Полная и достоверная статистическая информация является тем необходимым основанием, на котором базируется процесс управления экономикой. Вся информация, имеющая народнохозяйственную значимость, в конечном счете, обрабатывается и анализируется с помощью статистики.
Именно статистические данные позволяют определить объемы валового внутреннего продукта и национального дохода, выявить основные тенденции развития отраслей экономики, оценить уровень инфляции, проанализировать состояние финансовых и товарных рынков, исследовать уровень жизни населения и другие социально-экономические явления и процессы. Овладение статистической методологией - одно из условий для предприятия в познании конъюнктуры рынка, изучении тенденций и прогнозировании, принятии оптимальных решений на всех уровнях деятельности.
Статистическая практика - это деятельность по сбору, накоплению, обработке и анализу цифровых данных, характеризующих все явления в жизни общества. Окружающий мир состоит из массовых явлений. Если отдельный факт зависит от законов случая, то масса явлений подчиняется закономерностям. Для обнаружения этих закономерностей используется закон больших чисел. Процесс статистического исследования включает три основные стадии: сбор данных, их сводка и группировка, анализ и расчет обобщающих показателей. От того, как собран первичный статистический материал, как он обработан и сгруппирован в значительной степени зависят результаты и качество всей последующей работы.
Сложной, трудоемкой и ответственной является заключительная, аналитическая стадия исследования. На этой стадии рассчитываются средние показатели и показатели распределения, анализируется структура совокупности, исследуется динамика и взаимосвязь между изучаемыми явлениями и процессами.
На всех стадиях исследования статистика использует различные методы. Методы статистики - это особые примы и способы изучения массовых общественных явлений.
На первой стадии исследования применяются методы массового наблюдения, собирается первичный статистический материал. Основное условие - массовость, т.к. закономерности общественной жизни проявляются в достаточно большом массиве данных в силу действия закона больших чисел, т.е. в сводных статистических характеристиках случайности взаимопогашаются. На второй стадии исследования, когда собранная информация подвергается статистической обработке, используется метод группировок. Применение метода группировок требует непременного условия - качественной однородности совокупности. На третьей стадии исследования проводится анализ статистической информации.
1.1 Метод группировок
Различные единицы статистической совокупности, имеющие определенное сходство межу собой по достаточно важным признакам, объединяются в группы при помощи метода группировки. Такой прием позволяет «сжать» информацию, полученную в ходе наблюдения, и на этой основе установить закономерности, присущие изучаемому явлению.
Группировка – это распределение единиц по группам в соответствии со следующим принципом: различия между единицами, отнесенными к одной группе, должны быть меньше, чем между единицами, отнесенными к разным группам или расчленение множества единиц исследуемой совокупности на группы по определенным существенным для них признакам.
Метод группировок применяется для решения различных задач, важнейшими из которых являются: выделение социально-экономических типов, определение структуры однотипных совокупностей, вскрытие связей и закономерностей между отдельными признаками общественных явлений
В связи с этим существуют 3 вида группировок: типологические, структурные и аналитические. Группировки различают по форме проведения. Выполнятся они могут либо путем последовательного развертывания, либо одновременного охвата группировочных признаков, вследствие чего образуются простая группировка (по одному признаку) и комбинационная группировка (по двум или нескольким признакам).
Типологическая группировка представляет собой разделение совокупности на классы, социально-экономические типы, однородные группы единиц, например можно назвать группировки работников одной профессии по различным квалификациям, группировки акционерных компаний по различным уровням дивидендов. Сначала намечают, к какому типу относится та или иная группа или подгруппа, затем подсчитывают число единиц совокупности по каждой группе или подгруппе и посредством суммирования однокачественных групп и подгрупп устанавливают число типов, которые характеризуются соответствующими системами показателей.
Структурные группировки разделяют однородную в качественном отношении совокупность единиц по определенным, существенным признакам на группы, характеризующие ее состав и внутреннюю структуру. Структурные группировки дают информацию о том, из каких частей состоит изучаемое множество явлений, каково строение типов явлений и какими показателями характеризуются отдельные части; служат преимущественно для получения выводов о текущем состоянии хозяйства, используются для оперативного руководства работой предприятия, а также в качестве основы для выявления и мобилизации имеющихся в хозяйстве резервов. В качестве примеров можно назвать группировки рабочих по стажу работы, по заработной плате, исследование состава населения по полу, возрасту, исследование состава коммерческих банков по капиталу, уставному фонду.
Аналитические группировки обеспечивают установление взаимосвязи и взаимозависимости между исследуемыми социально-экономическими явлениями и признаками, их характеризующими. Посредством этого вида группировок устанавливаются и изучаются причинно-следственные связи между признаками однородных явлений, определяются факторы развития статистической совокупности. В качестве примеров можно назвать установление связей между стажем работы и часовой заработной платой в коллективе рабочих одной профессии.
Метод группировок используется совместно с методом обобщающих показателей. Поэтому для каждой группы, образованной по какому-либо признаку, вычисляется средняя абсолютная или относительная величина результативного признака.
Основные понятия статистических методов
При наличии большого количества статистических данных разного значения производится случайный отбор ограниченного (небольшого) числа объектов, которые и подвергают изучению. Выборочной совокупностью (выборкой) называется совокупность случайно отобранных однородных объектов. Генеральной совокупностью называется совокупность всех однородных объектов, из которых производится выборка. Объемом совокупности (выборочной или генеральной) называется число объектов этой совокупности. Пусть из генеральной совокупности значений некоторого количественного признака произведена выборка объема N:
X = {x1, x2, x3,..., x N}. (1)
Таблица 1- Статистический ряд
| № | … | N | |||
| x | X1 | X2 | X3 | … | XN |
Таблица вида называется простым статистическим рядом, являющимся первичной формой представления статистического материала. Размах выборки – это длина основного интервала [xmin; xmax], в который попадают все значения выборки. Вычисляется размах выборки следующим образом:
d = xmax – xmin (2)
Ряды распределения, в основе которых лежит качественный признак, называют атрибутивным. Если ряд построен по количественному признаку, его называют вариационным. При построении вариационного ряда с равными интервалами определяют его число групп ( ) и величину интервала (
) и величину интервала (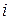 ). Оптимальное число групп может быть определено по формуле Стерджесса:
). Оптимальное число групп может быть определено по формуле Стерджесса:
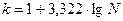 , (3)
, (3)
где 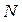 - число единиц совокупности.
- число единиц совокупности.
Данное число задает количество подынтервалов (классов), на которые разбиваем основной интервал. Длины h подынтервалов и их границы ai (i 0, k) = вычисляются по формулам:
h = d/ k (4)
Далее находятся частоты mj (j = 1, k) и относительные частоты
μj = mj /N(j 1, k) попадания значений выборки X в j-й подынтервал
x [a 0; a1) [a1; a 2) … [a k−1; a k ]. В целях визуального изучения полученных
пользуются различными способами их графического изображения. К ним
относятся гистограмма и полигон.Гистограммой относительных частот называется ступенчатая фигура, состоящая из прямоугольников, основаниями которых служат частичные подынтервалы длины h, а высоты равны числам μ j h (плотности вероятностей). Полигоном относительных частот называется ломаная, отрезки которой соединяют точки (x1; μ1); (x2; μ2); …; (xk; μk). Полигон относительных частот есть визуальное представление эмпирического закона распределения выборки. Гистограмма частот, кривая распределения и полигон частот соответственно приведены в приложениях 1,2,3.
Для построения гистограмм используются частоты, или же вероятность событий. Вероятность события - предельная относительная частота появления события при проведении серии испытаний, при неограниченном увеличении их числа. Выражается формулой:
 (5)
(5)
Определение объема выборки (для социологических, педагогических и психологических исследований)
Преимуществом же сгруппированных данных является их компактность и большая наглядность. В статистике применяются различные виды средних: арифметическая, гармоническая, квадратическая, геометрическая и структурные средние – мода и медиана. Средние, кроме моды и медианы, исчисляются в двух формах: простой и взвешенной. Выбор формы средней зависит от исходных данных и содержание определяемого показателя. Наибольшее распространение получила средняя арифметическая, как простая, так и взвешенная.
Средняя арифметическая простая равна сумме значений признака, деленной на их число:
 , (5)
, (5)
где  – значение признака (вариант);
– значение признака (вариант);
–число единиц признака.
Средняя арифметическая простая применяется в тех случаях, когда варианты представлены индивидуально в виде их перечня в любом порядке или в виде ранжированного ряда.
Если данные представлены в виде дискретных или интервальных рядов распределения, в которых одинаковые значения признака () объединены в группы, имеющие различное число единиц ( ), называемое частотой (весом), применяется средняя арифметическая взвешенная:
), называемое частотой (весом), применяется средняя арифметическая взвешенная:

(6)
Для измерения степени колеблемости отдельных значений признака от средней исчисляются основные обобщающие показатели вариации: дисперсия, среднее квадратическое отклонение и коэффициент вариации.
Дисперсия (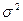 ) – это средняя арифметическая квадратов отклонений отдельных значений признака от их средней арифметической. В зависимости от исходных данных дисперсия вычисляется по формуле средней арифметической простой или взвешенной:
) – это средняя арифметическая квадратов отклонений отдельных значений признака от их средней арифметической. В зависимости от исходных данных дисперсия вычисляется по формуле средней арифметической простой или взвешенной:
 - невзвешенния (простая); (7)
- невзвешенния (простая); (7)
 - взвешенная. (8)
- взвешенная. (8)
Среднее квадратическое отклонение (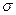 ) представляет собой корень квадратный из дисперсии и рано:
) представляет собой корень квадратный из дисперсии и рано:
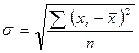 - невзвешенния; (9)
- невзвешенния; (9)
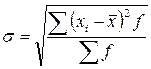 - взвешенная. (10)
- взвешенная. (10)
В отличие от дисперсии среднее квадратическое отклонение является абсолютной мерой вариации признака в совокупности и выражается в единицах измерения варьирующего признака (рублях, тоннах, процентах и т.д.).
Для сравнения размеров вариации различных признаков, а также для сравнения степени вариации одноименных признаков в нескольких совокупностях исчисляется относительный показатель вариации – коэффициент вариации (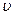 ), который представляет собой процентное отношение среднего квадратического отклонения и средней арифметической:
), который представляет собой процентное отношение среднего квадратического отклонения и средней арифметической:
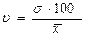 (11)
(11)
По величине коэффициента вариации можно судить о степени вариации признаков, а, следовательно, об однородности состава совокупности. Чем больше его величина, тем больше разброс значений признака вокруг средней, тем менее однородна совокупность по составу.При механическом отборе предельная ошибка выборки определяется по формуле:
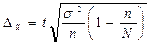 (12)
(12)
1.2 Корреляционно-регрессионный анализ
Две случайные величины могут быть связаны между собой функциональной зависимостью, либо зависимостью другого рода, называемой статистической, либо быть независимыми. Строгая функциональная зависимость для случайных величин реализуется редко, так как обе величины (или одна из них) подвержены различным случайным факторам. Пример статистической зависимости приведен в приложении 4.
Корреляционный анализ ставит задачу измерить тесноту связи между варьирующими переменными и оценить факторы оказывающие наибольшее влияние на результативный признак.
Регрессионный анализ предназначен для выбора формы связи типа модели для определения расчетных значений зависимой переменной (результативного признака).
Корреляционные связи являются не полными так как они не учитывают всех факторов от которых зависит результативный признак. Эти связи проявляются лишь в массе единиц совокупности когда индивидуальные особенности отдельных единиц взаимопогашаются.
Корреляционные связи бывают парными (простыми) и множественными. Парная корреляция характеризует зависимость результативного признака от одного а множественная – от нескольких признаков.
Наиболее разработанной в теории и широко применяемой на практике является парная корреляция когда исследуются соотношения результативного и одного факторного признаков. Это – однофакторный корреляционный и регрессионный анализ.
Для близости соотношения двух переменных используется линейный коэффициент корреляции.
Он измеряет степень линейной зависимости между двумя переменными одна из которых – результативный показатель (у) а другая – факторный (х).
 (13)
(13)
где  - средняя арифметическая факторного показателя
- средняя арифметическая факторного показателя
 - средняя арифметическая результативного показателя
- средняя арифметическая результативного показателя
 - число данных в выборке.
- число данных в выборке.
Величина коэффициента корреляции находится в пределах от -1 до +1. Наличие определенной зависимости между двумя переменными характеризуется значениями r близкими к -1 – указывает на обратную связь между признаками; близкими к +1 – на прямую связь; r = 0 - связь отсутствует. Пример положительной линейной связи приведен в приложении 5.
Качество корреляционно-регрессионного анализа обеспечивается выполнением ряда условий среди которых – однородность используемой информации значимость коэффициента корреляции надежность уравнения связи (регрессии).
Корреляционно-регрессионный анализ учитывает межфакторные связи следовательно дает нам более полное измерение роли каждого фактора: прямое непосредственное его влияние на результативный признак; косвенное влияние фактора через его влияние на другие факторы; влияние всех факторов на результативный признак. Если связь между факторами несущественна индексным анализом можно ограничиться. В противном случае его полезно дополнить корреляционно-регрессионным измерением влияния факторов даже если они функционально связаны с результативным признаком.
Корреляционный анализ является одним из методов статистического анализа взаимосвязи нескольких признаков.
Он определяется как метод применяемый тогда когда данные наблюдения можно считать случайными и выбранными из генеральной совокупности распределенной по многомерному нормальному закону. Основная задача корреляционного анализа (являющаяся основной и в регрессионном анализе) состоит в оценке уравнения регрессии.
Корреляция – это статистическая зависимость между случайными величинами не имеющими строго функционального характера при которой изменение одной из случайных величин приводит к изменению математического ожидания другой.
1. Парная корреляция – связь между двумя признаками (результативным и факторным или двумя факторными).
2. Частная корреляция – зависимость между результативным и одним факторным признаками при фиксированном значении других факторных признаков.
3. Множественная корреляция – зависимость результативного и двух или более факторных признаков включенных в исследование.
Корреляционный анализ имеет своей задачей количественное определение тесноты связи между двумя признаками (при парной связи) и между результативным признаком и множеством факторных признаков (при многофакторной связи). Степень тесноты связи в зависимости от коэффициента корреляции отражена в приложении 6.
ПРАКТИЧЕСКАЯ ЧАСТЬ
Имеются следующие выборочные данные (выборка 10%-ная, механическая) по предприятиям одной из отраслей промышленности:
Таблица 2 – Исходные данные
| № предприятия | Численность промышленно-производственного персонала, чел. | Выпуск продукции, млн. руб. | № предприятия | Численность промышленно-производственного персонала, чел. | Выпуск продукции, млн. руб. |
| 99,0 | 147,0 | ||||
| 27,0 | 101,0 | ||||
| 53,0 | 54,0 | ||||
| 57,0 | 44,0 | ||||
| 115,0 | 94,0 | ||||
| 62,0 | 178,0 | ||||
| 86,0 | 95,0 | ||||
| 19,0 | 88,0 | ||||
| 120,0 | 135,0 | ||||
| 83,0 | 90,0 | ||||
| 55,0 | 71,0 |
По исходным данным:
1. Постройте статистический ряд распределения предприятий по выпуску продукции, образовав пять групп с равными интервалами. Постройте графики ряда распределения.
2. Рассчитайте характеристики ряда распределения предприятий по выпуску продукции: среднюю арифметическую, среднее квадратическое отклонение, дисперсию, коэффициент вариации.
Сделайте выводы.
3. С вероятностью 0,955 определите ошибку выборки среднего выпуска на одно предприятие и границы, в которых будет находиться средний выпуск продукции отрасли в генеральной совокупности.
1. Сначала определим длину интервала :

Таблица 3- Сгруппированные данные по рассчитанным интервалам
| № группы | Группировка предприятий по выпуску продукции | № предприятия | Выпуск продукции |
| I | 19,0-50,8 | 19,0 | |
| 27,0 | |||
| 44,0 | |||
| II | 50,8-82,6 | 53,0 | |
| 54,0 | |||
| 55,0 | |||
| 57,0 | |||
| 62,0 | |||
| 71,0 | |||
| III | 82,6-114,4 | 83,0 | |
| 86,0 | |||
| 88,0 | |||
| 90,0 | |||
| 94,0 | |||
| 95,0 | |||
| 99,0 | |||
| 101,0 | |||
| IV | 114,4-146,2 | 115,0 | |
| 120,0 | |||
| 135,0 | |||
| V | 146,2-178,0 | 147,0 | |
| 178,0 |
2. Рассчитываем характеристику ряда распределения предприятий по выпуску продукции.
Таблица 4- Характеристика ряда распределений
| Выпуск продукции, млн. руб. | Число
предприятий,
| Середина
интервала,

| 
| 
| 
|
| 19,0-50,8 | 34,9 | 104,7 | 3177,915 | 9533,745 | |
| 50,8-82,6 | 66,7 | 66,7 | 603,832 | 3622,992 | |
| 82,6-114,4 | 98,5 | 98,5 | 52,230 | 417,84 | |
| 114,4-146,2 | 130,3 | 130,3 | 1523,107 | 4569,321 | |
| 146,2-178,0 | 162,1 | 162,1 | 5016,464 | 10032,928 |


Среднеквадратическое отклонение:

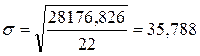
Дисперсия:


Коэффициент вариации:


Выводы.
1.Средняя величина выпуска продукции на предприятии составляет 91,273 млн. руб.
2.Среднеквадратическое отклонение показывает, что значение признака в совокупности отклоняется от средней величины в ту или иную сторону в среднем на 35,788 млн. руб.
3. Определяем ошибку выборки.
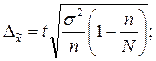

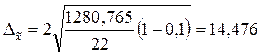


С вероятностью 0,954 можно сказать, что средний выпуск продукции в генеральной совокупности находится в пределах от 76,797 млн. руб. до 105,749 млн. руб.