Классификация баз данных
По технологии обработки данных базы данных подразделяются на централизованные и распределенные. Централизованная база данных хранится в памяти одной вычислительной системы. Если эта вычислительная система является компонентом сети ЭВМ, возможен распределенный доступ к такой базе. Такой способ использования баз данных часто применяют в локальных сетях.
Распределенная база данных состоит из нескольких, возможно пересекающихся или даже дублирующих друг друга частей, хранимых в различных ЭВМ вычислительной сети. Работа с такой базой осуществляется с помощью системы управления распределенной базой данных (СУРБД).
По способу доступа к данным базы данных разделяются на базы данных с локальным доступом и базы данных с удаленным (сетевым) доступом. Системы централизованных баз данных с сетевым доступом предполагают различные архитектуры подобные
· файл-сервер; · клиент-сервер
Файл-сервер - архитектура систем БД с сетевым доступом предполагает выделение одной из машин сети в качестве центральной (сервер файлов) На такой машине хранится совместно используемая централизованная БД. Все другие машины сети выполняют функции рабочих станций, с помощью которых поддерживается доступ пользовательской системы к централизованной базе данных. Файлы базы данных в соответствии с пользовательскими запросами передаются на рабочие станции, где в основном и производится обработка. При большой интенсивности доступа к одним и тем же данным производительность информационной системы падает. Пользователи могут создавать также на рабочих станциях локальные БД, которые используются ими монопольно.
Клиент-сервер. В этой концепции подразумевается, что помимо хранения централизованной базы данных центральная машина (сервер базы данных) должна обеспечивать выполнение основного объема обработки данных. Запрос на данные, выдаваемый клиентом порождает поиск и извлечение данных на сервере. Извлеченные данные (но не файлы) транспортируются по сети от сервера к клиенту. Спецификой архитектуры клиент-сервер является использование языка запросов SQL.
Виды моделей данных.
Ядром любой базы данных является модель данных. Модель данных представляет собой множество структур данных, ограничений целостности и операций манипулирования данными. С помощью модели данных могут быть представлены объекты предметной области и взаимосвязи между ними.
Модель данных - совокупность структур данных и операций их обработки.
СУБД основывается на использовании иерархической, сетевой или реляционной модели, на комбинации этих моделей или на некотором их подмножестве. Рассмотрим три основных типа моделей данных иерархическую, сетевую и реляционную.
Иерархическая модель данных
Иерархическая структура представляет совокупность элементов, связанных между собой по определенным правилам. Объекты, связанные иерархическими отношениями, образуют ориентированный граф (перевернутое дерево), вид которого представлен ниже на рис. К основным понятиям иерархической структуры относятся: уровень, элемент (узел), связь. Узел - это совокупность атрибутов данных, описывающих некоторый объект. На схеме иерархического дерева узлы представляются вершинами графа. Каждый узел на более низком уровне связан только с одним узлом, находящимся на более высоком уровне. Иерархическое дерево имеет только одну вершину (корень дерева), не подчиненную никакой другой вершине и находящуюся на самом верхнем (первом) уровне. Зависимые (подчинённые) узлы находятся на втором, третьем и т.д. уровнях. Количество деревьев в базе данных определяется числом корневых записей.
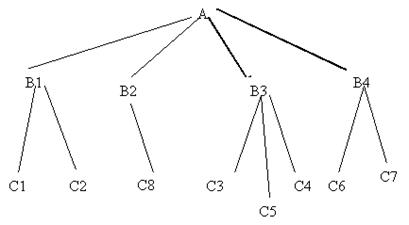
К каждой записи базы данных существует только один (иерархический) путь от корневой записи. Например, как видно из рис. 2, для записей С4 путь проходит через записи А и В3
Сетевая модель данных
В сетевой структуре при тех же основных понятиях (уровень, узел, связь) каждый элемент может быть связан с любым другим элементом. На рис. изображена сетевая структура базы данных в виде графа

Реляционная модель данных
Понятие реляционный (англ. rе1аtion - отношение) связано с разработками известного американского специалиста в области систем баз данных Е Кодда. Эти модели характеризуются простотой структуры данных, удобным для пользователя табличным представлением и возможностью использования формального аппарата алгебры отношений и реляционного исчисления для обработки данных.
Реляционная модель ориентирована на организацию данных в виде двумерных таблиц. Каждая реляционная таблица представляет собой двумерный массив и обладает следующими свойствами:
· каждый элемент таблицы - один элемент данных;
· все столбцы в таблице однородные, т.е. все элементы в столбце имеют одинаковый тип (числовой, символьный и т.д.) и длину;
· каждый столбец имеет уникальное имя;
· одинаковые строки в таблице отсутствуют;
· порядок следования строк и стол6цов может быть произвольным.
Понятие нормализации отношений
Одни и те же данные могут группироваться в таблицы (отношения) различными способами. Группировка атрибутов в отношениях должна быть рациональной, т.е. минимизирующей дублирование данных и упрощающей процедуры их обработки и обновления.
Определенный набор отношений обладает лучшими свойствами при включении, модификации, удалении данных, чем все остальные возможные наборы отношений, если он отвечает требованиям нормализации отношений.
Нормализация отношений - формальный аппарат ограничений на формирование отношений (таблиц), который позволяет устранить дублирование, обеспечивает непротиворечивость хранимых в базе данных, уменьшает трудозатраты на ведение (ввод, корректировку) базы данных. В.Коддом выделены три нормальные формы отношений и предложен механизм, позволяющий любое отношение преобразовать к третьей (самой совершенной нормальной форме).
Первая нормальная форма. Отношение называется нормализованным или приведенным к первой нормальной форме, если все его атрибуты простые (далее неделимы). Преобразование отношения к первой нормальной форме может привести к увеличению количества реквизитов (полей) отношения и изменению ключа. Например, отношение Студент (номер, Фамилия, Имя, Отчество, Дата, Группа) находится в первой нормальной форме.
Вторая нормальная форма. Чтобы рассмотреть вопрос приведения отношений ко второй нормальной форме, необходимо дать пояснения к таким понятиям, как функциональная зависимость и полная функциональная зависимость. Описательные реквизиты информационного объекта логически связаны с общим для них ключом, эта связь носит характер функциональной зависимости реквизитов. Функциональная зависимость реквизитов - зависимость, при которой в экземпляре информационного объекта определенному значению ключевого реквизита соответствует только одно значение описательного реквизита. Такое определение функциональной зависимости позволяет при анализе всех взаимосвязей реквизитов предметной области выделить самостоятельные информационные объекты. В случае составного ключа вводится понятие функционально полной зависимости. Функционально полная зависимость не ключевых атрибутов заключается в том что каждый не ключевой атрибут функционально зависит от ключа, но не находится в функциональной зависимости ни от какой части составного ключа. Отношение будет находиться во второй нормальной форме, если оно находится в первой нормальной форме, и каждый не ключевой атрибут функционально полно зависит от составного ключа.
Пример1: Отношение Студент = (Номер, Фамилия, Имя, Отчество, Дата, Группа) находится в первой и во второй нормальной форме одновременно, так как описательные реквизиты однозначно определены и функционально зависят от ключа Номер.
Пример2: Отношение Успеваемость - (Номер, Фамилия, Имя, Отчество, Дисциплина, Оценка) находится в первой нормальной форме и имеет составной ключ Номер+ Дисциплина. Это отношение не находится во второй нормальной форме так как атрибуты Фамилия, Имя, Отчество не находятся в функционально полной зависимости от составного ключа.
Третья нормальная форма. Понятие третьей нормальной формы основывается на понятии нетранзитивной зависимости. Транзитивная зависимость наблюдается в том случае, если один из двух описательных реквизитов зависит от ключа, а другой описательный реквизит зависит от первого описательного реквизита. Отношение будет находиться в третьей нормальной форме, если оно находится во второй нормальной форме, и каждый не ключевой атрибут нетранзитивно зависит от первичного ключа.
Пример. Если в состав описательных реквизитов информационного объекта Студент включить фамилию старосты группы (Староста), которая определяется только номером группы, то одна и та же фамилия старосты будет многократно повторяться в разных экземплярах данного информационного объекта. В этом случае наблюдаются затруднения в корректировке фамилии старосты в случае назначения нового старосты, а также неоправданный расход памяти для хранения дублированной информации. Для устранения транзитивной зависимости описательных реквизитов необходимо провести "расщепление" исходного информационного объекта. В результате расщепления часть реквизитов удаляется из исходного информационного объекта и включается в состав других (возможно, вновь созданных) информационных объектов.
Реляционные БД
БД, основанные на использовании реляционных моделей данных, называются реляционными БД.
Простейшая база данных имеет хотя бы одну таблицу. Структуру двумерной таблицы образуют столбцы и строки. Их аналогами в базе данных являются поля и записи. Поле (столбец) – набор одной и той же характеристики (например, номер телефона) для нескольких объектов. Запись (строка)- набор нескольких характеристик (например, табельный номер, фамилия, телефон, адрес, должность и др.) для одного и того же объекта.
Разработка структуры реляционной базы данных
1. Составление генерального списка полей (м.б. десятки и даже сотни полей).
2. Определяют наиболее подходящий тип данного для каждого поля.
3. Разделяют поля генерального списка по базовым таблицам. На первом этапе разделение производят по функциональному признаку (цель - обеспечить ввод данных в одну таблицу на одном рабочем месте). На втором этапе приступают к дальнейшему делению таблиц. При этом целью деления является исключение повторяющихся записей в таблице.
4. В каждой из таблиц намечают ключевое поле. Ключевое поле – это поле, которое однозначно определяет каждую запись в таблице. Например, для таблицы данных о студентах таким полем может служить индивидуальный шифр студента.
Если такого поля нет, то в качестве ключа можно выбрать комбинацию полей, которая также однозначно определяет каждую запись в таблице. Например, для таблицы, в которой содержатся расписания занятий, в качестве ключа можно выбрать комбинацию полей "Время занятий" и "Номер аудитории". Эта комбинация неповторима (т.к. в одной аудитории в одно и то же время не идут разные занятия).
Если в таблице вообще нет никаких полей, которые можно было бы использовать как ключевые, всегда можно ввести дополнительное поле типа "Счетчик": оно не может содержать повторяющихся данных по определению.
5. Устанавливаются связи между таблицами. Связанные таблицы называют схемой данных. Существует несколько типов возможных связей между таблицами. Наиболее распространенными являются связи "один ко многим" и " один к одному". Связь между таблицами организуется на основе общего поля, причем в одной из таблиц оно обязательно д.б. ключевым, т.е. на стороне "один" должно выступать ключевое поле, содержащее уникальные, неповторяющиеся значения. Значения на стороне "Многие" могут повторяться
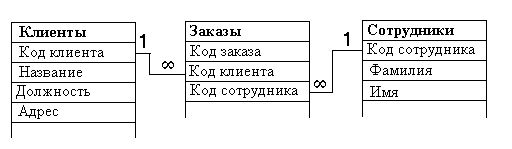
Про подобные таблицы говорят, что они связаны реляционными отношениями. Системы управления, способные работать со связанными таблицами, называют системами управления реляционными базами данных.
Итак, в реляционной базе данных используется несколько разных таблиц, между которыми устанавливаются связи (relation). Они позволяют ввести информацию в одной таблице и связать ее с записями другой через специальный идентификатор. При этом сокращается общее количество информации, хранимой в базе данных, поскольку в записях повторяются уже не сами данные, а только идентификаторы для связывания.