Постановка задачи
В контрольной работе для выбранного массива данных решить задачу классификации с помощью нейронной сети в Statistica. Исследовать влияние параметров на качество решения
Все этапы необходимо последовательно описать в отчете.
Описание массива исходных данных
В качестве базы данных была взята база данных «Авто-Mpg данные» 1
Источники:
(А) Происхождение: Этот набор данных был взят из библиотеки StatLib которая поддерживается в Карнеги-Меллона. Набор данных был используемый в 1983 Американской статистической ассоциации экспозиции. (С) Дата: 7 июля 1993
Соответствующая информация:
Этот набор данные представляет собой слегка модифицированную версию набора данных, представленные в библиотека StatLib. В соответствии с использованием Росс Квинлан (1993) в прогнозирования атрибута «миль на галлон», 8 оригинальных экземпляров были удалены потому что у них были неизвестные значения для атрибута «миль на галлон». Оригинал набор данных доступен в файле «авто-mpg.data-оригинал».
«Данные касается городского цикла расхода топлива в милях на галлон, чтобы быть предсказаны в терминах дискретного многозначного 3 и 5 непрерывного атрибуты «. (Вос, 1993)
Количество экземпляров: 385
Количество атрибутов: 9 в том числе атрибута класса
Атрибут информации:
1. расход: непрерывный 5,05-26,14
2. Цилиндры: многозначные дискретный 4,6,8
3. смещение: непрерывный 68- 455
4. Мощность: непрерывная 46-230
5. Вес: непрерывный 1613-5140
6. Ускорение: непрерывное 8-24,8
7. модельного года: многозначное дискретное 1970-1982
8. Происхождение: многозначное текстовое JAPAN, EURO, USA
9. Название Автомобиля: строка (уникальная для каждого экземпляра)
Характеристика полученных результатов
Решим задачи классификации с помощью нейронной сети в пакете Statistica.
Для анализа данных применим нейронные сети в Statisitca

Рис.1
3.1. Исходные данные: В качестве исходных данных (рис 1) были использованы три вида двигателей, 4,6,8-цилиндровые. И семь категории измерений. В ходе исследования пропущенные значения не найдены.
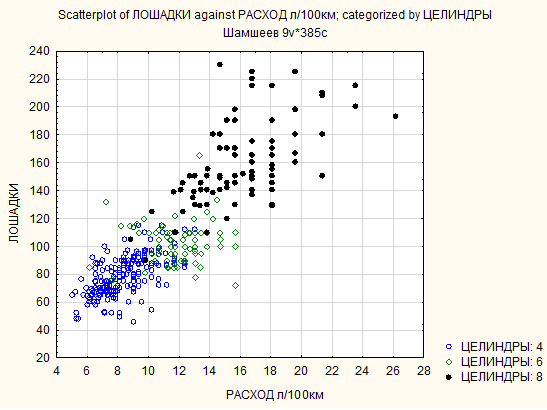
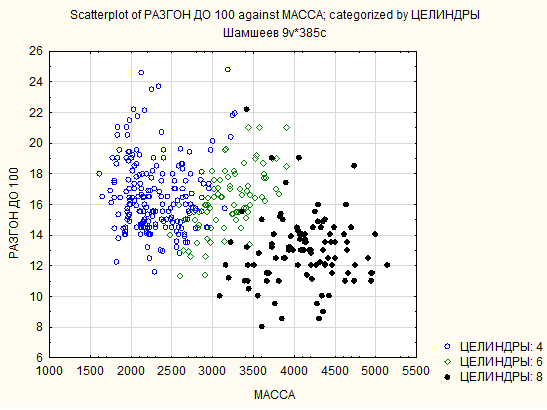
Рис. 2
3.2. Распространение данных в пространстве. Категоризованная диаграмма рассеивания, которая характеризует распределение объектов по типу двигателя. Распределение происходило по Расходу и Мощности, а так же по Разгону и массе. На данной диаграмме видно, что наиболее мощные, быстрые, тяжелые машины имеют 8 цилиндров. 4-х целиндровые напротив, экономичнее, медленнее, легче. 6-ти целиндровые обладают средними показателями во всем.
3.3. Для анализа данных применим нейронные сети в Statisitca. Автоматизированная стратегия построения нейронных сетей классификации. В задачах классификации обычно используется логистические и гиперболические функции активации для скрытых нейронов и такие же для выходных нейронов. Количество скрытых нейронов 4-12, т.к. этого достаточно. Параметры создания нейронной сети указаны на рисунке 3.
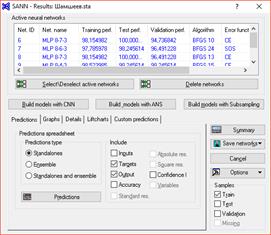

Рис. 3 Параметры создания нейронной сети
3.4. Запустим обучение нейронной сети, получим результаты.
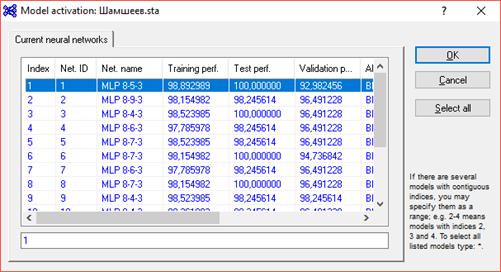
Рис. 4 Нейронные сети
Из полученных результатов видно, что мы имеем многослойный перцептрон 8-5-3 с точностью при обучении 98,89% и тестировании 100%, это наилучший результат, который удалось добиться в Statistica.
3.5. Посмотрим на матрицу ошибок по каждой модели классификации. В матрице указано число правильно и неправильно классифицированных наблюдений по каждому классу, а также указано число по всем классам.
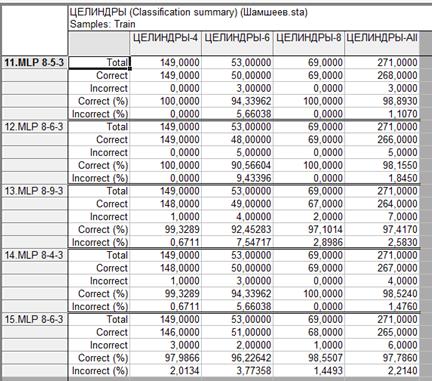
Рис. 5
3.6. Выберем 3 модель и проанализируем ее.
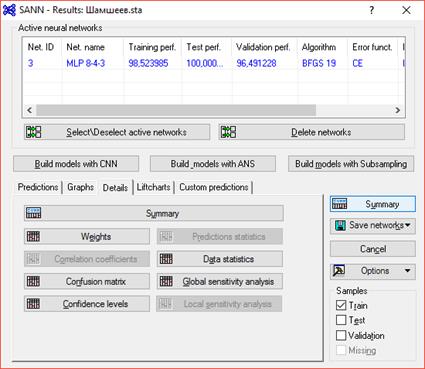
Рис. 6

Рис. 7 Описательная статистика отдельной модели 3, по всем переменным
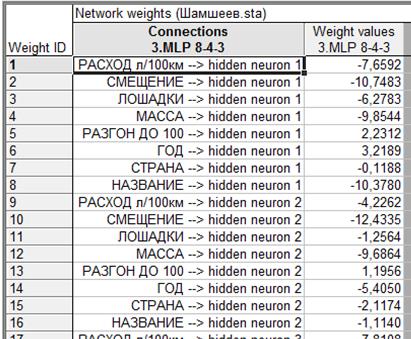
Рис. 8
3.7. Веса нейронной сети. Это параметры, которые обучены. Из каждого слоя нейронов на следующий слой идут соответствующие веса, которые указаны после стрелки -->. Эти веса указаны в графе weight values.
4. Вывод: Система Statistica позволяет на основе настроек решать задачи классификации методом подбора. Система строит перечень рекомендуемых сетей и составляет статистику. Сеть с наилучшей статистикой можно взять в качестве рабочей.