Статистический машинный перевод — это разновидность машинного перевода текста, основанная на сравнении больших объёмов языковых пар. Языковые пары — тексты, содержащие предложения на одном языке и соответствующие им предложения на втором, могут быть как вариантами написания двух предложений человеком — носителем двух языков, так и набором предложений и их переводов, выполненных человеком. Таким образом, статистический машинный перевод обладает свойством «самообучения». Чем больше в распоряжении имеется языковых пар и чем точнее они соответствуют друг другу, тем лучше результат статистического машинного перевода. Под понятием «статистического машинного перевода» подразумевается общий подход к решению проблемы перевода, который основан на поиске наиболее вероятного перевода предложения с использованием данных, полученных из двуязычной совокупности текстов. В качестве примера двуязычной совокупности текстов можно назвать парламентские отчеты, которые представляют собой протоколы дебатов в парламенте. Двуязычные парламентские отчеты издаются в Канаде, Гонконге и других странах; официальные документы Европейского экономического сообщества издаются на 11 языках; а Организация объединенных наций публикует документы на нескольких языках. Как оказалось, эти материалы представляют собой бесценные ресурсы для статистического машинного перевода.
4. Автоматическое извлечение фактов из текста (извлечение информации) (англ. factextraction, textmining)
Извлечение информации (англ. informationextraction) — это задача автоматического извлечения (построения) структурированных данных из неструктурированных или слабоструктурированных машиночитаемых документов.
Извлечение информации является разновидностью информационного поиска, связанного с обработкой текста на естественном языке. В современных информационных технологиях роль такой процедуры, как извлечение информации, всё больше возрастает — из-за стремительного увеличения количества неструктурированной информации, в частности, в Интернете. Эта информация может быть сделана более структурированной посредством преобразования в реляционную форму или добавлением XML разметки. При мониторинге новостных лент с помощью интеллектуальных агентов как раз и потребуются методы извлечения информации и преобразования её в такую форму, с которой будет удобнее работать позже.
Типичная задача извлечения информации: просканировать набор документов, написанных на естественном языке, и наполнить базу данных выделенной полезной информацией. Современные подходы извлечения информации используют методы обработки естественного языка, направленные лишь на очень ограниченный набор тем (вопросов, проблем) — часто только на одну тему. Например, «Конференция по Пониманию сообщений» (en:MessageUnderstandingConference, MUC) — это конференция соревновательного характера и в прошлом она фокусировалась на таких вопросах:
5. Автореферирование (англ. automatic text summarization). Эта функция включена, например, в MicrosoftWord.
II. Оптическое распознавание символов (англ. OCR). Например, программа FineReader
Оптическое распознавание символов (англ. opticalcharacterrecognition, OCR) механический или электронный перевод изображений рукописного, машинописного или печатного текста в текстовые данные, использующихся для представления символов в компьютере (например, в текстовом редакторе). Распознавание широко используется для конвертации книг и документов в электронный вид, для автоматизации систем учёта в бизнесе или для публикации текста на веб-странице. Оптическое распознавание текста позволяет редактировать текст, осуществлять поиск слов или фраз, хранить его в более компактной форме, демонстрировать или распечатывать материал, не теряя качества, анализировать информацию, а также применять к тексту электронный перевод, форматирование или преобразование в речь. Оптическое распознавание текста является исследуемой проблемой в областях распознавания образов, искусственного интеллекта и компьютерного зрения.
Системы оптического распознавания текста требуют калибровки для работы с конкретным шрифтом; в ранних версиях для программирования было необходимо изображение каждого символа, программа одновременно могла работать только с одним шрифтом. В настоящее время больше всего распространены так называемые «интеллектуальные» системы, с высокой степенью точности распознающие большинство шрифтов. Некоторые системы оптического распознавания текста способны восстанавливать исходное форматирование текста, включая изображения, колонки и другие не текстовые компоненты.
· Автоматическое распознавание речи (англ. ASR).
Первое устройство для распознавания речи появилось в 1952 году, оно могло распознавать произнесённые человеком цифры. В 1962 году на ярмарке компьютерных технологий в Нью-Йорке было представлено устройство IBM Shoebox.
Коммерческие программы по распознаванию речи появились в начале девяностых годов. Обычно их используют люди, которые из-за травмы руки не в состоянии набирать большое количество текста. Эти программы (например, DragonNaturallySpeaking (англ.)русск., VoiceNavigator (англ.)русск.) переводят голос пользователя в текст, таким образом, разгружая его руки. Надёжность перевода у таких программ не очень высока, но с годами она постепенно улучшается.
Увеличение вычислительных мощностей мобильных устройств позволило и для них создать программы с функцией распознавания речи. Среди таких программ стоит отметить приложение MicrosoftVoiceCommand, которое позволяет работать со многими приложениями при помощи голоса. Например, можно включить воспроизведение музыки в плеере или создать новый документ.
Все большую популярность применение распознавания речи находит в различных сферах бизнеса, например, врач в поликлинике может проговаривать диагнозы, которые тут же будут внесены в электронную карточку. Или другой пример. Наверняка каждый хоть раз в жизни мечтал с помощью голоса выключить свет или открыть окно. В последнее время в телефонных интерактивных приложениях все чаще стали использоваться системы автоматического распознавания и синтеза речи. В этом случае общение с голосовым порталом становится более естественным, так как выбор в нём может быть осуществлен не только с помощью тонового набора, но и с помощью голосовых команд. При этом системы распознавания являются независимыми от дикторов, то есть распознают голос любого человека.
Следующим шагом технологий распознавания речи можно считать развитие так называемых интерфейсов безмолвного доступа (silentspeechinterfaces, SSI). Эти системы обработки речи базируются на получении и обработке речевых сигналов на ранней стадии артикулирования. Данный этап развития распознавания речи вызван двумя существенными недостатками современных систем распознавания: чрезмерная чувствительность к шумам, а также необходимость четкой и ясной речи при обращении к системе распознавания. Подход, основанный на SSI, заключается в том, чтобы использовать новые сенсоры, не подверженные влиянию шумов в качестве дополнения к обработанным акустическим сигналам.
Сканер
Ска́нер (англ. scanner) — устройство, которое создаёт цифровое изображение сканируемого объекта.Полученное изображение может быть сохранено как графический файл, или, если оригинал содержал текст, распознано посредством программы распознавания текста и сохранено как текстовый файл.
Рассмотрим принцип действия планшетных сканеров, как наиболее распространённых моделей. Сканируемый объект кладётся на стекло планшета сканируемой поверхностью вниз. Под стеклом располагается подвижная лампа, движение которой регулируется шаговым двигателем.
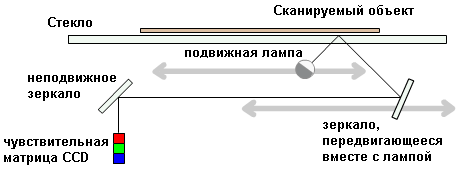
Рис. Устройство планшетного сканера.
Свет, отражённый от объекта, через систему зеркал попадает на чувствительную матрицу (CCD — Couple-ChargedDevice), далее на АЦП и передаётся в компьютер. За каждый шаг двигателя сканируется полоска объекта, потом все полоски объединяются программным обеспечением в общее изображение.
В зависимости от способа сканирования объекта и самих объектов сканирования существуют следующие виды сканеров:
Планшетные — наиболее распространённые, поскольку обеспечивают максимальное удобство для пользователя — высокое качество и приемлемую скорость сканирования. Представляет собой планшет, внутри которого под прозрачным стеклом расположен механизм сканирования.
Ручные — в них отсутствует двигатель, следовательно, объект приходится сканировать вручную, единственным его плюсом является дешевизна и мобильность, при этом он имеет массу недостатков — низкое разрешение, малую скорость работы, узкая полоса сканирования, возможны перекосы изображения, поскольку пользователю будет трудно перемещать сканер с постоянной скоростью.
Листопротяжные — лист бумаги вставляется в щель и протягивается по направляющим роликам внутри сканера мимо ламы. Имеет меньшие размеры, по сравнению с планшетным, однако может сканировать только отдельные листы. Многие модели имеют устройство автоматической подачи, что позволяет быстро сканировать большое количество документов, причем в ряде моделей – с двух сторон за один прогон.
Планетарные — применяются для сканирования книг или легко повреждающихся документов. При сканировании нет контакта со сканируемым объектом (как в планшетных сканерах).
Барабанные — применяются в полиграфии, имеют большое разрешение (около 10 тысяч точек на дюйм). Оригинал располагается на внутренней или внешней стенке прозрачного цилиндра (барабана).
Слайд-сканеры — как ясно из названия, служат для сканирования плёночных слайдов, выпускаются как самостоятельные устройства, так и в виде дополнительных модулей к обычным сканерам.
Сканеры штрих-кода — небольшие, компактные модели для сканирования штрих-кодов товара в магазинах.
Основные производители: Fujitsu, Mustek, Hewlett-Packard (HP).