Практическая работа 5.
Изучение алгоритма сжатия Хаффмана. Сжатие текстов»
Цель работы: изучить алгоритм оптимального префиксного кодирования Хаффма на и его использование для сжатия сообщений.
Теоретические сведения
Алгоритм Хаффмана — адаптивный жадный алгоритм оптимального префиксного кодирования алфавита с минимальной избыточностью. Был разработан в 1952 году аспирантом Массачусетского технологического института Дэвидом Хаффманом.
Сжатие данных по Хаффману применяется при сжатии фото- и видеоизображений (JPEG, стандарты сжатия MPEG), в архиваторах (PKZIP, LZH и др.), в протоколах передачи данных MNP5 и MNP7.
Жадный алгоритм (Greedy algorithm) — алгоритм, заключающийся в принятии локально оптимальных решений на каждом этапе, допуская, что конечное решение также окажется оптимальным.
Идея алгоритма Хаффмана состоит в следующем: зная вероятности символов в сообщении, можно описать процедуру построения кодов переменной длины, состоящих из целого количества битов. Символам с большей вероятностью ставятся в соответствие более короткие коды. Коды Хаффмана обладают свойством префиксности (то есть ни одно кодовое слово не является префиксом другого), что позволяет однозначно их декодировать. Этот метод кодирования состоит из двух основных этапов:
1.Построение оптимального кодового дерева.
2.Построение отображения код-символ на основе построенного дерева.
Классический алгоритм Хаффмана на входе получает таблицу частот встречаемости символов в сообщении. Далее на основании этой таблицы строится дерево кодирования Хаффмана (Н-дерево).
1. Символы входного алфавита образуют список свободных узлов. Каждый лист имеет вес, который может быть равен либо вероятности, либо количеству вхождений символа в сжимаемое сообщение.
2. Выбираются два свободных узла дерева с наименьшими весами. 3.Создается их родитель с весом, равным их суммарному весу.
4. Родитель добавляется в список свободных узлов, а два его потомка удаляются из этого списка.
5. Одной дуге, выходящей из родителя, ставится в соответствие бит 1, другой — бит 0.
6. Шаги, начиная со второго, повторяются до тех пор, пока в списке свободных узлов не останется только один свободный узел. Он и будет считаться корнем дерева.
Для примера рассмотрим кодирование фразы
ТКЁТ ТКАЧ ТКАНИ
Можно видеть, что фраза состоит из L = 15 символов.
Первоначально необходимо сформировать алфавит фразы и построить таблицу количества вхождений и вероятности символов. Она представлена в табл.1.1.
| Алфавит | Т | К | Ё | «» | А | Ч | Н | И |
| Кол. вх. | ||||||||
| Вероятн. | 0,27 | 0,2 | 0,065 | 0,135 | 0,135 | 0,065 | 0,065 | 0,065 |
Таблица 1.1 Алфавит фразы и вероятности символов
Каждый символ является конечным узлом дерева, количество повторений символа - это вес узла.
Создадим список нераспределенных узлов по возрастанию весов.
1. {"Ё"(1)} 2. {"Ч"(1)} 3. {"Н"(1)} 4. {"И"(1)}
5. {"_"(2)} 6. {"А"(2)} 7. {"К"(3)} 8. {"Т"(4)}
Объединим узлы с минимальным весом (1) в новый узел с весом 1+1=2 и поставим этот узел в список вместо исходных узлов в соответствии с получившимся весом:
1. {"1 (2)":{"Ё"(1)},{"Ч2(1)}}
2. {"2 (2)":{"Н"(1)},{"И"(1)}}
3. {"_"(2)}
4. {"А"(2)}
5. {"К"(3)}
6. {"Т"(4)}
Теперь объединяем узлы с весом (2) в новые узлы с весом 2+2=4
1. {"К"(3)}
2. {"4 (4)":{"_"(2)},{"А"(2)}}
3. {"3 (4)":{"2 (2)":{"Н"(1)},{"И"(1)}},{"1 (2)":{"Ё"(1)},{"Ч"(1)}}}
4. {"Т"(4)}
далее объединение узлов "К" и 4 в узел 5 с весом 4+3=7
1. {"3 (4)":{"2 (2)":{"Н"(1)},{"И"(1)}},{"1 (2)":{"Ё"(1)},{"Ч"(1)}}}
2. {"Т"(4)}
3. {"5 (7)":{"К"(3)},{"4 (4)":{"_"(2)},{"А"(2)}}}
узлы 3 и "Т" объединяем в узел 6 с весом 4+4=8
1. {"6 (8)":{"3 (4)":{"2 (2)":{"Н"(1)},{"И"(1)}},{"1 (2)":{"Ё"(1)}, {"Ч"(1)}}}, {"Т"(4)}}
2. {"5 (7)":{"К"(3)},{"4 (4)":{"_"(2)},{"А"(2)}}}
Оставшиеся 2 узла объединяются в корневой узел 7 с весом 7+8=15.
Кодовое дерево Хаффмана стром по следующим правилам:
-символ задает вершину - лист графа;
-вес вершины равен частоте вхождения символа;
-левые ветви обозначаем 0;
-правые ветви обозначаем 1;
-определяем код символа от корня к листу;
Графически наше кодовое дерево можно представить так:
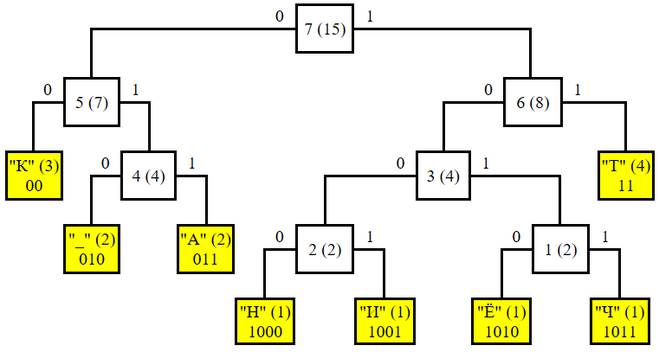 Рис. 1.1. Упорядоченное дерево кодирования Хаффмана
Рис. 1.1. Упорядоченное дерево кодирования Хаффмана
Код каждого символа получается, как путь по дереву от корня до соответствующего листа:
| Алфавит | Т | К | Ё | «» | А | Ч | Н | И |
| код |
Таблица 1.2 Таблица кодов по разработанному дереву Хаффмана
Согласно таб. 1.2 наша фраза будет представлена двоичным кодом:
 11 00 1010 11 010 11 00 011 1011 010 11 00 011 1000 1001
11 00 1010 11 010 11 00 011 1011 010 11 00 011 1000 1001
ТКЁТ ТКАЧ ТКАНИ
Рассчитаем коэффициент сжатия относительно использования кодировки ASCII (8 бит/символ).
L ASCII= 8 *15 = 120 бит.
L Huff= 4*2+3*2+1*4+2*3+2*3+1*4+1*4+1*4=42 бит
Следовательно, коэффициент сжатия относительно таблицы ASCII будет равен: К= L ASCII/ L Huff=120/42=2,86
При равномерном кодировании длина текста равна 15*4=60 бит
Сжатие по отношению к равномерному коду равно 60/42=~1.43
Задания для практического выполнения
В соответствии с номером компьютера выбери фразу и создай по ней дерево Хаффмана.

1. Осип охрип, Архип осип.
2. Сачок зацепился за сучок.
3. Инцидент с интендантом.
4. Прецедент с претендентом.
5. Константин констатировал.
6. Яшма в замше замшела.
7. У елки иголки колки.
8. В один клин, Клим, колоти.
9. Подал грабли крабу краб
10. Саша шапкой шишку сшиб
11. А мне не до недомогания.
12. Петя был мал и мяту мял
13. Дед Додон в дуду дудел
14. Не руби дрова на траве двора!
15. На дворе — трава, на траве — дрова