Технология прогнозирования временных рядов с сезонной составляющей
Введение
Управление деятельностью современного предприятия делает востребованным решение задач прогнозирования результатов экономической деятельности. Так, формирование бюджета в среднесрочной перспективе требует прогнозирования ряда экономических параметров, например, объёма продаж, на перспективу длительностью от года и выше. При этом требуется не просто определение годового объёма продаж, а его помесячная детализация.
Динамика экономических показателей, подлежащих прогнозированию, помимо общей тенденции, которую можно выразить трендом, как правило, содержит сезонную составляющую. И тренд, и сезонность являются системными компонентами временного ряда и обязательно должны быть отражены в прогнозе. Однако их разделение при анализе временного ряда является задачей, решение которой не представляется простым и очевидным [10].
Дискуссии, разворачивающиеся между аналитиками предприятий, являющихся непосредственными потребителями таких методов, показывают, что прогнозирование временных рядов с сезонной составляющей представляет для них реальную проблему. Это приводит к тому, что предлагаемые решения иногда носят откровенно дилетантский характер [8], справедливо вызывающий нарекания со стороны специалистов, попробовавших последовать предлагаемым рекомендациям [2, 5]. Далеко не всегда успешным является применение классических методов спектрального анализа [6]. Основной причиной этого является то, что тригонометрическими функциями можно хорошо аппроксимировать исходный ряд, но это не даёт возможности выявить тенденции. Для этой цели гораздо лучше подходят тренды, представляемые монотонными функциями [7]. Однако для самой процедуры выявления этих трендов чаще всего используется морально устаревший метод сглаживания [9]. Его основным недостатком является то, что процедурой усреднения можно элиминировать не только сезонность, но и повредить сам тренд. Кроме того, метод не предлагает никакого формального критерия, что полученный тренд является самым правильным решением.
В то же самое время существуют математические методы, позволяющие гарантированно выделить из временного ряда наилучший тренд. Поэтому в настоящий момент можно говорить о том, что наиболее актуальной является задача внедрения таких методов в практику и придания им такой степени технологичности, чтобы их использование перестало быть уделом избранных специалистов, а превратилось в рутинную процедуру. Это позволит решать не единичные задачи, а реализовывать развитую методику прогнозирования деятельности в нескольких аналитических разрезах одновременно.
Одним из таковых является метод, предложенный автором в [3]. Он имеет достаточно понятный «механизм» и легко может быть реализован в электронных таблицах. Его конструктивным недостатком является необходимость обращения к процедуре нахождения оптимального решения вспомогательной задачи посредством использования надстройки «Поиск решения». Это существенно препятствует превращению метода в технологию, обеспечивающую обработку потока задач. Гораздо более пригодным для этого оказался метод мнимых переменных. В [1] он представлен под названием «метод манекенов» и используется для решения задач, не связанных с анализом сезонных временных рядов. Поэтому в настоящей статье будет излагаться не столько сам математический аппарат, сколько способ реализации его в электронных таблицах, реализующий его технологическое воплощение.
Выделение тренда и сезонности
Рассмотрим исходный временной ряд y длительности k, состоящий из помесячных последовательных значений, в виде суммы следующих составляющих:
 , (1)
, (1)
где  – тренд,
– тренд,  – сезонность, ε – остаточная компонента. Под трендом
– сезонность, ε – остаточная компонента. Под трендом
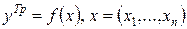 (2)
(2)
понимается монотонная (случай  ) или кусочно монотонная (случай
) или кусочно монотонная (случай  ) компонента. Под сезонностью – строго периодическая кусочно линейная компонента вида:
) компонента. Под сезонностью – строго периодическая кусочно линейная компонента вида:
 , (3)
, (3)
для которой  , из чего следует, что в наиболее простом представлении строки матрицы Z заполнены нулями, кроме единственной компоненты, соответствующей нужному месяцу, имеющей значение 1.
, из чего следует, что в наиболее простом представлении строки матрицы Z заполнены нулями, кроме единственной компоненты, соответствующей нужному месяцу, имеющей значение 1.
Для определённости в качестве объекта исследования взят временной ряд, представляющий собой динамику продаж товарной линейки корпусной мебели фирмы, занимающейся розничной реализацией этой продукции. Источником данных является ежемесячная отчётность о продажах на протяжении 3-х лет, формируемая корпоративной информационной системой. На рис. 1 исходный ряд имеет круглые маркеры. В нём явно присутствует сезонность с выраженным «низким» периодом в первом полугодии и ростом объёмов продаж во втором полугодии. Получается, что сезонный рост от января к декабрю неизбежно отразится в регрессии, построенной по исходному ряду, хотя к трендовому (среднегодовому) росту это не имеет отношения. Действительно, реальные годовые темпы роста по данным исходного ряда (см. табл. 1 внизу) составляют 11%+57%=68%. У линейной регрессии за те же периоды темпы составят 55%+35%=90%! Интуитивно понятно, что при том виде сезонности, которая имеет место в рассматриваемом примере, простая линейная регрессия по исходному ряду действительно должна иметь угол наклона больше, чем у тренда, т.е. реальной тенденции.
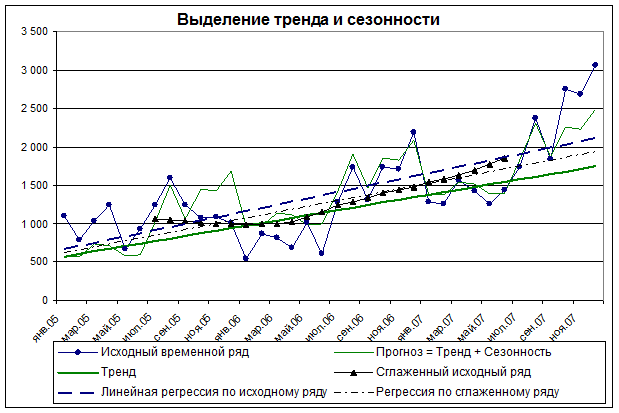 Рисунок 1. Выделение тренда и построение прогноза по исходному временному ряду.
Рисунок 1. Выделение тренда и построение прогноза по исходному временному ряду.
Процедуры предварительного сглаживания для такого ряда помогут построить более точный тренд. На рис. 1 видно, что регрессия по сглаженному ряду имеет меньший угол наклона, чем регрессия по исходному ряду. Однако нет никакой гарантии, что этот тренд будет наилучшим из всех возможных.
Для того чтобы регрессия соответствовала тренду годового роста, из исходного временного ряда предварительно должна быть удалена сезонность. Задачу эту, однако, решить не так просто, поскольку для выделения сезонности из временного ряда необходимо предварительно удалить тренд. Разорвать этот заколдованный круг можно, только решая задачи выделения тренда и сезонности одновременно. Для этого необходимо обратиться к регрессии вида:
 , (4)
, (4)
где Z – матрица мнимых переменных, так же, как и в (3), «отвечающих» за сезонность. Её отличительной особенностью является то, что она формирует сезонные отклонения только для 11 месяцев, а 12-й будет отображаться трендом.
Представленное уравнение регрессии может быть решено методом наименьших квадратов. Это очень известная и стандартизованная процедура. В MS Excel она реализована функцией ЛИНЕЙН. Само название функции и её описание в справочной системе вводит пользователя в заблуждение, будто она позволяет находить решение только для линейных регрессий. В действительности, задавая объясняющие переменные функцией соответствующего вида, ей можно получить все решения, доступные в интерфейсе «Добавить линию тренда», кроме скользящего среднего, поскольку оно не является регрессией.
Исходные данные, регрессионная модель и полученный с её помощью прогноз представлены в табл. 1. Рассмотрим её структуру в последовательности продвижения к полученному решению:
· Исходный ряд данных (столбец 2). Здесь он включает 3 года помесячно.
· Номер периода (столбец 20). Задаёт линейную функцию вида  при
при  Она используется как аргумент для функции объясняющих переменных
Она используется как аргумент для функции объясняющих переменных  в (4).
в (4).
· Объясняющие и мнимые Z переменные регрессии (столбцы 6-19). Здесь предполагается использование трёх объясняющих переменных, из которых пока задана только одна в виде линейной функции, поэтому столбец 6 повторяет столбец 20. Ячейки в этих столбцах, представленные здесь для повышения читабельности таблицы как пустые, при расчётах обязательно должны быть заполнены нулями.
· Решение регрессии расположено внизу в области столбцов 6-20, обведённой штрих-пунктирной границей. Оно получено вектор-функцией ЛИНЕЙН(ДИД;ДОМП;1;1), где «ДИД» – диапазон исходных данных (столбец 2 с периода 1 по 36), «ДОМП» – диапазон объясняющих и мнимых переменных (область столбцов 6-19, обведённая штриховой границей). Оба диапазона обязательно должны иметь одинаковое число строк. Назначение двух последних аргументов, а также как с помощью вектор-функции получить массив результатов, и что в нём представлено, можно узнать из справочной системы MS Excel. В данном случае этот массив состоит из четырёх строк, из которых требуемое решение регрессии, содержащее коэффициенты a и q, расположено в первой из них. По необъяснимой прихоти разработчиков коэффициенты располагаются в обратном порядке относительно переменных, поэтому двумя строками ниже области решения они ссылками переставлены в нужном порядке и подписаны. Кроме этого в первой ячейке третьей строки области результатов выводится такая важная характеристика, как коэффициент детерминации. Для пользователя он затем дублируется в области характеристик качества прогноза, расположенной самом низу таблицы. Расчёты необходимо производить в MS Excel версии 2003 и старше, поскольку в более ранних функция ЛИНЕЙН не умеет обрабатывать нулевые объясняющие переменные.
· Прогноз получается скалярным произведением коэффициентов на переменные  . В табл. 1 для строки, соответствующей июлю 2008 г. приведён пример использования для этого функции СУММПРОИЗВ.
. В табл. 1 для строки, соответствующей июлю 2008 г. приведён пример использования для этого функции СУММПРОИЗВ.
· Тренд получается точно таким же образом, но скалярным произведением только объясняющих переменных, т.е. области столбцов 6-8. Поскольку он требуется только для вывода на график, то начало тренда сдвинуто на январь месяц:  .
.
· Остаточная компонента 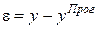 используется для оценки качества прогноза (расчёта среднеквадратического отклонения и коэффициента вариации) и поиска прочих системных составляющих, о чём речь пойдёт ниже.
используется для оценки качества прогноза (расчёта среднеквадратического отклонения и коэффициента вариации) и поиска прочих системных составляющих, о чём речь пойдёт ниже.