Общая структура клиент-серверного взаимодействия со стороны сервера описана ранее.
Однако, нас больше интересует этот же взгляд со стороны клиента, и в этой связи, нет никакой разницы между двухзвенной и трехзвенной архитектурой:
Здесь важно понимание двух вещей:
– Может быть множество клиентов, использующих один аккаунт для общения с севером.
– Каждый клиент, как правило, имеет свое собственное локальное хранилище.
Следует отметить, что поскольку, некоторые разработчики стремятся избавится от «серверной части» некоторые приложения построены вокруг синхронизации их хранилищ в «облаке». Т. е. фактически, имеют так же, двухзвенную систему, но с переносом архитектуры её развертывания на уровень операционной системы. В некоторых случаях такая структура оправдана, но такая система не так легко масштабируется, и её возможности весьма ограничены.
Общая структура приложения
На самом примитивном уровне абстракции приложение, ориентированное на работу с сервером, состоит из следующих архитектурных слоев:
1. Ядро приложения, которое включает в себя компоненты системы, не доступные для взаимодействия с пользователем.
2. Графический пользовательский интерфейс.
3. Компоненты повторного использования: библиотеки, визуальные компоненты и другое.
4. Файлы окружения: синглтоны, делегаты приложения и т.д.
5. Ресурсы приложения: графические файлы, звуки, необходимые бинарные файлы.
Наиважнейшим условием построение стрессоустойчивой архитектуры является отделение ядра системы от GUI, настолько, что б одно, могло успешно функционировать без другого. Между тем, большинство RAD систем исходят из противоположного посыла – формы приложения образуют скелет системы, а функции наращивают ей мышцы. Как правило, это оборачивается тем, что не приложение становится ограниченным своим интерфейсом. И, интерфейс приобретает однозначное толкование как с точки зрения пользователя, так и с точки зрения иерархии классов.
Ядро
Ядро приложения, состоит из следующих слоев:
1. (Start layer) Стартовый слой, определяющий рабочий процесс, начала исполнения программы.
2. (Network layer) Сетевой слой, обеспечивающий механизм транспортного взаимодействия.
3. (API layer) Слой API, обеспечивающий единую систему команд взаимодействия между клиентом и сервером.
4. (Network Cache Layer) Слой сетевого кэширования, обеспечивающий ускорения сетевого взаимодействия клиента и сервера.
5. (Validation Items Layer) Слой валидации данных полученных из сети
6. (Network Items Layer) Слой сущности данных передаваемых по сети
7. (Data Model) Модель данных, обеспечивающая взаимодействие сущностей данных.
8. (Local cache layer) Слой локального кеширования, обеспечивающий локальный доступ к уже полученным сетевым ресурсам.
9. (Workflow layer) Слой рабочих процессов, включающий классы и алгоритмы специфичные для данного приложения.
10. (Local storage) Локальное хранилище
Одна из основных задач стоящие перед разработчиками системы заключается в том, чтобы обеспечить взаимно независимое функционирование указанных слоев. Каждый слой должным обеспечивать только выполнение возложенных на него функций. Как правило, слой находящийся на более высоком уровне иерархии не должен иметь представление о специфике реализации других слоев.
Постановка задачи позволяет выделить несколько подзадач, которые могут быть описаны отдельными классами:
1) Загрузка данных из сети.
- Проверка полученных данных.
- Сохранение данных в постоянном хранилище.
- Вычисление данных.
- Фильтрация данных по указанным критериям (настройки приложения)
- Класс старта приложения.
2) Обеспечить связанную работу интерфейса, который состоит форм:
3) После запуска приложения на выполнение, производится создание (инстанциирование) объекта, отвечающего за загрузку данных (в подавляющем большинстве случае асинхронную) и начинает процесс. Главный контроллер приложения отображает сплеш-скрин, и в это время, формирует форму, которая займет его место по сокрытию сплэш-формы.
4) По окончании загрузки данных, создается объект-валидатор и объект-провайдер локального хранилища. В случае если данные прошли необходимую валидацию, они могут быть переданы провайдеру локального хранилища.
5) Для отображения данных, создается объект локального хранилища и объект настроек данных. Настройки данных передаются в провайдер локального хранилища для извлечения данных с установленными фильтрами.
6) Для проведения вычислений создаются соответствующие объекты. В объекты передаются данные полученные с форм.
Конечно, данный подход требует больше усилий по программированию, и соответственно, изначально предполагает больше времени. Однако, исходя из подзадач ясно, что, во-первых, работу над ним легко распараллелить – в то время как один разработчик занят формированием ядра – другой, создает и отлаживает UI. Ядро может благополучно работать в рамках консоли, UI прощелкиваться на устройстве (ПК, девайс) и, ко всему прочему, к обеим частям можно прикрутить независимые юнит-тесты. Другим несомненным достоинством является то, что второй подход значительно более масштабируем. В случае пересмотра функциональности проекта, любые изменения будут вносится многократно быстрее, потому что попросту не существует ограничительных рамок визуальных представлений. Сами визуальные формы (GUI) отображают необходимый минимум основанный на существующих в ядре задачах.
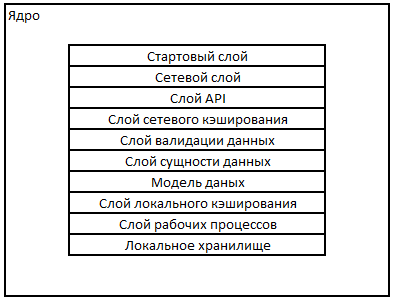
Рисунок 1 – Слои ядра приложения
Стартовый стой
В.Net приложение начинает функционировать с класса Programm, в iOS – с запуска объекта делегатного класса, в Android – с запуска объекта класса App. Их (стартовых классов) назначение – принять и передать вызовы системы приложению, а также, осуществить первоначальную конфигурацию GUI приложения. Все алгоритмы и механизмы, которые не относятся к старту приложения, или получения сообщений от системы должны быть вынесены в отдельные классы. Сразу после завершения первоначальной конфигурации управление должно быть передано классу, который осуществляет остальные операции настройки приложения: авторизацию, реконфигурирование интерфейса в зависимости от условий, первоначальную загрузку данных, получения необходимых токенов и так далее. Типичной ошибкой разработчиков является размещение большого количества кода в стартовых классах приложений. Оно и понятно – практически все примеры внешних фреймворков для простоты понимания именно здесь располагают свой код.
Намного более элегантным решением было бы создание синглтонного класса Start, и передачу туда данных, приходящих в стартовый класс, а уж в Start производить разведение данных по рабочим процессам.
Сетевой слой
Обеспечивает базовые алгоритмы транспортного уровня передачи сообщений от клиента к серверу, и получению от него необходимой информации. Как правило, сообщения могут передаваться в форматах JSON и Multipart, хотя, в некоторых экзотических случаях это может быть XML или бинарный поток. Кроме того, каждое сообщение может иметь заголовок со служебной информацией. Например, там может быть описана длительность хранения запроса / ответа в кеше приложения.
Network Layer не имеет никакого представления об используемых приложением серверах, или о его системе команд. Обработка ошибок сетевого соединения осуществляется виртуальными методами на следующих уровнях приложения. Задача этого слоя только осуществить вызов метода обработки и передать в него полученную из сети информацию.
Кроме того, перед непосредственным запросом информации из сети, network layer опрашивает локальный кеш, и в случае присутствия там ответа сразу же возвращает его пользователю.
Содержание этого слоя во многом зависит от того, какая технология транспорта наиболее близка. В арсенале разработчика наиболее востребованы следующие варианты:
Socket – наиболее низкоуровневый подход, включающий в себя синхронные и асинхронные запросы, и имеющий возможность работать как с TCP, так и с UDP подключениями.
WebSocket – подход, опирающийся на использование заголовков поверх TCP.
WCF – наверное самый совершенный механизм, но имеющий столь серьезный минус, который перевешивает все плюсы. Подход изобретенный в недрах Microsoft опирается на создании прокси-класса, который опосредует взаимоотношение между логикой приложения, и удаленным севером. Работает «на ура» в том случае, если удается сгенерировать прокси класс на основе WSDL схем.
REST — надежный, проверенный временем компромисс всех перечисленных выше подходов. Конечно, от части возможностей каждого из подхода приходится отказываться, зато делается это быстро, и чрезвычайно эффективно с минимумом усилий.
REST опирается на использование GET, POST, PUT, HEAD, PATCH и DELETE запросов.
Подавляющее большинство приложений ограничивает систему команд двумя типами, GET и POST, хотя, достаточно только одного – POST.
GET запрос передается в виде строки, которую Вы используете в браузере, а параметры для запроса передаются разделенные знаками ‘&’. POST запрос так же использует «браузерную строку» но, параметры скрывает внутри невидимого тела сообщения.
Слой API
Описывает команды REST и осуществляет выбор хоста. API Layer полностью отделен от знания реализации сетевых протоколов и любых других особенностей функционирования приложения. Технически, он может быть полностью заменен, без каких-либо изменений в остальных частях приложения.
Слой сетевого кэширования
Данный слой кеширования задействуется для ускорения сетевого обмена между клиентом и сервером. Выбор ответов осуществляется стороной лежащей за пределами контроля системы, и не гарантирует снижение сетевого трафика, но ускоряет его. Доступа к данным или механизмам реализации нет ни со стороны приложения, ни со стороны системы.
Для его работы необходимо сообщить ОС о том, что требуется кэширование, вызвав соответствующий метод.
Слой валидации данных
Формат получаемых данных из сети в большей степени зависит от разработчиков сервера. Приложение физически не может контролировать использование изначально заданного формата. Для сложно-структурированных данных, коррекция ошибок сравнима по сложности с разработкой самого приложения. Наличие ошибок, в свою очередь, чревато падением приложения. Использование механизма валидации данных существенно снижает угрозу некорректного поведения. Слой валидации состоит из схем JSON для большинства запросов к серверу, и класса, который осуществляет проверку полученных данных на соответствие загруженной схемы. Если полученный пакет не соответствует схеме, он отклоняется приложением. Вызывающий код получит уведомление об ошибке. Аналогичное уведомление будет записано в лог консоли. Кроме того, может быть вызвана команда сервера для передачи на сторону сервера отчета, о возникшей ошибке. Главное, предусмотреть выход из рекурсии, если команда отправки такого сообщения тоже вызывает какую-нибудь ошибку (4xx или 5xx).
Имеет смысл на сервер отправлять следующие данные:
Для какого аккаунта произошла ошибка.
Какая команда вызвала ошибку.
Какие данные были переданы серверу.
Какой ответ был получен от сервера.
Время UTC*
Статус код команды. Для ошибок валидации он всегда 200.
Схема, которой не удовлетворяет ответ сервера.
Предполагается, что схемы JSON запросов предоставляют серверные разработчики после реализации новых команд API.
Слой сущности данных
Именно на этом слое лежит ответственность за маппинг данных из JSON в десериализированное представление. Данный слой используется для описания классов, осуществляющих объектное или объектно-реляционное преобразование. В сети существует большое количество библиотек, осуществляющих объектно-реляционные преобразования. Например, Newtonsoft.JSON. Однако, не все так радужно. От проблем маппинга они не избавляют.
Поясним что такое маппинг:
Предположим существуют два запроса, которые возвращают одинаковые по структуре данные. Например, пользователей приложения и друзей пользователя, которые обладают таким полями как «идентификатор» и «имя пользователя». Беда в том, что серверные разработчики в одном запросе могут передать поля: «id», «username», а во втором «ident», «user_name». Такое разночтение может иметь целый набор неприятностей:
Сериализированные данные в поле «id» и «ident» могут содержать как строку, так и число. При выводе их на консоль, разницы между двумя числами не будет, но хэш-код у них будет разный, и словарь будет по-разному воспринимать значение этих полей.
Отличия между именами полей являются ответственностью сервера.
Универсального решения этих проблем нет, но они не настолько сложны, чтоб это требовало значительных интеллектуальных усилий.
Слой модели данных
Оперирует моделью данных приложения. Должен содержать классы, представляющие костях модели данных приложения.
Слой локального кэширования
К задачам данного слоя относятся:
1. Кеширование загружаемых из сети изображений.
2. Кеширование запросов / ответов сервера
3. Формирование очереди запросов в случае отсутствия сети и работы пользователя офлайн.
4. Мониторинг кэшированных данных и очистка данных, срок жизни которых истек.
5. Уведомление приложения о невозможности получить информацию о заданном объекте из сети.
Существует определенное количество нюансов, которые следует учитывать разработчикам:
– использовать виртуальные методы классов для их кэширования;
– хранение на сервере информации о том, что за кэшировано на клиенте;
– при отсутствии сети запросы на подключение записываются в хранилище, с указанием времени производимого запроса. Когда же подключение возобновляется, производится вычитывание данных из хранилища и передачи из на сервер, с одновременной очисткой очереди запросов. Это дает возможность обеспечить определенную клиент-серверную работу без непосредственного подключения к сети;
Слой рабочих процессов
Все реализованные алгоритмы, которые не относятся к слоям ядра, и не представляют собой GUI должны быть вынесены в классы специфических последовательностей рабочих процессов. Каждый из этих процессов оформляется в своем стиле, и подключается к основной части приложения путем добавления ссылок на экземпляр соответствующего класса в GUI. В подавляющем большинстве случаев, все эти процессы являются не визуальными. Однако имеются некоторые исключения, например, когда необходимо осуществить длинную последовательность предопределенных кадров анимации, с заданными алгоритмами отображения
Вызывающий код должен иметь минимальные знания об этой функциональности.
Один из часто используемых процессов – процесс авторизации пользователя – очевидный претендент на рефакторинг с использованием паттерна «машины состояний».
Каждый вызов слоев ядра сопровождается передачей объекта обратного вызова (callback), и именно через него должно быть возвращено управление в приложение при успешном выполнении команды или возникновения ошибок, либо возможно использование асинхронного программирования.
Локальное хранилище
Существует большое количество способов сохранение временных данных в постоянном хранилище устройства.
Как правило использования постоянных хранилищ призвана обеспечить существенное снижение сетевого трафика, за счёт использования уже полученной из сети информации. Однако, в некоторых случаях это не происходит поскольку источником этой информации является сервер, который и принимают решения относительно актуальности данной информации.
Локальное хранилище на основе файловой системы
Использование словаря в качестве формата полученных данных позволяет автоматически решить еще целый ряд архитектурных проблем:
данные в массивах могут быть представлены точно в той последовательности, в которой они были получены от сервера.
данные однозначно соответствуют используемому запросу к серверу, с точностью до передаваемых параметров в POST запросе (т. е. легко было отличить объекты полученный от определенной команды, от объекта, полученного от той же команды, но с другими данными, переданными в качестве параметров POST пост запроса).
Атомарность записи объекта данных в постоянное хранилище.
Мгновенность и атомарность чтение данных из постоянного хранилища.
Полное соответствие ACID
Отсутствие необходимости в нормализации данных.
Независимость в интерпретации данных.
Все данные всегда актуальны.
Объем кода поддержки минимален (1 строка).
Для чтения сериализированных сохраненных данных нет необходимости в том, чтоб задействовать дополнительную логику. Возврат данных может осуществляться той же командой, которая читает данные из сети.
Отрицательной стороной такого подхода считается, что это плохо влияет на производительность устройства, однако, изучение вопроса показывает, что объем таких данных не превышает 5Кбайт, данные загружаются в память мгновенно, единым блоком, и таким же образом освобождаются из памяти, сразу же после того, как в них отпадает необходимость. В то же время чтение данных блоками (построчно) из базы данных SQL порождает большое количество объектов (на уровне, выходящем за рамки контроля приложения), которые суммарно превышают указанный объем, к тому же, создают дополнительную нагрузку на процессор. Использование центрального хранилище оправдано тогда, когда данные должны сохраняться долгое время, на протяжении многих сессий работы приложения. При этом, данные из сети загружаются частично.
Локальное хранилище на основе средств фреймворка