Абстрактные типы данных, типы данных, структуры данных.
Информация поступающая, в ЭВМ состоит из определенных множеств данных, относящихся к какой-то проблеме. Решая любую задачу, необходимо выбрать уровень абстрагирования, т.е. выбрать множество данных, представляющих реальную ситуацию. Т.е. абстрагирование – упрощение данных. Абстракция, называемая абстрактным типом данных создает определяемый пользователем тип данных, чьи операции указывают, как клиент может манипулировать этими данными. Пример: множество целых чисел с их операциями. Абстрактный тип данных – это математическая модель + различные операторы, определенные в рамках этой модели. Абстрактный тип данных (АТД) является независимым от реализации и позволяет программисту сосредоточиться на идеализированных моделях данных и операциях над ними.
Для реализации алгоритма на конкретном языке программирования необходимо найти способ представления абстрактных типов данных в терминах типов данных и операторов, поддерживаемых данным языком программирования. В языках программирования тип данных переменной обозначает множество значений, которое может принимать эта переменная.
Термин реализация абстрактного типа данных подразумевает перевод в операторы языка программирования объявлений, определяющих переменные этого абстрактного типа данных + процедуры для каждого оператора, выполняемого над объектами абстрактного типа данных.
Для представления абстрактных типов данных используют структуры данных, который представляет собой набор переменных, возможно различных типов данных, объединенных определенным образом. Каждая структура данных строится на основе базовых типов данных, применяемых в языках программирования, используя доступные в этом языке средства структурирования данных.
Классификация Структур данных.
К Стандартным простейшим типам относятся типы, встроенные на большинстве ЭВМ. Они являются естественными для большинства языков программирования, и объекты этих типов не могут быть разделены на меньшие части. Набор базовых типов данных отличается в различных языках: в языке паскале - это числа, символы и булевский тип. В СИ - это числа, символы, указатели и определенные пользователем типы перечисления.
Структурированные типы данных имеют компоненты, построенные из простых типов по правилам, определяющим связи между компонентами. Правила конструирования составных типов данных на основе базовых также различаются в языках программирования. Различают фундаментальные и усложненные структуры.
Фундаментальные структуры(молекулы) из которых строятся составные структуры. Такими структурами являются запись, массив (фикс. размера), и множества. К ним с некоторыми ограничениями можно отнести последовательные файлы. Переменные фундаментальных структур могут изменять только свое значение, а их структура и множество допустимых значений остаются неизменными. В результате, размер памяти, занимаемый такими переменными, остается постоянным. Для переменных усложненной структуры характерна способность, изменять в процессе выполнения программы и значения, и структуры. В такой классификации последовательности занимают промежуточное место, длина их меняется, но это изменение структуры носит тривиальный характер.
Структуры данных можно разделить на статические и динамические.
Статическая структура данных – это совокупность фиксированного количества переменных постоянной размерности с неизменным характером связи между ними.
Динамическая структура – это совокупность переменных количество, размерность и характер связи между которыми меняется во время работы программы. В зависимости от способа хранения элементов0 различают структуры данных, хранящие сами элементы данных, структуры данных хранящие указатель на элементы данных.
Структурированные типы данных включают массивы, строки, записи, файлы, списки, стеки и т.д. Эти структурированные типы данных являются примерами коллекций.
Коллекция – это класс памяти с инструментами обработки данных для добавления, обновления и удаления элементов. Бывают линейные и нелинейные коллекции.
Линейная коллекция содержит список элементов, упорядоченных по положению. В этом списке есть первый, второй, третий и т.д. элементы. Пример: массив с индексом.
Нелинейная коллекция определяет элементы без позиционного упорядочивания.
Иерархию коллекцию можно представить след образом.
Коллекция.
Линейные:
С прямым доступом (файлы прямого доступа, массив, запись), последовательным (стек, последовательные файлы, список, очередь, дек), индексным (хеш-таблица, словарь).
Нелинейные:
Иерархические (деревья, НЕАР-дерево), групповые (множество, граф, сеть).
Структура – файлы.
В качестве постоянного носителя для файлов выступает внешняя память, например диск. В зависимости от способа доступа к файлу различают: последовательные файлы и файлы прямого доступа. Последовательный файл характеризуется последовательным размещением его физических элементов в порядке их поступления в файл и доступа к элементам файла в порядке их физического расположения на носителе. Файл прямого доступа является аналогом хеш-таблицы. Отличие заключается в том, что таблица размещается в оперативной памяти, а файл на внешнем устройстве прямого доступа. Функция преобразования ключ - адрес записи на носителе и разрешения коллизий поддерживается прикладной программой.
Структура – массив.
Это коллекция элементов, имеющих один и тот же тип данных с прямым доступом по средствам целого индекса. Элементами массива могут быть числа, символы, строки, структуры. Статический массив содержит фиксированное количество элементов и задается в памяти во время компиляции. Динамический массив создается с использованием методов динамического распределения памяти, и его размер может быть изменен. Массив – это структура данных, которая может быть использована для хранения списка.
Структура – запись.
Запись – базовая структура, которая связывает элементы различных типов в один объект. Элементы записи называются полями и в свою очередь могут быть составными. Запись имеет оператор доступа, который делает возможным прямой доступ каждому полю. Но в отличие от массива, запись описывает единственное значение, а не список значений Записи как правило используются в других более сложных структурах (таблицах, файлах, базах данных). в СИ запись получила название структура (struct).
Struct student
{
int id;
Char name[20];
};
Коллекция с последовательным доступом. Более общей коллекций является список, сохраняющий элементы в последовательном порядке. Реализовать списки можно с помощью массивов и указателей. При реализации списков с помощью массивов элементы списка располагаются в смежных ячейках массива. Это представление позволяет легко просматривать содержимое списка и вставлять новые элементы в его коллекции. Но вставка нового элемента в середину списка требует перемещения всех последующих элементов на одну позицию к концу массива, чтобы освободить место для нового элемента. Удаление элемента также требует перемещение элементов, чтобы закрыть освободившуюся ячейку. При использовании массива, мы определяем тип лист как запись, имеющую два поля: 1. Элементы массива, размер которого считается достаточным для хранения списков любой длины. 2. Целочисленного типа указывает на позицию последнего элемента списка в массиве.
Struct list
{
Int mas[30];
Int last;
};
При реализации списков помощью указателей, независимые элементы в связанном списке называют узлами. Узел (node) состоит из поля данных и указателя обозначающего следующий элемент в списке. Связанный список состоит из множества узлов, первый элемент которого – это узел, на который указывает голова. Список связывает узлы от первого до хвоста. Хвост определяется как узел, чье поле указателя содержит пустое значение (NULL). Для списка без узлов голова будет одержать значение NULL. Таким образом, списковая структура данных представляет собой множество переменных, связанных между собой указателями. Каждый элемент такой структуры содержит 1 или несколько указателей на аналогичные элементы.
Struct node
{
Int data;
Node *next; // единственный указатель
Node *prev, *next;
Node *link [10];
Node **plinks;
};
Списки бывают: односвязный список (в котором каждый элемент списка имеет указатель на следующий), двусвязный (в котором каждый элемент списка имеет указатель на следующий и на предыдущий), двусвязный циклический список (в котором первый и последний элементы списка ссылаются друг на друга таким образом, что цепочка представляет собой кольцо).
Для односвязного списка наиболее простыми являются операции включения и исключения элементов в начале и конце списка, поэтому они используются для моделирования таких структур как стеки и очереди. Стеки и очереди – это особые версии линейного списка с ограниченным доступом к элементам данных. В стеки элементы добавляются и удаляются только в один конец списка, называемый вершиной. LIFO – тип хранения в стеке. Абстрактные типы данных семейства стек обычно используют следующие пять операторов: 1. Push – вставляет элемент в вершину стека. 2. Pop – служит для извлечения или удаления элемента из вершины стека. 2. Top (pick) – возвращает значение элемента из вершины стека. 4. Stack Empty – возвращает единицу, если стек пустой и ноль в противном случае. 5. Clear Stack – делает стек пустым.
Очередь – это список с доступом в начале и в конце. Элементы вставляется в конец списка, а удаляются из начала. Тип хранения соответствует FIFO. Для работы с очередями используются следующие операторы: 1. QInsert - записывает элемент в конец очереди. 2. QDelete – удаляет элемент из начала очереди. 3. Qfront - возвращает значение элемента в начале очереди. 4. Qlen – определяет количество элементов в очереди. 5. QEMPTY – возвращает 1 если очередь пуста, 0 в противном случае. 6. QClear – очищает очередь.
Для некоторых приложений мы можем изменить структуру очереди, устанавливая очередность элементов. Это так называемая очередь приоритетов, где вставляются данные являются несущественными. Важно то, что при удалении удаляется элемент с наивысшим приоритетом. Дек – это разновидность очереди, в которой включение и выборка элементов возможна с обоих концов. Выделяют две разновидности дека. Дек с ограниченным входом и дек с ограниченным выходом. Дек с ограниченным входом допускает включение элемента только на одном конце и выборку с обоих концов. Дек с ограниченным выходом допускает выборку только с одного конца. Для реализации используют двусвязные списки. Деки используются при управлении памятью, когда распределение памяти производится и сверху и снизу.
Нелинейные коллекции
Иерархическая коллекция – это масса элементов, которые разделяются по уровням. В иерархическую коллекцию входят все разновидности деревьев. А дерево - это структура, состоящая из узлов и ветвей, и имеющих направление от корня ко всем последующим потокам.
HEAP –дерево, особая версия дерева, в котором самый маленький элемент всегда занимает корневой узел. Удаление корневого узла вызывает такую реорганизацию дерева, что маленький элемент вновь занимает корень такого дерева. Эта структура использует очень эффективные алгоритмы реорганизации дерева, просматривая только короткие пути от корня вниз к концу дерева. ХЕАП-дерево может использоваться для упорядочивания списка элементов.
Коллекция групп представляет те нелинейные коллекции, которые содержат элементы, без какого либо упорядочивания.
Множество – это коллекция находящая применение, когда данные являются неупорядоченными, и каждый элемент данных является, единственны в своем роде, уникальным.
Граф – структура данных G=<V,E>. Дающая набор вершин и связей, связывающих эти вершины.
Сеть – это особая форма графа, которая присваивает вес каждой связи.
ЛАБА – построение таблицы хеширования.
Хеширование. Хеш-функции. Методы устранения коллизий.
Хеширование является самым быстродействующим из известных методов программного поиска. Термин хеширование произошел от английского глагола «to hash» (крошить, нарезать, делать месиво). Для методов хеширования встречаются следующие термины: рассеянная память, адресация вразброс, адресация с перемешиванием, ключевые преобразования, расстановка. Данный метод не требует никакого упорядочивания или сортировки ключевых слов. Высокая скорость выполнения операции хеширование обусловлена тем, что элементы данных запоминаются и впоследствии выбираются из ячеек памяти, адреса которых являются простыми арифметическими функциями содержимого соответствующих ключевых слов. Адреса, получаемые из ключевых слов методом хеширования, называются хеш адресами. Таким образом, идея хеширования состоит в том, чтобы взять некоторые характеристики ключа с помощью, так называемой хеш-функции и взять это значение в качестве адреса начала поиска, то есть k храниться по адреса F(k). С хеш-функцией связана так называемая хеш-таблица, ячейки которой пронумерованы и хранят сами данные или ссылки на данные. Однако функции, дающие неповторяющиеся значения редки даже в случае большой таблицы. Возможно, что найдутся различные ключи ki=!kj, для которых F(ki)=F(kj). Таким образом, часто отображение, осуществляемое хеш-функцией, является отображение многие к одному и приводит к коллизии. При возникновении коллизии два или более ключа ассоциируются с одной и той же ячейкой хеш-таблицы. Поскольку два ключа не могут занимать одну и ту же ячейку в таблице, необходимо выбрать стратегию разрешения коллизий, то есть метод, указывающий альтернативное местоположение элемента. Следовательно, чтобы использовать хеш-таблицу, программист должен выбрать хеш-функцию и метод разрешения коллизий.
Хеш-функция, не порождающая коллизий, называется совершенной. Нет смысла искать совершенную хеш-функцию, если множество ключей является постоянным. Однако, для таблицы символов компилятора, содержащего зарезервированные слова, совершенная хеш-функция крайне желательна, т.к. в этом случае для определения, является ли некоторый идентификатор зарезервированным словом, потребуется одна проба. Хеш-функция должна отображать ключ в целое число. При этом количество коллизий должно быть ограниченным, а вычисление самой хеш-функции очень быстрым. Рассмотрим методы, которые удовлетворяют этим требованиям.
1. Метод деления. Требует двух шагов. Сперва, ключ преобразуется в целое число, а затем полученное значение вписывается в диапазон 0….(n-1) с помощью оператора получения
остатка.
2. Метод умножения. Вначале, с его помощью получается нормализованный хеш-адрес h(k), принадлежащий интервалу [0,1). h(k) Назовем величину, вычисляемую следующим образом (c*k) mod 1, где k – элементы, ключи, c- некоторая константа [0,1). Итоговый хеш-адрес обозначим f(k) вычисляется как h(k)*t, где t – размер хеш-таблиц. Качество хеширования по этому методу зависит от выбора константы C. Хорошие результаты дает константа C = 0,618034 (золотое сечение).
3. Метод середины квадрата. Предусматривает преобразование ключа в целое число, возведение его в квадрат и возвращение в качестве значения функции последовательности цифр, извлеченного из середины этого квадрата. F(k)= k2 % 100.
4. Метод алгебраических преобразований над ключом. Позволяет получать хеш-адреса путем выполнения алгебраических действий над цифрами, из которых состоит ключ. Например, сложение по модулю пары соседних цифр ключа, получение суммы всех цифр ключа.
5. Метод усечения. При этом подходе из ключа выделяются определенные биты, которые определяют хеш-адрес элемента. 761819 > 76|18|19.
Не смотря на то, что два или более ключей могут хешироваться одинаково, они не могут занимать в хеш таблиц одну и ту же ячейку. Остается два пути: 1. Найти для нового ключа другую позицию в таблице. 2. Создать для каждого значения хеш-функции отдельный список, в котором будут все ключи, отображающиеся при хешировании в это значение. Первый вариант получил название открытая адресация с линейным или квадратичным опробованием. Второй – метод цепочек.
Открытая адресация предполагает, что каждая ячейка таблицы помечена как незанятая, поэтому при добавлении нового ключа всегда можно определить, занята ли данная ячейка таблицы или нет. Если да, то есть, занята, алгоритм осуществляет опробование по кругу, пока не встретится свободное место, то есть открытый для размещения адрес.
В линейном пробинге к хеш адресу прибавляется или вычитается по единице, пока не обнаружится незанятая ячейка. аi =(a0+i)mod t. аi – номер пробы, а t - размер хеш таблицы. T >= 1,5*n. При квадратичной пробе расчет ведется по той же формуле, но при i^2. N - Общее количество ключей. Небольшой недостаток квадратичных проб заключается в том, что при поиске пробуются не все строки таблицы, т.е. при включении элемента может не найтись свободного места, хотя на самом деле оно есть. Если размер T – простое число, то при квадратичных пробах рассматривается, по крайней мере, половина таблицы.
6. метод устранения – метод цепочек.
При этом подходе к хешированию, таблица рассматривается как массив связанных списков. Каждая такая цепочка называется блоком и содержит записи отображаемой хеш функции в один и тот же табличный адрес. Чтобы обнаружить элемент данных, нужно применить хеш функцию для определения нужного связного списка и выполнить там последовательный поиск. Пример таких цепочек размер таблицы T, рекомендуется брать от 1/3n от количества элементов до 1/2n. В общем случае, метод цепочек быстрее открытой адресации, т.к. просматривает только те ключи, которые попадают в один и тот же табличный адрес. Кроме того, открытая адресация предполагает наличие таблицы фиксированного размера, в то время как в методе цепочек элементы таблицы создаются динамически.
1. Наибольшее применение метода хеширования получило системное программирование. В настоящее время все символьные таблицы строятся по методу хеширования.
2. Управление базами данных.
3. Применяется для организации таблиц, используемых в языках искусственного интеллекта.
4. Защита информации, криптографии, кодировании.
Пример. Требуется построить хеш таблицу, содержащую следующие ключи: 25 15 17 29 11 36 89 84 61 83
Хеш функция – сумма цифр ключа.
Вариант 1 – линейные пробы.
N=10. T=1.5*10=15. 0..14.
F(25)=7
F(15)=6
F(17)=8
F(29)=11
F(11)=2
F(36)=9
F(89)=17%15=2
A1=(2+1)%15=3
F(84)=12
F(61)=7…=10
F(83)=11
A1=(11+1)%15=12
A2=(11+2)%15=13
Вариант 2. – квадратичные пробы.
F(61)
A1=(7+1^2)%15=8
A2=(7+2^2)%15=11
A3=(7+3^2)%15=1.
Вариант 3. – метод цепочек.
T=1/2*10=5
Деревья.
Деревья – нелинейная структура, которая состоит из узлов и ветвей и имеет направлением от единственного начального узла, называемого корнем к внешним узлам, называемым листьями. Каждый узел дерева является корнем поддерева, который определяется данным узлом и всеми потомками этого узла. Прохождение от родительского узла к его дочернему дереву и его потомкам осуществляется вдоль путей. Путь от корня к узлу дает меру, называемую уровнем узла. Уровень узла – длина пути от корня к этому узлу. Глубина дерева – максимальный уровень любого его узла.
Выделим виды рассматриваемых деревьев: 1. Бинарные (идеально сбалансированные, поисковые, сбалансировано-поисковые) 2. Сильноветвящиеся (Б-дерево).
Бинарные деревья – упорядоченные деревья второй степени. Это такое множество узлов B, что это множество – дерево, если множество узлов пусто. B разбивается на три пересекающихся подмножества. D – коневой узел {l1, l2,…,} – левое поддерево, {r1,r1…} – правое поддерево. Бинарное дерево является рекурсивной структурой, т.к. каждый узел – это корень своего собственного поддерева, у которого в свою очередь есть потомки. Процедуры обработки деревьев тоже рекурсивны. На любом уровне n бинарное дерево может содержать от 1 до 2^n узлов. Число узлов, приходящееся на уровень, является показателем плотности дерева. Крайними мерами плотности дерева являются с одной стороны – вырожденное дерево (у которого есть! лист и, каждый листовой узел имеет только одного сына), с другой стороны – это законченное и полное дерево. Законченные бинарное дерево на каждом уровне о..n-1 имеет полный набор вершин, а все листья уровня n расположены слева. Законченное бинарное дерево, содержащее 2^n узлов на уровне n является полным. ∑ узлов = 2^(n+1)-1. Двоичные деревья часто используются для представления множества данных, среди которых идет поиск по уникальному ключу. Структура дерева построена из узлов, соответственно узел дерева содержит поле с данными и два указателя: на левый и на правый. Left|data|right------Null|data|Null.
Корневой узел определяет входную точку дерева, а поле указателя – узел следующего уровня. Листовой узел содержит нулевое значение в поле правого и левого указателя.
Struct node
{
int data
Node data
Node *left;
Node * right;
}
Рекурсивные методы прохождения деревьев.
Рекурсивное определение бинарного дерева определяет эту структуру, как корень с двумя поддеревьями. Сила рекурсии проявляется вместе с методами прохождения. Каждый алгоритм прохождения дерева выполняет в узле три действия: 1. Заходит или посещает узел. 2. Рекурсивно спускается по левому поддереву. 3. Рекурсивно спускается по правому поддереву. Спустившись по дереву, алгоритм определяет, что он находится в узле и может выполнить те же три действия. Спуск прекращается по достижению пустого дерева. Различные алгоритмы рекурсивного прохождения отличаются порядком, в котором они выполняют свои действия в узле. Рассмотрим прямой, симметричный и обратный методы прохождения.
Прямой метод определяется посещением узла в первую очередь и последующим прохождением сначала левого, а потом правого поддеревьев:
1) Посещение узла N 2) Прохождение левого поддерева 3) Прохождение правого поддерева
Симметричный метод 1) начинает свои действия в узле спуском по его левому поддереву, 2) затем выполняется второе действие обработки данных в узле 3) далее рекурсивное прохождение правого поддерева.
При обратном прохождении посещение узла откладывается до тех пор, пока не будут рекурсивно пройдены оба его поддерева: 1) Рекурсивное прохождение левого поддерева 2) Рекурсивное прохождение правого поддерева 3) прохождение узлов.
В каждом рассмотренном случае, сначала осуществлялось прохождение по левому поддереву, а уже потом по правому. Фактически существует еще три алгоритма, которые выбирают сначала правое поддерево, а потом левое.
Пример.
Рисунок…

Прямой A B D F E G L L C H I M K R
Симметричное F D B E L G L A M C M I K R
Обратное F D L G E B L H M K I C A R
Бинарные деревья.
Идеально сбалансированное дерево. n элементов. Пусть у нас дано n элементов, из которых нужно построит дерево минимальной глубины. Минимальная высота при заданном числе вершин достигается, если на всех уровнях кроме последнего помещается максимально - возможное число вершин. Этого легко добиться, размещая приходящие вершины поровну слева и справа от каждой вершины. Дерево называется идеально сбалансированным, если число вершин в его левых и правых поддеревьях отличается не более чем на единицу. Алгоритм построения идеального дерева состоит из трех шагов: 1) Взять одну вершину в качестве корня. 2) Тем же способом построить левое поддерево с количеством вершин nl=nDIV2. 3) Тем же способом построить правое поддерево nr=n-nl-1. Заполнение идеально сбалансированного дерева осуществляется согласно прямого метода прохождения, т.е. элементы заносятся в следующем порядке: первый элемент становится корнем, затем для каждой вершины поддерева уровня H вначале заполняется его левое поддерево, а затем правое.
Void Insert (int key, **T)
{ Node *new node;
If (T==0)
{
Newnode= new
Newnode->data=key;
Newnode->left= NULL;
newnode->right=NULL;
*T=new;
}
}
Tree *tree (int n, int *k)
{
Node *newnode;
Int nl, nr;
If (n==0)
newnode=0;
else
{
nj=n/2; nr=n-nl-1;
newnode=new;
newnode->data=k[i++];
newnode->left=tree (nl, *k);
newnode->right=tree (nr, *k);
}
Return newnode;
}
Пусть надо построить идеально сбалансированное дерево, содержащее n=11 количество вершин
17 1 4 7 13 84 3 15 52 45 46.

Бинарное дерево поиска.
Структура дерева, которая позволяет обеспечить эффективный доступ к элементам. Эта структура, называемая бинарным деревом поиска, упорядочивает элементы по средствам оператора отношения, чтобы сравнить узлы дерева, мы подразумеваем, что часть или все поле данных определено в качестве ключа, и оператор сравнивает ключи, когда размещает элемент на дереве. Бинарное дерево поиска строится по следующему правилу: для каждого узла значение данные в левом поддереве меньше чем в этом узле, а в правом дереве больше или равны.

Сбалансированно-поисковая. AVL– tree.
Рассмотрим модифицированный класс деревьев, обладающих всеми преимуществами бинарных деревьев поиска и никогда не вырождающихся.
Определение. Дерево называется сбалансированным тогда и только тогда, когда высоты двух поддеревьев каждой из его вершин отличаются не более чем на единицу.
AVL дерево представляет собой списковую структуру, похожую на бинарное дерево поиска с одним дополнительным условием: дерево должно оставаться сбалансированным по высоте после каждой операции включение или удаление. Для постоянного отслеживания соотношения высот левого и правого поддеревьев вводят показатель сбалансированности (баланс), который содержит разность высот левого и правого поддеревьев. Если баланс<0 узел перевешивает влево. Если показатель сбалансированности больше нуля, узел перевешивает вправо. Если показатель сбалансированности =0, то высота левого и правого поддерева равны, т.е. в AVL дереве показатель сбалансированности может принимать значения {-1,0,1}.
Процесс включения вершины состоит из следующих трех, последовательно выполняемых частей: 1. прохождение по пути поиска, пока не убедимся, что ключа в дереве нет. 2. Включение новой вершины и определение показателей сбалансированности, т.е. отступление по пути поиска и проверка в каждой вершине показателя сбалансированности. 3. Если необходимо, то проведение балансировки.
Балансировка.
Операция по балансировке состоит из последовательных переприсваиваний ссылок. Фактически, ссылки циклически м5няются местами, что приводит к одно-, или двукратному повороту двух и трех участвующих в процессе вершин. Кроме вращения ссылок нужно должным образом поправить показатель сбалансированности соответствующих вершин.
Повороты необходимы в том случае, когда родительский узел P становится разбалансированным.
Одинарный LL поворот происходит, когда Родительский узел P его левый L начинает перевешивать влево после включения узла в позицию X.

Однократный RR поворот возникает, когда родительский узел P и его правый сын R начинают перевешивать вправо после включения узла в позицию X.







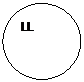
|



 Возникает, когда двойной узел P становится перевешивающим влево, а его левый сын L перевешивающим вправо. В результате поворота, узел LR замещает своего родителя P, а бывший родитель P становится правым сыном LR.
Возникает, когда двойной узел P становится перевешивающим влево, а его левый сын L перевешивающим вправо. В результате поворота, узел LR замещает своего родителя P, а бывший родитель P становится правым сыном LR. 
Двойной поворот влево или двойной RL поворот возникает в том случае, когда родительский узел P перевешивает вправо после включения узла в позицию X.
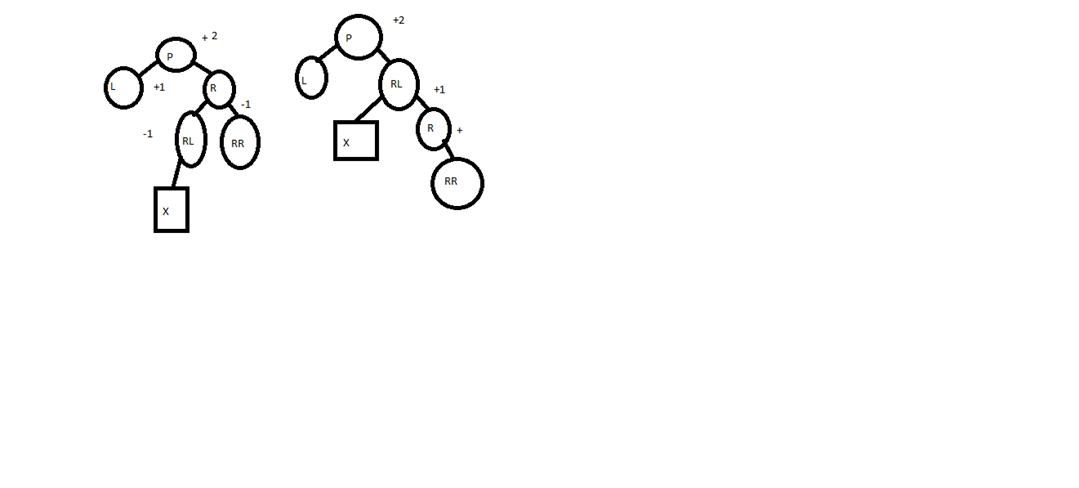
Удаление и исключение из сбалансированного дерева.
При удалении из AVL дерева возможно три варианта: 1. Исключаемый элемент является листом, т.е. не имеет потомков. В этом случае удаляется ссылка на этот элемент и проверяется, не нарушился ли баланс. Если необходимо, проводится балансировка. 2. Исключаемый элемент – терминальная вершина, т.е. имеет одного потомка. В этом случае исключаемый элемент заменяется на своего единственного потомка и проверяется, не нарушился ли баланс. Если необходимо, опять балансировка. 3. Удаляемый элемент- вершина с двумя потомками. В этом случае исключаемый элемент заменяется, либо на самый правый элемент левого поддерева (на самый большой в левом), либо на самый левый в правом. Балансировка (в то время, как включение одного узла может привести к одному повороту, исключение может потребовать поворота во всех вершинах вдоль пути поиска).
Д/З
16, 4, 93, 47, 14, 66, 255, 13, 4, 31, 552, 41, 74, 39. Идеально-сбалансированное,поисковое, AVL.
Сильно-ветвящиеся В деревья.
Для некоторых приложений необходимы деревья, имеющие вершины со многими ветвями. Практической областью сильно применения сильно ветвящихся деревьев является формирование и поддержание крупномасштабных деревьев поиска, но для которых либо не хватает оперативной памяти. В этом случае вершины дерева хранятся во внешней памяти и ссылки представляют собой адреса на внешне запоминающем устройстве, а не в оперативной памяти. Поскольку, в этом случае, каждый шаг включает обращение к внешнему запоминающему устройству, то желательно организация памяти, требующая меньшего числа обращений. Для этого предполагается, что дерево разбито на поддеревья, и каждый шаг предполагает обращение к целой группе элементов, которые одновременно доступны. Такие поддеревья называют страницами.
Обозначим через n порядок дерева. m - число элементов на странице. В таких обозначениях B дерево порядка n называется структура, обладающая следующими свойствами: 1. Каждая страница содержит число элементов не более m<=2n. 2. Каждая страница за исключением корневой, содержит не менее m>=n элементов. N<=m<=2n. 3. Каждая страница либо является листом (не имеет потомков), либо имеет m+1 потомков. 4. Все страницы листья находятся на одном уровне.
Включение B дерева происходит за один шаг, если у нас m<2n и за 3 шага, если m=2n. 1 шаг: проверяете, есть ли ключ в дереве. Если его нет, происходит включение. Проверяется, если страница c заполнена, и включение в неё невозможно, то переходим к шагу 2. Ы. 2 шаг: если страница c разделяется на две страницы c и d. 3 шаг: ключи, их в этот момент 2n+1 поровну распределяются между страницами c и d, а средний по значению ключ переносится на один уровень вверх на родительскую страницу.
Пример 1. (он ужасен и расположен в тетради…)
Графы и алгоритмы на графах.
ГрррРРррафы! Являются обобщенными иерархическими структурами. G=<V,E> V- множество вершин, E – ребра или дуги.
Способы машинного представления графа.
Рассмотрим несколько способов представления графов с оценкой их достоинств и недостатков. 1. Классическим способом представления графов служит матрица инциденции. Эта матрица Aij размера nxm где n - число строк, соответствующие вершинам, m – число столбцов, которое равно числу ребер. В случае неориентированного графа, столбец, соответствующий ребру [Vi, Vj] содержит единиицу в строках соответствующих вершине Vi, так и в строке Vj и нули в остальных строках. Для ориентированного графа столбец соответствующий дуге <Vi, Vj> содержит
-1 в строке соответствующей Vi и 1 в строке соответствующей вершине Vj и нули во всех остальных строках.

| 1,2 | 1,4 | 2,3 | 2,4 | 3,4 | |
| -1 | -1 | ||||
| -1 | |||||
| -1 | -1 | ||||
С алгоритмической точки зрения, матрица инциденции является самым худшим способом представления графа, т.к.:1. Требует m*n ячеек памяти, большинство из которых заполнены нулями. 2. Неудобен доступ к информации, т.к. определение «существует ли дуга Vi Vj» требует в худшем случае перебора всех столбцов матрицы=> m шагов.
2 способ – матрица смежности. Также определим её как Aij=1, если существует ребро ij и Aij = 0, если такого ребра не существует. Причем для неориентированного графа (ij)=(ji).
Недостаток – независимо от числа ребер, объем заданной памяти n*n=n2.
3 способ
Более экономно в отношении памяти, особенно в случае неплотных графов (когда m<n2) является метод представления графа с помощью списка пар, соответствующих его ребрам. Неудобством является больше число шагом, необходимое для получения множества вершин порядка m, к которым ведут ребра из данной вершины.
Списки инцидентности.
В этом способе представления графа, каждая вершина ассоциируется со связным списком смежных с ней вершин. Эта динамическая модель хранит информацию лишь о фактически принадлежащих графу вершинах.
| •→ | •→ | NULL | |||
| •→ | NULL | ☻ | ☻ | ||
| NULL | ☻ | ☻ | ☻ | ☻ | |
| •→ | •→ | NULL |
Способы прохождения графов.
Существуют много алгоритмов на графах, в основе которых лежит систематический перебор вершин графа, такой, что каждая вершина просматривается в точности 1 раз.
Рассмотрим два алгоритма поиска на графе. Они получили названия «Поиск в глубину» и «поиск в ширину». Начальная вершина передается в качестве параметра и становится первой обрабатываемой вершиной. Начинается итерационный процесс, на каждом шаге к