Пространственно-векторная модель позволяет получить результат, хорошо согласующийся с запросом. Причем документ может оказаться полезным, даже не имея 100% соответствия. В найденном документе может вовсе не оказаться одного или нескольких слов запроса, но при этом его смысл будет запросу соответствовать. Как достигается такой результат?
Все документы базы данных размещаются в воображаемом пространстве (это может быть многомерное пространство, представить которое весьма трудно). Координаты каждого документа зависят от структуры терминов, в нем содержащихся (от весовых коэффициентов, положения внутри документа, от расстояния между терминами и т.п). В результате окажется, что документы с похожим набором терминов разместятся в пространстве ближе друг к другу [рис. 4].
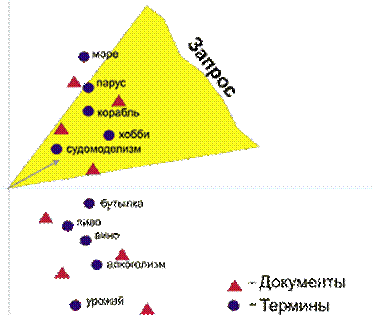
Предположим, мы хотим найти документы, касающиеся постройки моделей кораблей в бутылках. Составим запрос, например, такой: корабли в бутылках. Получив его, поисковая система удалит лишние слова, выделит термины и вычислит вектор запроса в пространстве документов (стрелочка на рисунке). Установив некоторый диапазон соответствия, система выдаст документы, попавшие в заштрихованную область на рисунке 4. Эта область непременно захватит документы, повествующие о необычных увлечениях -- хобби, классическом судомоделизме и т.п. В них может вовсе не оказаться некоторых слов запроса, однако документы останутся достаточно релевантными. Термины, относящиеся к вину, будут группироваться в другой точке пространства, и запрос их не затронет. Как видите, "уравниловку" терминов удалось преодолеть. В пространственно-векторной модели термины взаимодействуют друг с другом, что повышает релевантность документов. Понятно, что пространственно-векторная модель лучше воспринимает запросы, составленные на естественном языке, чем матричная.
К сожалению, догадаться, по какой схеме работает та или иная поисковая система Интернета, очень трудно. Как правило, создатели держат ее в секрете. Мы в простой форме изложили лишь основы работы поисковой системы. В реальности механизм индексации и структура базы данных значительно сложнее. Однако полученных знаний уже достаточно, чтобы попытаться выработать оптимальную стратегию поиска информации в сети Интернет.
Стратегия поиска
Итак, мы знаем, как система выделяет ключевые слова. Воспользуемся этим знанием, чтобы сформировать оптимальный запрос. Прежде всего оговорим некоторые исходные предпосылки. Допустим, мы имеем некий текст-источник и хотим найти в сети Интернет документы схожего содержания. Откуда возьмется текст-источник? Поскольку сама задача поиска не могла возникнуть из ничего, где-то непременно должна существовать информация, возбудившая интерес к проблеме. Может быть, это журнальная статья, книга, веб-страница и т.п. Именно эту информацию и нужно упорядочить и привести в форму, удобную для анализа. Если задача существует только у вас в голове, попробуйте написать небольшое сочинение, изложив свое видение проблемы, -- оно и станет текстом-источником. Если бы нам удалось препарировать текст-источник так же, как это делает поисковая машина, по идее, мы могли бы получить результаты с максимально высокой релевантностью. Попробуем. Возьмем текст-источник и проанализируем его. Для автоматизации процесса можно заглянуть на интерактивную страничку www.shipbottle.ru/ir/, где функционирует с грехом пополам сооруженный автором апплет, или воспользоваться небольшой программкой MTAS (mtasprog.exe) (www.sas.upenn.edu/~bkat/dwnld.htm). (Внимательно прочтите инструкцию: для обработки русского текста придется написать небольшой файл-алфавит.) Если текст-источник -- файл на диске вашего компьютера, укажите программе путь к нему -- она сама вычислит все необходимые параметры. В противном случае, например, когда текст-источник -- страница в журнале, анализ придется сделать вручную.
Последовательность действий такова:
1. Подбираем текст-источник. Чем четче описание проблемы в тексте-источнике, тем качественнее и точнее окажется результат. Размытый и путаный текст-источник выудит из поисковой системы столь же бестолковые документы.
2. Удаляем из текста стоп-слова (их можно просто вычеркивать).
3. Вычисляем частоту вхождения каждого термина. Причем делаем это без учета морфологии слов. Так, слова ship и ships будут разными терминами. Не нужно учитывать и регистр, все буквы считаем строчными.
4. Выписываем на отдельный лист термины в порядке убывания их частоты вхождения (первыми должны идти те, которые встречаются чаще).
5. Выбираем диапазон частот. Он должен лежать где-нибудь посередине. Не нужно брать слишком часто или, наоборот, слишком редко встречающиеся термины. Выбор диапазона субъективен. Вам следует ориентироваться на конкретный смысл текста. Необходимость выбирать диапазон вручную не должна смущать, ведь теперь вы выбираете термины не из текста, а из построенного по определенному закону упорядоченного списка.
6. Из выбранного диапазона выписываем термины. В большом тексте в диапазоне может оказаться довольно много слов. Все их применить вряд ли удастся. Достаточно взять 10-20 терминов. Их следует выбирать, руководствуясь, в первую очередь, здравым смыслом. Причем не стоит ограничиваться только характерными терминами, даже если они кажутся наиболее удачными. В список должны попасть и общие слова (их лучше выбирать из средней части диапазона).
7. Составляем запрос, располагая отобранные слова в порядке их следования в списке терминов. Запрос должен пониматься машиной как слова, связанные логическим оператором ИЛИ. Это очень важное требование. Чтобы результат не исказился, следует изучить особенности синтаксиса запросов конкретной поисковой системы.
8. Отправляем запрос поисковой системе.
В ответ вы можете получить несколько миллионов ссылок. Но не пугайтесь. Если поисковая машина ранжирует результаты (а это еще одно необходимое условие), на первых страницах окажутся практически стопроцентно релевантные документы. Самое любопытное, что документ -- источник запроса (если его аналог существует в Интернете) вовсе не обязательно будет возглавлять список. Он может оказаться и на задворках.