ЧАСТЬ 2. Управление ресурсами ЭВМ
Один из основных ресурсов ЭВМ, распределением которого занимается ОС - это оперативная память. Поэтому организация памяти оказывает большое влияние на структуру и возможности ОС. В теории и практике ОС накоплен большой опыт управления ОП. Мы рассмотрим только наиболее известные и распространенные модели управления ОП: статическая, открытая (физическая), динамическая, виртуальная
4.1. Методы и средства распределения памяти.
4.1.1. Статическое модель
 В статической модели ОП априорно разбита на разделы фиксированного, но возможно, разного размера (IBM OS/360-MFT, DEC RSX-11). Каждая задача загружается в свободный раздел подходящего размера. Если этот раздел больше, чем требуется задаче, то излишняя память не может использоваться до завершения задачи. Это явление называется внутренней фрагментацией. При такой организации число одновременно загруженных задач ограничено количеством разделов ОП. В этой модели управление ОП сводится к выбору подходящего раздела для загружаемой программы и защите памяти разных разделов. В том случае, если задача не помещается ни в один из разделов памяти, то либо она должна быть перепрограммирована на несколько задач меньшего размера, либо должна использовать метод оверлеев (рис.1). В настоящее время статическое управление памятью применяется очень редко.
В статической модели ОП априорно разбита на разделы фиксированного, но возможно, разного размера (IBM OS/360-MFT, DEC RSX-11). Каждая задача загружается в свободный раздел подходящего размера. Если этот раздел больше, чем требуется задаче, то излишняя память не может использоваться до завершения задачи. Это явление называется внутренней фрагментацией. При такой организации число одновременно загруженных задач ограничено количеством разделов ОП. В этой модели управление ОП сводится к выбору подходящего раздела для загружаемой программы и защите памяти разных разделов. В том случае, если задача не помещается ни в один из разделов памяти, то либо она должна быть перепрограммирована на несколько задач меньшего размера, либо должна использовать метод оверлеев (рис.1). В настоящее время статическое управление памятью применяется очень редко.
Метод оверлеев требует, чтобы программист определил такие ветви алгоритма своей программы, которые могут выполняться только поочередно, и назначал один и тот же адрес загрузки для кода каждой из таких ветвей. Этим достигалась экономия памяти, т.к. задача могла успешно выполняться в объеме памяти, меньшем, чем суммарный объем программы.
4.1.2. Открытая (физическая) модель
 Задача 1 Задача 1
| Задача 1 | Задача 1 | Задача 1 | Задача 1 | ||||
| Задача 2 | Задача 2 | |||||||
| Задача 3 | Задача 3 | Задача 3 | ||||||
| Задача 4 | ||||||||
| Рисунок 2. Внешняя фрагментация в открытой модели памяти |

 В этой модели ОП рассматривается как непрерывная адресная линейка, и программы загружаются по последовательно возрастающим адресам. Внутренняя фрагментация при этом незначительна, однако, активные операции по запросу и освобождению памяти могут привести к тому, что вся доступная ОП будет разбита на экстенты маленького размера, и попытка выделения большого экстента завершится неудачей, даже если сумма длин свободных кусков больше требуемой. Кроме того, большое количество блоков требует длительного поиска. Это явление называется внешней фрагментацией памяти (рис.2).
В этой модели ОП рассматривается как непрерывная адресная линейка, и программы загружаются по последовательно возрастающим адресам. Внутренняя фрагментация при этом незначительна, однако, активные операции по запросу и освобождению памяти могут привести к тому, что вся доступная ОП будет разбита на экстенты маленького размера, и попытка выделения большого экстента завершится неудачей, даже если сумма длин свободных кусков больше требуемой. Кроме того, большое количество блоков требует длительного поиска. Это явление называется внешней фрагментацией памяти (рис.2).
Тем не менее, модель физической ОП удобна для детерминированных приложений РВ, когда можно заранее назначить адреса загрузки критичным задачам.
4.1.2.1. Управление ОП в ОС CP/M
Самый простой случай управления памятью - ситуация, когда диспетчер памяти отсутствует, и в системе может быть загружена только одна программа. В таком режиме работают CP/M и RT-11 SJ (Single-Job, однозадачная). В этих системах программы загружаются с фиксированного адреса PROG_START. В CP/M это 0x100; в RT-11 - 0x1000. В адресах от 0 до начала программы находятся вектора прерываний, а в RT-11 - также и стек программы. Сама система размещается в старших адресах памяти. Адрес SYS_START, с которого она начинается, зависит от количества памяти у машины и от конфигурации самой ОС. Управление памятью состоит в том, что загрузчик проверяет, поместится ли загружаемый модуль в пространство от PROG_START до SYS_START. Предполагается, что объем памяти, который использует программа, не будет меняться во время ее исполнения. Тем не менее, существует риск затирания ОС прикладной программой.
4.1.2.2. Управление ОП в MS DOS
Процедура управления памятью MS DOS предполагает, что программы выгружаются из памяти только в порядке, обратном тому, в каком они туда загружались. Это предотвращает внешнюю фрагментацию и позволяет свести управление памятью к стековой дисциплине. Каждой программе в MS DOS отводится блок памяти. С каждым таким блоком ассоциирован дескриптор, MCB - Memory Control Block. Этот дескриптор содержит размер блока, идентификатор программы, которой принадлежит этот блок и признак того, является ли данный блок последним в цепочке.
При запуске программы DOS берет последний сегмент в цепочке, и загружает туда программу, если этот сегмент достаточно велик. Иначе, DOS сообщает «Not enough memory» и отказывается загружать программу.
При завершении программы DOS освобождает все блоки, принадлежавшие программе. При этом соседние блоки объединяются.
4.2. Динамическая модель
При динамическом распределении фиксированных разделов не существует, а память выделяется блоками (возможно, переменного размера) по мере необходимости программ во время их исполнения. При этом внутренняя фрагментация может быть сведена к минимуму.
В общем случае для динамического управления памятью используются алгоритмы, рассчитанные на самый общий случай, когда запрашиваются блоки случайного размера в случайном порядке и освобождаются также случайным образом. Описанные далее алгоритмы распределения памяти используются не операционной системой, а библиотечными функциями, вызываемыми из прикладных программ при запросах и освобождении памяти.
4.2.1. Выделение памяти
Обычно все свободные блоки памяти объединяются в двунаправленный связанный список. Список должен быть двунаправленным для того, чтобы из него в любой момент можно было извлечь любой блок, а при освобождении – слить с предыдущим и/или последующим.
4.2.1.1. Алгоритмы first fit, best fit, next fit
Поиск в списке может вестись разными способами. Например, до нахождения первого подходящего (first fit) блока или до блока, размер которого минимально больше заданного - (best fit). При использовании best fit надо просматривать весь список, в то время как первый подходящий может оказаться в любом месте, и среднее время поиска будет меньше.
В общем случае best fit увеличивает внешнюю фрагментацию памяти. Действительно, если найден блок с размером больше заданного, нужно отделить его не используемый объем и пометить его как новый свободный блок. Понятно, что в случае best fit средний размер этого хвоста будет маленьким, и в итоге получится большое количество несмежных мелких блоков.
При использовании first fit с линейным двунаправленным списком возникает проблема антисортировки. Если каждый раз просматривать список с одного и того же места, то свободные блоки, расположенные ближе к началу, будут чаще использоваться. Соответственно, мелкие свободные блоки будут скапливаться в начале списка, что увеличит среднее время поиска. Простой способ борьбы с этим явлением состоит в том, чтобы просматривать список то в одном направлении, то в другом.
Более радикальный и еще более простой метод состоит в том, что список делается кольцевым, и поиск каждый начинается с того места, где была выделена память в прошлый раз (next fit). В результате список очень эффективно перемешивается и антисортировки не возникает.
В ситуациях, требуются блоки нескольких фиксированных размеров, алгоритмы best fit оказываются лучше. Однако библиотеки распределения памяти рассчитывают на худший случай, и в них обычно используются алгоритмы first fit.
4.2.1.2. Алгоритм близнецов
В случае работы с блоками нескольких фиксированных размеров можно создать для каждого типоразмера свой список. Это избавляет от необходимости выбирать между first и best fit и устраняет необходимость поиска в списках.
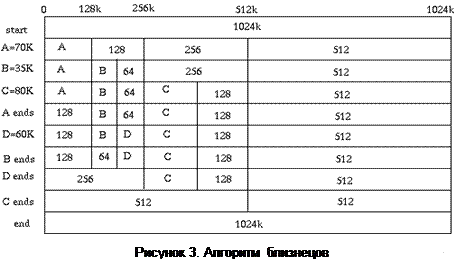 Частный случай этого подхода для случая, когда память запрашивается блоками с размером 2N, т.е. 512 байт, 1Кбайт, 2Кбайта и т.д., называется алгоритмом близнецов (buddy system). Он состоит в том, что для свободных блоков каждого типоразмера создается свой список, и блок требуемого размера ищется в соответствующем списке. Если этот список пуст, рассматривается список блоков вдвое большего размера и любой из них делится пополам. Ненужную половину помещают в соответствующий список свободных блоков. Одно из преимуществ этого метода состоит в простоте объединения блоков при их освобождении. Нужно только проверить, свободен ли его близнец (смежный блок такого же размера). Если он свободен, то эти блоки объединяются в экстент вдвое большего размера, и т.д. Пример использования алгоритма близнецов приведен на рис.3.
Частный случай этого подхода для случая, когда память запрашивается блоками с размером 2N, т.е. 512 байт, 1Кбайт, 2Кбайта и т.д., называется алгоритмом близнецов (buddy system). Он состоит в том, что для свободных блоков каждого типоразмера создается свой список, и блок требуемого размера ищется в соответствующем списке. Если этот список пуст, рассматривается список блоков вдвое большего размера и любой из них делится пополам. Ненужную половину помещают в соответствующий список свободных блоков. Одно из преимуществ этого метода состоит в простоте объединения блоков при их освобождении. Нужно только проверить, свободен ли его близнец (смежный блок такого же размера). Если он свободен, то эти блоки объединяются в экстент вдвое большего размера, и т.д. Пример использования алгоритма близнецов приведен на рис.3.
Алгоритм близнецов устраняет внешнюю фрагментацию памяти и снижает внутреннюю в среднем до 25%, а также ускоряет поиск блоков. Поэтому алгоритм близнецов используется в ситуациях, когда необходимо гарантированное время реакции, например, для задач реального времени. Часто этот алгоритм или его варианты используются для выделения памяти внутри ядра ОС.
4.2.2. Освобождение памяти.
Программа динамического распределения памяти должна решать еще одну важную проблему - объединение свободных блоков. Один способ упоминался в описании алгоритма близнецов, но он пригоден только для описанной ситуации.
| Lбл1 | освобождение | Lбл(1+2) + 2сл |
| Блок1 (своб) | Блок1+2 (своб) | |
| Lбл1 | ||
| -Lбл2 | ||
 Блок2 (занят) Блок2 (занят)
| ||
| -Lбл2 | Lбл(1+2) + 2сл | |
| Рисунок 4. Алгоритм парных меток |
4.2.2.1. Алгоритм парных меток
Пусть освобождается блок с начальным адресом addr и размером Lбл. Это означает, что его надо либо слить с соседним свободным (если он есть), либо включить в виде нового элемента в список свободных блоков (если смежного свободного нет). А для определения того, что рядом с освобождаемым есть свободный блок, надо просмотреть весь список. Более совершенный метод, называемый алгоритмом парных меток, состоит в том, что в начале и в конце каждого занятого и свободного экстента добавляется по слову памяти (дескриптору), содержащему его длину (Lбл). При этом значения длины будут положительными, если блок свободен, и отрицательными, если блок занят. Можно и наоборот, важно только потом соблюдать это соглашение (рис.4).
Пусть освобождается блок2 с адресом addr. Если предыдущий блок1 свободен, то можно определить адрес начала блока1 как addr - Lбл1. Затем можно легко объединить блок1 с блоком2, для чего нужно сложить их длины и записать их в дескрипторы объединенного блока. Список свободных блоков не корректируется.
Похожим образом присоединяется и сосед сзади. Единственное отличие состоит в том, что список свободных блоков все-таки потребуется корректировать.
4.2.2.2. Методы сборки мусора
Некоторые системы программирования, например среда выполнения Microsoft.NET, VM Java, используют специальный метод освобождения динамической памяти, называемый сборкой мусора. Этот метод состоит в том, что ненужные блоки памяти не освобождаются явным образом. Вместо этого периодически (как правило, если свободной памяти оказалось недостаточно) используется некоторый алгоритм, следящий за тем, какие блоки еще нужны, а какие - уже нет.
Самый простой метод отличать используемые блоки от ненужных - считать, что блок, содержащий объект, на который есть ссылка, – нужен, а блок с объектами, на которые ни одной ссылки не осталось – не нужен. Для этого к каждому блоку присоединяют дескриптор, в котором подсчитывают количество ссылок на него. Каждая передача указателя на этот блок приводит к увеличению счетчика ссылок на 1, а каждое уничтожение объекта, содержавшего указатель - к уменьшению.
Если число различных объектов может быть очень велико и поиск блоков, оставшихся без ссылок, займет слишком много времени, то используются более сложные методы. Например, сборщик мусора Microsoft.NET (Garbage Collector - GC) для обнаружения уже ненужных блоков применяет следующий алгоритм:
- объекты, еще ни разу не проверявшиеся на наличие ссылок, считаются объектами поколения 0;
- ранее найденные объекты без ссылок, которые не были удалены только из-за того, что нужды в освобождении памяти не было, считаются объектами поколения 1;
- объекты без ссылок, пережившие более одной проверки, и все еще не удаленные, причисляются к поколению 2.
При очередном запуске GC проверяет и удаляет объекты поколения 0. если освободившейся памяти оказалось достаточно для удовлетворения запроса на выделение памяти, то выжившие объекты поколения 0 переводятся в поколение 1. В противном случае процесс удаления продолжается, уничтожая все объекты поколения 0, а затем 1 и 2. Этот алгоритм приводит к тому, что вероятность удаления выше для недавно созданных объектов, чем для «старых», например объектов приложения.
Однако если создается циклический список ссылок, на который нет ни одной ссылки извне, то все объекты в нем будут считаться используемыми, даже если они уже не нужны ни одной программе. Если есть уверенность, что такие циклы, как правило, не возникают, то метод подсчета ссылок вполне приемлем; если же такой уверенности нет, то необходим более сложный алгоритм.
4.2.3. Сводка методов динамической модели
Итак, наилучшим из известных универсальных методов динамического управления памятью является объединение свободных блоков в двунаправленный кольцевой список с поиском по принципу next fit и освобождением по алгоритму парных меток. Этот метод обеспечивает приемлемую производительность почти для всех стратегий распределения памяти, используемых в прикладных программах. Такой алгоритм используется практически во всех реализациях стандартной библиотеки языка C. Другие известные методы либо просто хуже, чем этот, либо проявляют свои преимущества только в специальных случаях.
Основными недостатками этого метода являются отсутствие верхней границы времени поиска подходящего блока, что делает его неприемлемым для задач реального времени, и внешняя фрагментация памяти.
4.3. Модели виртуальной памяти
В системах с виртуальной памятью используется понятие логической адресации задачи, создаваемой транслятором. Логические адреса могут отличаться от физических в реальной ОП. Более того, физические адреса, соответствующие соседним логическим, могут оказаться несмежными.
4.3.1. Базовая адресация
ОС с базовой адресацией (пример, ICL1900/Орденок), используют два регистра. Один из регистров задает базу для адресов, второй устанавливает верхний предел. Если адрес выходит за верхнюю границу, возникает исключительная ситуация (exception) ошибочной адресации. Как правило, это приводит к тому, что система принудительно завершает работу программы.
При помощи этих двух регистров решаются две важные проблемы.
Во-первых, можно изолировать программы друг от друга - ошибки в одной программе не приводят к разрушению или повреждению других программ или самой системы. Благодаря этому обеспечивается защита ОС не только от ошибочных программ, но и от действий пользователей по разрушению системы или доступу к чужим данным.
Во-вторых, появляется возможность сдвигать адресные пространства задач по физической памяти так, что сама программа не замечает, что ее передвинули. За счет этого решается проблема внешней фрагментации памяти, а программы получают возможность наращивать свое адресное пространство. Для этого можно просто сдвинуть позже загруженную программу вверх по физическим адресам.
В современных системах базовая виртуальная адресация используется редко. Дело не в том, что она плоха, а в том, что более сложные методы, такие как сегментная и страничная трансляция адресов, оказались намного лучше.
4.3.2. Сегментная и страничная виртуальная память
 При сегментной или страничной адресации виртуальный адрес разбит на два битовых поля: номер страницы (сегмента) и смещение в нем (page:offset). Соответственно, адресное пространство оказывается состоящим из дискретных блоков. Если все эти блоки имеют фиксированную длину и образуют вместе непрерывное пространство, они называются страницами. Если длина каждого блока может задаваться произвольно, то они называются сегментами. Как правило, один сегмент соответствует коду или данным одного модуля программы. Со страницей или сегментом могут быть ассоциированы права чтения, записи и исполнения.
При сегментной или страничной адресации виртуальный адрес разбит на два битовых поля: номер страницы (сегмента) и смещение в нем (page:offset). Соответственно, адресное пространство оказывается состоящим из дискретных блоков. Если все эти блоки имеют фиксированную длину и образуют вместе непрерывное пространство, они называются страницами. Если длина каждого блока может задаваться произвольно, то они называются сегментами. Как правило, один сегмент соответствует коду или данным одного модуля программы. Со страницей или сегментом могут быть ассоциированы права чтения, записи и исполнения.
Такая адресация реализуется аппаратно. Процессор, как правило, имеет специальное устройство, называемое диспетчером памяти (MMU). В некоторых процессорах, например в MC68020 или MC68030 или в некоторых RISC-системах, это устройство реализовано на отдельном кристалле; в других, таких как i386 или Alpha, диспетчер памяти интегрирован в процессор.
4.3.2.1. Таблица трансляции адресов и функции MMU
MMU содержит регистр – указатель на таблицу трансляции. Эта таблица размещается в физической памяти. Ее элементами являются дескрипторы каждой виртуальной страницы/сегмента, содержащие права доступа к странице, признак присутствия этой страницы в памяти и физический адрес страницы/сегмента. Для сегментов в дескрипторе также хранится длина сегмента.
Как правило, MMU имеет также кэш (cache) дескрипторов – быструю память с ассоциативным доступом. В этой памяти хранятся дескрипторы часто используемых страниц.
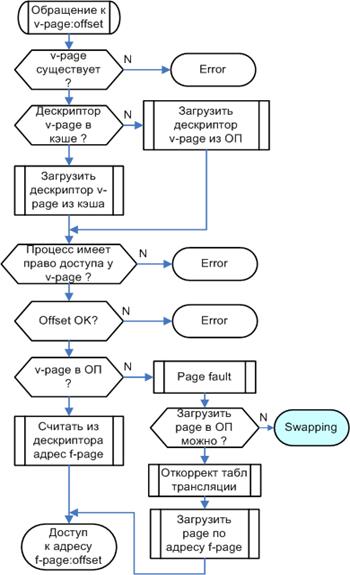
Алгоритм доступа к памяти по виртуальному адресу (page:offset) получается следующим:
-Проверить, существует ли страница page вообще. Такая проверка осуществляется простым сравнением номера страницы с длиной таблицы трансляции. Если страницы не существует, возникает особая ситуация ошибки сегментации (segmentation violation)
-Попытаться найти дескриптор страницы в кэше.
-Если его нет в кэше, загрузить дескриптор из таблицы в памяти.
-Проверить, имеет ли процесс соответствующее право доступа к странице. Иначе также возникает ошибка сегментации.
-Проверить, находится ли страница в оперативной памяти. Если ее там нет, возникает прерывание по отсутствию страницы (page fault). Как правило, реакция на нее состоит в том, что вызывается специальная программа-обработчик (trap - ловушка), которая подкачивает требуемую страницу с диска. В мультизадачных системах во время такой подкачки может исполняться другой процесс.
-Если страница есть в памяти, взять из ее дескриптора физический адрес phys_addr.
-Если применяется сегментная адресация, сравнить смещение в сегменте с длиной этого сегмента. Если смещение оказалось больше, также возникает ошибка сегментации.
-Произвести доступ к памяти по адресу phys_addr[offset].
Такая схема адресации довольно сложна, но благодаря аппаратной реализации и кэшу дескрипторов, скорость доступа к памяти получается почти такой же, как и при прямой адресации. Кроме того, эта схема имеет неоценимые преимущества при реализации мультизадачных ОС, например:
- С каждой задачей можно связать свою таблицу трансляции, а значит и свое виртуальное адресное пространство. Благодаря этому даже в мультизадачных ОС можно пользоваться абсолютным загрузчиком. Кроме того, программы оказываются изолированными друг от друга, что обеспечивает их безопасность.
- Редко используемые области виртуальной памяти программ можно сбрасывать на диск - не всю программу целиком, а только ее часть. Программа вообще не обязана знать, какая ее часть может быть сброшена. Разумеется, это неприемлемо для систем реального времени, которые обязаны гарантировать время реакции. Поэтому код, обрабатывающий критичное событие, и используемые при этом данные должны быть всегда в памяти.
- Программа, имея непрерывное виртуальное адресное пространство, не обязана занимать непрерывную область физической памяти. Это упрощает борьбу с фрагментацией памяти, а в системах со страничной адресацией проблема фрагментации физической памяти вообще снимается.
- Система может обеспечивать не только защиту программ друг от друга, но и защиту программы от самой себя - например, от ошибочной записи данных на место кода.
- Различные задачи могут использовать общие области памяти для взаимодействия, например, для обмена или для того, чтобы работать с одной копией библиотеки подпрограмм.
Перечисленные преимущества настолько серьезны, что считается невозможным реализовать мультизадачную ОС общего назначения на машинах без диспетчера памяти.
4.3.2.2. Выбор размера страницы
Отдельной проблемой при разработке системы со страничной или сегментной адресацией является выбор размера страницы. Этот размер определяется шириной соответствующего битового поля адреса и поэтому должен быть степенью двойки.
С одной стороны, страницы не должны быть слишком большими, так как это может привести к неэффективному использованию памяти и перекачке слишком больших объемов данных при сбросе страниц на диск. С другой стороны, страницы не должны быть слишком маленькими, так как это приведет к чрезмерному увеличению таблиц трансляции, требуемого объема кэша дескрипторов и т.д.
Это обстоятельство вынуждает применять двухступенчатую виртуальную память – сегментно-страничную адресацию, в которой каждый сегмент, в свою очередь, разбит на страницы. Это, например, позволяет раздавать права доступа сегментам, а подкачку с диска осуществлять постранично. Таким образом организована виртуальная память в IBM System 370 и ряде других больших компьютеров, а также в i3/486.
4.3.2.3. Страничный обмен.
Страничный обмен, или свопинг (swapping – обмен) – это процесс сброса редко используемых областей виртуального адресного пространства программы на диск или другое устройство массовой памяти. Такая массовая память всегда намного дешевле оперативной, хотя и намного медленнее. Свопинг применяется в том случае, когда в физической ОП недостаточно свободного места для загрузки необходимых данных.
Как правило, 90% времени исполняется код, который занимает 10% места, а остальные 90% кода исполняются только 10% времени. Это приводит к идее многослойной или многоуровневой памяти, когда в быстрой памяти хранятся часто используемые код или данные, а редко используемые постепенно мигрируют на более медленные устройства. В случае дисковой памяти такая миграция осуществляется вручную, когда администратор системы сбрасывает на ленты редко используемые данные. В случае кэш-памяти и ОЗУ делать что-то вручную просто физически невозможно.
Для автоматизации процесса удаления редко используемых данных и программ, нужно иметь легко формализуемый критерий, по которому определяется, какие данные считать редко используемыми. Для ручного переноса данных критерий очевиден - нужно удалять то, что дольше всего не будет использоваться в будущем. Конечно, любые предположения о будущем имеют условный характер. Тем не менее, обычно человек располагает такой информацией о системе и ее использовании, которая принципиально недоступна самой этой системе. А для автомата будущее неизвестно, и он должен делать догадки о будущем только на основании данных об использовании системы в прошлом. Алгоритм автомата должен быть как можно более быстрым и, следовательно, очень простым. Даже микропрограммный автомат с точки зрения скорости оказывается недопустимым, не говоря уже о сложных алгоритмах, использующих динамические структуры данных.
Самый простой алгоритм - выкидывать случайно выбранный объект. Такой алгоритм хорош тем, что очень прост – не надо набирать никакой статистики о частоте использования и т.д. Очевидно, при этом удаленный объект совершенно необязательно будет ненужным и может потребоваться для исполнения следующей машинной команды..
Еще один простой критерий выбора - при прочих равных условиях, в первую очередь, выбирать в качестве жертвы (victim) для удаления тот объект, который не был изменен за время жизни в быстрой памяти.
Можно также удалять то, что дольше всего находится в данном слое памяти (алгоритм FIFO). Это чуть сложнее случайного удаления – нужно запоминать, когда что загружалось. Понятно также, что это лишь очень грубое приближение к тому, что требуется.
Наиболее справедливым будет удалять тот объект, к которому дольше всего не было обращений в прошлом LRU (Least Recently Used). Это требует набора статистики обо всех обращениях. Для страничного или сегментного управления памятью это также требует аппаратной поддержки, т.к. невозможно программно отслеживать все обращения ко всем страницам без катастрофического падения производительности. Такая поддержка на практике должна состоять в том, что диспетчер памяти поддерживает в дескрипторе каждой страницы счетчик обращений, и при каждой операции чтения или записи над этой страницей увеличивает этот счетчик на единицу. Это требует довольно больших накладных расходов, поэтому такая техника применяется только в экспериментальных установках, используемых для оценки производительности тех или иных алгоритмов. Она также применяется в некоторых контроллерах кэш-памяти и программно реализованных дисковых кэшах.
Приближением к алгоритму LRU является так называемый clock-алгоритм:
-Дескриптор каждой страницы содержит clock-бит, указывающий, что к данной странице было обращение;
-При первом обращении к странице, в которой clock-бит был сброшен, диспетчер памяти устанавливает этот бит;
-Программа свопинга циклически просматривает все дескрипторы страниц. Если clock-бит сброшен, данная страница объявляется жертвой, и просмотр заканчивается – до появления потребности в новой странице. Если clock-бит установлен, то программа сбрасывает его и продолжает поиск.
Очевидно, что вероятность оказаться жертвой для страницы, к которой часто происходят обращения, существенно ниже.
Практически все известные диспетчеры памяти предполагают использование clock-алгоритма. Такие диспетчеры хранят в дескрипторе страницы или сегмента два бита - clock-бит и признак модификации. Признак модификации устанавливается при первой записи в страницу/сегмент, в дескрипторе которой этот признак был сброшен.
Каждая программа имеет некоторый набор страниц, называемый рабочим множеством, который ей в данный момент действительно нужен. Размер такого набора зависит от алгоритма программы, он изменяется на различных этапах исполнения и т.д. Если все страницы рабочего набора попадают в память, то частота ошибок отсутствия страницы резко снижается. В случае, когда памяти не хватает, программе почти на каждой команде требуется новая страница, и производительность системы катастрофически падает. Это состояние по-английски называется overswap - чрезмерный свопинг и является крайне нежелательным.
В системах коллективного пользования размер памяти часто выбирают так, чтобы система балансировала где-то между состоянием, когда все программы держат свое рабочее множество в ОЗУ, и оверсвопом. Точное положение точки балансировки определяется в зависимости от соотношения скорости процессора со скоростью обмена с диском и с потребностями прикладных программ.
======================================================================================
ВОПРОСЫ:
1.Статическая модель управления памятью. Оверлеи.
2.Открытая модель управления памятью.
3.Управление памятью в MS DOS, CP/M и RT-11.
4.Отличия статической, физической и динамической моделей памяти.
5.Алгоритмы выделения памяти first fit, best fit, next fit.
6.Выделение и освобождение памяти по алгоритму близнецов.
7.Причины внутренней и внешней фрагментации памяти.
8.Освобождение памяти по алгоритму парных меток.
9.Освобождение памяти методом «сборки мусора».
10. Оценка методов динамического управления памятью.
11. Понятия логической и физической памяти
12. Базовая виртуальная адресация.
13. Сегментная и страничная виртуальная адресация.
14. Таблица трансляции адресов и функции MMU.
15. Выбор размера страницы виртуальной памяти
16. Оценка фрагментации в статической, физической и динамической моделях ОП
17. Алгоритмы свопинга.