При первичном кодировании используется обычно равномерное квантование отсчетов звукового сигнала (ЗС) с разрядностью 16...24 бит при частоте дискретизации f д = 44,1...96 кГц. В каналах студийного качества обычно применяется разрядность 16 бит, f д = 48 кГц, полоса частот кодируемого звукового сигнала 20...20000 Гц. Динамический диапазон такого цифрового канала составляет около 54 дБ. Если f д = 48 кГц и разрядность16 бит, то скорость цифрового потока при передаче одного такого сигнала v = 48 х 16 = 768кбит/с. Это требует суммарной пропускной способности канала связи при передаче звукового сигнала формата 5.1 (Dolby Digital) более 3,840 Мбит/с. Но человек способен со своими органами чувств сознательно обрабатывать лишь около 100 бит/с информации. Поэтому можно говорить о присущей первичным цифровым звуковым сигналам значительной избыточности.
Компрессия цифровых аудиоданных обычно выполняется в кодере источника (рисунок 1) после тракта формирования программ (ТФП) перед подачей ЗС в каналы трактов первичного распределения программ (ТПРП).
Различают статистическую и психоакустическую избыточность первичных цифровых сигналов. Сокращение статистической избыточности базируется на учете свойств самих звуковых сигналов, а психоакустической — на учете свойств слухового восприятия.
Статистическая избыточность обусловлена наличием корреляционной связи между соседними отсчетами временной функции звукового сигнала при его дискретизации.
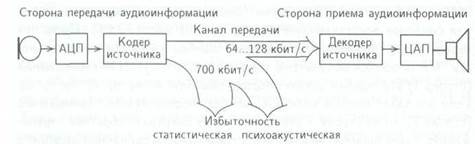
Рисунок 1 К устранению избыточности цифровых звуковых сигналов
Для ее уменьшения применяют достаточно сложные алгоритмы обработки. При их использовании потери информации нет, однако исходный сигнал оказывается представленным в более компактной форме, что требует меньшего числа битов при его кодировании. Важно, чтобы все эти алгоритмы позволяли бы при обратном преобразовании восстанавливать исходные сигналы без искажений. Наиболее часто для этой цели используют ортогональные преобразования. Оптимальным с этой точки зрения является преобразование Карунена-Лоэва. Но его реализация требует существенных вычислительных затрат. Незначительно по эффективности ему уступает модифицированное дискретное косинусное преобразование (МДКП). Важно также, что для реализации МДКП разработаны быстрые вычислительные алгоритмы. Кроме того, между коэффициентами преобразования Фурье (к которому мы все привыкли) и коэффициентами МДКП существует простая связь, что позволяет представлять результаты вычислений в форме, достаточно хорошо согласующейся с работой механизмов слуха. Дополнительно уменьшить скорость цифрового потока позволяют также методы кодирования, учитывающие статистику звуковых сигналов (например, вероятности появления уровней звукового сигнала разной величины). Примером такого учета являются коды Хаффмана, где наиболее вероятным значениям сигнала приписываются более короткие кодовые слова, а отсчеты, вероятность появления которых мала, кодируются кодовыми словами большей длины. Именно в силу этих двух причин в наиболее эффективных алгоритмах компрессии цифровых аудиоданных кодированию подвергаются не сами отсчеты ЗС, а коэффициенты МДКП и для их кодирования используются кодовые таблицы Хаффмана. Заметим, что число таких таблиц достаточно велико и каждая из них адаптирована к звуковому сигналу определенного жанра.
Однако даже при использовании достаточно сложных процедур обработки устранение статистической избыточности звуковых сигналов позволяет в конечном итоге уменьшить требуемую пропускную способность канала связи лишь на 15...25 % по сравнению с ее исходной величиной, что никак нельзя считать революционным достижением.
После устранения статистической избыточности скорость цифрового потока при передаче высококачественных ЗС и возможности человека по их обработке отличаются, по крайней мере, на несколько порядков. Это свидетельствует также о существенной психоакустической избыточности первичных цифровых ЗС и, следовательно, о возможности ее уменьшения. Наиболее перспективными с этой точки зрения оказались методы, учитывающие такие свойства слуха, как маскировка, предмаскировка и послемаскировка. Если известно, какие доли (части) звукового сигнала ухо воспринимает, а какие нет вследствие маскировки, то можно вычленить и затем передать по каналу связи лишь те части сигнала, которые ухо способно воспринять, а неслышимые доли (составляющие исходного сигнала) можно отбросить (не передавать по каналу связи).
Кроме того, сигналы можно квантовать с возможно меньшим разрешением по уровню так, чтобы искажения квантования, изменяясь по величине с изменением уровня самого сигнала, еще оставались бы неслышимыми, т.е. маскировались бы исходным сигналом. После устранения психоакустической избыточности точное восстановление формы временной функции ЗС при декодировании оказывается уже невозможным.
В этой связи следует обратить внимание на две очень важные для практики особенности. Если компрессия цифровых аудиоданных уже использовалась ранее в канале связи при доставке программы, то ее повторное применение часто ведет к появлению существенных искажений, хотя исходный сигнал кажется нам на слух вполне качественным перед повторным кодированием. Поэтому очень важно знать «историю» цифрового сигнала, и какие методы кодирования при его передаче уже использовались ранее. Если измерять традиционными методами параметры качества таких кодеков на тональных сигналах (как это часто и делается), то мы будем для них получать при разных, даже самых малых установленных значениях скорости цифрового потока, практически идеальные величины измеряемых параметров. Результаты же тестовых прослушиваний для них, выполненные на реальных звуковых сигналах, будут принципиально отличаться. Иными словами, традиционные методы оценки качества для кодеков с компрессией цифровых аудиоданных не пригодны. Для экспертных оценок качества кодеков с компрессией цифровых аудиоданных следует использовать отрывки звуковых сигналов с компакт-диска EBU-SQAM, Cat. H- 422 204-2. Он специально создан группой MPEG для этой цели. При объективной оценке качества этих устройств следует руководствоваться рекомендацией ITU-R «Method for objective Measurements of Perceived Audio Quality» (Document 10-4/19-E, 19 March 1998).
Работы по анализу качества и оценке эффективности алгоритмов компрессии цифровых аудиоданных с целью их последующей стандартизации начались в 1988 г., когда была образована международная экспертная группа MPEG (Moving Pictures Experts Group). Итогом работы этой группы на первом этапе явилось принятие в ноябре 1992 г. международного стандарта MPEG-1 ISO/IEC 11172-3 (здесь и далее цифра 3 после номера стандарта относится к той его части, где речь идет о кодировании звуковых сигналов).
К настоящему времени достаточное распространение в радиовещании получили также еще нескольких стандартов MPEG, таких, как MPEG-2 ISO/IEC 13818-3. 13818-7 и MPEG-4 ISO/IEC 14496-3. В отличие от этого в США был разработан стандарт Dolby AC-3 (А/52) в качестве альтернативны стандартам MPEG.
Несмотря на значительное разнообразие алгоритмов компрессии цифровых аудиоданных, структура кодера, реализующего такой алгоритм обработки сигналов, может быть представлена в виде обобщенной схемы так, как это показано на рисунке 2. В блоке временной и частотной сегментации исходный звуковой сигнал s(n) разделяется на субполосные составляющие и сегментируется по времени.

Рисунок 2. Обобщенная структурная схема кодера с компрессией цифровых аудиоданных
Длина кодируемой выборки зависит от формы временной функции звукового сигнала. При отсутствии резких выбросов по амплитуде используется так называемая длинная выборка, обеспечивающая высокое разрешение по частоте. В случае же резких изменений амплитуды сигнала длина кодируемой выборки резко уменьшается, что дает более высокое разрешение по времени. Решение об изменении длины кодируемой выборки принимает блок психоакустического анализа, вычисляя психоакустическую энтропию сигнала. После сегментации субполосные сигналы нормируются, квантуются и кодируются. В наиболее эффективных алгоритмах компрессии кодированию подвергаются не сами отсчеты выборки ЗС, а соответствующие им коэффициенты МДКП.
Обычно при компрессии цифровых аудиоданных используется энтропийное кодирование, при котором одновременно учитываются как свойства слуха человека, так и статистические характеристики звукового сигнала. Однако основную роль при этом играют процедуры устранения психоакустической избыточности. Учет закономерностей слухового восприятия звукового сигнала выполняется в блоке психоакустического анализа. Здесь по специальной процедуре для каждого субполосного сигнала рассчитывается максимально допустимый уровень искажений (шумов) квантования, при котором они еще маскируются полезным сигналом данной субполосы. Блок динамического распределения битов (рисунок 2) в соответствии с требованиями психоакустической модели для каждой субполосы кодирования выделяет такое минимально возможное их число, при котором уровень искажений, вызванных квантованием, не превышал бы порога их слышимости, рассчитанного психо-акустической моделью. В современных алгоритмах компрессии используются также специальные процедуры в форме итерационных циклов, позволяющие управлять величиной энергии искажений квантования в субполосах при недостаточном числе доступных для кодирования битов. Для обеспечения правильного декодирования компрессированных сигналов, кроме кодовых слов отсчетов ЗС или соответствующих им коэффициентов МДКП (основная аудиоинформация), к декодеру передается также и определенная дополнительная информация. После кодирования цифровые потоки основной и дополнительной информации форматируются. При этом наиболее важная часть цифровых данных подвергается помехоустойчивому кодированию (CRC-код).