Лекс анализатор - цель разбить текст на лексемы.
Таблица команд,таблица переменных,таблица констант,термов.
Типа как: 0=>program,1=>var и тд..
Лексический анализ – первая фаза процесса трансляции, предназначенная для группировки символов входной цепочки в более крупные конструкции, называемые лексемами. С каждой лексемой связано два понятия:
– класс лексемы, определяющий общее название для категории элементов, обладающих общими свойствами (например, идентификатор, целое число, строка символов и т. д.);
– значение лексемы, определяющее подстроку символов входной цепочки, соответствующих распознанному классу лексемы. В зависимости от класса, значение лексемы может быть преобразовано во внутреннее представление уже на этапе лексического анализа. Так, например, поступают с числами, преобразуя их в двоичное машинное представление, что обеспечивает более компактное хранение и проверку правильности диапазона на ранней стадии анализа.
Лексический анализ включает в себя сканирование исходного текста программы и распознавание лексем, т.е. элементов, из которых строятся предложения языка, и замену их кодами лексем. Лексемой может быть ключевое слово, имя переменной, число и т.п. Программу, которая выполняет лексический анализ, называют лексическим анализатором или сканером. Точный перечень лексем, которые необходимо распознавать, зависит от языка программирования и от грамматики, используемой для его описания. Например, для языка PASCAL лексемами являются: PROGRAM, INTEGER, REAL, VAR, DO, READ и т.д. Каждый код лексемы обычно представляется кодом таблицы и спецификатором. Спецификатор задает номер строки в таблице, куда занесена лексема. Это позволяет избежать дополнительного поиска по таблицам на последующих этапах трансляции. Сканер работает с тремя таблицами: терминальных символов, символических имен и литералов.
Таблица терминальных символов в простейшем случае может иметь следующий вид:
| № строки | Терминальный символ | Признак разделителя |
| PROGRAM | – | |
| VAR | – | |
| BEGIN | – | |
| END | – | |
| INTEGER | – | |
| FOR | – | |
| TO | – | |
| DO | – | |
| WHILE | – | |
| DIV | – | |
| MOD | – | |
| AND | – | |
| OR | – | |
| := | + |
Таблица символических имен может иметь следующий вид:
| № строки | Символическое имя | Адрес | Тип | Другая информация |
| I | int | |||
| Y | real | |||
| X1 | real | |||
| ... | ... | ... | ... |
Таблица литералов по структуре аналогична таблице символических имен:
| № строки | Литерал | Адрес | Тип | Другая информация |
| int | ||||
| int | ||||
| ... | ... | ... | ... |
Результатом работы сканера является последовательность кодов лексем. Например, в результате обработки сканером следующего предложения языка Pascal
FOR I:= 1 TO 100 DO Y:= X1;
Будет получена строка:
<1,06><2,1><1,14><3,1><1,07><3,2><1,08><2,2><1,14><2,3>,
где в угловых скобках пара чисел задает код таблицы и спецификатор. В дополнение к своей основной функции – распознавание лексем – сканер также выполняет чтение строк и печать листинга исходной программы.
Функционально в сканере могут быть выделены следующие модули:
1. Выделение из входной строки очередного слова.
2. Поиск в таблицах лексем и определение кода лексемы.
3. Формирование и вывод выходной строки.
Для модуля выделения слова важна информация о том, какие символы могут быть признаками начала или конца слова. Например, в языке PASCAL ключевые слова отделяются от других элементов предложения пробелами. Сложнее обстоит дело с выделением идентификаторов и чисел, поскольку разделителем для них может служить любой другой символ, не входящий по определению в идентификатор или число.
Для поиска в таблицах может быть использован как наиболее простой метод – линейный алгоритм.
При заполнении таблиц выполняется проверка на наличие в ней элемента, совпадающего с выделенным идентификатором или константой, и при совпадении занесение в таблицу не выполняется.
В задачи последнего модуля входит занесение в выходную строку кодов лексем.
2. Машинно- независимая оптимизация кода.
Предполагает:
1. Одним из важнейших источников оптимизации кода является удаление общих подвыражений, т.е. подвыражений, которые встречаются в нескольких местах программы и вычисляют одно и то же выражение.
2. Другим источником оптимизации кода является удаление инвариантов цикла. Так называются подвыражения внутри цикла, результирующие значения которых не изменяются внутри цикла при переходе от одной итерации к другой. Поскольку для большинства программ основное время работы приходится на выполнение циклов, экономия времени от подобной оптимизации может быть весьма существенной.
3. Еще один источник оптимизации кода состоит в замене менее эффективных операций на более эффективные.
3. Синтаксический анализ: задачи, виды, преимущества использования грамматик.
Синт анализатор - цель проверка входной строки на соответстиве грамматики.
Мн-во терм символов - (ab+-12 и тд)
набор нетерм символов - A B C
продукции - A->Bc|Ad
начальный нетерминал
Лекс А->Синт А->Дерево разбора->Семант А
_____________________________________________________________
Синтаксическая диаграмма графически изображает структуру конструкций алгоритмического языка. Отдельными элементами диаграммы могут быть основные символы или понятие языка. Из каждого элемента выходит одна или несколько стрелок, указывающих на те элементы, которые могут непосредственно следовать за данным элементом (то есть стрелки указывают возможных преемников каждого из элементов диаграммы). Стрелка, не выходящая из какого-либо элемента, является входом в диаграмму, а стрелка, не ведущая к какому-либо элементу, означает выход из диаграммы, то есть конец синтаксического определения. Чтобы легче было отличить в диаграммах основные символы (терминальные) от понятий (нетерминальных символов) их выделяют каким-либо способом, например, заключают основные символы в кружки или овалы, а понятия – в прямоугольники. Однако, это не совсем удобно при подготовке печатных документов.
Поэтому сохраним для понятий символику БНФ, то есть понятия будут заключаться в угловые скобки, а терминальные символы будут без скобок.
Например, определение идентификатора в БНФ имеет вид:
1.<идентификатор>::=<буква><продолжение идентификатора>
2. <продолжение идентификатора>::= <буква><продолжение идентификатора> |
<цифра><продолжение идентификатора> |
<пусто>
Синтаксическая диаграмма для этого определения будет выглядеть, как показано на Рисунке 2.1.

Рисунок 2.1 Синтаксическая диаграмма идентификатора
Достоинством синтаксических диаграмм является наглядность и простота для понимания. Кроме того, от синтаксической диаграммы просто перейти к блок-схеме алгоритма грамматического разбора.
Для данного примера диаграммы блок-схема приведена на Рисунке 2.2. (указанные в блок-схеме подпрограммы вырабатывают признак U=True, если символ входной строки соответствует проверяемому понятию, и U=False – в противном случае). Подпрограммы «буква» и «цифра» выполняют соответственно проверку очередного символа входной строки на принадлежность множеству букв и цифр.
Общим недостатком формальных методов является отсутствие средств для задания смысловых правил синтаксиса языка. Примером такого вида правил является требование, чтобы все объекты в PASCAL-программе были описаны. Однако при переходе к алгоритмическому заданию синтаксиса (например, в виде блок-схемы) эта трудность преодолима. Пусть в рассмотренном примере требуется, чтобы количество символов в идентификаторе не превышало 5. Если обозначить счетчик символов как COUNT, то можно изменить приведенную на Рисунке 2.2 блок-схему так, как показано на Рисунке 2.3.
Задача синтаксического анализа упрощается, если программа предварительно обработана лексическим анализатором и поступает на вход синтаксического анализатора в форме последовательности кодов лексем. Тогда любой модуль блок-схемы, соответствующий элементу диаграммы, в начале по коду таблицы определяет допустимость данного вида лексем в структуре предложения и если допустим, тогда по спецификатору проверяется допустимость лексемы.
4. Машино- зависимая оптимизация кода.
Использование регистров процессора вместо ячеек оперативной памяти.
Использование непосредственно заданных операндов.
Использование косвенной адресации, когда операнд хранит адрес операнда.
Ограничение использования стека.
программа оптимизация ассемблер листинг
5. Метод рекурсивного спуска.
Метод рекурсивного спуска или нисходящий разбор — это один из методов определения принадлежности входной строки к некоторому формальному языку, описанному LL(k) контекстно-свободной грамматикой. Это класс алгоритмов грамматического анализа, где правила формальной грамматики раскрываются, начиная со стартового символа, до получения требуемой последовательности токенов.
Идея метода
Для каждого нетерминального символа K строится функция, которая для любого входного слова x делает 2 вещи:
-Находит наибольшее начало z слова x, способное быть началом выводимого из K слова
-Определяет, является ли начало z выводимым из K
Такая функция должна удовлетворять следующим критериям:
-считывать из еще необработанного входного потока максимальное начало A, являющегося началом некоторого слова, выводимого из K
-определять является ли A выводимым из K или просто невыводимым началом выводимого из K слова
В случае, если такое начало считать не удается (и корректность функции для нетерминала K доказана), то входные данные не соответствуют языку, и следует остановить разбор.
Разбор заключается в вызове описанных выше функций. Если для считанного нетерминала есть составное правило, то при его разборе будут вызваны другие функции для разбора входящих в него терминалов. Дерево вызовов, начиная с самой «верхней» функции эквивалентно дереву разбора.
Наиболее простой и «человечный» вариант создания анализатора, использующего метод рекурсивного спуска, — это непосредственное программирование по каждому правилу вывода для нетерминалов грамматики.
__________________________________________________________
· В лексическом анализе были рассмотрены две модели анализаторов: автоматная и на «жесткой» логике:
· В анализаторе на «жесткой» логике лексика «зашита» в управляющие конструкции программы (ветвления, циклы), т.е. непосредственно в алгоритмическую часть. В результате анализатор настроен на единственный вариант лексики;
· В автоматной модели лексика «зашита» в управляющие таблицы конечного автомата (КА), т.е. по существу является данными. Это позволяет настраивать анализатор на различные варианты лексики, но требует предварительной работы по проектированию самого КА и построению его управляющих таблиц, либо наличия языка формального языка описания лексики и транслятора с него.
· Наличие двух вариантов иллюстрирует один из фундаментальных тезисов теории алгоритмов - эквивалентность алгоритма и данных: уменьшить объем алгоритмической части программы можно за счет «переноса» управляющих конструкций алгоритма в данные и наоборот.
· В синтаксическом анализе, аналогично, известен метод рекурсивного спуска, основанный на «зашивании» правил грамматики непосредственно в управляющие конструкции распознавателя. Идеи нисходящего разбора, принятые в LL(1)-грамматиках, в нем полностью сохраняются:
· происходит последовательный просмотр входной строки слева-направо;
· очередной символ входной строки является основанием для выбора одной из правых частей правил группы при замене текущего нетерминала;
· терминальные символы входной строки и правой части правила «взаимно уничтожаются»;
· обнаружение нетерминала в правой части рекурсивно повторяет этот же процесс.
· В методе рекурсивного спуска они претерпевают такие изменения:
· каждому нетерминалу соответствует отдельная процедура (функция), распознающая (выбирающая и «закрывающая») одну из правых частей правила, имеющего в левой части этот нетерминал (т.е. для каждой группы правил пишется свой распознаватель);
· во входной строке имеется указатель (индекс) на текущий «закрываемый символ». Этот символ и является основанием для выбора необходимой правой части правила. Сам выбор «зашит» в распознавателе в виде конструкций if или switch. Правила выбора базируются на построении множеств выбирающих символах, как это принято в LL(1)-грамматике;
· просмотр выбранной части реализован в тексте процедуры-распознавателя путем сравнения ожидаемого символа правой части и текущего символа входной строки;
· если в правой части ожидается терминальный символ и он совпадает с очередным символом входной строки, то символ во входной строке пропускается, а распознаватель переходит к следующему символу правой части;
· несовпадение терминального символа правой части и очередного символа входной строки свидетельствует о синтаксической ошибке;
· если в правой части встречается нетерминальный символ, то для него необходимо вызвать аналогичную распознающую процедуру (функцию).
Для начала рассмотрим, как работает метод на достаточно простой грамматике, построив для нее формальными методами множества выбирающих символов.
Z:: N# SEL(Z::N#) = FIRST(N)=FIRST(U)={a}
N:: UM SEL(N::UM) = FIRST(U)={a}
M:: +UM SEL(M::+UM) = {+}
M:: e SEL(M::e) = FOLLOW(M)=FOLLOW(N)={#,]}
U:: aSK SEL(U::aSK) = {a}
S:: aS SEL(S::aS) = {a}
S:: e SEL(S::e) = FOLLOW(S)=
FIRST*(K) Í FOLLOW(U)=
FIRST*(K) Í FIRST*(M) Í FOLLOW(N)={[,+,],#}
K:: [N] SEL(K::[N]) = {[}
K:: e SEL(K:: e) = FOLLOW(K)=FOLLOW(U)=
FIRST*(M) Í FOLLOW(N) = {#,+,]}
Грамматика продуцирует цепочки вида aaa[a+a]+aa+aaa[a+a[a]], состоящие из идентификаторов, построенных из символов a, соединенных в цепочки символом ‘+’, возможно с квадратными скобками, в которых могут быть аналогичные цепочки. Текст распознавателя сначала напишем, формально следуя этой грамматике:
//---------------------------------------------------------------------------------------RecDown1.cpp
char s[100]="aaa[aa+aa[a]]+aa#";
int i=0;
extern void N(),M(),U(),S(),K();
// Z:: N# SEL(Z::N#)={a}
void Z(){
printf("Z::%s\n",&s[i]);
if (s[i]!='a') throw "error a(1)";
N();
if (s[i]=='#') i++; // Проверка и пропуск символа в правой части правила
else throw "error #";
}
//N:: UM SEL(N::UM)={a}
void N(){
printf("N::%s\n",&s[i]);
if (s[i]!='a') throw("error a(2)");
U(); M();
}
//M:: +UM SEL(M::+UM) = {+}
//M:: e SEL(M::e) ={#,]}
void M(){
printf("M::%s\n",&s[i]);
switch(s[i]){
case '#':
case ']': return; // Аннулирующее правило
case '+': i++; // пропуск символа +
U(); M(); break;
default: throw "error [,a";
}}
//U:: aSK SEL(U::aSK) = {a}
void U(){
printf("U::%s\n",&s[i]);
if (s[i]!='a') throw "error a(3)";
i++; // пропуск символа a
S(); K();
}
//S:: aS SEL(S::aS) = {a}
//S:: e SEL(S::e) ={[,+,],#}
void S(){
printf("S::%s\n",&s[i]);
if (s[i]=='a') { i++; S(); }
else return; // аннулирующее правило S::e для всех остальных
}
//K:: [N] SEL(K::[N]) = {[}
//K:: e SEL(K:: e) = {#,+,]}
void K(){
printf("K::%s\n",&s[i]);
switch(s[i]){
case 'a': throw "error a(4)";
case '[': i++; // пропуск символа [
N();
if (s[i]==']') i++;
else throw "error 4";
break; // ошибка - ожидается символ ]
default: return; // аннулирющее правило по ],+,#
}}
void main(){
try{
Z(); if (s[i]==0) puts("success");
} catch(char *ss){ puts(ss); puts(&s[i]); } }
В целом, грамматика перекладывается в текст программы достаточно просто и естественно. Для выбора той или иной части правил используются выбирающие символы, аннулирующие правила представляют собой «заглушки», не выполняющие никаких содержательных функций.
6. Машино- зависимая оптимизация кода.
7. LL(1) грамматики. Проверка свойств LL(1). переходов.
LL(1)-грамматика - это такая КС(1)-грамматика, в которой множества выбора правил с одинаковыми левыми частями не пересекаются.
Если возможно написать детерминированный анализатор, осуществляющий разбор сверху вниз, для языка, генерируемого s- грамматикой, то такой анализатор принято называть LL (1)-грамматикой.
Обозначения в написании LL (1)-грамматики означают:
L – строки разбираются слева направо;
L – используются самые левые выводы;
1 – варианты порождающего правила выбираются с помощью одного предварительного просмотра символа.
Т.е. грамматику называют LL (1)-грамматикой, если для каждого нетерминала, появляющегося в левой части более одного порождающего правила, множество направляющих символов, соответствующих правым частям альтернативных порождающих правил, – непересекающиеся.
Множество терминальных символов предшественников определяется следующим образом.
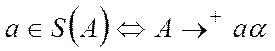 ,где А – нетерминал;
,где А – нетерминал;
a - строка терминалов и/или нетерминалов;
 - множество символов предшественников А.
- множество символов предшественников А.
Пример.
| P®Ac P®Bd A®a | A®Aa B®b B®bB |
символы а и b – символы предшественники для Р.
Определение.
Если А – нетерминал, то его направляющими символами (DS) будут + (все символы, следующие за А, если А может генерировать пустую строку).
В общем случае для заданного варианта a и нетерминала Р (P®a) имеем
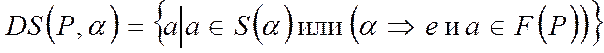 ,
,
где F (P) есть множество символов, которые могут следовать за Р.
Пример.
| T®AB A®PQ A®BC P®pP P®e Q®qQ | Q®e B®bB B®d C®cC C®f |
Эта грамматика дает  ,
,  ,
,  и
и  .
.
Из определения LL(1)-грамматики следует, что эти грамматики можно разбирать детерминирован сверху вниз.
Синтаксический LL-анализатор (LL parser) — нисходящий синтаксический анализатор для подмножества контекстно-свободных грамматик. Он анализирует входной поток слева направо, и строит левый вывод грамматики. Класс грамматик, для которых можно построить LL-анализатор, известен как LL-грамматики.
Синтаксический LL-анализатор (LL parser) — нисходящий синтаксический анализатор для подмножества контекстно-свободных грамматик. Он анализирует входной поток слева направо, и строит левый вывод грамматики. Класс грамматик, для которых можно построить LL-анализатор, известен как LL-грамматики.
Далее описывается анализатор, в основе которого лежит построение таблиц; альтернативой может служить анализатор, построенный методом рекурсивного спуска, который обычно пишется вручную (хотя существуют и исключения, например, генератор синтаксических анализаторов ANTLR для LL(*) грамматик).
LL-анализатор называется LL(k)-анализатором, если данный анализатор использует предпросмотр на k токенов (лексем) при разборе входного потока. Грамматика, которая может быть распознана LL(k)-анализатором без возвратов к предыдущим символам, называется LL(k)-грамматикой. Язык, который может быть представлен в виде LL(k)-грамматики, называется LL(k)-языком. Существуют LL(k)-языки, которые не являются LL(k+n)-языками. Следовательно, не все контекстно-свободные языки являются LL(k)-языками.
LL(1)-грамматики очень распространены, потому что соответствующие им LL-анализаторы просматривают поток только на один символ вперед при принятии решения о том, какое правило грамматики необходимо применить. Языки, основанные на грамматиках с большим значением k, традиционно считались трудными для распознавания, хотя при широком распространении генераторов синтаксических анализаторов, поддерживающих LL(k) грамматики с произвольным k, это замечание уже неактуально.
LL-анализатор называется LL(*)-анализатором, если нет строгого ограничения для k и анализатор может распознавать язык, если токены принадлежат какому-либо регулярному множеству (например, используя детерминированные конечные автоматы).
Существуют противоречия между так называемой «Европейской школой» построения языков, которая основывается на LL-грамматиках, и «Американской школой», которая предпочитает LR-грамматики. Такие противоречия обусловлены традициями преподавания и деталями описания различных методов и инструментов в конкретных учебниках; кроме того, свое влияние оказал Н. Вирт из ETHZ, чьи исследования описывают различные методы оптимизации LL(1) распознавателей и компиляторов.
Синтаксический анализатор предназначен для разрешения проблемы принадлежности строки заданной грамматике и построения дерева вывода в случае принадлежности.
Синтаксический анализатор состоит из:
-Ленты (входного буфера) — содержит анализируемую строку
-Стек — служит для сохранения промежуточных данных синтаксического анализа
-Таблица синтаксического анализа — таблица, задающая однозначное соответствие правила грамматики для символа магазинного алфавита, находящегося на вершине стека, и текущего читаемого символа на ленте, или содержащая информацию об отсутствии такого правила для заданной пары символов.
В строках таблицы располагаются символы магазинного алфавита, а в столбцах — символы терминального алфавита.
При запуске синтаксического анализа, стек уже содержит два символа:[ S, $ ]
Где '$' — специальный терминал, служащий для указания конца стека, а 'S' — аксиома грамматики. Синтаксический анализатор пытается при помощи правил грамматики заменить в стеке аксиому на цепочку символов, аналогичную цепочке, находящейся на входной ленте, и затем полностью прочитать ленту, опустошая стек.
8. Критерии производительности компиляторов.
Критерии производительности Имеется ряд аспектов производительности компилятора. Достаточно сложно найти компромисс среди всех этих критериев, а кроме того, ряд параметров может остаться не определенным спецификацией компилятора. Например, что важнее — скорость работы компилятора или скорость работы генерируемого им кода. Однако такой подход может не привести к компилятору, который генерирует высококачественный целевой код и имеет простую поддержку. Есть два аспекта переносимости компилятора. Переносимый компилятор может оказаться не настолько эффективен, как компилятор, разрабатываемый для определенной машины, поскольку последний может использовать информацию о целевой машине, которую не может использовать переносимый компилятор.
Компилятор — достаточно сложная программа, которую желательно писать на языке более дружественном, чем ассемблер. Использование возможностей языка для компиляции его самого является сущностью раскрутки. Здесь мы рассмотрим использование раскрутки для создания компиляторов и перенесения их с одной машины на другую путем изменения заключительной стадии компиляции. Основные идеи раскрутки известны со средины. Раскрутка может привести к вопросу о том, как был скомпилирован первый компилятор. Для ответа мы рассмотрим, каким образом
ПОДХОДЫК РАЗРАБОТКЕ КОМПИЛЯТОРА.
Старый компилятор генерировал недостаточно эффективный код. Среда разработки компилятора По существу, компилятор является просто программой. Среда, в которой эта программа разрабатывается, может повлиять на скорость и надежность реализации компилятора. Не менее важен и язык разработки компилятора. Хотя имеются компиляторы, написанные на языках типа. Если исходный язык представляет собой новый системно. С использованием рассмотренной в предыдущем разделе технологии, компилирование компилятора облегчает его отладку. Существенно облегчить создание эффективного компилятора может инструментарий разработки программного обеспечения, имеющийся в используемой среде программирования. При написании компилятора обычным является разделение всей программы на модули, где каждый модуль может обрабатываться своим способом. Программа, управляющая обработкой таких модулей, — незаменимый помощник создателя компилятора. Чтобы показать, как задача сборки компилятора может быть выполнена с помощью. Двоеточие во второй строке говорит о том, что файл. За такой строкой зависимости могут следовать команды для. Транслятор создается посредством ввода команды. После создания компилятора профайлер может использоваться для определения того, какое время затрачивается при компиляции на решение различных задач. В дополнение к общим инструментам для разработки программного обеспечения, при разработке компиляторов используются специализированные инструменты. В дополнение к генераторам лексических и синтаксических анализаторов, созданы генераторы атрибутных грамматик и генераторов кода, облегчающие создание соответствующих компонентов компилятора. Многие из этих инструментов обеспечивают поиск ошибок в спецификациях компиляторов. По поводу эффективности и удобства генераторов программ при построении компиляторов велись определенные споры. Однако нельзя отрицать тот факт, что хорошо реализованный генератор может оказать неоценимую помощь при разработке надежных. СРЕДА РАЗРАБОТКИ КОМПИЛЯТОРА. Корректный синтаксический анализатор гораздо проще получить при использовании грамматического описания языка и генератора анализаторов, чем при кодировании его вручную. Важным вопросом, однако, является то, насколько корректно эти генераторы работают в связке друг с другом и с другими программами.
9. Преобразование грамматик к LL(1) виду.
Найдя LL (1)-грамматику для языка, можно перейти к следующему этапу – применению найденной грамматики в фазе разбора. Обычно модуль компилятора, занимающийся семантическим разбором, называется драйвером. Драйвер указывает на то место в синтаксисе, которое соответствует текущему входному символу. Составной частью драйвера является стек, который служит для запоминания адресов возврата всякий раз, когда он входит в новое порождающее правило, соответствующее какому-нибудь нетерминалу.
Опишем сначала возможный вид таблицы разбора, а затем рассмотрим возможные способы ее оптимизации относительно используемых вычислительных ресурсов.
Таблица разбора в общем виде представляет собой одномерный массив структур вида:
declare 1 TABLE,
2 terminals list,
2 jump int,
2 accept bool,
2 stack bool,
2 return bool,
2 error bool;
где list
declare 1 list,
2 term string,
2 next pointer;
Кроме того, для работы драйвера нужен стек адресов возврата и указатель стека.
В таблице каждому шагу процесса разбора соответствует один элемент. В процессе разбора осуществляются следующие шаги.
1) Проверка предварительно просматриваемого символа, для того чтобы выяснить, не является ли он направляющим для какой-либо конкретной правой части порождающего правила. Если этот символ – не направляющий и имеется альтернативная правая часть правила, то она проверяется на следующем этапе. В особом случае, когда правая часть начинается с терминала, множество направляющих символов состоит только из одного терминала.
2) Проверка терминала, появляющегося в правой части порождающего правила.
3) Проверка нетерминала. Она заключается в проверке нахождения предварительно просматриваемого символа в одном из множеств направляющих символов для данного нетерминала, помещению в стек адреса возврата и переходу к первому правилу, относящемуся к этому нетерминалу. Если нетерминал появился в конце правой части правила, то нет необходимости помещать в стек адрес его возврата.
Таким образом, в таблицу разбора включается по одному элементу на каждое правило грамматики и на каждый экземпляр терминала или нетерминала правой части правил. Кроме того, в таблице будут находиться элементы на реализацию пустой строки в правой части правил (по одному на каждую реализацию).
Драйвер содержит процедуру, которая обрабатывает элементы таблицы разбора и определяет следующий элемент для обработки. Поле перехода обычно дает следующий элемент обработки, если значение поля возврата не окажется истиной. В последнем случае адрес следующего элемента берется из стека (что соответствует концу правила). Если же предварительно просматриваемый символ отсутствует в списке терминалов и значение поля ошибки окажется ложью, нужно обрабатывать следующий элемент таблицы с тем же предварительно просматриваемым символом (способ обращения с альтернативными правыми частями).
Рассмотрим схему построения таблицы разбора и соответствующей программы для следующей грамматики:
(1) PROGRAM ® begin DECLIST semi STATLIST end
(2) DECLIST ® d X
(3) X ® comma DECLIST
(4) X ® e
(5) STATLIST ® s Y
(6) Y ® comma STATLIST
(7) Y ® e
Сначала представим грамматику в виде схемы (рис. 4.1). В скобках и справа на рисунке указаны номера элементов таблицы разбора.
Таблица разбора, соответствующая этой грамматике может быть представлена в виде табл. 4.6.
| (1) | PROGRAM | 
| begin | (2) | |||||||
| DECLIST | (3) | ||||||||||
| semi | (4) | ||||||||||
| STATLIST | (5) | ||||||||||
| end | (6) | ||||||||||
| (7) | DECLIST | d | (8) | ||||||||
| X | (9) | ||||||||||
| (10) | X1 | comma | (12) | ||||||||
| (11) | X2 | DECLIST | (13) | ||||||||
| e | (14) | ||||||||||
| (15) | STATLIST | s | (16) | ||||||||
| Y | (17) | ||||||||||
| (18) | Y1 | comma | (20) | ||||||||
| (19) | Y2 | STATLIST | (21) | ||||||||
| e | (22) |
Рис. 4.1. Схема грамматики
Таблица 4.6 – Таблица разбора
| terminals | jump | accept | stack | return | Error | |
| {begin} {begin} {d} {semi} {s} {end} {d} {d} {comma, semi} {comma} {semi} {comma} {d} {semi} {s} {s} {comma, end} {comma} {end} {comma} {s} {end} | 2 3 7 5 15 0 8 9 10 12 14 13 7 0 16 17 18 20 22 21 15 0 | false true false true false true false true false false false true false false false true false false false true false false | false false true false true false false false false false false false false false false true false false false false false false | false false false false false true false false false false false false false true false false false false false false false true | True True True True True true true true true false true true true true true true true false true true true true |
Рассмотрим разбор предложения
begin d comma d semi s semi end
| i | Действия | Стек разбора | |
| 1. | begin считывается и проверяется; перейти к 2 | ||
| 2. | begin считывается и принимается; перейти к 3 | ||
| 3. | d считывается и проверяется; 4 помещается в стек; перейти к 7 | ||
| 7. | d принимается; перейти к 8 | ||
| 8. | d проверяется и принимается; перейти к 9 | ||
| 9. | comma считывается и проверяется; перейти к 10 | ||
| 10. | comma проверяется; перейти к 12 | ||
| 12. | comma проверяется и принимается; перейти к 13 | ||
| 13. | d считывается и проверяется; перейти к 7 | ||
| 7. | d проверяется; перейти к 8 | ||
| 8. | d проверяется и принимается; перейти к 9 | ||
| 9. | comma считывается и проверяется; перейти к 10 | ||
| 10. | semi не совпадает с comma; ошибка ложь – перейти к 11 | ||
| 11. | comma проверяется; перейти к 14 | ||
| 14. | semi проверяется; возврат истина – удаляется 4; перейти к 4 | ||
| 4. | semi проверяется и принимается; перейти к 5 | ||
| 5. | s считывается и проверяется; 6 помещается в стек; перейти к 15 | ||
| 15. | s проверяется; перейти к 16 | ||
| 16. | s проверяется и принимается; перейти к 17 | ||
| 17. | comma считывается и проверяется; перейти к 18 | ||
| 18. | comma проверяется; перейти к 20 | ||
| 20. | comma проверяется и принимается; перейти к 21 | ||
| 21. | s считывается и проверяется; перейти к 15 | ||
| 15. | s проверяется; перейти к 16 | ||
16.
<
Поиск по сайту©2015-2024 poisk-ru.ru
Все права принадлежать их авторам. Данный сайт не претендует на авторства, а предоставляет бесплатное использование. Дата создания страницы: 2017-06-21 Нарушение авторских прав и Нарушение персональных данных |
Поиск по сайту: Читайте также: Деталирование сборочного чертежа Когда производственнику особенно важно наличие гибких производственных мощностей? Собственные движения и пространственные скорости звезд |