления}
Del(ServiceVar1^.Left)
end
end;
Вспомогательная рекурсивная процедура Del вызывается лишь в третьем случае процедуры удаления. Она переходит к самому правому элементу левого поддерева удаляемого элемента, а затем заменяет информационное поле удаляемого на значение поля найденного элемента.
4.4 Вывод элементов дерева
Данная задача также может быть решена с помощью механизма рекурсии.
procedure PrintTree(Tree: Pointer);
var
ServiceVar: Assoc1;
begin
ServiceVar:= Tree;
writeln(ServiceVar^.Elem);
if ServiceVar^.Right <> nil then PrintTree(ServiceVar^.Right);
if ServiceVar^.Left <> nil then PrintTree(ServiceVar^.Left);
end;
Разберем решение типичной задачи, связанной с обработкой двоичных деревьев.
Текст задания
Описать процедуру copy(T, T1) которая строит T1 √ копию дерева T.
Решение
procedure CopyTree(T: Tree; var T1: Tree);
begin
if T= nil then T1:= nil
else
begin
new(T1);
T1^.Elem:= T^.Elem;
CopyTree(T^.Left, T1^.Left);
CopyTree(T^.Right, T1^.Right)
end
end;
Глава II. Практическая часть
1-Задача 1. Программа «Калькулятор»
Постановка задачи. Составить программу калькулятор.
Листинг программы
program Kalkulator;
var
M:array[1..50] of string;
j,i,n:integer;
s,s1,s2,s3:string;
x,y:real;
begin
writeln('BBeDi OPeRAciy');
readln(s);
n:=length(s);
for i:=0 to n-1 do
begin
M[i]:=copy(s,i,1);
if (m[i]='+')or(m[i]='-')or(m[i]='*')or(m[i]='/') then j:=i;
end;
s1:=copy(s,0,j-1);
s2:=copy(s,j,1);
s3:=copy(s,j+1,n);
val(s1,x,n);
val(s3,y,n);
if s2='+' then writeln(x+y:4:1);
if s2='-' then writeln(x-y:4:1);
if s2='*' then writeln(x*y:4:1);
if s2='/' then writeln(x/y:4:1);
readln;
end.
Блок-схема
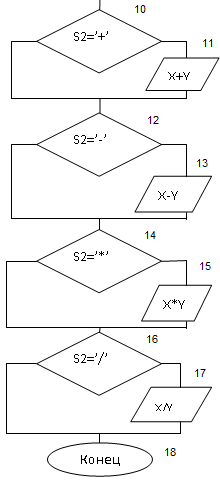
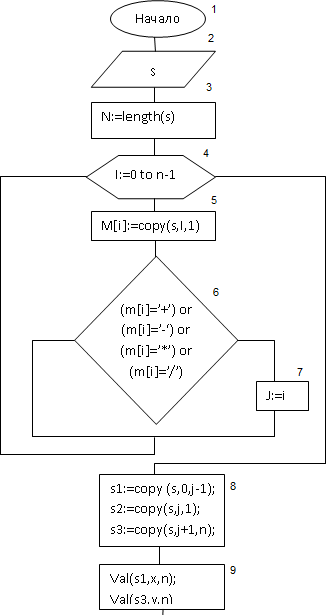
Пояснение к блок-схеме
| № блока | Назначение |
| Начало программы | |
| Ввод/вывод данных | |
| Выполнение операции N:=length(s) | |
| Цикл i:=0 to n-1 | |
| Тело цикла, выполнение операции M[i]:=copy(s,i,1) | |
| Тело цикла, условие (m[i]=’+’) or (m[i]=’-‘) or (m[i]=’*’) or m[i]=’/’) | |
| Тело цикла выполнение операции j:=i | |
| Выполнение операции s1:=copy (s,o,j-1); s2:=copy (s,j,1); s3:=copy (s,j+1,n) | |
| Выполнение операции val(s1,x,n); val(s3,y,n) | |
| Блок условия s2=’+’ | |
| Ввод/вывод данных x+y | |
| Блок условия s2=’-‘ | |
| Ввод/вывод данных x-y | |
| Блок условия s2=’*’ | |
| Ввод/вывод данных x*y | |
| Блок условия s2=’/’ | |
| Ввод/вывод данных x/y | |
| Конец программы |
Протокол программы
BBeDi OPeRaciy
56*9
504,0
2-Задача2. Выполнить сортировку по латинскому алфавиту
Постановка задачи. Составить программу которая, сортирует буквы латинского алфавита по алфавиту.
Листинг программы
program Alfavit;
var
M:array[1..50] of string;
j,i,n:integer;
b:boolean;
s,tmp:string;
begin
writeln('BBeDu TekcT');
readln(s);
n:=length(s);
for i:=0 to n-1 do
begin
M[i]:=copy(s,i,1);
end;
b:=true;
while b do
begin
b:=false;
for i:=1 to n-1 do
begin
if m[i] > m[i+1] then
begin
tmp:= m[i];
m[i]:=m[i+1];
m[i+1]:=tmp;
b:=true;
end;
end;
end;
for i:=0 to n-1 do begin;
write(m[i],' ');
end;
readln;
end.
Блок-схема

Пояснение к блок-схеме
| № блока | Назначение |
| Начало программы | |
| Ввод/вывод данных n:=length(s) | |
| Цикл i:=0 to n-1 | |
| Тело цикла M:=copy(s,i,1) | |
| Выполнение операции b:=true | |
| Выполнение операции b:=false | |
| Цикл i:=1 to n-1 | |
| Тело цикла, условие m[i]>m[i+1] | |
| Выполнение операции tmp:=m[i]; m[i]:=m[i+1]; m[i+1]:=tmp; b:=true | |
| Цикл i:=o to n-1 | |
| Ввод/вывод данных m[i] | |
| Конец программы |
Протокол программы
BBeDu TekcT
abrakadabra
aaaaabbdkr
Приложения

 Рис. 1. Линейный список (связанный список)
Рис. 1. Линейный список (связанный список)
 Рис. 2. Двунаправленный список
Рис. 2. Двунаправленный список
 Рис. 3. Однонаправленный циклический список.
Рис. 3. Однонаправленный циклический список.

Рис. 4. Двунаправленный циклический список.
Рис. 5. Организация дека на основе линейного списка.

 Рис. 6. Организация стека на основе линейного списка.
Рис. 6. Организация стека на основе линейного списка.
Рис. 7. Представление бинарного дерева в виде списковой структуры.
Список литературы
Рапаков Г. Г. и Ржецукая С. Ю.. Turbo Pascal для студентов и школьников. BHV – С.-Петербург 2004
Меженный О. А. Turbo Pascal: учитель программирования. Диалектива 2001.
Культин Н.. Программирование в Turbo Pascal и Delphi. BHV 2003
Фаронов В. В. Turbo Pascal: учебное пособие. BHV 2006