Исполнитель: ___________________________
(Фамилия, И.О.)
Группа № ____________
Вариант №___________
Исходные данные: год исследования 1996
эндогенная переменная: Y - число зарегистрированных преступлений;
экзогенные переменные:
X 1 – численность населения;
X 2 – численность зарегистрированных безработных;
X 3 – численность предприятий и организаций;
X 4 – номинальная начисленная среднемесячная заработная плата.
- Для выявления данных с аномальными значениями признаками рассчитаем средние значения и стандартные отклонения показателей на листе «Данные». Согласно «правилу трех сигм» аномальными считаются показатели, отличающиеся от среднего значения более, чем на три стандартных отклонения. Анализ значений показывает, что для города Сыктывкара имеется превышения по показателям «Численность населения» и «Численность предприятий и организаций». Так как превышение значений не является достаточно существенным и проявляется только по двум показателям, оставим это наблюдение в выборке.
- Проанализируем статистические взаимосвязи между показателями. Для этого вычислим парные коэффициенты корреляции и проанализируем их статистическую значимость. Для вычисления используем Анализ данных/Корреляция и выведем результаты на лист «Корреляция ». На этом же листе проанализируем значимость полученных оценок с помощью критерия Стьюдента при уровне значимости a = 5%. Сравнение t- статистик с t (критическим) показывает, что при данном объеме выборки статистически незначимыми являются лишь оценки коэффициентов корреляции r [ X2, X4 ] и r [ X3, X4 ]. Но анализ значимости полученных оценок выявил, что оценку коэффициента r [ X3, X4 ] можно считать статистически значимой на уровне 8%.
Перейдем к анализу значений полученных оценок коэффициентов корреляции, которые представлены в таблице ниже
| Y | X1 | X2 | X3 | X4 | |
| Y | 1,0000 | ||||
| X1 | 0,9646 | 1,0000 | |||
| X2 | 0,8099 | 0,8001 | 1,0000 | ||
| X3 | 0,9547 | 0,9554 | 0,7734 | 1,0000 | |
| X4 | 0,4712 | 0,5024 | 0,1463 | 0,3673 | 1,0000 |
Как видно из представленной таблицы, число зарегистрированных преступлений Y имеет сильную линейную связь со следующими показателями: численность населения X1, число зарегистрированных безработных X2, численность предприятий и организаций X3, но при этом нужно учитывать что они сильно взаимосвязаны между собой.
- Из объясняющих переменных, сильнее всего коррелирует с результатом переменная X 1 – численность населения. На листе «Парная регрессия » построим поле корреляции, предварительно расположив данные по возрастанию значений фактора X 1 .
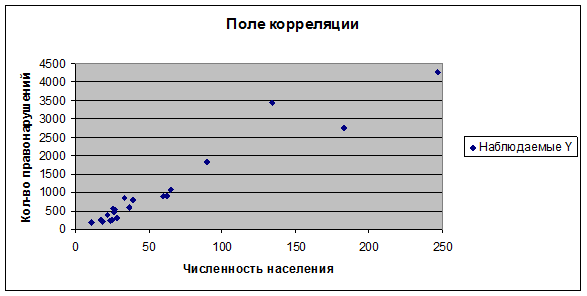
Из графика можно предположить о линейной форме связи между количеством зарегистрированных преступлений (Y) и численностью населения (X 1). В этом случае спецификация будет иметь следующий вид:
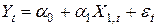 ,
,  ,
,
где 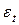 - случайные величины, относительно которых будем предполагать, что выполняются предпосылки теоремы Гаусса-Маркова:
- случайные величины, относительно которых будем предполагать, что выполняются предпосылки теоремы Гаусса-Маркова:
1) 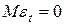 ;
;
2)  не зависит от t;
не зависит от t;
3)  при
при  и кроме того,
и кроме того,
4) имеет нормальное распределение.
Исключим одно из наблюдений (город Сосногорск) и оценим параметры модели с помощью функции ЛИНЕЙН (). Оцененная спецификация имеет вид:

Сравним полученное уравнение регрессии с наблюдаемыми значениями на графике

Далее оценим значения случайной последовательности с помощью остатков  и проверим выполняются ли предпосылки нашей модели. Условие некоррелированности остатков проверим с помощью теста Дарбина-Уотсона. Статистика Дарбина-Уотсона DW = 2,34 показывает, что нет оснований отклонять гипотезу о некоррелированности остатков. Условие гомоскедастичности случайных возмущений проверим с помощью теста Голдфельда-Квандта. Значение статистик CQ = 0,06 и 1/CQ = 17,84 показывает, что гипотеза о гомоскедастичности должны быть отвергнута при уровне значимости 5%. Для проверки гипотезы о нормальном распределении построим гистограмму остатков и
и проверим выполняются ли предпосылки нашей модели. Условие некоррелированности остатков проверим с помощью теста Дарбина-Уотсона. Статистика Дарбина-Уотсона DW = 2,34 показывает, что нет оснований отклонять гипотезу о некоррелированности остатков. Условие гомоскедастичности случайных возмущений проверим с помощью теста Голдфельда-Квандта. Значение статистик CQ = 0,06 и 1/CQ = 17,84 показывает, что гипотеза о гомоскедастичности должны быть отвергнута при уровне значимости 5%. Для проверки гипотезы о нормальном распределении построим гистограмму остатков и 
и сравним с кривой плотности нормального распределения. Общий вид гистограммы показывает, что нет оснований отклонить гипотезу о нормальном распределении остатков.
Проверим значимость оценок коэффициентов уравнения и значимость всего уравнения в целом с помощью Анализа данных/Регрессия. P -значения t -статистик показывают, что коэффициент наклона регрессии является статистически значимым (уровень значимости = 2,4659E-11), а свободный член является статистически не значимым (уровень значимости = 0,96).
Проверим адекватность оцененной модели, сравнив точечную и доверительную оценку для Y - числа зарегистрированных преступлений с наблюдаемым значением по г.Сосногорску. Наблюдаемое значение Y = 898, прогнозное точечное значение, полученное через уравнение регрессии, равно 
Доверительный интервал, построенный с доверительной вероятностью 0,95, равен (387,94; 1762,33) и захватывает наблюдаемое значение Y.
Полученные результаты позволяют признать оцененную модель адекватной и пригодной для целей прогнозирования.
- Составим спецификацию эконометрической модели, включив в нее все переменные:
X 1 – численность населения;
X 2 – численность зарегистрированных безработных;
X 3 – численность предприятий и организаций;
X 4 – номинальная начисленная среднемесячная заработная плата.
В этом случае спецификация примет вид
 , ,
, ,
где - случайные величины, для которых выполняются предпосылки теоремы Гаусса-Маркова.
Исключим одно из наблюдений (город Сосногорск) и оценим параметры модели с помощью Анализа данных/Регрессия. Результаты выведем на листе «Множественная регрессия 2 ». Оцененная спецификация имеет вид:


Проверим адекватность оцененной модели, сравнив точечную и доверительную оценку для Y - числа зарегистрированных преступлений с наблюдаемым значением по г.Сосногорску. Наблюдаемое значение Y = 898, прогнозное точечное значение, полученное через уравнение регрессии, равно  . Доверительный интервал, построенный с доверительной вероятностью 0,95, равен (429,23; 1665,16) и захватывает наблюдаемое значение Y. Полученные результаты позволяют признать оцененную модель адекватной и пригодной для целей прогнозирования.
. Доверительный интервал, построенный с доверительной вероятностью 0,95, равен (429,23; 1665,16) и захватывает наблюдаемое значение Y. Полученные результаты позволяют признать оцененную модель адекватной и пригодной для целей прогнозирования.
Тесноту выявленной зависимости оценим с помощью коэффициента детерминации 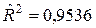 . Как видим существует достаточно тесная зависимость между Y – количеством правонарушений и X 1 – численность населения; X 2 – численность зарегистрированных безработных; X 3 – численность предприятий и организаций; X 4 – номинальная начисленная среднемесячная заработная плата.
. Как видим существует достаточно тесная зависимость между Y – количеством правонарушений и X 1 – численность населения; X 2 – численность зарегистрированных безработных; X 3 – численность предприятий и организаций; X 4 – номинальная начисленная среднемесячная заработная плата.
Проверим значимость полученных оценок коэффициентов уравнения и всего уравнения в целом. P -значения t -статистик показывают, что статистически значимыми является оценка коэффициента наклона для X 3 (уровень значимости = 0,03) Статистически не значимыми являются оценки коэффициента наклона для X 1 (уровень значимости = 0,36), коэффициента наклона для X 2 (уровень значимости = 0,15), коэффициента наклона для X 4 (уровень значимости = 0,18) и свободного члена (уровень значимости = 0,24). Значимость F - статистики равна 3,55285E-09, что говорит о том, что все уравнение в целом и коэффициент детерминации является статистически значимым.
Сравним оцененную модель множественной регрессии с ранее построенной моделью парной регрессии. Для этого сравним оценки коэффициентов детерминации: для парной линейной регрессии -  , для множественной линейной регрессии . Как видим разница между ними является несущественной, что и подтверждает значение статистики F = 0,68 < Fкр = 3,34. Это означает, что переменные X 2 – численность зарегистрированных безработных, X 3 – численность предприятий и организаций и X 4 – номинальная начисленная среднемесячная заработная плата, могут быть исключены.
, для множественной линейной регрессии . Как видим разница между ними является несущественной, что и подтверждает значение статистики F = 0,68 < Fкр = 3,34. Это означает, что переменные X 2 – численность зарегистрированных безработных, X 3 – численность предприятий и организаций и X 4 – номинальная начисленная среднемесячная заработная плата, могут быть исключены.
- Попробуем улучшить качество построенной модели с помощью взвешенного метода наименьших квадратов. Для этого оценим параметры следующей модели
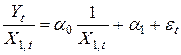 , ,
, ,
где - случайные величины, для которых выполняются предпосылки теоремы Гаусса-Маркова.
Значимость F -статистики оцененной модели равна 0,23, что говорит о невысоком качестве всего уравнения в целом и необходимости отказаться от предложенной модели.
Рассмотрим модель без свободного члена, т.е.
 , ,
, ,
где - случайные величины, для которых выполняются предпосылки теоремы Гаусса-Маркова.
Оцененная спецификация имеет вид

Анализ качества полученных оценок: значимость оценки коэффициента наклона равна 2,59945E-14, значимость F -статистики равна 8,6622E-14, говорит о высоком качестве уравнения.
Попробуем улучшить качество последней модели, введя фиктивную переменную D = 0/1 ( район/город) и рассмотрим следующую модель
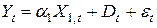 , ,
, ,
где - случайные величины, для которых выполняются предпосылки теоремы Гаусса-Маркова.
Оцененная спецификация имеет вид

Анализ значимости коэффициента наклона при фиктивной переменной показывает, что влияние фиктивной переменной на результат является статистически не значимым (значимость соответствующей t -статистики равна 0,58) и переменная D может быть исключена из модели.
Таким образом, из рассмотренных моделей остановимся на модели без свободного члена. Проверим выполнение условий теоремы Гаусса-Маркова и условие нормальности остатков. Проведенный анализ на листе «Проверка свойств» показывает, что нарушается условие гомоскедастичности.
Проверим адекватность оцененной модели, сравнив точечную и доверительную оценку для Y - числа зарегистрированных преступлений с наблюдаемым значением по г.Сосногорску. Наблюдаемое значение Y = 898, прогнозное точечное значение, полученное через уравнение регрессии, равно 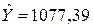 . Доверительный интервал, построенный с доверительной вероятностью 0,95, равен (409,52; 1745,26) и захватывает наблюдаемое значение Y. Полученные результаты позволяют признать оцененную модель адекватной и пригодной для целей прогнозирования.
. Доверительный интервал, построенный с доверительной вероятностью 0,95, равен (409,52; 1745,26) и захватывает наблюдаемое значение Y. Полученные результаты позволяют признать оцененную модель адекватной и пригодной для целей прогнозирования.