Содержание
Описание методов численного решения СЛАУ.. 3
Метод Якоби. 4
Особенности реализации на CUDA.. 5
Исходныйкод. 7
Результаты выполнения программы.. 13
Заключение. 14
Описание методов численного решения СЛАУ
Методы численного решения СЛАУ делятся на две большие группы:
прямые методы и итерационные методы.
Прямыми методами называются методы, позволяющие получить решение системы за конечное число арифметических операций, т.е. эквивалентными преобразованиями привести решаемую алгебраическую систему к наиболее простому виду, из которого решение находится уже непосредственно. Под простейшими подразумеваются системы с диагональными, двухдиагональными, треугольными и т.п. матрицами. Уменьшение ненулевых элементов в матрице преобразованной системы, ведет к простоте и устойчивости решения, но, с другой стороны, приведение к такому виду сложно и неустойчиво. Обычно стремятся к компромиссу между этими взаимно противоположными требованиями, и в зависимости от целей, преследуемых при решении СЛАУ, приводят её к диагональному, двухдиагональному или треугольному виду.
К прямым методам относятся метод Крамера, метод Гаусса, LU-метод и т.д. Эти методы можно назвать конечными или даже точными. Точными они являются, поскольку решение выражается в виде точных формул через коэффициенты системы.
Следует заметить, что реализация прямых методов на компьютере приводит к решению с погрешностью, т.к. все арифметические операции над переменными с плавающей точкой выполняются с округлением. В зависимости от свойств матрицы исходной системы эти погрешности могут достигать значительных величин.
Итерационные методы или методы последовательных приближений — это методы, порождающие последовательность приближений к искомому решению 𝑥, которое получается как предел
Сходимость метода обычно подразумевает под собой, если к пределу сходится конструируемая им последовательность приближений {𝑥.
К этим методам относятся метод Зейделя, Якоби, метод верхних релаксаций и т.д.
Метод Якоби
Метод Якоби — разновидность метода простой итерации для решения системы линейных алгебраических уравнений. Назван в честь Карла Густава Якоби.
Постановка задачи:
Возьмём систему линейных уравнений:

Описание метода:
Для того, чтобы построить итеративную процедуру метода Якоби, необходимо провести предварительное преобразование системы уравнений
 к итерационному виду
к итерационному виду 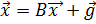 . Оно может быть осуществлено по одному из следующих правил:
. Оно может быть осуществлено по одному из следующих правил:



где в принятых обозначениях D означает матрицу, у которой на главной диагонали стоят соответствующие элементы матрицы A, а все остальные нули; тогда как матрицы U и L содержат верхнюю и нижнюю треугольные части A, на главной диагонали которых нули, E — единичная матрица.
Тогда процедура нахождения решения имеет вид:
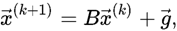 ,
,
Или в виде поэлементной формулы:

где k счётчик итерации.
В отличие от метода Гаусса-Зейделя мы не можем заменять  на
на 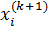 в процессе итерационной процедуры, так как эти значения понадобятся для остальных вычислений. Это наиболее значимое различие между методом Якоби и методом Гаусса-Зейделя решения СЛАУ. Таким образом на каждой итерации придётся хранить оба вектора приближений: старый и новый.
в процессе итерационной процедуры, так как эти значения понадобятся для остальных вычислений. Это наиболее значимое различие между методом Якоби и методом Гаусса-Зейделя решения СЛАУ. Таким образом на каждой итерации придётся хранить оба вектора приближений: старый и новый.
Достаточным признаком сходимости будем считать утверждение – если в системе линейных алгебраических уравнений 𝐴𝑥 = 𝑏 матрица 𝐴 является квадратной и имеет диагональное преобладание, то метод Якоби для решения этой системы сходится при любом начальном приближении.
Особенности реализации на CUDA
Полный отказ от работы с CPU при разработке приложения решения СЛАУ не является возможным, так как графический процессор напрямую не имеет доступ к памяти компьютера. Поэтому прежнему за исполнение программы и постобработку данных будет отвечать CPU, а все трудоемкие вычислительные процессы будут выполняться на GPU.
Общая концепция CUDA строится в том, что GPU, так же называемый устройством или device, выступает в роли массивно-параллельного сопроцессора к GPU, называемым host. Отсюда получаем, что программа на CUDA включает работу как CPU, так и GPU, при этом весь непараллельный код, подготовка и копирование данных на устройство, задание параметров для ядра и его запуск, выполняется на CPU.
Как уже упоминалось, графический процессор напрямую не имеет доступ к памяти компьютера, однако, CPU тоже не может напрямую обращаться в память GPU. Поэтому при работе с данными обычными указателями не обойтись. Для обращения к памяти к GPU через CPU и наоборот, необходимо пользоваться специальными функциями, входящими в стандартный набор CUDA SDK.
Все стандартные математические функции из библиотек языка C, C++ поддерживаются CUDA. Однако есть особенность использования чисел с двойной точностью (double). На графических устройствах наблюдается падение производительности при использовании double, по сравнению числами сплавающей запятой (float), поэтому предпочтительнее использовать, при возможности, тип float.
В CUDA есть особенность использования условного оператора if. Когда выполнение программы идет по разным веткам условного оператора if, нити одного варпа будут выполнять различные инструкции. Оказывается, нити, которые не должны исполнять данную инструкцию просто будут простаивать. В случае ветвления в начале будет выполнена одна ветвь оператора if, а затем другая. Очевидно, что в этом случае можно потерять до 50% теоретической производительности GPU. И все больше усложняется, если такое ветвление многоуровневое. Естественно если все нити варпа должны идти по одной ветви условного оператора, другая ветвь считается, не будет и в этом случае не будет потери производительности. Таким образом, в CUDA программах предпочтительно использовать те реализации алгоритмов, в которых меньше ветвления в рамках одного варпа.
Чтобы добиться максимальной производительности на архитектуре Kepler и его мультипроцессоре (SMX) требуется, чтобы ядро запускалось с полным заполнением Kepler нитями и блоками. Поэтому лучше запускать ядра со значительно большим количеством блоков, чем требуется, чтобы заполнить GPU.
При работе с CUDA можно выделить основные шаги при проектировании программы.
Подготовка памяти. Необходимо заранее распределить данные по типам памяти в GPU. Для этого в CUDA используются функции cudaMalloc,cudaMemcpy и cudaFree, аналогичные стандартным malloc, memcpy и free, но, разумеется, все операции проводятся над видеопамятью. У функцииcudaMemcpy присутствует дополнительный параметр, отвечающий направление копирования информации.
Конфигурация блоков. Необходимо найти оптимальный баланс между размером блоков и их количеством. Отсюда можно снизить количество обращений к глобальной памяти через увеличение количества потоков и работать с быстрой разделяемой памятью, что повысит производительность. Однако и большое количество регистров выделяемых на блок может негативно сказаться на работе, ведь размер регистров фиксирован и при слишком большом количестве GPU начнет размещать данные в медленной локальной памяти.
Запуск ядра. Вызов ядра не отличается от вызова любой функции на языке C, только добавляется в начале объявления идентификатор __global__. Единственное существенное отличие кроется в необходимости заранее передать ему размерности сетки и блока при вызове ядра.
Получение результатов. После вычислений на GPU необходимо скопироватьрезультаты выполнения программы в хост. Используется все та же функцияcudaMemcpy, только с указанием обратного направления копирования (из GPU вCPU).
Освобождение памяти. И последнее действие, помогающее предотвратить утечку памяти, освободить все выделенные ресурсы.
Исходныйкод
#include "cuda_runtime.h"
#include <stdlib.h>
#include <iostream>
#include <stdio.h>
#include <math.h>
#include <time.h>
#include <cstring>
#define Thread 512
//Raschetpriblijennogoznachenijaiteracii k+1
__global__ void KernelJacobi(float* deviceA, float* deviceF, float* deviceX0, float* deviceX1, int N)
{
float temp;
inti = blockIdx.x * blockDim.x + threadIdx.x;
deviceX1[i] = deviceF[i];
for (int j = 0; j < N; j++) {
if (i!= j)
deviceX1[i] -= deviceA[j + i * N] * deviceX0[j];
else
temp = deviceA[j + i * N];
}
deviceX1[i] /= temp;
}
//Raschetdeltidlyausloviaostanovki
__global__ void EpsJacobi(float* deviceX0, float* deviceX1, float* delta, int N)
{
inti = blockIdx.x * blockDim.x + threadIdx.x;
delta[i] += fabs(deviceX0[i] - deviceX1[i]);
deviceX0[i] = deviceX1[i];
}
intmain()
{
srand(time(NULL));
float *hostA, *hostX, *hostX0, *hostX1, *hostF, *hostDelta;
float sum, eps;
float EPS = 1.e-5;
int N = 2048;
float size = N * N;
int count;
int Block = (int)ceil((float)N / Thread);
dim3 Blocks(Block);
dim3 Threads(Thread);
intNum_diag = 0.5f * (int)N * 0.3f;
unsigned intmem_sizeA = sizeof(float) * size;
unsigned intmem_sizeX = sizeof(float) * (N);
//Videleniepamyatinahoste
hostA = (float*)malloc(mem_sizeA);
hostF = (float*)malloc(mem_sizeX);
hostX = (float*)malloc(mem_sizeX);
hostX0 = (float*)malloc(mem_sizeX);
hostX1 = (float*)malloc(mem_sizeX);
hostDelta = (float*)malloc(mem_sizeX);
//Inicializacijamassivov
for (inti = 0; i< size; i++) {
hostA[i] = 0.0f;
}
for (inti = 0; i< N; i++) {
hostA[i + i * N] = rand() % 50 + 1.0f * N;
}
for (int k = 1; k <Num_diag + 1; k++) {
for (inti = 0; i< N - k; i++) {
hostA[i + k + i * N] = rand() % 5;
hostA[i + (i + k) * N] = rand() % 5;
}
}
for (inti = 0; i< N; i++) {
hostX[i] = rand() % 50;
hostX0[i] = 1.0f;
hostDelta[i] = 0.0f;
}
for (inti = 0; i< N; i++) {
sum = 0.0f;
for (int j = 0; j < N; j++)
sum += hostA[j + i * N] * hostX[j];
hostF[i] = sum;
}
for (inti = 0; i< N; i++)
hostX1[i] = 1.0f;
//Videleniepamyatina GPU
float *deviceA, *deviceX0, *deviceX1, *deviceF, *delta;
cudaMalloc((void**)&deviceA, mem_sizeA);
cudaMalloc((void**)&deviceF, mem_sizeX);
cudaMalloc((void**)&deviceX0, mem_sizeX);
cudaMalloc((void**)&deviceX1, mem_sizeX);
cudaMalloc((void**)&delta, mem_sizeX);
//Peredachadannichna GPU
cudaMemcpy(deviceA, hostA, mem_sizeA, cudaMemcpyHostToDevice);
cudaMemcpy(deviceF, hostF, mem_sizeX, cudaMemcpyHostToDevice);
cudaMemcpy(deviceX0, hostX0, mem_sizeX, cudaMemcpyHostToDevice);
cudaMemcpy(deviceX1, hostX1, mem_sizeX, cudaMemcpyHostToDevice);
count = 0;
eps = 1.0f;
// Инициализация и создание Event'овдля определение времени расчета
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
// Инициализация переменной времени расчета
float gpuTime = 0.0f;
// Запусктаймера
cudaEventRecord(start, 0);
//ZapuskmetodaJakobi
while (eps > EPS) {
count++;
cudaMemcpy(delta, hostDelta, mem_sizeX, cudaMemcpyHostToDevice);
KernelJacobi<<<Blocks, Threads>>>(deviceA, deviceF, deviceX0, deviceX1, N);
EpsJacobi<<<Blocks, Threads>>>(deviceX0, deviceX1, delta, N);
cudaMemcpy(hostDelta, delta, mem_sizeX, cudaMemcpyDeviceToHost);
eps = 0.0f;
for (int j = 0; j < N; j++) {
eps += hostDelta[j];
hostDelta[j] = 0;
}
eps = eps / N;
}
cudaMemcpy(hostX1, deviceX1, mem_sizeX, cudaMemcpyDeviceToHost);
// Остановкатаймера
cudaEventRecord(stop, 0);
// Синхронизация Event'ов
cudaEventSynchronize(stop);
// Получение времени расчета как интервала между Event'ами
cudaEventElapsedTime(&gpuTime, start, stop);
/*
std::cout<< "Matrix A." <<std::endl;
for (inti = 0; i< N; i++) {
for (int j = 0; j < N; j++) {
std::cout<<hostA[i * N + j] << " ";
}
std::cout<<std::endl;
}
std::cout<< "Matrix F." <<std::endl;
for (inti = 0; i< N; i++) {
std::cout<<hostF[i] << " ";
}
std::cout<<std::endl;
std::cout<< "Matrix X." <<std::endl;
for (inti = 0; i< N; i++) {
std::cout<<hostX[i] << " ";
}
std::cout<<std::endl;
std::cout<< "Result matrix." <<std::endl;
for (inti = 0; i< N; i++) {
std::cout<< hostX1[i] << " ";
}
std::cout<<std::endl;
*/
std::cout<< "Размерматрицы A: " <<mem_sizeA / 1024.0 / 1024.0 << " MB." <<std::endl;
std::cout<< "Расчетзавершен." <<std::endl;
std::cout<< "Времярасчетана GPU: " <<gpuTime<< " миллисекунд." <<std::endl;
// Удаление Event'ов
cudaEventDestroy(start);
cudaEventDestroy(stop);
//Osvobojdeniepamyati
cudaFree(deviceA);
cudaFree(deviceF);
cudaFree(deviceX0);
cudaFree(deviceX1);
free(hostA);
free(hostF);
free(hostX0);
free(hostX1);
free(hostX);
free(hostDelta);
return 0;
}