ВВЕДЕНИЕ
Цель данной курсовой работы является создать многофайловый проект в среде Visual Studio на языке C. Для достижения цели необходимо решить следующие задачи:
- Выполнить программную реализацию задач по изученным темам дисциплины с применением принципов модульного программирования;
- Подготовить тестовые примеры и протестировать задачи;
- Создать многофайловый проект. При помощи меню организовать переход по ссылкам на каждую из изученных тем: рекурсия, структуры, файлы, сортировки, стеки, очереди, деревья и графы.
В курсовую работу входит: введение, главы, заключение, список использованной литературы и приложение.
Тема «Рекурсивные функции»
Теоритическая часть
Рекурсивной называют функцию, которая прямо или косвенно сама вызывает себя. При каждом обращении к рекурсивной функции создается новый набор объектов автоматической памяти, локализованных в теле функции.
Рекурсивные алгоритмы эффективны, например, в тех задачах, где рекурсия использована в определении обрабатываемых данных. Поэтому серьезное изучение рекурсивных методов нужно проводить, вводя динамические структуры данных с рекурсивной структурой. Рассмотрим вначале только принципиальные возможности, которые предоставляет язык Си для организации рекурсивных алгоритмов.
Различают прямую и косвенную рекурсии. Функция называется косвенно рекурсивной в том случае, если она содержит обращение к другой функции, содержащей прямой или косвенный вызов определяемой (первой) функции. В этом случае по тексту определения функции её рекурсивность (косвенная) может быть не видна. Если в теле функции явно используется вызов этой же функции, то имеет место прямая рекурсия, т.е. функция, по определению, рекурсивная (иначе – самовызываемая или самовызывающая). Классический пример – функция для вычисления факториала неотрицательного целого числа. В литературе по программированию рекурсиям уделено достаточно внимания как в теоретическом плане, так и в плане рассмотрения механизмов реализации рекурсивных алгоритмов. Сравнивая рекурсию с итерационными методами, отмечают, что рекурсивные алгоритмы наиболее пригодны в случаях, когда поставленная задача или используемые данные определены рекурсивно. В тех случаях, когда вычисляемые значения определяются с помощью простых рекуррентных соотношений, гораздо эффективнее применять итеративные методы. Таким образом, определение корня математической функции, возведение в степень и вычисление факториала только иллюстрируют схемы организации рекурсивных функций, но не являются примерами эффективного применения рекурсивного подхода к вычислениям. (1)
Практические задачи
Задание № 1. Написать алгоритм поиска простых чисел, не превосходящих n, как рекурсивную функцию.
Таблица 1
| Наименование переменной | Тип | Назначение | |
| Входные данные | n | int | Число, вводимое с клавитуры |
| j | int | Переменная цикла, передается в функцию для проверки на простоту | |
| s | int | Делимое | |
| i | int | Делитель | |
| Выходные данные | n | int | Число до которого выводятся простые числа |
Блок схема всей программы:

Листинг программы:
#include<stdlib.h>
#include<stdio.h>
#include<locale.h>
int recurs (int s,int i);
int main()
{
int j,n;
printf("Введите число:");
scanf("%d",&n);
for(j=2;j<=n;j++)
if(recurs (j,2))
printf("Простое число:%d\n",j);
system(“pause”);
return 0
}
int recurs (int s,int i)
{
if(s==i) return 1;
if(s%i==0) return 0;
return recurs (s,i+1);
}

Рис 1.1. Вывод простых чисел с помощью рекурсии
Задание № 2. описать рекурсивную функцию, осуществляющую перевод целого числа из десятичной системы счисления в систему с основанием К. Перевести заданное число N из десятичной системы в системы с основанием 2,8,16.
Таблица № 2.
| Наименование переменной | Тип | Назначение | |
| Входные данные | n | int | Делимое |
| k | int | Делитель | |
| l | int | Переменная для количества чисел | |
| n1 | int | Число, которое переводится в другую систему исчисления | |
| k1 | int | Система исчисления | |
| Выходные данные | n1 | int | Переведенное число |
Блок схема всей программы:

Листинг программы:
#include<stdlib.h>
#include<stdio.h>
#include<locale.h>
void recurs (int n,int k);
void main()
{
setlocale(LC_ALL,”RUS”);
int n1,k1,l;
printf("Введите количество чисел для перевода:");
scanf("%d", &l);
for(int i=0;i<l; i++)
{
printf("Введите число:");
scanf("%d", &n1);
printf("Введите систему исчисления:");
scanf("%d", &k1);
printf("Результат:");
recurs(n1,k1);
printf("\n");
}
}
void recurs(int n,int k)
{
if(n>=k) recurs (n/k,k);
switch(n%k)
{
case 10:printf("A");break;
case 11:printf("B");break;
case 12:printf("C");break;
case 13:printf("D");break;
case 14:printf("E");break;
case 15:printf("F");break;
default:printf("%d",n%k);
}
}
Результат работы программы:

Рис 1.4. Перевод числа 255 в разные системы исчисления
Тема «Структуры»
Теоритическая часть
Структура - это одна или несколько переменных, которые для удобства работы с ними сгруппированы под одним именем. Структуры помогают в организации сложных данных, поскольку позволяют группу связанных между собой переменных трактовать не как множество отдельных элементов, а как единое целое.
Объявление структуры начинается с ключевого слова struct и содержит список объявлений, заключенный в фигурные скобки. За словом struct может следовать имя, называемое тегом структуры. Тег дает название структуре данного вида и далее может служить кратким обозначением той части объявления, которая заключена в фигурные скобки.
Перечисленные в структуре переменные называются элементами. Имена элементов и тегов могут совпадать с именами обычных переменных, так как они всегда различимы по контексту.
Объявление структуры определяет тип. За правой фигурной скобкой, закрывающей список элементов, могут следовать переменные точно так же, как они могут быть указаны после названия любого базового типа.
Объявление структуры, не содержащей списка переменных, не резервирует памяти; оно просто описывает шаблон, или образец структуры. Однако если структура имеет тег, то этим тегом далее можно пользоваться при определении структурных объектов.
Доступ к отдельному элементу структуры осуществляется посредством конструкции вида:
имя структуры. элемент
Структуры могут быть вложены друг в друга. Единственно возможные операции над структурами - это их копирование, присваивание, взятие адреса и осуществление доступа к ее элементам. Копирование и присваивание также включают в себя передачу функциям аргументов и возврат ими значений. Структуры нельзя сравнивать.
Указатели на структуры используются весьма часто, поэтому для доступа к ее элементам была придумана еще одна, более короткая форма записи.
р-›элемент-структуры
Массивы структур. Предположим нам нужно уметь хранить ключевые слова в виде массива строк и счетчики ключевых слов в виде массива целых. Один из возможных вариантов - это иметь два параллельных массива:
char *keyword[NKEYS];
int keycount[NKEYS];
Однако именно тот факт, что они параллельны, подсказывает нам другую организацию хранения - через массив структур. Каждое ключевое слово можно описать парой характеристик
char *word;
int count;
Такие пары составляют массив. Объявление
struct key
{
char *word;
int count;
} keytab[NKEYS];
объявляет структуру типа key и определяет массив keytab, каждый элемент которого является структурой этого типа и которому будет выделена память.
Инициализаторы задаются парами, чтобы соответствовать конфигурации структуры. Однако когда инициализаторы - простые константы или строки символов и все они имеются в наличии, во внутренних скобках нет необходимости. (1)
Практическая задача.
Задание: создать структуру с полями ЧИСЛО, МЕСЯЦ, ГОД. Составить и протестировать функции:
· ввода и вывода на экран даты;
· по году и порядковому номеру дня в году вычисляющую число и месяц года, соответствующему этому дню;
· находящую в массиве введенных дат самую позднюю
Таблица №3.
| Наименование переменной | Тип | Назначение | |
| Входные данные | b.d, b.m, b.y | int | Структурные переменные |
| c | int | Переменная для меню | |
| q | int | Переменная для меню | |
| с | сhar | Переменная для считывания из файла | |
| i | int | Счётчик для массива структур | |
| max, max2,max3 | int | Переменные для определения максимальной даты | |
| cnt, cnt1 | int | Счётчики для нахождения максимумов,если дат с одним годом(месяцем) несколько | |
| h[20],h1[20] | int | Массивы для запоминания номеров дат с максимальным годом или месяцем | |
| b.d1, b.y1 | int | Структурные переменные для дня и года | |
| Выходные данные | b.d, b.m, b.y | int | В массиве структур хранятся даты |
Блок-схема главной функции структуры.


Листинг программы(неполный):
#include<stdio.h>
#include<stdlib.h>
void output(void);
void day(void);
void last_year(void);
void input(void);
struct
{
int d;
int m;
int y;
}b[100];
void main_struct(void)
{
printf("Структуры\n");
for(;;)
{
int c;
printf("1-Ввод новой даты\n");
printf("2-Вывод всех дат\n");
printf("3-Нахождение самой поздней даты\n");
printf("4-Определение дня по номеру\n");
printf("5-Вернуться в главное меню\n");
do
{
printf("Введите номер нужного пункта:");
scanf("%d",&c);
}while(c<0 || c>5);
switch(c)
{
case 1:
{
input();system("PAUSE");
system("cls");break;
}
case 2:
{
output();system("PAUSE");
system("cls");break;
}
case 3:
{
last_year();system("PAUSE");
system("cls");break;
}
case 4:
{
day();system("PAUSE");
system("cls");break;
}
case 5: return;
}
}
}
Полный листинг программы приведен в приложении.
Результат работы программы:
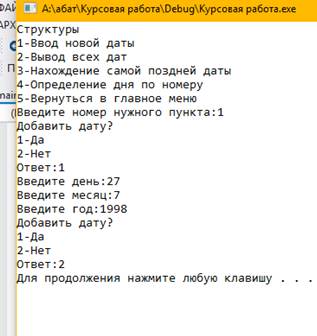
Рис 2.1. Ввод новой даты в массив структур
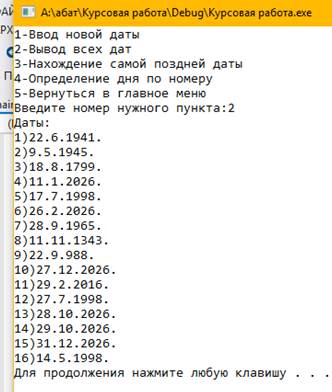
Рис 2.2. Вывод всех дат с файла

Рис 2.3. Нахождение самой поздней даты

Рис 2.4. Определение дня и месяца по номеру дня
Тема «Файлы».
Теоритическая часть.
Доступ к файлам. Для того чтобы можно было читать из файла или писать в файл, он должен быть предварительно открыт с помощью библиотечной функции fopen. Функция fopen получает внешнее имя типа x.txt, после чего возвращает указатель, используемый в дальнейшем для доступа к файлу.
Для определения указателя файла, - это задать описания такого, например, вида:
FILE *fp;
FILE *fopen(char *name, char *mode);
это говорит, что fp есть указатель на FILE, a fopen возвращает указатель на FILE. Заметим, что FILE - это имя типа наподобие int, а не тег структуры. Обращение к fopen в программе может выглядеть следующим образом:
fp = fopen(name, mode);
Первый аргумент - строка, содержащая имя файла. Второй аргумент несет информацию о режиме. Это тоже строка: в ней указывается, каким образом пользователь намерен применять файл. Возможны следующие режимы: чтение (read - "r"), запись (write - "w") и добавление (append - "a"), т. е. запись информации в конец уже существующего файла. Различают текстовые и бинарные файлы; в случае последних в строку режима необходимо добавить букву "b" (binary - бинарный). Открытие уже существующего файла на запись приводит к удалению его старого содержимого, в то время как при открытии файла на добавление его старое содержимое сохраняется. Попытка читать несуществующий файл является ошибкой. Могут иметь место и другие ошибки; например, ошибкой считается попытка чтения файла, который по статусу запрещено читать. При наличии любой ошибки fopen возвращает NULL.
Следующее, что необходимо знать, - это как читать из файла или писать в файл. Существует несколько способов сделать это, из которых самый простой состоит в том, чтобы воспользоваться функциями getc и putc. Функция getc возвращает следующий символ из файла; ей необходимо сообщить указатель файла, чтобы она знала откуда брать символ.
int getc(FILE *fp);
Функция getc возвращает следующий символ из потока, на который указывает *fp; в случае исчерпания файла или ошибки она возвращает EOF.
Функция putc пишет символ c в файл fp
int putc(int с, FILE *fp);
и возвращает записанный символ или EOF в случае ошибки. Аналогично getchar и putchar, реализация getc и putc может быть выполнена в виде макросов, а не функций.
Форматный ввод-вывод файлов можно построить на функциях fscanf и fprintf. Они идентичны scanf и printf с той лишь разницей, что первым их аргументом является указатель на файл, для которого осуществляется ввод-вывод, формат же указывается вторым аргументом.
int fscanf(FILE *fp, char *format,…)
int fprintf(FILE *fp, char *format,…)
int fclose(FILE *fp) - обратная по отношению к fopen; она разрывает связь между файловым указателем и внешним именем (которая раньше была установлена с помощью fopen), освобождая тем самым этот указатель для других файлов. Так как в большинстве операционных систем количество одновременно открытых одной программой файлов ограничено, то файловые указатели, если они больше не нужны, лучше освобождать, как это и делается в программе. (2)
Практическая задача
Задание: Имеется текстовый файл. Переписать его строки в другой файл, поменяв местами слова в строках.
Таблица № 4.
| Наименование переменной | Тип | Назначение | |
| Входные данные | *p,b[100][100] | char | Для разбивания строк на лексемы |
| e | char | Считывания из файла | |
| s[100][100] | char | Считывания из файла текста | |
| q | int | Переменная для выбора в меню | |
| Выходные данные | b[100][100] | char | Запись в файл слов текста в обратном порядке |
| s[100][100] | char | Скопирован весь текст |
Блок-схема функции file().

Листинг программы(неполный):
#include<stdlib.h>
#include<stdio.h>
#include<string.h>
void file(void);
void file_main()
{
int q;
printf("Файлы\n");
for(;;)
{
printf("1-Задание\n");
printf("2-Вернуться в главное меню\n");
do
{
printf("Выберите пункт меню:");
scanf("%d",&q);
}while(q<0||q>3);
switch (q)
{
case 1:
{
file();
system("pause");
system("cls");
break;
}
case 2: return;
}
}
}
Полный листинг программы приведен в приложении.
Результат работы программы:

Рис 3.1. Результат
Тема «Алгоритмы сортировки»
Теоритическая часть
Перед разговором о различных алгоритмах сортировки, их недостатках и преимуществах, необходимо ввести в рассмотрение понятие анализа эффективности алгоритмов. Формально термин "анализ алгоритмов" означает процесс исследования эффективности алгоритмов, которую можно оценить по двум параметрам: времени выполнения алгоритма и требуемому объему оперативной памяти.
Различают два вида эффективности: временную и пространственную. Временная эффективность является индикатором скорости работы алгоритма. Пространственная эффективность показывает, сколько дополнительной оперативной памяти нужно для работы алгоритма.
Всё внимание перешло на временную эффективность благодаря развитию ЭВМ.
Оценка размера входных данных. Время выполнения большинства алгоритмов напрямую зависит от размера вводимых данных. Эффективность алгоритма можно описать в виде функции от некоторого параметра, связанного с размером входных данных.
Каковы единицы измерения времени выполнения алгоритма? Для этого можно просто воспользоваться— секундой, миллисекундой и т.д. и с их помощью оценить время выполнения программы, реализующей рассматриваемый алгоритм. Однако у такого подхода существуют явные недостатки - определение единиц измерения времени выполнения алгоритма через единицы измерения времени имеет недостатки, поскольку результаты измерений будут зависеть от многих факторов
Мы должны составить список наиболее важных операций, выполняемых в алгоритме, называемых основными, или базовыми операциями (basic operation), определить, какие из них вносят наибольший вклад в общее время выполнения алгоритма, и вычислить, сколько раз эти операции выполняются. Как правило, составить список основных операций алгоритма совсем нетрудно. Обычно в него включают наиболее длительные по времени операции, выполняемые во внутреннем цикле алгоритма. Например, в большинстве алгоритмов сортировки используется метод сравнения двух элементов (ключей) списка, который сортируется. Для подобного типа алгоритмов основной является операция сравнения ключей. Таким образом, показатель для анализа временной эффективности алгоритмов будет оцениваться по количеству основных операций, которые должен выполнить алгоритм при обработке входных данных размера n. (3)
Практическая задача
Задание: Дана матрица размерностью NxN, содержащая целые числа. Отсортировать диагонали матрицы, расположенные выше главной по убыванию элементов методом вставки.
Таблица № 5.
| Наименование переменной | Тип | Назначение | |
| Входные данные | c | char | Считывание с файла |
| i, j | int | Переменные для циклов | |
| a[100][100] | int | Считывание массива с файла | |
| s[100] | int | Диагонали считываются в этот массив и передаются в сортирующую функцию | |
| t | int | Счётчик для массива s | |
| Выходные данные | s[100] | int | Отсортированные диагонали |
| a[100][100] | int | Отсортированный массив |
Блок-схема функции insert_sort()
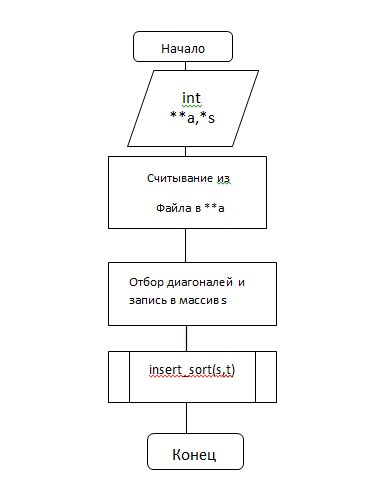
Листинг программы(неполный):
#include <stdio.h>
#include <stdlib.h>
void insertion_sort(int *a,int t);//сортировка
void insert_sort(void);//функция вывода и вызова сортировки массива
void sort_main()
{
int q;
for(;;)
{
printf("Сортировки\n");
printf("1-Задание №1\n");
printf("2-Вернуться в главное меню\n");
do
{
printf("Выберите пункт меню:");
scanf("%d",&q);
}while(q<0||q>3);
switch (q)
{
case 1:
{
insert_sort();system("pause");
system("cls");break;
}
case 2: return;
}
}
}
Полный листинг программы приведен в приложении.
Результат работы программы:

Рис.4.1 Сортировка диагоналей матрицы
Задание № 2: Переписать данные из файла «Сортировка списка(r).txt» в файл «Сортировка списка(w).txt»
отсортировав их в алфавитном порядкe по фамилии и имени методом пузырька.
Таблица № 6.
| Наименование переменной | Тип | Назначение | |
| Входные данные | a[100] | struct | Считывание списка |
| temp | struct | Темповая переменная для сортировки | |
| b[100] | struct | Для отбора с повторяющимися фамилиями | |
| i,j,l,m | int | Переменные для циклов | |
| Выходные данные | b[100] | struct | Отобранные с одинаковыми фамилиями сортируются по имени и заносятся в файл |
Блок-схема функции bubble_sort_fn()

Листинг программы(неполный):
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
void bubble_sort_fn(void);//вывод и сортировка списка по фамилиии и имени
void bubble_sort_fam(struct sp *a,int n);// функция сортирует по фамилии
void bubble_sort_name(struct sp *b,int n);//функция сортирует по имени
struct sp
{
int nm;
char f[30];
char name[20];
char o[25];
int y;
char note[6];
}a[100],temp,b[100];
void sort_main()
{
int q;
for(;;)
{
printf("Сортировки\n");
printf("1-Задание\n");
printf("2-Вернуться в главное меню\n");
do
{
printf("Выберите пункт меню:");
scanf("%d",&q);
}while(q<0||q>3);
switch (q)
{
case 1:
{
bubble_sort_fn();
system("pause");
system("cls");
break;
}
case 2: return;
}
}
}
Полный листинг программы приведен в приложении.
Результат работы программы:

Рис 4.2. Сортировка списка по фамилии и имени
Тема «Линейные списки»
Теоритическая часть
Линейные списки. В математике список – это последовательность элементов одного типа. Важное свойство списка заключается в том, что элементы линейно упорядочены в соответствии с их позицией в списке.
Самый простой способ связать множество элементов – сделать так, чтобы каждый элемент содержал ссылку на следующий элемент последовательности. Такую динамическую структуру называют однонаправленным (односвязным) линейным списком. Если каждый элемент списка содержит две ссылки: одну на следующий элемент, вторую на предыдущий, то такой список называют двунаправленным. А если последний элемент связать указателем с первым, то получится кольцевой список.
На рис.5.1 приведена структура односвязного списка. На нем поле INF - информационное поле, данные, NEXT - указатель на следующий элемент списка. В поле указателя последнего элемента списка находится специальный признак NULL, свидетельствующий о конце списка.

Рис. 5.1. Односвязный список
Однако, обработка односвязного списка не всегда удобна, так как существует возможность перемещения по списку лишь в одну сторону. Такую возможность обеспечивает двусвязный список, каждый элемент которого содержит два указателя: на следующий и предыдущий элементы списка. Структура линейного двусвязного списка приведена на рис.5.2, где поле NEXT - указатель на следующий элемент, поле PREV - указатель на предыдущий элемент. В крайних элементах соответствующие указатели должны содержать NULL, как и показано на рисунке.
Для удобства обработки списка добавляют еще один особый элемент - указатель конца списка. Наличие двух указателей в каждом элементе усложняет список и приводит к дополнительным затратам памяти, но в то же время обеспечивает более эффективное выполнение некоторых операций над списком.

Разновидностью рассмотренных видов линейных списков является кольцевой список, который может быть организован на основе как односвязного, так и двусвязного списков. При этом в односвязном списке указатель последнего элемента должен указывать на первый элемент; в двусвязном списке в первом и последнем элементах соответствующие указатели переопределяются, как показано на рисунке 5.3.
При работе с такими списками несколько упрощаются некоторые процедуры, выполняемые над списком. Однако, при просмотре такого списка следует принять меры предосторожности, чтобы не попасть в бесконечный цикл.

Далее подробно рассмотрим два частных случая однонаправленного списка (стек и очередь) и общий случай двунаправленного списка.
Стек – это частный случай однонаправленного списка, добавление элементов в который и выборка элементов из которого выполняется с одного конца. Другие операции со стеком не определены. При выборке элемент исключается из стека. Стек реализует принцип LIFO (last in – first out, последним пришел – первым вышел).
 Структура содержит базовый элемент, в котором есть:
Структура содержит базовый элемент, в котором есть:
· информационное поле inf, которое может быть любого типа кроме файлового, и будет использоваться для хранения значений, например чисел, строк и др.
· кассылочное поле next, в котором хранится адрес следующего элемента в стеке, и которое будет использоваться для связи элементов стека.

Очередь – это частный случай списка, добавление элементов в который выполняется в один конец, а выборка осуществляется из другого конца. Другие операции с очередью не определены. При выборке элемент исключается из очереди. Очередь реализует принцип FIFO (first in-first out –первым вошел, первым вышел). В программировании очереди применяются при математическом моделировании, буферном вводе-выводе и других задачах.
Организация очереди:

Структура содержит базовый элемент, в котором есть:
· информационное поле inf, которое может быть любого типа, кроме файлового, и будет использоваться для хранения значений.
· ссылочное поле next, в котором хранится адрес следующего элемента очереди, и которое будет использоваться для организации связи элементов. (2)
Практические задачи
Стек
Задание: Создать список из слов,в который все слова исходного текст входят только один раз.
Таблица № 7.
| Наименование переменной | Тип | Назначение | |
| Входные данные | head->a | struct(char) | Информационная часть стека |
| a | char | Считывание строк из файла | |
| *s,p[100][100] | char | Разбиение строк на лексемы, после отбора не повторяющихся слов,заносятся в стек | |
| i | int | Счётчик для массива | |
| cnt | int | Счётчик для отбора слов | |
| Выходные данные | head->a | struct(char) | Слова, которые не повторяются заносятся сюда |
Блок-схема функции stack().

Листинг программы(неполный):
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#define open_file "Невозможно открыть файл.\n"
#define text "Исходный текст:\n"
#define spisok "Исходный список элементов:\n"
#define out_spisok "Полученный список элементов:\n"
struct st
{
char a[100]; //информационное поле целого типа
st *n; //указатель на следующий элемент стека
}*head;
st *in_s()
{
return NULL;
}
void push (st *&s, char i[100]);
char *pop(st *&s);
int empty_st(st *s);
void stack();
void main_menu()
{
int q;
for(;;)
{
printf("1-Стек\n");
printf("2-Вернуться к главному меню\n");
do
{
printf("Выберите пункт меню:");
scanf("%d",&q);
}while(q<0||q>3);
switch(q)
{
case 1:
{
stack();
system("pause");
system("cls");
break;
}
case 2: return;
}
}
}
Полный листинг программы приведён в приложении.
Результат работы программы:

Рис.5.6. Стек из слов
Очередь
Задание: Создать список из чисел. Исключить все повторяющиеся подряд элементы. Оставить по одному из них.
Таблица № 7.
| Наименование переменной | Тип | Назначение | |
| Входные данные | h->inf | int | Информационная часть очереди |
| q[50] | int | Массив из чисел в который считывается из файла | |
| Выходные данные | h->inf | int | Хранятся неповторяющиеся числа |
Блок-схема функции tqueue_f()
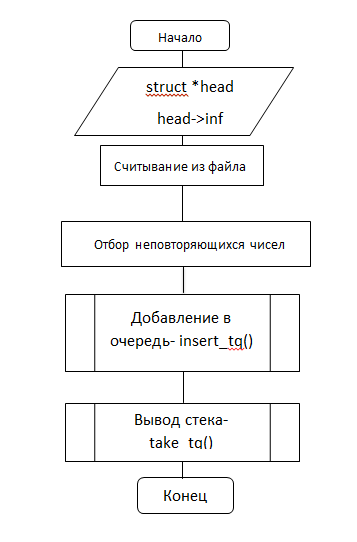
Листинг программы(неполный):
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#define open_file "Невозможно открыть файл.\n"
#define text "Исходный текст:\n"
#define spisok "Исходный список элементов:\n"
#define out_spisok "Полученный список элементов:\n"
struct tqueue
{
int inf;
tqueue *next;
}*h,*t;
void init_tq(tqueue *&h, tqueue *&t);
void insert_tq(tqueue *&h,tqueue *&t, int item);
int take_tq(tqueue *&h, tqueue *&t);
int empty_tq(struct tqueue *h);
void tqueue_f();
void main_menu()
{
int q;
for(;;)
{
printf("1-Очередь\n");
printf("2-Вернуться к главному меню\n");
do
{
printf("Выберите пункт меню:");
scanf("%d",&q);
}while(q<0||q>3);
switch(q)
{
case 1:
{
tqueue_f();
system("pause");
system("cls");
break;
}
case 2: return;
}
}
}
Полный листинг программы приведён в приложении.
Результат работы программы:

Рис.5.7. Элементы очереди