Алгоритмы слияния имеют два существенных недостатка:
1. Большой расход памяти для вспомогательной рабочей области.
2. Необходимость большого числа перемещений записей.
Эти недостатки можно устранить, создав из сортируемого файла подобие связанного списка, для чего каждая запись Ri должна иметь “поле связи” Li, в котором будет храниться № записи, следующей за данной записью в порядке возрастания ключей.
После сортировки L0=№ записи с наименьшим ключом.
Алгоритм:
Предполагается, что записи R1,…,RN содержат ключи k1,…,kN и поля связи L1,…,LN, в которых могут храниться числа от -(N+1) до (N+1). В начале и в конце файла имеются искусственные записи R0 и RN+1 с полями связи L0 и LN+1. Этот алгоритм сортировки устанавливает поля связи таким образом, что записи оказываются связанными в возрастающем порядке.
После завершения сортировки L0 указывает на запись с наименьшим ключом, при 1≤k≤N связь Lk указывает на запись, следующую за Rk, а если Rk – запись с наибольшим ключом, то Lk=0. В процессе выполнения этого алгоритма записи R0 и RN+1 служат “головами” двух линейных списков, подсписки которых в данный момент сливаются.
Отрицательная связь означает конец подсписка, о котором известно, что он упорядочен; нулевая связь означает конец списка. Предполагается, что N≥2.
Через “|Ls|←p” обозначена операция присвоить Ls значение р или –p, сохранив прежний знак Ls.
L1. [Подготовить два списка]. Установить L0←1, LN+1←2, Li← -(i+2)
при 1≤i≤N-2 и LN-1←LN←0.
Мы создаём два списка, содержащие соответственно записи
R1,R3,R5,… и R2,R4,R6,... Отрицательные связи говорят о том,
что каждый упорядоченный “подсписок” состоит всего лишь из
одного элемента. Другой способ: выполнить этот шаг, извлекая пользу из
упорядоченности, которая могла присутствовать в исходных данных.
L2. [Начать новый просмотр.] Установить s←0, t←N+1, p←Ls, q←Lt.
Если q=0, то работа алгоритма завершена.
При каждом просмотре p и q пробегают по спискам, которые
подвергаются слиянию; s обычно указывает на последнюю
обработанную запись текущего подсписка, а t – на конец только
что выведенного подсписка.
L3. [Сравнить kp: kq]. Если kp>kq, то перейти к L6.
L4. [Продвинуть p]. Установить |Ls|←p, s←p, p←Lp. Если p>0, то
Возвратиться к шагу L3.
L5. [Закончить подсписок]. Установить Ls←q, s←t.
Затем установить t←q и q←Lq один или более раз, пока не станет
q≤0, после чего перейти к шагу L8.
L6. [Продвинуть q]. (Шаги L6 и L7 двойственны по отношению к L4 и
L5.) Установить |Ls|←q, s←q, q←Lq. Если q>0, то возвратиться к
Шагу L3.
L7. [Закончить подсписок]. Установить Ls ←p, s←t. Затем установить
t←p и p←Lp один или более раз, пока не станет p≤0.
L8. [Конец просмотра]. К этому моменту p≤0 и q≤0, так как оба
указателя подвинулись до конца соответствующих подсписков.
Установить p← -p, q← -q. Если q=0, то установить |Ls|←p, |Lt|←0 и воз- вратиться к шагу L2. В противном случае возвратиться к шагу L3.
9. Алгоритмы поиска данных. Последовательный, двоичный, блочный, интерполяционный, Фибоначчиев поиск
Последовательный поиск
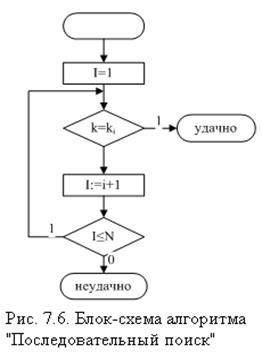
Это наиболее простой и очевидный способ отыскания записи по заданному ключу К. Он состоит в последовательном просмотре всех записей и сравнении их ключей с заданным значением ключа. Последовательность записей R1, R2,..., Rn снабжены ключами К1, К2,..., Кn. Необходимо найти запись с заданным ключом К. На рис.5.6 приведена блок-схема алгоритма «Последовательный поиск», на рис.5.7 – блок-схема алгоритма «Быстрый последовательный поиск». Ускоряющий принцип во втором алгоритме – только одно сравнение во внутреннем цикле.

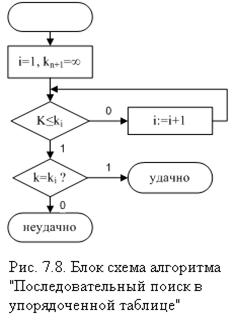 Существует способ сделать этот алгоритм поиска ещё быстрее. Если известно, что исходная последовательность расположена по возрастанию ключей, то алгоритм поиска можно сделать ещё более эффективным. На рис.5.8 представлена блок-схема алгоритма “Последовательный поиск в упорядоченной таблице”. Здесь отсутствие нужной записи обнаруживается примерно в два раза быстрее.
Существует способ сделать этот алгоритм поиска ещё быстрее. Если известно, что исходная последовательность расположена по возрастанию ключей, то алгоритм поиска можно сделать ещё более эффективным. На рис.5.8 представлена блок-схема алгоритма “Последовательный поиск в упорядоченной таблице”. Здесь отсутствие нужной записи обнаруживается примерно в два раза быстрее.
Бинарный поиск
С помощью этого алгоритма разыскивается аргумент К в таблице записей R1, R2,...,Rn, ключи которых расположены в возрастающем порядке (К1, К2,..., Кn).
Идея бинарного поиска заключается в следующем. Сначала нужно сравнить К со средним ключом в таблице. Результат сравнения позволит определить, в какой половине файла продолжать поиск, применяя к ней ту же процедуру, и т.д. После не более чем log2N сравнений ключ либо будет найден, либо будет установлено его отсутствие. Такая процедура иногда называется “Логарифмическим поиском” или “Методом деления пополам”, но наиболее употребительный термин – “Бинарный поиск”.
Одна из наиболее популярных реализаций метода использует два указателя: l и u, соответствующие верхней и нижней границам поиска. На рис.7.9 приведена блок-схема алгоритма бинарного поиска.

Рис 7.9. Бинарный поиск в упорядоченной матрице
Поиск Фибоначчи
Этот метод поиска основан на использовании чисел Фибоначчи, которые используются для построения бинарного дерева.
Алгоритм построения дерева поиска Фибоначчи:
1. Если k=0 или k=1, дерево сводится к 0.
2. Если k>=2, корнем является Fk; левое поддерево есть дерево Фибоначчи порядка k-1; правое поддерево есть дерево Фибоначчи порядка k-2 с числами в узлах, увеличенными на Fk.
Замечание.
Желательно, чтобы число ключей в таблице N удовлетворяло условию: N<Fk+1-1.
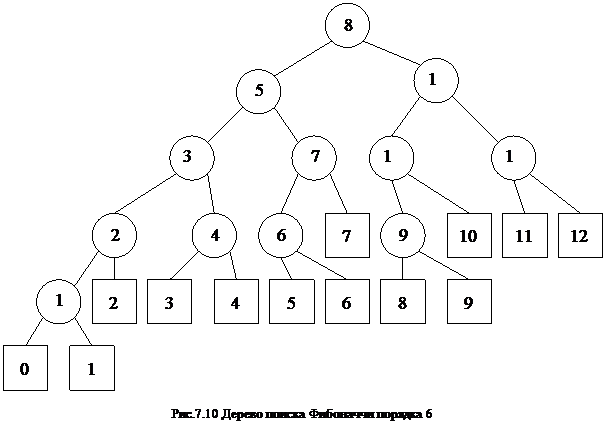
На рис.5 изображено дерево поиска Фибоначчи для N=12 и K=6. Здесь K – порядковый номер числа Фибоначчи (порядок дерева Фибоначчи).
k123456 7 8 9 1011
Fk 01123581321345569
Алгоритм поиска Фибоначчи.
Алгоритм представляется для поиска аргумента К в таблице записей
R1, R2,..., Rn, расположенных в порядке возрастания ключей
К1, К2,..., Кn.
Предлагается, что N+1 есть число Фибоначчи Fk+1. Подходящей начальной установкой данный метод можно сделать пригодным для любого N. В алгоритме переменные p и q – последовательные числа Фибоначчи.
Блок-схема алгоритма поиска Фибоначчи приведена на рис.6.

Рис.7.11 Поиск Фибоначчи
10. Хеширование, хеш-функции. Способы разрешения коллизий.
Идентификатор – атрибут, уникально определяющий запись.
Хеширование идентификатора – метод доступа, обеспечивающий прямую адресацию данных путем преобразования значения ключа в относительный или абсолютный физический адрес.
Алгоритм получения адреса называется функцией хеширования, или функцией преобразования ключа. При использовании хеш-функции возможно преобразование двух или более значений ключа в один и тот же физический адрес.
Коллизия – случай преобразования ключа в уже занятый собственный адрес.
Метод деления. Наиболее широко распространенная функция хеширования основывается на методе деления и определяется в виде
H(x) = x mod m + 1,
где m – делитель. Эта функция хеширования – одна из первых и наиболее используемых.
При отображении ключей в адреса методом деления до некоторой степени сохраняется существующая на множестве ключей равномерность распределения. Ключи с близкими значениями отображаются при этом в уникальные адреса. Например, при делителе, равном 101, такая функция отобразила бы ключи 2000, 2001, …, 2017 в адреса 82, 83, …, 99. К сожалению, если два скопления ключей или более отображаются в одни и те же адреса, то сохранение равномерности будет недостатком. Например, если имеются также ключи 3310, 3311, 3313, 3314, …, 3323, 3324, то при делителе 101 они будут отображены в адреса 79, 80, 82, 83, …, 92, 93, и с группой ключей, значение которых начинаются с 2000, произойдет много коллизий. Причина этого в том, что ключи из этих двух групп совпадают по модулю 101.
Вообще, если по модулю d совпадает много ключей, a m и d не являются взаимно простыми числами, то использование значения m в качестве делителя может привести к низкой эффективности хеширования, основанного на методе деления. Это показано в предыдущем примере, в котором m = d = 101. Возьмем другой пример: если все ключи в совокупности записи совпадают по модулю 5 и делителем является число 65, то значения ключей отображаются лишь в 13 различных позициях. Если m является большим простым числом, то обычно ключи не совпадают по модулю m, и поэтому в качестве делителя следует выбирать простое число. Исследования, однако, показывают, что удовлетворительные результаты получаются и при нечётном делителе, не имеющем множителей менее 20. В особенности следует избегать четных делителей, так как при этом четные и нечетные ключи отображаются соответственно в нечетные и четные адреса (в предположении, что адресное пространство имеет вид {1, 2, …, m}). При этом возникали бы трудности в организации таблиц, содержащих в основном четные или в основном нечетные ключи.
При хешировании по методу середины квадрата ключ умножается сам на себя, а адрес получается отсечением битов или цифр от обоих концов произведения, которое выполняется до тех пор, пока число оставшихся битов или цифр не станет равным требуемой длине адреса. Во всех получаемых произведениях при этом должны использоваться одни и те же позиции. В качестве примера рассмотрим шестизначный ключ 113586. При возведении его в квадрат получается 12901779396. Если требуется четырёхзначный адрес, могут быть выбраны позиции 5-8, дающие адрес 1779. Метод середины квадрата подвергался критике, но его применение к некоторым наборам ключей даёт хорошие результаты.
В методе свертывания ключ разбивается на части, каждая из которых имеет длину, равную длине требуемого адреса (кроме, возможно, последней части). Чтобы сформировать адрес, части затем складываются, при этом игнорируется перенос в старшем разряде. Если ключи представлены в двоичном виде, то вместо сложения может быть использована операция исключающего ИЛИ. Существуют различные вариации этого метода, которые лучше всего проиллюстрировать на конкретном примере ключа 187249653. В методе свертывания со сдвигом складываются 187, 249 и 653, при этом получается адрес 89.
В методе граничного свертывания инвертируются цифры в крайних частях ключа и, таким образом, в нашем примере складываются числа 781, 249 и 356, что даёт адрес 386. Свёртывание является функцией хеширования, удобной для сжатия многословных ключей и последующего перехода к другим функциям хеширования.
Преобразование системы счисления является методом хеширования, в котором делается попытка получить случайное распределение ключей по адресам в адресном пространстве. Ключ, представленный в системе счисления q (q обычно равно 2 или 10), рассматривается как число в системе счисления p, где p больше q, причем p и q – взаимно простые. Это число из системы счисления с основанием p переводится в систему счисления с основанием q и адрес формируется путём выбора правых цифр (или битов) нового числа или применением метода деления.
Например, ключ 53047610, рассматриваемый как 53047611, переводится в десятичную систему счисления с помощью следующих вычислений:
53047611 = 5 * 115 + 3 * 114 + 4 * 112 + 7 * 11 + 6 = 84974510.
Отсечение трех левых цифр в полученном числе дает адрес 745 в адресном пространстве {0, 1, …, 999}.
Мультипликативный метод. Весьма удобной является мультипликативная функция хеширования. Для неотрицательного целого ключа x и константы с такой, что 0<c<1, эта функция определяется в виде:
H(x) = └ m (cx mod 1) ┘ + 1.
Здесь выражение cx mod 1 обозначает дробную часть величины cx, а скобки └ ┘ - наибольшее целое, не превышающее значения заключённой между ними величины. Такая мультипликативная функция даёт хорошие результаты при правильном выборе константы c, что трудно сделать.
Повторное хеширование. Функция повторного хеширования h(p) имеет в качестве входа один индекс в массиве и выдает другой индекс. Если ячейка массива i = h(k) уже занята некоторой записью с другим ключом, то функция h(p) применяется к значению i для того, чтобы найти другую ячейку, куда может быть помещена эта запись.
Если ячейка hp(i) также занята, то хеширование выполняется еще раз, и проверяется ячейка hp(hp(i)).
Двойное хеширование. Первая функция хеширования h1(x1) = h1(x2) = i при x1 ≠ x2.
Вторая функция хеширования h2(x1) ≠ h2(x2) при x1 ≠ x2
Методы разрешения коллизий
Для разрешения коллизий используются различные методы, которые в основном сводятся к методам цепочек и открытой адресации.
Методом цепочек называется метод, в котором для разрешения коллизий во все записи вводятся указатели, используемые для организации списков цепочек переполнения. В случае возникновения коллизии при заполнении таблицы в список для требуемого адреса хеш-таблицы добавляется еще один элемент.
Поиск в хеш-таблице с цепочками переполнения осуществляется следующим образом. Сначала вычисляется адрес по значению ключа. Затем осуществляется последовательный поиск в списке, связанном с вычисленным адресом.
Процедура удаления из таблицы сводится к поиску элемента и его удалению из цепочки переполнения.

Рис.8.4. Разновидности методов разрешение коллизий
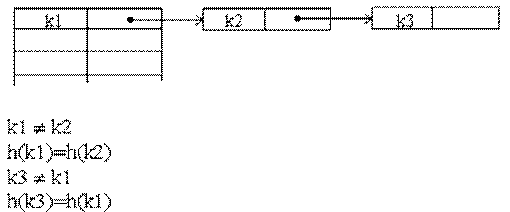
Рис.8.5. Разрешение коллизий при добавлении элементов методом цепочек
Метод открытой адресации состоит в том, чтобы, пользуясь каким-либо алгоритмом, обеспечивающим перебор элементов таблицы, просматривать их в поисках свободного места для новой записи.
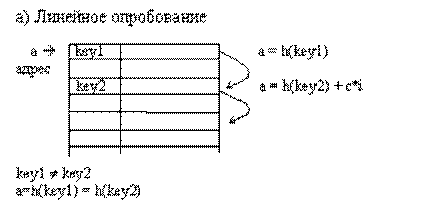
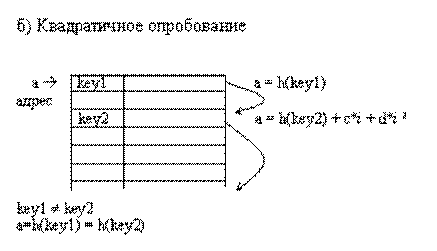

Рис.8.6. Разрешение коллизий при добавлении элементов методами открытой
адресации.
Линейное опробование сводится к последовательному перебору элементов таблицы с некоторым фиксированным шагом
a=h(key) + c* i,
где i номер попытки разрешить коллизию. При шаге равном единице происходит последовательный перебор всех элементов после текущего.
Квадратичное опробование отличается от линейного тем, что шаг перебора элементов не линейно зависит от номера попытки найти свободный элемент
a = h(key2) + c* i + d* i 2
Благодаря нелинейности такой адресации уменьшается число проб при большом числе ключей-синонимов.
Однако даже относительно небольшое число проб может быстро привести к выходу за адресное пространство небольшой таблицы вследствие квадратичной зависимости адреса от номера попытки.
Еще одна разновидность метода открытой адресации, которая называется двойным хешированием, основана на нелинейной адресации, достигаемой за счет суммирования значений основной и дополнительной хеш-функций
a=h1(key) + i *h2(key).