Лабораторная работа № 1
Анализ статистических свойств и моделирование источников
сообщений
Краткие теоретические сведения
 |
Теория информации оперирует событиями окружающей человека действительности на таком уровне абстракции, на котором физическая сторона явлений становится несущественной. Все происходящее представляет интерес только в том смысле, в котором позволяет получить новые сведения об изучаемом предмете - информацию. Общность подобного рода может быть достигнута, если в основу описания наблюдаемых явлений положить понятие источника сообщений (ИС). Источник сообщений можно представить в виде некого устройства, которое устанавливает взаимосвязь между физической сущностью объекта наблюдения и его информационными характеристиками (рис. 1). На вход источника сообщений может поступать произвольная физическая величина W, характеризующая объект наблюдения, а на его выходе формируется последовательность состояний принадлежащих некоторому множеству X. Параметры носителя, изменяемые во времени в соответствии с передаваемым сообщением, называют информативными. В зависимости от структуры множества выходных состояний источника сообщений различают непрерывные и дискретные ИС. Источник сообщений считают дискретным по данному параметру, если число значений, которое может принимать этот параметр, конечно. Если множество возможных значений параметра образует континиум, то ИС считают непрерывным по данному параметру. Источник сообщений, дискретный по одному параметру и непрерывный по другому, называют дискретно-непрерывным. Для дискретных источников алфавит задается в виде дискретного множества
 причем
причем  ,
,
где xi – состояния ИС, p (xi) – вероятности соответствующих состояний, n – число состояний. Для непрерывных источников подобное представление невозможно, так как множество их состояний бесконечно. Это приводит к тому, что вероятность каждого состояния в отдельности стремится к нулю. Непрерывное множество состояний принято характеризовать функцией плотности распределения вероятностей (ФПВ). При этом алфавит непрерывного источника может быть представлен в следующем виде
 ,
,
где x – случайная величина, характеризующая поведение источника, f (x) – ФПВ случайной величины x.
 |
Примером дискретного источника сообщений может служить игральная кость. Шесть пронумерованных граней кости образуют ансамбль из шести состояний: x 1, …, x 6. Вероятности появления данных состояний равны: p (x 1) = p (x 2) = … = p (x 6) = 1/6 (рис. 2,а). Другой пример дискретного источника с равновероятными состояниями – монета. В этом случае число состояний n равно 2, а вероятности равны 1/2. Пример объекта наблюдения, для которого источник сообщений имеет состояния с различными вероятностями – бутерброд, число состояний которого также равно двум, а вероятности данных состояний различны (вероятность падения бутерброда маслом вниз выше, рис. 2,б). Примером непрерывного источника сообщений может служить термометр для измерения температуры человека. Источник сообщений, построенный на основе подобного объекта наблюдения, будет иметь непрерывное множество значений, поскольку температура тела может принимать любое значение, хотя и на ограниченном интервале. Причем очевидно, что плотность вероятности появления значений вблизи нормальной температуры выше, чем повышенных или пониженных значений (рис. 2,в).
Изменение состояния объекта наблюдения во времени принято связывать с реализацией источником сообщения того или иного символа алфавита - xi для дискретных источников или значения случайной величины x для непрерывных. Следует отметить, что как для дискретных источников сообщений, так и для непрерывных, изменение состояния может происходить как в определенные моменты времени, так и в произвольные.


В соответствии с этим существуют следующие разновидности математических представлений (моделей) сигнала:
- дискретная функция дискретного аргумента, например функция, принимающая одно из конечного множества возможных значений (уровней) в определенные моменты времени (рис. 3,а);
- дискретная функция непрерывного аргумента, например функция времени, квантованная по уровню (рис. 3,б);
- непрерывная функция дискретного аргумента, например функция, значения которой отсчитывают только в определенные моменты времени (рис. 3,в);
- непрерывная функция непрерывного аргумента, например непрерывная функция времени (рис. 3,г).
В силу цифровой природы современных средств вычислительной техники наибольший интерес представляет случай, представленный на рис. 3,а (дискретный источник с дискретным временем). Остальные варианты ИС могут быть сведены к данному путем использования операций дискретизации и квантования, которые подразумевают получение оценок случайной величины x через достаточно малые промежутки времени и сопоставление данных оценок ближайших значений состояния источника xi. Например, объект наблюдения непрерывной природы можно представить в виде дискретного источника сообщений следующим образом. Зададимся верхней и нижней границами возможных значений температуры: Tверх = 40oC, Tниж = 35oС, а также достаточной погрешностью ее измерения D T = 0.1oC. Тогда число состояний соответствующего ИС: n = (Tверх - Tниж)/ D T = (40 – 35)/0.1 = 50. Для реальных объектов наблюдения представление в виде дискретного ИС с достаточной точностью может потребовать десятков и даже сотен тысяч состояний. Характеризовать подобные источники, непосредственно указывая вероятности каждого состояния, весьма неудобно. Кроме того, значения данных вероятностей получаются очень малыми, что затрудняет наглядность оценки статистических свойств источника. Избежать недостатков непосредственного подхода позволяет переход к характеристике источника в виде усредненных статистических характеристик. К числу наиболее распространенных из них можно отнести:
- максимальное и минимальное значения: xmax, xmin;
- функцию плотности распределения вероятностей f (x);
- математическое ожидание M (X) и дисперсию D (X), которые для дискретных источников вычисляются соответственно по формулам
 ,
,  ,
,
а для непрерывных
 ,
,  ;
;
- среднеквадратическое отклонение (СКО) s (X):
 .
.
Особое практическое значение имеют две взаимообратных задачи. Одна из них связана с вопросом анализа статистических характеристик источника сообщений по последовательности реализаций его состояний во времени. Другая задача – задача синтеза (моделирования) ИС либо в соответствии с заданным объектом наблюдения, либо в соответствии с заданными статистическими характеристиками.
Задача анализа обычно ставится следующим образом. Имеется последовательность реализаций состояний, полученная от анализируемого источника. Определить основные статистические характеристики указанного ИС. В упрощенном виде алгоритм решения данной задачи можно разбить на следующие этапы.
1. Находятся максимальное и минимальное значения в последовательности реализаций.
2. Вычисляется значение выборочного среднего как оценки математического ожидания  , дисперсии
, дисперсии 
и СКО 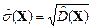 , где xj – последовательность реализаций, k – общее число известных реализаций (объем выборки).
, где xj – последовательность реализаций, k – общее число известных реализаций (объем выборки).
{ == Получение статистических оценок == }
Procedure Otcenki(const x: array [1..N] of extended;
var Mx,Dx:extended);
Var
i:integer;
Begin
Mx:=0; Dx:=0;
For i:=1 to N do Mx:=Mx+x[i];
Mx:=Mx/N;
For i:=1 to N do Dx:=Dx+Sqr(x[i]-Mx);
Dx:=Dx/N;
End;
3. Строится гистограмма как оценка ФПВ.
 |
Для построения гистограммы весь интервал значений от xmin до xmax разбивается на N равных частей Dxj (рис. 4). Далее, подсчитывается число попавших в каждый интервал реализаций Q (Dxj). Для наглядности число попаданий представлено в виде графика в левой части рис. 4. Подсчитываются вероятности попадания реализаций в каждый интервал
(X)+s(X)  при
при  .
. 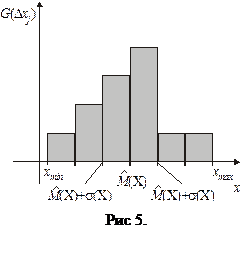
Вычисляются значения гистограммы
 при
при  .
.
Данные значения используются для построения графика гистограммы (рис. 5). На этом же графике откладываются значения  и
и  , которые характеризуют разброс реализаций относительно среднего значения. При увеличении числа опытов можно задавать более мелкие интервалы Dxj. При этом гистограмма приближается к ФПВ
, которые характеризуют разброс реализаций относительно среднего значения. При увеличении числа опытов можно задавать более мелкие интервалы Dxj. При этом гистограмма приближается к ФПВ  .
.
{ == Процедура построения гистограммы == }
Procedure Histogr(const Data: array [1..MaxK] of
extended);
Var
mx,my,x0,y0,x,hgt,wdt,i,Step:word;
MaxX,Sc:extended;
s:string;
Begin { Histogr }
mx:=GetMaxX; { размер экрана по горизонтали }
my:=GetMaxY; { размер экрана по вертикали }
x0:=16; { Начало координат }
y0:=my-16;
wdt:=mx-2*16;{ Ширина гистограммы по горизонтали}
hgt:=my-2*16;{ Ширина гистограммы по вертикали }
MaxX:=Data[1]; { Определяем масштабный коэффициент}
For i:=2 to MaxK do
If Data[i]>MaxX
then MaxX:=Data[i];
Sc:=hgt/MaxX;
Step:=Trunc(wdt/MaxK);
ClearDevice; { Рисуем гистограмму }
SetColor(White);
SetFillStyle(SolidFill,Blue);
SetTextStyle(DefaultFont,VertDir,1);
x:=x0;
For i:=1 to MaxK do begin
mx:=x+Step;
my:=Trunc(Sc*Data[i]);
Rectangle(x,y0,mx,y0-my);
Bar(x+1,y0-1,mx-1,y0-my+1);
Str(Data[i]:5:3,s);
If my>7*8
then OutTextXY(x+12,y0-my+4,s)
else OutTextXY(x+12,y0-my-6*8,s);
x:=mx
end;
ReadLn { Пауза }
End; { Histogr }
Задача моделирования источника сообщений обычно сводится к получению последовательности реализаций, статистические характеристики которой соответствуют заданным характеристикам ИС. Последние могут быть заданы в виде ансамбля состояний с соответствующими вероятностями (случай дискретного источника) либо в виде аналитически определенной ФПВ (случай непрерывного источника). Процесс моделирования указанных ИС может существенно различаться. Однако в его основу обычно кладется принцип получения требуемого распределения вероятностей реализаций (ФПВ в случае непрерывного источника) по известному распределению. В качестве известного, как правило, выбирается равномерное распределение. Генератор случайной величины, распределенной по равномерному закону, реализован в любом современном языке программирования, поэтому решение задачи синтеза ИС направлено на поиск преобразования равномерного распределения в заданное.
Моделирование ИС обычно подразумевает аналитическое представление ФПВ. При этом задача моделирования, главным образом, заключается в поиске требуемой передаточной функции x = W (r), где r – случайная величина с равномерным распределением. Обычно в качестве подобной функции выступает функция обратная интегральному закону распределения (ИЗР) F (x). ИЗР может быть найден для заданной ФПВ f (x) посредством несложного выражения  .
.
 |
Остается найти такую функцию F -1(x), что если истинно выражение r = F (x), то истинно и обратное утверждение: x = F -1(r). Другими словами, необходимо выразить значение аргумента через значение функции ИЗР. Наглядно данный процесс представлен на рис. 6, где изображены графики для произвольной ФПВ, соответствующего ИЗР (рис. 6 а), а также обратного ИЗР (рис. 6,б). Для большинства известных законов распределения задача получения функции F -1(r) решена.
Таким образом, процедура получения значений случайной величины с заданной функцией распределения F (r) заключается в следующем:
1. реализация случайной величины r, равномерно распределенной на интервале [0,1);
2. вычисление значений случайной величины x по формуле  .
.
Ниже приведены сведения о некоторых, наиболее распространенных ФПВ и соответствующих им передаточных функциях.
Источник сообщений с равномерной ФПВ на произвольном интервале распределения от a до b
 ;
;
.
ИЗР для рассматриваемой случайной величины x имеет вид

Согласно методу обратных функций
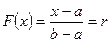 .
.
Откуда
 ,
,
где r - случайная величина, равномерно распределенная на интервале [0,1).
Таким образом, реализации подобного источника могут быть получены при помощи обратного ИЗР  , при
, при  , где J – число реализаций.
, где J – число реализаций.
Пример. Составить программу моделирования случайной величины Х, равномерно распределенной на интервале [ a, b).
Program RavnAB;
Var
a,b,r,x:real;
N,i:word;
Begin
Write(’Задайте границы интервала а и b:’);
ReadLn(a,b);
Write(’Количество случайных чисел N:’);
ReadLn(N);
Randomize;
For i:=1 to N do begin
r:=Random;
x:=a+r*(b-a);
WriteLn(’x’,i:5,’=’,x:5:3); {обработка x}
end;
WriteLn(’Моделирование завершено’);
End.
Источник сообщений с нормальной ( гауссовой ) ФПВ.
 ,
,
где s - среднеквадратическое отклонение, а M (X) – математическое ожидание случайной величины x. Для нормальной ФПВ с параметрами M (X) = 0, s = 1 можно записать, воспользовавшись аппроксимацией
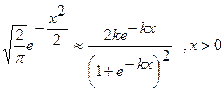 , где
, где  .
.
Тогда для положительной полуоси можно получить следующую аппроксимацию
 .
.
Обратная функция имеет вид
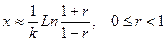 .
.
В общем случае x распределена на интервале от -¥ до ¥, что не позволяет производить моделирование непосредственно, используя обратный ИЗР. Однако возможно использование приближенной формулы, основанной на центральной предельной теореме
 , при .
, при .
Для случая, когда M (X) и s имеют другие значения, требуемый закон распределения можно получить использовав линейное преобразование  , где x in – нормально распределенная случайная величина с параметрами M (X)=0, s =1, а x out нормально распределенная случайная величина с заданными параметрами M (X) и s.
, где x in – нормально распределенная случайная величина с параметрами M (X)=0, s =1, а x out нормально распределенная случайная величина с заданными параметрами M (X) и s.
Источник сообщений с экспоненциальной ФПВ
 , l > 0,
, l > 0,
может быть смоделирован с помощью метода обратного ИЗР.
 .
.
Согласно методу обратных функций
 .
.
Получим
 ;
;
 ;
;
 .
.
Так как случайная величина  имеет то же самое распределение, что и r, то при нахождении значений случайной величины x пользуются формулой
имеет то же самое распределение, что и r, то при нахождении значений случайной величины x пользуются формулой 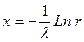 .Соответствующая функция имеет вид
.Соответствующая функция имеет вид  , при .
, при .
При моделировании необходимо учитывать возможность появления значений случайной величины r близких к 0. При этом указанное выражение может принимать значения, стремящиеся к бесконечности, а, следовательно, возможно появление ошибок переполнения. Во избежание ошибок подобного рода необходимо ограничить с помощью проверки множество значений величины r снизу некоторой малой величиной (например, 0.01).
Источник сообщений с ФПВ распределенной по закону Вейбулла
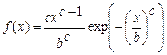 ,
,
где 0£ x <¥; c >0; b >0; b, c – целые, может быть смоделирован путем использования следующего обратного ИЗР
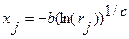 .
.
Здесь, значение величины r должно быть также ограничено снизу малой величиной.
Источник сообщений с логарифмически-нормальной ФПВ
 ,
,
где c > 0 моделируется с помощью следующего выражения
 ,
,
где yj – случайная величина, распределенная по нормальному закону с параметрами M (X) = 0, s = 1.
Обобщим результаты, а также приведем данные для других законов распределения:
| Название закона распределения | ФПВ | Случайная величина |
| Равномерный | 
| 
|
| Экспоненциальный | 
| 
|
| Нормальный | 
| 
|
| Логарифмически-нормальный | 
| 

|
| Вейбулла | 
| 
|
| Лапласа |  , l > 0 , l > 0
| 
|
| Коши | 
| 
|
| Симпсона |  , 0< x < a , 0< x < a
| 
|
| Прямоугольного треугольника |  , 0< x < a , 0< x < a
| 
|
| Параболы |  , 0< x < a , 0< x < a
| 
|
Задание
В лабораторной работе требуется смоделировать непрерывный источник сообщений в соответствии с параметрами, заданными в таблице, произвести вычисление оценок его основных статистических характеристик: xmax, xmin, 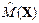 ,
, 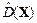 и
и 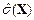 , а также построить гистограмму распределения вероятностей.
, а также построить гистограмму распределения вероятностей.
| № п/п | Закон распределения случайной величины |
| Равномерный (a =1, b =3) | |
| Экспоненциальный (l =2) | |
| Нормальный (M (X) = 0, s = 1) | |
| Логарифмически-нормальный (c =2) | |
| Вейбулла (b =3, c =2) | |
| Лапласа | |
| Коши (a =2.5) | |
| Симпсона (a =2.5) | |
| Прямоугольного треугольника (a =3) | |
| Параболы (a =0.25) | |
| Равномерный (a =0, b =5) | |
| Экспоненциальный (l =1.2) | |
| Нормальный (M (X)=2, s = 1.5) | |
| Логарифмически-нормальный (c =1.5) | |
| Вейбулла (b =2.5, c =2) | |
| Лапласа | |
| Коши (a =1.5) | |
| Симпсона (a =1.75) | |
| Прямоугольного треугольника (a =3.2) | |
| Параболы (a =0.6) |
Рекомендации по выполнению работы
Лабораторную работу рекомендуется выполнять в следующем порядке.
1. Формируется массив реализаций случайной величины r, распределенной по равномерному закону на интервале от 0 до 1. Для этого используется встроенный датчик случайных чисел. Объем массива J не менее 1000 элементов.
2. В соответствии с заданным вариантом производится моделирование непрерывного ИС с требуемым законом распределения.
3. Вычисляются оценки статистических характеристик и параметров гистограммы для массива реализаций смоделированного непрерывного источника. На графике гистограммы строится для сравнения аналитическая форма ФПВ f (x). Число шагов гистограммы выбирается не более (10…15).
Лабораторная работа № 2
Изучение методов рационального кодирования
Сообщений
Краткие теоретические сведения
 |
Одной из основных задач, которую приходится решать при проектировании любой информационной системы, является передача информации от источника сообщений к получателю. В упрощенном виде структурная схема системы передачи информации может быть представлена так, как показано на рис. 1,а. Функционирование системы в данном виде возможно только тогда, когда алфавит источника сообщений совпадает с алфавитом входных состояний канала связи. На практике алфавит канала связи выбирается исходя из нескольких требований:
- передача сообщений от нескольких источников сообщений с различными ансамблями состояний;
- обеспечение максимальной помехоустойчивости передаваемых сообщений;
- простота технической реализации.
Выполнение данных требований приводит к тому, что непосредственная передача сообщений от источника по каналу связи становится невозможной. Возникает необходимость преобразования алфавита источника в алфавит входных состояний канала связи на передающей стороне и алфавита канала связи в алфавит получателя сообщений на приемной стороне. Прямое преобразование носит название процесса кодирования и осуществляется в кодере источника (рис. 1,б). Обратное преобразование называется декодированием и осуществляется с помощью декодера. Пару устройств кодер-декодер называют кодеком.
Современные информационные системы используют для передачи информации главным образом двоичные каналы связи. Алфавит состояний такого канала включает только два символа: 0 и 1. Процесс кодирования сообщений в этом случае заключается в представлении множества состояний источника в двоичной форме. Число символов, требующихся для кодирования одного сообщения, связано с числом сообщений источника следующим образом: L = log2 n, где n – число состояний источника. Если n не кратно степени числа 2, то L округляется в большую сторону. Пример двоичного кодирования источника с 8-ю состояниями приведен в табл. 1. Здесь L = log28 = 3.
Таблица 1
| xi | x1 | x2 | x3 | x4 | x5 | x6 | x7 | x8 |
| Код |
Следует отметить, что предыдущие рассуждения относились к источнику, для которого известно только число состояний, а их вероятности полагались равными. Более сложное описание дискретного источника сообщений в виде ансамбля состояний с различными вероятностями

подразумевает, что количество информации, получаемой при реализации различных состояний, может быть разным. Другими словами, имеется некоторая априорная (известная заранее) информация о возможности реализации того или иного состояния, которая позволяет предсказывать возможный исход эксперимента, уменьшая количество получаемой информации. В этом случае говорят об избыточности источника. Избыточность принято характеризовать показателями относительной энтропии и коэффициентом избыточности. Относительная энтропия m характеризует количество устраняемой неопределенности по отношению к максимально возможной и может быть найдена следующим образом:
 ,
,
где H (X) – энтропия источника с заданным ансамблем, а H max(X) – максимальная энтропия источника с данным числом состояний. Первый показатель вычисляется посредством меры Шеннона, а второй – меры Хартли:
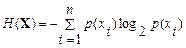 ,
,
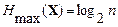 .
.
Коэффициент избыточности r характеризует степень избыточности источника
 .
.
Если r = 0, то имеет место источник сообщений с равновероятными состояниями, для которого информативность состояний максимальна. Иначе (r > 0) имеет место избыточность источника сообщений.
Избыточность источника сообщений приводит к тому, что в результате кодирования получается избыточный код. То есть каждый символ кодовой последовательности несет количество информации отличное от максимально возможного. Этот факт связан с тем, что сообщения источника, имеющие большую вероятность реализации (менее информативные сообщения), появляются чаще, а для их кодирования используется такая же длительность кодовой комбинации, как и для остальных. Естественной была бы ситуация, при которой менее информативные (часто встречающиеся) сообщения кодировались бы меньшим числом символов, чем более информативные. Методы кодирования, позволяющие устранить избыточность сообщений источника, называют методами рационального кодирования.
Одним из наиболее простых методов рационального кодирования является метод Шеннона-Фано. Кодовые комбинации, для соответствующих состояний источника находятся следующим образом. Состояния источника сообщений ранжируются в порядке убывания их вероятностей. Весь алфавит источника сообщений делится на две группы таким образом, чтобы суммарные вероятности сообщений каждой группы были примерно одинаковы. Далее, каждому состоянию из одной группы ставится в соответствие символ 1, а другой – 0. Там для каждой группы снова производится разбиение на равновероятные подгруппы и так далее до тех пор, пока в каждой подгруппе не останется по одному символу. Рассмотрим в качестве примера процесс построения кодовых комбинаций для источника с 8-ю состояниями (табл. 2).
Таблица 2
| xi | p (xi) | прямой код | 1-й шаг | 2-й шаг | 3-й шаг | 4-й шаг | 5-й шаг | 6-й шаг | 7-й шаг | Код Ш-Ф |
| x 1 | 1/2 | 1/2 | ||||||||
| x 2 | 1/4 | 1/2 | 1/4 | |||||||
| x 3 | 1/8 | 1/4 | 1/8 | |||||||
| x 4 | 1/16 | 1/8 | 1/16 | |||||||
| x 5 | 1/32 | 1/16 | 1/32 | |||||||
| x 6 | 1/64 | 1/32 | 1/64 | |||||||
| x 7 | 1/128 | 1/64 | 1/128 | |||||||
| x 8 | 1/128 | 1/128 |
Из табл. 2 видно, что максимальную длину имеют кодовые комбинации с минимальной вероятностью. Энтропия источника, рассчитанная с помощью меры Шеннона:
 .
.
Предельная энтропия для источника сообщений с 8-ю состояниями в соответствии с мерой Хартли:
 .
.
Относительная энтропия m = H (X)/Hmax(X) » 1/3. Коэффициент избыточности r = 1 - m » 2/3.
Преимущество рационального кодирования по сравнению с прямым можно охарактеризовать величиной средней длительности кодовой комбинации
 ,
,
где L (xi) – длина кодовой комбинации для символа xi. В соответствии с данным выражением Lm = 127/64 » 2. То есть при использовании кода Шеннона-Фано для источника с указанным распределением вероятностей средняя длина кодовой комбинации равна двум символам, тогда как при прямом кодировании – трем. Это позволяет сократить объем передаваемой информации более чем на 30 %.
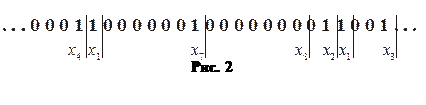
Процесс декодирования непрерывной последовательности кодовых комбинаций основан на процедуре накопления получаемых символов до тех пор, пока не будет принят символ 1 или длина последовательности нулей не станет равной 7. Пример декодирования кодовой последовательности приведен на рис. 2. Здесь вертикальные отметки показывают момент принятия решения о получении соответствующего символа.
Одним из существенных недостатков описанного метода кодирования является его слабая формализуемость. В самом деле, поиск наилучшего варианта разбиения методом прямого перебора возможных сочетаний при сколь-нибудь значительном числе состояний является ресурсоемкой вычислительной задачей. Кроме того, не все сочетания символов являются разрешенными. Например, крайне нежелательно объединение в группу двух состояний, одно из которых имеет гораздо большую вероятность, чем другое. В этом случае для их передачи потребуется одинаковое число символов, что не соответствует принципам рационального кодирования.
От указанных недостатков свободен другой метод рационального кодирования – метод Хаффмана. Кодовые комбинации для данного метода могут быть получены в соответствии со следующим алгоритмом. Состояния источника ранжируются в порядке убывания их вероятностей. Два состояния, имеющие минимальные вероятности, объединяются в одно, вероятность которого равна сумме вероятностей объединяемых состояний. В результате объединения получается новый набор состояний, число которых на единицу меньше первоначального. Полученные состояния снова ранжируются. Операция объединения повторяется. Так продолжается до тех пор, пока в результате объединения не будет получено одно состояние с вероятностью 1. На основании результатов объединения состояний строится бинарное кодовое дерево. Узлам данного кодового дерева сопоставляются вероятности объединяемых состояний, а ветвям– символы 0 или 1.
Пример описанного алгоритма для дискретного источника сообщений, имеющего 8 состояний, представлен на рис. 3, а полученное кодовое дерево – на рис. 4. Для получения кодовой комбинации для состояния xi необходимо найти путь, ведущий от корня кодового дерева до узла, соответствующего данному состоянию. Последовательность ветвей, образующих путь, указывает на последовательность

Рис. 3
символов 0 и 1 в кодовой комбинации. Для указанного примера кодовые комбинации приведены в табл. 3. Нетрудно заметить, что выполняется основное правило рационального кодирования – сообщению с меньшей вероятностью соответствуют кодовые комбинации большей длины и наоборот.
Таблица 3
| x 1 | x 2 | x 3 | x 4 | x 5 | x 6 | x 7 | x 8 |
Декодирование непрерывной последовательности кодовых комбинаций осуществляется с помощью кодового дерева. С помощью получаемых символов производится трассировка пути от корня дерева до конца ветви. Достижение окончания ветви соответствует моменту принятия решения о получении символа xi.


Средняя длительность кодовой комбинации в данном примере: Lm = 2.8 (при прямом кодировании 3). Относительно невысокий выигрыш связан с более равномерным распределением вероятностей, чем в примере, рассмотренном для кода Шеннона-Фано.
Рассмотренные методы рационального кодирования относятся к классу оптимальных кодов, так как не требуют передачи разделительных символов. То есть любая кодовая комбинация может быть выделена из непрерывной последовательности, наблюдаемой с начала. Существует ряд кодов, не являющихся оптимальными. К числу таких кодов можно отнести хорошо известный код Морзе. Данный код спроектирован только с учетом частоты появления символов латинского алфавита. Для однозначного выделения закодированных символов необходимо, чтобы между ними существовали однозначно идентифицируемые разделительные интервалы.
Задание
В лабораторной работе необходимо выполнить программное моделирование алгоритма поиска кодовых комбинаций и алгоритма кодирования методом Хаффмана. Для дискретного источника сообщений, смоделированного в лабораторной работе №1, выполнить кодирование последовательности продолжительностью K = 100 и K = 1000 реализаций. Вычислить значение оценки средней длительности кодовых комбинаций для каждого из двух случаев
 ,
,
где Li – длина i -й кодовой комбинации. Сравнить полученные значения с рассчитанным теоретически, в соответствии с распределением вероятностей состояний источника, а также с длительностью кодовой комбинации при использовании прямого метода кодирования.
Лабораторная работа № 3
Модели дискретных каналов
Цель работы
Изучение математических моделей дискретных каналов и статистических методов формирования последовательности ошибок, отвечающих заданной модели канала.
Методические указания
1. Статистические характеристики каналов
Непрерывные, дискретные и каналы передачи данных. Согласно эталонной модели архитектуры открытых систем Международной организации стандартов, поддерживающей многоуровневую иерархическую концепцию сетей, канал передачи данных КПД представляет собой совокупность средств двух уровней: первого, называемого физическим, и второго — канального. Структурная схема КПД показан