Вариант 1
Опишите три основные проблемы, послужившие появлению долгосрочных хранилищ данных.
Приложениям необходимо сохранять собственное состояние: во время работы процесс может хранить ограниченное количество данных в собственном адресном пространстве (ОЗУ), однако емкость такого хранилища ограничена размерами виртуального адресного пространства. Для некоторых приложений такого размера вполне достаточно, но для других, например учетных систем, одного только виртуального адресного пространства будет недостаточно. Кроме того, после завершения работы процесса информация, хранящаяся в его адресном пространстве, теряется. Для большинства приложений (например, баз данных) эта информация должна храниться достаточно долго. Исчезновение данных после завершения работы процесса для таких приложений неприемлемо. Информация должна сохраняться даже в случае аварийного завершения процесса в случае сбоя во всей системе. Третья проблема состоит в том, что часто возникает необходимость нескольким процессам одновременно получить доступ к одним и тем же данным (или части данных). Если интерактивный телефонный справочник будет храниться в адресном пространстве одного процесса, то доступ к нему будет только у этого процесса. Для решения этой проблемы необходимо отделить информацию от процесса.
Опишите общую идею и механизм функционирования файлов, отображаемых в память. Какие трудности применения вы знаете.
Способ отображения файлов на адресное пространство работающего процесса был предоставлен в некоторых ОС, начиная с MULTICS.
Для реализации отображения файлов на память изменяются системные внутренние таблицы. Отображение файлов на память лучше всего работает в ОС, поддерживающей сегментацию. В такой системе каждый файл может быть отображен на свой собственный сегмент, так чтобы байт файла был также байтом сегмента. Рассмотрим процесс с двумя сегментами, исполняемым кодом программы и данными. Предположим, что процесс копирует файлы. Сначала он отображает на сегмент исходный файл, например abc. Затем он создает пустой сегмент и отображает его на выходной файл, xyz.
После копирования выходной файл, xyz, теперь будет существовать на диске, как если бы он был создан обычным путем. Хотя отображение на память устраняет необходимость обращения к системным вызовам ввода-вывода, вместе с ним появляются новые проблемы. Во-первых, трудно определить длину выходного файла. Все, что может сделать ОС — это создать файл, длина которого равна размеру страницы. Вторая проблема может возникнуть при попытке одного процесса открыть файл, уже отображенный на адресное пространство другого процесса. Третья проблема, связанная с отображением файлов на память, вызвана тем, что файл может оказаться больше сегмента памяти и даже больше чем все виртуальное адресное пространство.
Опишите механизм поиска файла посредством хеш-таблиц, его достоинства и недостатки, который используется при реализации каталогов. Механизм кэширования результатов поиска.
Один из способов ускорить поиск файла состоит в использовании хэш-таблицы в каждом каталоге. Пусть размер такой таблицы будет равен n. При добавлении в каталог нового файла его имя должно хэшироваться в число от 0 до n 1. Исследуется элемент таблицы, соответствующий полученному хэш-коду. Если элемент не используется, туда помещается указатель на описатель файла. Если же элемент таблицы уже занят, то создается связный список, объединяющий все описатели файлов с одинаковым хэш-кодом. Поиск файла осуществляется аналогично: 1. Имя файла хэшируется. 2. По хэш-коду определяется элемент таблицы. 3. Затем проверяются все описатели файла из связного списка и сравниваются с искомым именем файла обычным способом. Если имени файла в связном списке нет, это означает, что файла нет в каталоге. Преимуществом использования хэш-таблицы является ускоренный в несколько раз поиск файла. Недостаток этого метода состоит в более сложном администрировании каталога.
Принципиально отличный способ ускорения процесса поиска файлов в больших каталогах заключается в кэшировании результатов поиска. Прежде чем начать поиск файла, проверяется, нет ли его имени в кэше. Если ФС недавно уже искала этот файл, его имя окажется в кэше и повторная операция поиска будет выполнена очень быстро. Конечно, кэширование поможет только в том случае, если ФСмного раз обращается к небольшому количеству файлов.
Какие существуют стратегии выделения дискового пространства под файлы. Укажите какие проблемы связаны с определением размера блока хранения файла, какие подходы к решению. Как зависит скорость чтения/записи данных с диска и эффективность использования дискового пространства от размера блока.
Для хранения файла из n байтов возможно использование двух стратегий: выделение на диске n последовательных байтов или разбиение файла на несколько непрерывных блоков.
При хранении файла в виде непрерывной последовательности байтов возникает проблема, связанная с увеличением его размеров. Единственный способ увеличить непрерывный файл состоит в перемещении его на новое место на диске. По этой причине почти все ФС хранят файлы в виде блоков фиксированного размера, расположенных в различных частях диска.
Как только принято решение хранить файлы блоками фиксированного размера, возникает вопрос о размере этих блоков. Роль сегмента могут выполнять: сектор, дорожка и цилиндр диска. В системе управления страницами памяти это также размер страницы. Если выбрать большую единицу хранения, такую как цилиндр, это будет означать, что любой файл, даже состоящий из одного байта, займет как минимум целый цилиндр.
С другой стороны, при использовании маленьких единиц хранения каждый файл будет состоять из большого числа блоков.
Скорость чтения/записи данных растет пропорционально размеру блока до тех пор, пока блок не вырастет настолько, что важнее окажется время передачи блока.
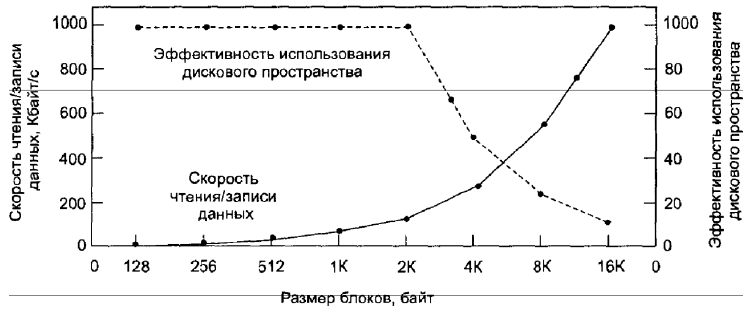
Рис. 14. Зависимость скорости чтения/записи данных диска (жирная линия, левая шкала) и эффективности использования дискового пространства (штриховая линия, правая шкала) от размера блоков.
Что такое NUMA-мультипроцессоры? Укажите основную идею и ключевые характеристики. Какие основные преимущества перед UMA-системами. Системы с когерентным (CC-NUMA) и некогерентным (NU-NUMA) кешем. Опишите каталоговый мультипроцессор в CC-NUMA, каковы его достоинства и недостатки.
Как и UMA, мультипроцессоры NUMA (NonUniform Memory Access — неоднородный доступ к памяти) предоставляют единое адресное пространство для всех CPU, но в отличие от UMA-машин доступ к локальной памяти у них быстрее, чем к удаленным модулям. Таким образом, все программы, написанные для UMA, будут работать и на мультипроцессорах NUMA, но их производительность будет ниже, чем на машинах UMА при той же тактовой частоте CPU. Ключевые характеристики: 1. Для всех нейтральных CPU имеется единое адресное пространство. 2. Доступ к удаленным модулям памяти осуществляется при помощи специальных команд CPU. 3. Доступ к удаленным модулям памяти медленнее, чем к локальной памяти. В том случае, если доступ к удаленной памяти не является скрытым (то есть кэширование не применяется), система называется NC-NUMA (No Caching NUMА — система NUMA без кэширования). При наличии когерентных кэш-модулей система называется CC-NUMA (Cache-Coherent NUMA — система NUMA с когерентным кэшированием).
Каталоговый мультипроцессор - поддержание БД, в которой содержится информация о том, где располагается каждая строка кэша и ее состояние. При обращении к строке кэша БД получает запрос на поиск этой строки и выдает ее состояние («чистая» или «грязная»). Поскольку запросы этой БД направляются на каждой команде CPU, обращающейся к памяти, эта база должна храниться в крайне быстром специальном аппаратном устройстве, способном выдавать ответ за долю цикла шины.
Опишите подход функционирования ОС на каждом CPU - метод персональной копии. Дайте графическую интерпретацию и основные замечания. В чем состоят достоинства и недостатки.
Простейший способ организации мультипроцессорных ОС состоит в том, чтобы статически разделить ОЗУ по числу CPU и дать каждому CPU свою собственную память с собственной копией ОС. В результате n CPU будут работать как n независимых компьютеров. В качестве очевидного варианта оптимизации можно позволить всем CPU совместно использовать код ОС и хранить только индивидуальные копии данных, рис. 7. Квадратики, помеченные словом Data, означают персональные данные ОС для каждого CPU.

Такая схема лучше, чем n независимых компьютеров, так как она позволяет всем машинам совместно использовать набор дисков и других устройств ввода-вывода, а также обеспечивает гибкое совместное использование памяти. Но с точки зрения ОС наличие ОС у каждого CPU является крайне примитивным подходом.
Следует отметить четыре аспекта данной схемы, возможно, не являющихся очевидными:
1. Когда процесс обращается к системному вызову (СВ), СВ перехватывается и обрабатывается его собственным CPU при помощи структур данных в таблицах ОС.
2. Поскольку у каждой ОС есть свои собственные таблицы, у нее есть также и свой набор процессов, которые она сама планирует. Совместного использования процессов нет.
3. Совместного использования страниц также нет.
4. Если ОС поддерживает буферный кэш недавно использованных дисковых блоков, то каждая ОС будет выполнять это независимо от остальных. Таким образом, может случиться так, что некоторый блок диска будет присутствовать в нескольких буферах одновременно, причем в нескольких буферах сразу он может оказаться модифицированным, что приведет к порче данных на диске. Единственный способ избежать этого заключается в полном отказе от блочного кэша, что значительно снизит производительность всей системы.
7. Опишите подход к планированию в мультипроцессорах посредством разделения времени. В чем суть единой структуры данных для планирования, каковы достоинства и недостатки. В чем суть механизма умного планирования, приоритетного планирования, родственного планирования, двухуровневого планирования.
Рассмотрим сначала случай планирования независимых процессов. Затем обсудим, как планировать зависимые процессы. Простейший алгоритм планирования независимых процессов (или потоков) состоит в поддержании единой структуры данных для готовых процессов, возможно, просто списка, но скорее всего множества списков для процессов с различными приоритетами. Наличие единой структуры данных планирования, используемой всеми CPU, обеспечивает CPU режим разделения времени подобно тому, как это выполняется на однопроцессорной системе. Кроме того, такая организация позволяет автоматически балансировать нагрузку, то есть она исключает ситуацию, при которой один CPU простаивает, в то время как другие CPU перегружены.
Два недостатка такой схемы представляют собой: потенциальный рост конкуренции за структуру данных планирования по мере увеличения числа CPU; обычные накладные расходы на выполнение переключения контекста, когда процесс блокируется, ожидая выполнения операции ввода-вывода. Переключение контекста также может случиться, когда истекает квант процесса.
При умное планировании процесс, захватывающий спин-блокировку, устанавливает флаг, демонстрирующий, что он в данный момент обладает спин-блокировкой. Когда процесс освобождает блокировку, он также очищает и флаг. Таким образом, планировщик не останавливает процесс, удерживающий спин-блокировку, а, напротив, дает ему еще немного времени, чтобы тот завершил выполнение критической области и отпустил мьютекс.
Идея механизма «родственное планирование» заключается в приложении серьезных усилий для того, чтобы процесс был запущен на том же CPU, что и в прошлый раз, поскольку это увеличит скорость выполнения процесса Один из способов реализации этого метода состоит в использовании двухуровневого алгоритма планирования. В момент создания процесс назначается конкретному CPU, например наименее загруженному в данный момент. Это назначение процессов CPU представляет собой верхний уровень алгоритма. В результате каждый CPU получает свой набор процессов. Действительное планирование процессов находится на нижнем уровне алгоритма. Оно выполняется отдельно каждым CPU при помощи приоритетов или других средств. Двухуровневое планирование обладает тремя преимуществами: 1. Оно довольно равномерно распределяет нагрузку среди имеющихся CPU. 2. Двухуровневое планирование по возможности использует преимущество родственности кэша. 3. Поскольку у каждого CPU при таком варианте планирования есть свой собственный список свободных процессов, конкуренция за списки свободных процессов минимизируется, так как попытки использования списка другого CPU происходят относительно нечасто.
Механизм межмашинного взаимодействия на основе механизма обмена сообщениями.