РАЗДЕЛ 4. ПРОГНОЗИРОВАНИЕ ВРЕМЕНИ ВЫПОЛНЕНИЯ ПРОГРАММ
Статический и динамический анализ программ
Уровни и этапы анализа. Получение адекватных оценок времени выполнения программ или их выделенных фрагментов важно для эффективного распараллеливания, планирования вычислительных процессов и распределения ресурсов масштабируемых систем, а также для оптимизации программ. Довольно часто временные характеристики программы исследуются на инструментальной системе, а затем делается прогноз динамики программы на целевой вычислительной платформе. Как правило, инструментальные средства для такого рода анализа представляют собой сложные программные комплексы, позволяющие выявлять узкие места в работе пользовательских программ и добиваться ускорения их выполнения за счет оптимизации, в том числе и путем структурных преобразований программ. Арсенал таких средств включает в себя оптимизирующие компиляторы, профилировщики, отладчики и т. п. В основе их создания и применения лежат различные методы.
В этом подразделе мы рассмотрим суть так называемого статико-динамического анализа, предполагающего двухуровневое исследование программы – на языке высокого уровня и в коде ассемблера целевого процессора (рис. 4.1). Статико-динамический анализ включает в себя фрагментацию программы; однократный статический анализ выделенных фрагментов с учетом архитектуры целевого процессора; использование результатов, полученных в статике, в процессе прогона программы путем подсчета числа исполнений соответствующего фрагмента.
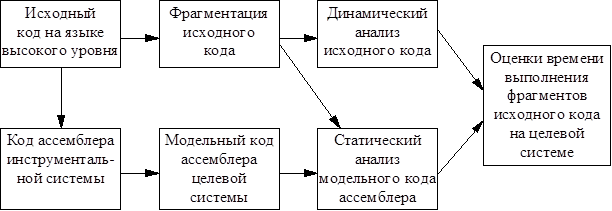
Рис. 4.1. Общая схема статико-динамического анализа программ
Динамический анализ, т.е. исследование фрагментированных программ в реальных прогонах, выполняется на языке высокого уровня. Для этого может быть использован метод частотных счетчиков. Основная идея этого метода состоит в том, что в программу вводятся средства для подсчета числа и, если требуется, для запоминания последовательности выполнений (профилирования) выделенных фрагментов программы. Пусть, например, необходимо, построить профиль прогона программы для вычисления 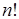 и подсчитать, сколько раз выполняется каждая из строк кода на языке С:
и подсчитать, сколько раз выполняется каждая из строк кода на языке С:
1 static unsigned long fact (unsigned long n) {
2 if (n > 1) {
3 return n * fact(n - 1);
4 } else {
5 return 1;
6 }
7 }
Положим, 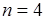 . Профиль программы в данном случае может быть представлен ее операционной историей (рис. 4.2, а) и содержимым частотных счетчиков – переменных, значения, которых накапливают число выполнений соответствующих строк (рис. 4.2, б).
. Профиль программы в данном случае может быть представлен ее операционной историей (рис. 4.2, а) и содержимым частотных счетчиков – переменных, значения, которых накапливают число выполнений соответствующих строк (рис. 4.2, б).
·®·®·®·®·®·®·®·®·®·®·®·®·®·®·®·®·
1 2 3 7 1 2 3 7 1 2 3 7 1 4 5 6 7
а)
Строка Число выполнений строки
1 4
2 3
3 3
4 1
5 1
6 1
7 4
б)
Рис. 4.2. Профилирование программы вычисления ()
Для реализации метода частотных счетчиков в программу, записанную на языке высокого уровня, как правило, вводятся средства на том же языке. Эти средства можно разделить на три типа:
– операторы присваивания, инкрементирующие соответствующий счетчик при каждом выполнении того или иного фрагмента;
– операторы вывода данных о выполнении исследуемых частей программы;
– операторы обращения к специальным измерительным программам или подпрограммам, например, профилировщикам и анализаторам.
При этом введение в исходный текст программы операторов присваивания для подсчета числа выполнений интересующих пользователя фрагментов сопровождается весьма незначительными накладными расходами, связанными с дополнительной нагрузкой на вычислительные ресурсы. Операторы вывода и вызова измерительных программ или подпрограмм позволяют визуализировать и обобщить результаты профилирования: построить трассу выполнения исследуемой программы, различного рода диаграммы и т.п. Рассмотренный выше пример с вычислением (см. рис. 4.2) довольно тривиален. Практика же требует, как правило, сложных программных систем для профилирования прикладных программ. При этом структура исследуемого приложения, как правило, представляется различного рода графами. Здесь можно упомянуть профилировщик GNU gprof, использующий граф вызова функций.
Помимо использования метода частотных счетчиков, динамический анализ может быть осуществлен посредством прерываний выполнения или интерпретации объектной программы. В первом случае выполнение программы прерывается через выбранные некоторым образом интервалы времени, запоминается адрес прерывания, а иногда и связанная с ним контекстная информация. Эта идея очень часто закладывается в основу различных средств профилирования. В другом случае, измерительные интерпретаторы позволяют выявить и подсчитать используемые команды, операнды и т.д. Измерения, основанные на прерываниях и интерпретации, в отличие от метода частотных счетчиков, практически всегда вызывают замедление работы исследуемой программы.
Цель статического анализа – получение времени однократного исполнения фрагмента на целевом процессоре. Учесть особенности его архитектуры команд, а также избыточность, вносимую штатными компиляторами на этапах получения объектного и исполняемого кодов после компоновки, можно лишь на уровне языка ассемблера.
Когда речь идет об избыточности, то здесь констатируется известный факт, заключающийся в том, что без некоторой дополнительной информации штатный компилятор вычислительной системы скорее всего не сможет обеспечить эффективной реализации прикладной программы. Известно также, что зачастую оптимизация программы вручную на языке ассемблера позволяет значительно ускорить ее выполнение. Кроме этого, существует взаимно однозначное соответствие между операторами языка ассемблера и машинными командами, что, безусловно, важно для получения адекватных оценок времени исполнения машинного кода. Однако необходимо учитывать и то, что исходный код на языке высокого уровня сначала компилируется в код ассемблера инструментального процессора (см. рис. 4.1). Временные оценки же необходимо получать для конкретного компилятора и языка ассемблера целевого процессора. Этим объясняется необходимость моделирования процесса компиляции, ассемблирования и функционирования процессоров целевой вычислительной системы. В этом и состоит основная трудность реализации статического анализа фрагментов программы. Современные компиляторы поддерживают развитые механизмы оптимизации кода, например, выделение и исключение общих подвыражений, продвижение констант, распределение регистров. Кроме этого, и компиляторы, и ассемблеры отдельно транслируют каждую единицу исходного кода. Так, сначала создаются объектные модули (в операционных системах Windows и UNIX они имеют расширения.obj и.о соответственно), а после компоновки получается исполняемый двоичный код (в Windows ему соответствует расширение.exe, в UNIX расширения нет). Все это может привести к тому, что моделирование компиляции отдельных фрагментов кода станет неадекватным реальному процессу компиляции всей программы. Конечно же, задача упрощается при наличии кросс-компилятора для целевой системы, который далеко не всегда доступен.
Код, получаемый в результате отображения языка ассемблера инструментального процессора на язык ассемблера целевого процессора, будем называть модельным кодом. Последующий его анализ (см. рис. 4.1) представляет собой, по сути, моделирование работы целевого процессора – организации конвейера команд, кэш-памяти и т.д. Сложность такого рода моделирования объясняется высокой степенью внутреннего параллелизма современных процессоров с сокращенным набором команд (RISC – Reduced Instruction Set Computer) и процессоров со сверхдлинным командным словом (VLIW – Very Long Instruction Word). Правда, это вовсе не означает, что моделировать работу процессоров Pentium или Celeron с 32-разрядной архитектурой команд IA-32 намного проще. Это – машины с полным набором команд (CISC – Complete Instruction Set Computer), хотя хорошо известно, что их ядро реализует сильно конвейеризованную систему RISC. CISC-команды архитектуры IA-32 внутри ядра разбиваются на операции RISC.
Далее мы еще вернемся к влиянию различий и особенностей архитектуры команд процессоров на адекватность анализа времени выполнения программ. Сейчас же попытаемся оценить еще один вариант проведения статического анализа. Это – эмуляция системы команд целевого процессора, позволяющая получить динамические характеристики программы на уровне языка ассемблера с высокой точностью. Однако эмуляция требует значительных временных затрат и, естественно, доступности эмулятора. Кроме того, использование эмуляции как метода имитационного моделирования работы процессоров целесообразно тогда, когда необходимо получать гарантированные оценки времени выполнения программ или их критических участков, в частности, в системах реального времени. Однако вряд ли оправданным является использование этого подхода для прогнозирования динамики сложных комплексов программ в масштабируемых вычислительных системах.
Итак, прибегать к статико-динамическому анализу целесообразно, когда недоступна целевая платформа или же осуществляется ее выбор. Основное достоинство статико-динамического анализа – гораздо более высокое быстродействие по сравнению с эмуляцией и практически та же точность оценок. Недостатки – необходимость детального моделирования процесса компиляции, аппаратуры и наличия подробнейшего описания архитектурных решений, чаще всего недоступного в условиях жесточайшей конкуренции между производителями современных процессоров. Здесь, в частности, можно сослаться на практику компании Intel, скрывающей организацию RISC-ядра в процессорах Pentium. Кроме того, однократный статический анализ не позволяет учесть зависимость динамики программы от вида исходных данных. Теперь подробнее рассмотрим, какие факторы влияют на степень соответствия кода целевого ассемблера и модельного кода.
Погрешность оценок модельного кода. Степень адекватности модельного кода коду ассемблера целевого процессора определяется долей неотображаемых операций в коде инструментальной системы. Для отображаемых операций существуют некоторые методы или эвристики получения и сопоставления временных оценок фрагментов кода целевого и инструментального процессоров. Для неотображаемых операций таких приемов нет. Причины могут быть обусловлены разными архитектурами команд и особенностями соответствующих компиляторов.
(Исторический экскурс в архитектурные различия процессоров. Архитектуры команд различных процессоров могут иметь весьма существенные различия. В качестве примера сравним две из них – IA-32 и Version 9 SPARC. Первая реализуется в таких процессорах фирмы Intel, как 8086, 8088, Pentium, Celeron и др. Вторая архитектура используется в процессорах SPARC. Набор команд IA-32 характерен для CISC-процессоров, хотя, как уже отмечалось, начиная с семейства процессоров Pentium, внутри ядра команды CISC разбиваются на операции RISC. А это все оборачивается дополнительными аппаратными затратами и, в конечном итоге, увеличением площади кристалла. Архитектура IA-32 поддерживает двухадресные команды и небольшой файл регистров. CISC-команды имеют разную длину, большое количество различных форматов и, следовательно, их сложно декодировать. Способы адресации весьма нерегулярны. Архитектура Version 9 SPARC – это набор команд для 64-разрядных RISC-процессоров, в частности, UltraSPARC II. Набор RISC-команд довольно компактен, реализуется всего два способа адресации, преобладают трехрегистровые операции, поддерживается большой файл регистров (в процессоре UltraSPARC II имеется 32 регистра общего назначения и 32 регистра с плавающей точкой). Все команды имеют фиксированную длину, по сравнению с CISC-командами и их проще декодировать "на лету".
Безусловно, принципиально новый качественный уровень – это архитектура IA-64, реализованная в RISC-процессорах Itanium. Это архитектура типа "загрузка/сохранение" с 64-разрядными регистрами и адресами. Непосредственно к памяти обращаются лишь команды загрузки и сохранения. Операнды для остальных команд хранятся только в регистрах либо содержатся в самих командах. Для программ IA-64 доступны 64 регистра общего назначения и дополнительные регистры для программ IA-32. Принципиальным отличием от других архитектур RISC-команд является концепция связанных команд. В 128-битовой связке (bundle) содержится по три 41-битовых команды и 5-битовый шаблон, с помощью которого могут образовываться группы из связок команд. Шаблон указывает, какие команды в связке и группах связок могут выполняться параллельно. При этом основная работа по выявлению таких команд и их переупорядочиванию возлагается на компилятор. По сути, архитектура IA-64 позволяет реализовать новую вычислительную парадигму, которая получила название Explicitly Parallel Instruction Computing (EPIC), что означает явный параллелизм в обработке команд. Парадигма EPIC строится на опыте, полученном из разработок RISC- и VLIW-компьютеров. Так, подобно VLIW-компьютерам, архитектура IA-64 группирует команды, которые могут выполняться параллельно, в связки. То, что при этом каждая команда относительно проста и имеет фиксированную длину, характерно для RISC-процессоров. Следующая отличительная особенность архитектуры IA-64 – это наличие в команде поля предикации, которое указывает, какой из 64 однобитных регистров предиката определяет, нужно ли выполнять соответствующую инструкцию. Это позволяет реализовать новый способ организации условных переходов и от многих их них избавиться: выполнение каждой команды условно, хотя при этом команда действительно выполняется. Однако, когда приходит время загрузки в выходной регистр, то проверяется истинность предиката. Если его значение истинно, то запись в выходной регистр производится, если значение ложно, то нет. Наконец, третья, характерная для архитектуры IA-64 особенность, это – спекулятивная загрузка, позволяющая выполнять вызовы операндов заранее, до того как они потребуются. Если же операнд не нужен, то команда загрузки просто объявляет регистр, с которым она связана, недействительным. В традиционных архитектурах команд такая ситуация невозможна и вызывает так называемое исключение (exception). Спекулятивная загрузка преодолевает негативное влияние эффекта "узкого горлышка", возникающего при обмене процессора с памятью и замедляющего выполнение программ. )
Вышеприведенное отступление от основной линии изложения нам понадобилось для того, чтобы вкратце рассказать об источниках погрешности при получении модельного кода в инструментальной системе. Теперь посмотрим, как эту погрешность оценить и на какие параметры кода целевой системы она влияет.
Пусть 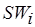 – код линейного участка (фрагмента) программы, а
– код линейного участка (фрагмента) программы, а 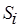 – длина кода в некоторых приведенных операциях, исполнение каждой из которых требует одного цикла инструментального процессора. Внутри фрагмента могут быть и циклы, и условные ветвления. Далее будем называть сложностью фрагмента , который в общем случае является мультимножеством, т.е. может содержать одинаковые операции. При этом
– длина кода в некоторых приведенных операциях, исполнение каждой из которых требует одного цикла инструментального процессора. Внутри фрагмента могут быть и циклы, и условные ветвления. Далее будем называть сложностью фрагмента , который в общем случае является мультимножеством, т.е. может содержать одинаковые операции. При этом 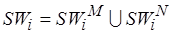 ,
,  , где
, где  – множество некоторых базовых операций, отображаемых на множество
– множество некоторых базовых операций, отображаемых на множество 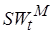 операций целевого процессора, а
операций целевого процессора, а 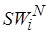 – множество неотображаемых операций инструментального процессора. Под базовыми понимаются операции, выполняющие большую часть вычислений в исследуемой прикладной программе. Для отображаемых операций определена некоторая функция
– множество неотображаемых операций инструментального процессора. Под базовыми понимаются операции, выполняющие большую часть вычислений в исследуемой прикладной программе. Для отображаемых операций определена некоторая функция  . Под
. Под 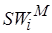 понимается совокупность базовых операций, для которых существуют правила и приемы оценки сложности
понимается совокупность базовых операций, для которых существуют правила и приемы оценки сложности 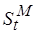 кода
кода 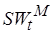 на основе знания сложности
на основе знания сложности 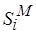 кода . С другой стороны, для операций множества
кода . С другой стороны, для операций множества 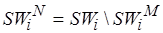 правила перехода к соответствующему коду
правила перехода к соответствующему коду  целевого процессора неизвестны и, следовательно, неизвестна сложность
целевого процессора неизвестны и, следовательно, неизвестна сложность  этого кода. Операции множества
этого кода. Операции множества 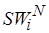 могут не иметь прямых аналогов на множестве базовых операций целевого процессора. Кроме того, операции из могут принадлежать неисполняемым фрагментам кода при реальном прогоне программы на инструментальной системе и поэтому неизвестно время исполнения операций из . Базовые операции целевого процессора, как правило, входят в множество
могут не иметь прямых аналогов на множестве базовых операций целевого процессора. Кроме того, операции из могут принадлежать неисполняемым фрагментам кода при реальном прогоне программы на инструментальной системе и поэтому неизвестно время исполнения операций из . Базовые операции целевого процессора, как правило, входят в множество 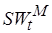 . Опять-таки полагаем, что
. Опять-таки полагаем, что  , через
, через 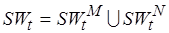 обозначим модельный код фрагмента (также мультимножество операций) для целевого процессора. Пусть
обозначим модельный код фрагмента (также мультимножество операций) для целевого процессора. Пусть 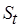 – его сложность. Таким образом,
– его сложность. Таким образом,  ,
,  . Поскольку коды ,
. Поскольку коды , 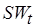 могут содержать и одинаковые операции, то при подсчете
могут содержать и одинаковые операции, то при подсчете 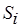 ,
, 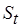 учитываются все экземпляры операций.
учитываются все экземпляры операций.
Предположим, коэффициент 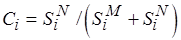 , равный доле неотображаемых операций в коде инструментального процессора, известен. В то же время для целевого процессора аналогичный коэффициент
, равный доле неотображаемых операций в коде инструментального процессора, известен. В то же время для целевого процессора аналогичный коэффициент  является неизвестным. При этом будем считать, что доля неотображаемых операций для целевого процессора удовлетворяет ограничению
является неизвестным. При этом будем считать, что доля неотображаемых операций для целевого процессора удовлетворяет ограничению
 . (4.1)
. (4.1)
Дальнейшее изложение можно было бы построить, исходя из ограничения на отношение 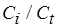 . По сути, это ничего не меняет. Главное то, что здесь
. По сути, это ничего не меняет. Главное то, что здесь 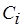 полагается известным, а
полагается известным, а  – нет. Сложность
– нет. Сложность  будем оценивать средним значением
будем оценивать средним значением 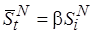 с помощью некоторого коэффициента
с помощью некоторого коэффициента 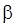 . О том, как он выбирается, речь пойдет ниже.
. О том, как он выбирается, речь пойдет ниже.
Необходимо ответить на следующие вопросы. Какова погрешность оценки сложности 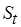 и, соответственно, времени исполнения линейного участка
и, соответственно, времени исполнения линейного участка  ? Каково минимально возможное значение сложности ? Это своего рода контрольная граница, показывающая насколько программа целевой вычислительной системы приближается к оптимальной.
? Каково минимально возможное значение сложности ? Это своего рода контрольная граница, показывающая насколько программа целевой вычислительной системы приближается к оптимальной.
Относительная погрешность оценки составляет
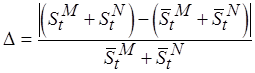 ,
,
где 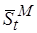 – среднее значение сложности кода (здесь
– среднее значение сложности кода (здесь  выражается в долях единицы, а не в % как это часто принято).
выражается в долях единицы, а не в % как это часто принято).
Будем полагать, 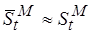 и считать, что погрешность обуславливается, главным образом, усредненной оценкой сложности кода :
и считать, что погрешность обуславливается, главным образом, усредненной оценкой сложности кода :
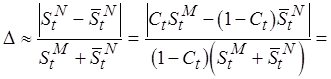 (4.2)
(4.2)
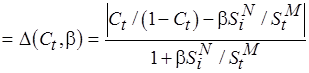 ,
,
где 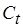 удовлетворяет (4.1).
удовлетворяет (4.1).
Поскольку – некоторым образом выбираемый коэффициент, а коэффициент неизвестен, то нас интересуют, во-первых, погрешность вида
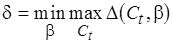 (4.3)
(4.3)
и, во-вторых, минимальная сложность кода для целевого процессора, оцениваемая с погрешностью 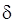
 . (4.4)
. (4.4)
Минимальное значение сложности (4.4) кода целевого процессора, оцениваемое с погрешностью (4.3), равной нулю, будем называть оптимальным.
Рассмотрим два случая для (4.2):
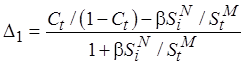 , где
, где 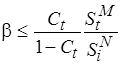 ;
;
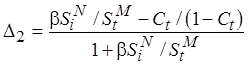 , где
, где 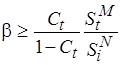 .
.
При этом, напомним, коэффициент удовлетворяет неравенству (4.1).
Функция 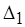 является монотонно возрастающей для
является монотонно возрастающей для 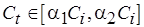 . Поэтому, полагая
. Поэтому, полагая 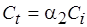 и согласно (4.3) считая
и согласно (4.3) считая 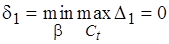 , получаем
, получаем
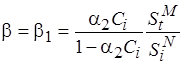 . (4.5)
. (4.5)
Функция 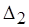 монотонно убывает для . Полагая
монотонно убывает для . Полагая 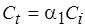 и
и 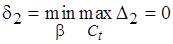 , получаем, что
, получаем, что
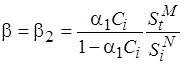 . (4.6)
. (4.6)
При этом с учетом (4.1)
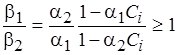 .
.
Тогда, если  , то оптимальное значение сложности (4.4) кода целевого процессора равно
, то оптимальное значение сложности (4.4) кода целевого процессора равно
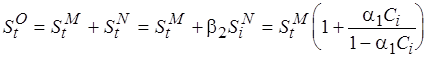 .
.
Таким образом, оптимальная сложность фрагмента кода для целевого процессора тем меньше, чем меньше доля неотображаемых операций в сложности кода инструментальной системы, чем меньше нижняя граница 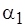 отношения
отношения  и, естественно, чем меньше сложность кода .
и, естественно, чем меньше сложность кода .
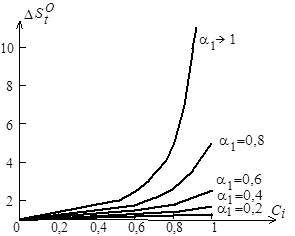
Рис. 4.3.Границы относительного прироста оптимальной сложности модельного кода
На рис. 4.3 приведены зависимости относительного прироста 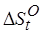 оптимальной сложности, когда сложность отображенного кода для целевого процессора условно принимается равной единице.
оптимальной сложности, когда сложность отображенного кода для целевого процессора условно принимается равной единице.
Теперь рассмотрим вопрос о том, как связаны погрешность оценки модельного кода и некоторые параметры фрагментов кода инструментального и целевого процессоров. Если 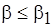 в (4.5), то относительная погрешность составляет
в (4.5), то относительная погрешность составляет 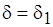 , если же
, если же  в (4.6), то
в (4.6), то 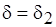 в (4.3). Минимальная сложность (4.4) определяется с погрешностью
в (4.3). Минимальная сложность (4.4) определяется с погрешностью 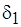 или
или 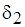 . Положим, необходимо выбрать коэффициент , с помощью которого определяется сложность кода с неотображенными операциями, так, чтобы относительная погрешность оценки сложности модельного кода не превышала некоторого заданного значения. Здесь возможны два случая определения относительной погрешности:
. Положим, необходимо выбрать коэффициент , с помощью которого определяется сложность кода с неотображенными операциями, так, чтобы относительная погрешность оценки сложности модельного кода не превышала некоторого заданного значения. Здесь возможны два случая определения относительной погрешности:
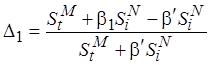 , откуда
, откуда 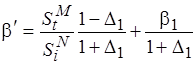 ;
;
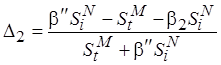 , где
, где 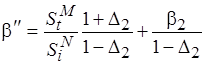 .
.
При этом, полагая  , имеем
, имеем 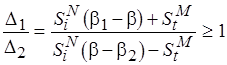 , поскольку
, поскольку 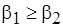 .
.
Следовательно, для того чтобы относительная погрешность оценки сложности модельного кода не превышала значения 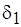 , коэффициент должен иметь следующее значение
, коэффициент должен иметь следующее значение
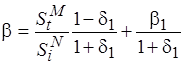 .
.
Здесь значения  и
и 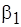 являются известными ( определяется по (4.5)). По сути, коэффициент отражает такое соотношение параметров кодов инструментального и целевого процессоров, а именно, , и
являются известными ( определяется по (4.5)). По сути, коэффициент отражает такое соотношение параметров кодов инструментального и целевого процессоров, а именно, , и  в (4.1), при которой погрешность оценки сложности модельного кода не превышает . Если параметры кодов не связаны подобным образом, то гарантий того, что погрешность не больше значения , дать нельзя.
в (4.1), при которой погрешность оценки сложности модельного кода не превышает . Если параметры кодов не связаны подобным образом, то гарантий того, что погрешность не больше значения , дать нельзя.
На рис. 4.4 приведены примеры таких зависимостей для  и
и  .
.
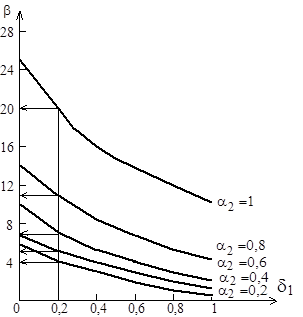
Рис. 4.4. Взаимосвязь параметров кодов инструментального, целевого процессоров и погрешность оценки модельного кода
Положим, необходимо получить оценку с погрешностью, не превышающей 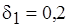 . При заданной верхней границе отношения
. При заданной верхней границе отношения 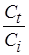 это возможно лишь тогда, когда
это возможно лишь тогда, когда 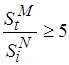 . Максимальные значения коэффициента отмечены горизонтальными стрелками на рис. 4.4. Напомним, что сложность оценивается через усреднение
. Максимальные значения коэффициента отмечены горизонтальными стрелками на рис. 4.4. Напомним, что сложность оценивается через усреднение 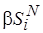 . При этом, чем больше степень соответствия между кодами целевого и инструментального процессоров, выраженная через параметр , тем больше допустимое значение . Параметр (4.1) отражает соотношение долей неотображаемых и отображаемых операций в кодах и .
. При этом, чем больше степень соответствия между кодами целевого и инструментального процессоров, выраженная через параметр , тем больше допустимое значение . Параметр (4.1) отражает соотношение долей неотображаемых и отображаемых операций в кодах и .
В общем случае сложность кода и, соответственно, время исполнения фрагмента программы являются случайными величинами. Их значения могут зависеть, например, от вида исходных данных. Поэтому под нужно понимать соответствующую числовую характеристику, в частности, оценку математического ожидания сложности  , получаемую из
, получаемую из 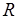 процедур статического анализа (прогонов модельного кода). Здесь должно быть достаточно велико, чтобы считать применимой центральную предельную теорему для сложности
процедур статического анализа (прогонов модельного кода). Здесь должно быть достаточно велико, чтобы считать применимой центральную предельную теорему для сложности  , получаемой в
, получаемой в 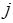 -м прогоне. При этом вводятся классические оценки доверительного интервала
-м прогоне. При этом вводятся классические оценки доверительного интервала 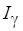 для заданной доверительной вероятности
для заданной доверительной вероятности 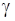 :
:
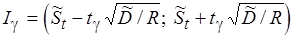 ;
;
 – несмещенная оценка дисперсии;
– несмещенная оценка дисперсии;
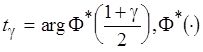 – нормальная функция распределения,
– нормальная функция распределения, 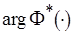 – функция, обратная
– функция, обратная 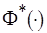 .
.
Влияние вида целевой архитектуры на оценки сложности кода. При оценке общей сложности модельного кода мы предполагаем, что известна сложность отображенного кода. Разумеется, она зависит не только от конкретного типа целевого процессора, но и, в целом, от вида целевой архитектуры, что требует анализа выбранной модели обработки. Поясним это на следующем примере. Положим, вычислительный модуль, показанный на рис. 4.5, содержит блок обработки (БО) на основе универсального микропроцессора; локальную оперативную память (ЛОП); блок прямого доступа к памяти (ПДП) и буферный регистр (БР).
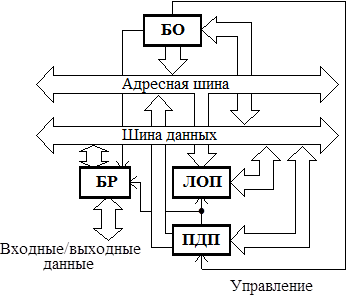
Рис. 4.5. Структура вычислительного модуля
Пусть в вычислительный модуль через буферный регистр поступает 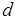 бит, обрабатываемых порциями по
бит, обрабатываемых порциями по 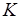 бит. При этом полагаем, что
бит. При этом полагаем, что  , где
, где 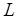 – разрядность процессора. Во избежание
– разрядность процессора. Во избежание 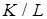 прерываний процессора вводится блок прямого доступа к локальной памяти. Таким образом, если
прерываний процессора вводится блок прямого доступа к локальной памяти. Таким образом, если 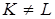 , то добавляется некоторое число процессорных циклов для подготовки и завершения собственно процедуры обработки, требующей
, то добавляется некоторое число процессорных циклов для подготовки и завершения собственно процедуры обработки, требующей  циклов, если
циклов, если 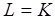 . Здесь
. Здесь 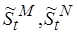 – оценки средних значений сложности. Сложность возрастает за счет операций препроцессорной и постпроцессорной обработки: разбиения -разрядного слова на частей; пересылок, запоминания в локальной оперативной памяти и вызовов их из нее; формирования целого слова из бит после окончания обработки слов (рис. 4.6).
– оценки средних значений сложности. Сложность возрастает за счет операций препроцессорной и постпроцессорной обработки: разбиения -разрядного слова на частей; пересылок, запоминания в локальной оперативной памяти и вызовов их из нее; формирования целого слова из бит после окончания обработки слов (рис. 4.6).
Будем считать, что операции препроцессорной и постпроцессорной обработки принадлежат множеству и требуют 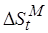 процессорных циклов. Таким образом, сложность отображенного кода равна
процессорных циклов. Таким образом, сложность отображенного кода равна 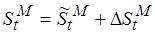 , а общая сложность
, а общая сложность 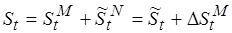 .
.
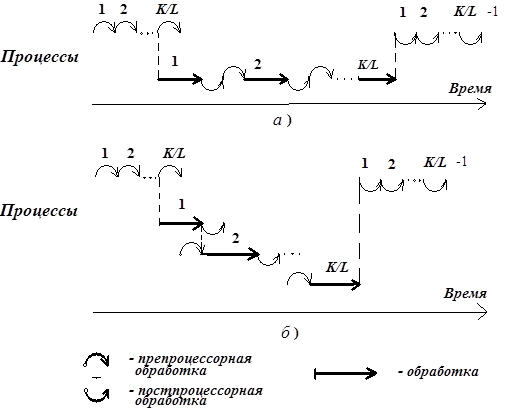
Рис. 4.6. Модели последовательной (а) и конвейерной (б) обработки
Время обработки бит составляет  , где
, где 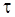 – длительность цикла целевого процессора. Положим,
– длительность цикла целевого процессора. Положим, 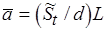 – среднее число циклов для обработки -битового слова, а
– среднее число циклов для обработки -битового слова, а 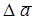 – среднее число циклов для -битовой препроцессорной и постпроцессорной обработки.
– среднее число циклов для -битовой препроцессорной и постпроцессорной обработки.
Тогда среднее время выполнения фрагмента равно
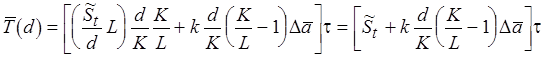 , (4.7)
, (4.7)
где 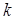 – коэффициент, определяющий способ обработки (см. рис. 4.6).
– коэффициент, определяющий способ обработки (см. рис. 4.6).
Время исполнения фрагмента определяется сложностью и временем цикла процессора. Предположим, что задано ограничение на среднее время выполнения фрагмента кода: 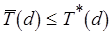 . Значение в (4.7) зависит от вида целевой архитектуры. В простейшем случае оно, по крайней мере, должно быть кратно разрядностям процессора в блоке обработки, локальной оперативной памяти, входных/выходных слов и должно быть равно разрядности буферного регистра (см. рис. 4.5). Положим, в (4.7)
. Значение в (4.7) зависит от вида целевой архитектуры. В простейшем случае оно, по крайней мере, должно быть кратно разрядностям процессора в блоке обработки, локальной оперативной памяти, входных/выходных слов и должно быть равно разрядности буферного регистра (см. рис. 4.5). Положим, в (4.7) 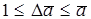 . Тогда можно получить огрубленные оценки максимально допустимого времени цикла процессора в блоке обработки:
. Тогда можно получить огрубленные оценки максимально допустимого времени цикла процессора в блоке обработки:
а) 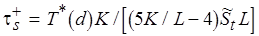 – для последовательной обработки (см. рис. 4.6, а);
– для последовательной обработки (см. рис. 4.6, а);
б) 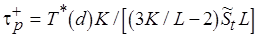 – для конвейерной обработки (см. рис. 4.6, б).
– для конвейерной обработки (см. рис. 4.6, б).
Значения коэффициента при этом соответственно равны:  и
и 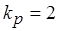 . Очевидно, что
. Очевидно, что 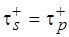 , если
, если  . Коэффициенты
. Коэффициенты 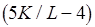 и
и 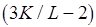 в выражениях для
в выражениях для 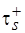 и
и 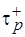 можно рассматривать как множители, определяющие увеличение сложности
можно рассматривать как множители, определяющие увеличение сложности 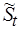 модельного кода в зависимости от выбираемого способа обработки. Конечно, оценки
модельного кода в зависимости от выбираемого способа обработки. Конечно, оценки  являются весьма грубыми, однако они могут использоваться на ранних этапах анализа эффективности той или иной целевой архитектуры. Так, пусть
являются весьма грубыми, однако они могут использоваться на ранних этапах анализа эффективности той или иной целевой архитектуры. Так, пусть 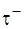 – минимально возможное время цикла процессора, а
– минимально возможное время цикла процессора, а 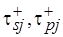 – оценки максимально допустимого времени цикла при выполнении -го фрагмента кода
– оценки максимально допустимого времени цикла при выполнении -го фрагмента кода 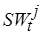 на целевой вычислительной системе. Положим, что
на целевой вычислительной системе. Положим, что 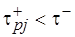 и, следовательно,
и, следовательно,  . Тогда можно заключить, что -й фрагмент не может быть реализован на процессоре с временем цикла при заданных параметрах целевой архитектуры (см. рис. 4.5), например,
. Тогда можно заключить, что -й фрагмент не может быть реализован на процессоре с временем цикла при заданных параметрах целевой архитектуры (см. рис. 4.5), например, 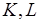 и . В общем же случае увеличение сложности, а значит, и времени реализации (4.7) участка программы зависит от принятой модели обработки и набора базовых операций целевого процессора.
и . В общем же случае увеличение сложности, а значит, и времени реализации (4.7) участка программы зависит от принятой модели обработки и набора базовых операций целевого процессора.
Выводы. Таким образом, основной источник погрешности оценок модельного кода – наличие неотображаемых операций в коде ассемблера для инструментальной системы. Выше были приведены соотношения для погрешности в оценке сложности кода, а также значение оптимальной сложности кода целевого процессора. В ходе статического анализа необходимо учитывать не только особенности процессора, но и вид архитектуры целевой вычислительной системы. И, еще раз подчеркнем, что к статико-динамическому анализу приходится прибегать тогда, когда по каким-либо причинам не удается осуществить реальных прогонов программы на целевой платформе.