СОДЕРЖАНИЕ
| Стр. | ||
| ВВЕДЕНИЕ | 3 | |
| 1. ТЕОРЕТИЧЕСКАЯ ЧАСТЬ | 4 | |
| 1.1. Обзор методов и алгоритмов работы интерпретатора языка МИЛАН | 4 | |
| 1.2. Грамматика модифицированного языка МИЛАН в виде диаграмм Вирта | 4 | |
| 1.3. Описание лексического анализатора модифицированного языка МИЛАН | 8 | |
| 1.4. Описание процесса расстановки ссылок модифицированного языка МИЛАН | 14 | |
| 1.5. Описание интерпретатора модифицированного языка МИЛАН | 19 | |
| 2. ИССЛЕДОВАТЕЛЬСКАЯ ЧАСТЬ | 27 | |
| 2.1. Программная реализация интерпретатора модифицированного языка МИЛАН | 27 | |
| 2.2. Разработка тестов и тестирование модифицированного языка МИЛАН | - | |
| ЗАКЛЮЧЕНИЕ | - | |
| СПИСОК ЛИТЕРАТУРЫ | - |
ВВЕДЕНИЕ
Курсовая работа – заключительный этап изучения дисциплины.
Цель курсовой работы: разработка интерпретатора языка МИЛАН с незначительными модификациями.
Программная реализация интерпретатора выполнена на языке PHP. Входной язык интерпретатора удовлетворяет следующим требованиям:
- входная программа может быть разбита на строки произвольным образом, все пробелы и переводы строки должны игнорироваться компилятором;
- текст входной программы может содержать <оператор-переключатель>:
SWITCH (< выражение >)
{
CASE < константа >: < последовательность операторов >
{ CASE < константа >: < последовательность операторов > }
[ DEFAULT: < последовательность операторов > ]
}
- текст входной программы может содержать < цикл-FОR >:
FOR < идентификатор >:= < выражение > TO < выражение >
[ STEP < выражение > ] < последовательность операторов > ENDFOR
- текст входной программы может содержать < оператор-инкремент >: ++
- текст входной программы может содержать комментарии любой длины, которые должны игнорироваться интерпретатором: комментарий в круглых скобках со звездочками. Пример: (* раздел описания переменных *).
ТЕОРЕТИЧЕСКАЯ ЧАСТЬ
1.1. Обзор методов и алгоритмов работы интерпретатора языка МИЛАН
Работа интерпретатора производится в два этапа: лексический и синтаксический анализ.
На этапе лексического анализа, осуществляемого лексическим анализатором соответственно, выполняется анализ входного текста и группировка символов входной цепочки в более крупные единицы – лексемы. Группировка входной последовательности символов программы на лексемы удобно для дальнейшей обработки синтаксическим анализатором. Так же в задачи лексического анализатора входит расстановка ссылок управляющих конструкции.
Синтаксический анализатор, проводя анализ лексем, распознает конструкции языка и выполняет заданные действия – таким образом, синтаксический анализатор выполняет и функцию интерпретации.
1.2. Грамматика модифицированного языка МИЛАН в виде синтаксических диаграмм Вирта
Грамматика в виде диаграмм Вирта представляет собой схематическое описание какого-либо нетерминального символа языка. В качестве начального нетерминального символа выбран нетерминал «программа». Каждая программа начинается со слова BEGIN и заканчивается словом END. Между этими словами расположены операторы, разделенные символом «; ». Типов операторов в расширенной грамматике МИЛАНа пять: вывод, присваивание, инкремент, развилка, цикл. По принципу вложенности диаграммы Вирта описывают возможные конструкции языка и выражение их через терминальные и нетерминальные символы. Множество терминальных символов модифицированного языка представлено в таблице 1.
Таблица 1
Терминалы грамматики языка МИЛАН
| Терминалы | Обозначения |
| Служебные слова | BEGIN, CASE, DEFAULT, DO, ELSE, END, ENDDO, ENDFOR, ENDIF, FOR, IF, OUTPUT, READ, STEP, SWITCH, THEN, TO, WHILE |
| знаки операций и отношений | +, ++, -, *, /, =, >, <, >=, <=, <> |
| латинские буквы в нижнем регистре | a, b,..., z |
| цифры | 0, 1,..., 9 |
| знак присваивания | := |
| разделитель операторов | ; |
| знаки комментария | (*, *) |
| знаки конструкций | (,), {, },: |
Диаграммы Вирта для группы нетерминалов 1 («программа», «комментарий» и «последовательность операторов») представлены на рисунке 1.

Рисунок 1 – Группа нетерминалов 1
Блок комментария введен в грамматику формально, так как не будет вводиться на уровне лексем. Еще на этапе лексического анализа скобки комментария и любые заключенные в них символы будут игнорироваться. Таким образом, комментарий можно вставлять произвольно по тексту программы, нетерминал «текст комментария» подразумевает множество любых символов.
Диаграмма Вирта для нетерминала оператор представлена на рисунке 2.

Рисунок 2 – Нетерминал «оператор»
В качестве условия используется пара выражений, разделенных знаками отношения. Соответствующая диаграмма представлена на рисунке 3.

Рисунок 3 – Нетерминал «условие»
Группа нетерминалов 2 («выражение», «терм» и «множитель») позволяют составлять различные выражения в конструкциях, и представлены на рисунке 4.

Рисунок 4 – Группа нетерминалов 2
Нетерминальные символы «идентификатор» и «константа» представлены на рисунке 5.

Рисунок 5 – Нетерминалы «идентификатор» и «константа»
Группа нетерминалов 3 замещаются терминальными символами и представляют собой минимальные единицы языка («операция отношения», «цифра», «буква», «операция умножения», «операция сложения») представлены на рисунке 6.

Рисунок 6 – Группа нетерминалов 6
1.3. Описание лексического анализатора модифицированного языка МИЛАН
Лексический анализатор (ЛА) выделяет в поданой последовательности символов простейшие конструкции языка – лексические еденицы. Затем лексические единицы заменяются их внутренним представлением – лексемами, которые включают в себя вспомогательную информацию о лексеме (класс и значение). Происходит построение таблицы массива лексем. Для работоспособности управляющих конструкций языка лексический анализатора проводит простановку ссылок на соответсвующие лексемы. Для таких классов лексических единиц, как идентификаторы и константы строятся отдельные таблицы.
Выделение лексем позволяет сократить объем информации, поступающей на вход синтаксического анализатора и делает сам анализ болле удобным.
Для расширенного языка МИЛАН используются определения лексем, представленные в таблице 2.
Таблица 2
Таблица лексем
| Название лексемы | Код | Запись в языке | Обозначение | Значение | ||
| Служебные слова: BEGIN DO ELSE END ENDDO ENDIF IF OUTPUT READ THEN WHILE | BEGIN DO ELSE END ENDDO ENDIF IF OUTPUT READ THEN WHILE | BEGIN DO ELSE END ENDDO ENDIF IF OUTPUT READ THEN WHILE | Ссылка на лексему после ENDDO Ссылка на лексему после ENDIF Ссылка на лексему после WHILE Ссылка на лексему после ENDIF или ELSE | |||
| Точка с запятой | ; | tz | ||||
| Знак отношения: = <> > < >= <= | = <> > < >= <= | otn | k(=)=0 k(<>)=1 k(>)=2 k(<)=3 k(>=)=4 k(<=)=5 | |||
| Операция типа сложения: + - | + - | ots | k(+)=0 k(-)=1 | |||
| Операция типа умножения: * / | * / | otu | k(*)=0 k(/)=1 | |||
| Присваивание | := | oprsv | ||||
| Открывающаяся скобка | ( | os | ||||
Продолжение таблицы 2
| Название лексемы | Код | Запись в языке | Обозначение | Значение |
| Закрывающаяся скобка | ) | zs | ||
| Идентификатор | a, b23 | id | Указатель на таблицу идентификаторов | |
| Константа без знака | 32, 0274 | int | Указатель на таблицу констант | |
| Добавлено | ||||
| Служебные слова: CASE DEFAULT ENDFOR FOR STEP SWITCH TO | CASE DEFAULT ENDFOR FOR STEP SWITCH TO | CASE DEFAULT ENDFOR FOR STEP SWITCH TO | Ссылка на лексему TO Ссылка на лексему после ENDFOR | |
| Инкремент | ++ | inc | ||
| Двоеточие | : | td | Ссылка на лексему CASE, DEFAULT или } | |
| Начало SWITCH | { | bswch | ||
| Конец SWITCH | } | eswch | ||
| Открытие комментария | (* | ocom | ||
| Закрытие комментария | *) | zcom |
Синтаксическая диаграмма (R-схема) расширенного лексического анализатора языка МИЛАН описывающая построение массива лексем, таблицы констант и идентификаторов представлена на рисунке 7.
Обозначение к R-схемелексического анализатора:
$Position - текущая позиция в строке, просматриваемая ЛА;
$Number_String - текущая строка программы, просматриваемая ЛА;
* - любой символ).
 Рисунок 7 – R-схема лексического анализатора
Рисунок 7 – R-схема лексического анализатора
Семантические функции к R-схеме лексического анализатора:
y0: подготовка (инициализация таблиц и переменных), $Position=0, $Number_String=1;
y1: чтение следующего символа программы на языке МИЛАН;
y2: увеличение счётчика текущей позиции ($Position++);
y3: переход на новую строку в программе, увеличение счётчика текущей строки, и сброс счётчика позиции ($Number_String++, $Position=0);
y4: накопление символов ключевого слова или идентификатора;
y5: проверка на принадлежность выделенного слова к ключевым словам;
y6: проверка на принадлежность выделенного слова к идентификаторам;
y7: накопление символов константы;
y8: проверка на принадлежность выделенной константы таблице констант;
y9: запись сформированной лексемы в массив лексем;
y10: завершение работы лексического анализатора;
y11: формирование лексемы;
Пример №1. Рассмотрим пример обработки лексическим анализатором программы на расширенном языке МИЛАН, содержащей все операторы языка и осуществляющей разбиение числа на единицы, сотни, десятки.
Листинг программы:
BEGIN
next:=1;
rng:=1;
c1:=READ;
c2:=c1;
WHILE next=1 DO
c1:=c1/10;
IF c1=0 THEN
next:=0
ELSE
rng++
ENDIF
ENDDO;
OUTPUT(rng);
FOR k:=1 TO rng
SWITCH(k)
{
CASE 1: rez:=c2-(c2/10)*10
CASE 2: rez:=c2/10
CASE 3: rez:=c2/100
DEFAULT: rez:=999
};
OUTPUT(rez)
ENDFOR
END
Результат выделения лексем лексического анализатора представлен в таблице 3.
Таблица 3
Таблица лексем для листинга примера 1
| номер | ||||||||||
| - | 1,0 | 19,1 | 16,0 | 20,1 | 12,0 | 19,2 | 16,0 | 20,1 | 12,0 | |
| 19,3 | 16,0 | 9,0 | 12,0 | 19,4 | 16,0 | 19,3 | 12,0 | 11,0 | 19,1 | |
| 13,0 | 20,1 | 2,0 | 19,3 | 16,0 | 19,3 | 15,1 | 20,2 | 12,0 | 7,0 | |
| 19,3 | 13,0 | 20,3 | 10,0 | 19,1 | 16,0 | 20,3 | 3,0 | 19,2 | 28,0 | |
| 6,0 | 5,0 | 12,0 | 8,0 | 17,0 | 19,2 | 18,0 | 12,0 | 24,0 | 19,5 | |
| 16,0 | 20,1 | 27,0 | 19,2 | 26,0 | 17,0 | 19,5 | 18,0 | 30,0 | 21,0 | |
| 20,1 | 29,0 | 19,6 | 16,0 | 19,4 | 14,1 | 17,0 | 19,4 | 15,1 | 20,2 | |
| 18,0 | 15,0 | 20,2 | 21,0 | 20,4 | 29,0 | 19,6 | 16,0 | 19,4 | 15,1 | |
| 20,2 | 21,0 | 20,5 | 29,0 | 19,6 | 16,0 | 19,4 | 15,1 | 20,6 | 22,0 | |
| 29,0 | 19,6 | 16,0 | 20,7 | 31,0 | 12,0 | 8,0 | 17,0 | 19,6 | 18,0 | |
| 23,0 | 4,0 |
Таблицы идентификаторов и констант представлены соответствующими таблицами 4 и 5.
Таблица 4
Таблица идентификаторов для листинга примера 1
| № | Идентификатор |
| next | |
| rng | |
| c1 | |
| c2 | |
| k | |
| rez |
Таблица 5
Таблица констант для листинга примера 1
| № | Константа |
1.4. Описание процесса расстановки ссылок модифицированного языка МИЛАН
Для организации правильной работы операторов цикла и развилки необходимо на некоторые лексемы поставит ссылки на номера лексем, куда будет передано управление при выполнении определенных условий. Такие ссылки записываются на место значения лексемы.
Для оператора цикла WHILE на лексему DO необходимо поставить ссылку на номер лексемы, следующей за лексемой ENDDO (рис. 8, а) для выхода из цикла при невыполнении условия. А для возврата по циклу – ссылку с ENDDO на лексему, следующую за WHILE, т.е. проверка условия цикла.
Для цикла FOR по аналогии с циклом WHILE ставится ссылка с лексемы TO на лексему, следующую за ENDFOR (рис. 8, б) для выхода из цикла при достижении заданного числа итераций. Лексема ENDFOR ссылается на TO для проверки условия продолжения цикла, при этом выполняется увеличение переменной цикла.
Для оператора развилки на лексему IF необходимо поставить ссылку на номер лексемы, стоящей после лексемы ELSE в полной форме оператора развилки (рис. 8, г), и стоящей после лексемы ENDIF в сокращенной форме (рис. 8, в). На эти лексемы передается управление при ложном условии оператора развилки.
Для оператора развилки SWITCH ссылки указываются следующим образом: каждая лексема «:» в строке выбора ссылается на нижележащую ветку выбора (CASE или DEFAULT) или на лексему завершения оператора «}»(рис. 8, д, е). Условия проверки выполнения ветки для CASE и DEFAULT различны. Для ветки CASE условие не выполняется – если константа не соответствует проверяемому значению, а для DEFAULT – если флаг прохождения ветви выставлен (который устанавливается в случае прохода в ветви CASE).

Рисунок 8 – Расстановка ссылок
Для независимой обработки вложенных структур используются отдельные стеки для циклов и развилок. Синтаксическая диаграмма (R-схема) расстановки ссылок представлена на рисунке 9.
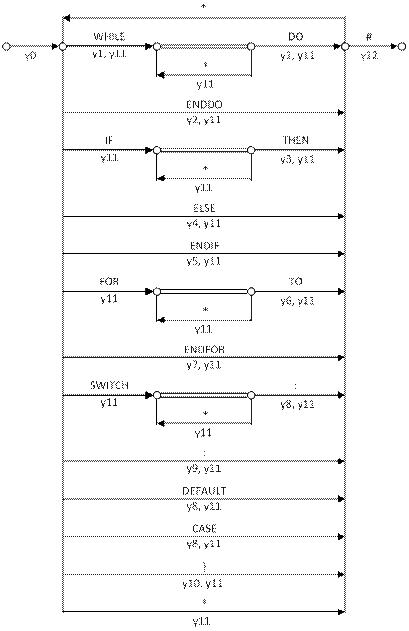
Рисунок 9 – R-схема расстановки ссылок
Обозначения для описания семантических функций синтаксической диаграммы расстановки ссылок:
- $Tab_Lexems[…]->Code – массив номеров лексем;
- $Tab_Lexems[…]->Value – массив значений лексем;
- $Number_Lexem – номер очередной рассматриваемой лексемы;
- $Stek_do – стек для циклов WHILE;
- $Stek_if – стек для развилок IF;
- $Stek_for – стек для циклов FOR;
- $Stek_switch – стек для развилок SWITCH.
Семантические функции к R-схеме расстановки ссылок:
y0: подготовка (инициализация стеков и переменных), номер очередной лексемы $Number_Lexem=1, прочитать лексему с номером $Number_Lexem;
y1: значение $Number_Lexem занести стек $Stek_do ($Number_Lexem→$Stek_do);
y2: снять вершину стека $Stek_do в переменную $s ($s ← $Stek_do), снять вершину стека $Stek_do в переменную $r ($r ← $Stek_do), значение $r+1 присвоть лексеме с номером $Number_Lexem [ENDDO→WHILE+1] ($Tab_Lexems[$Number_Lexem]->Value=$r+1), значение $Number_Lexem+1 присвоить лексеме с номером $s [DO→ENDDO+1] ($Tab_Lexems[$s]->Value=$Number_Lexem+1);
y3: значение $Number_Lexem занести в стек $Stek_if ($Number_Lexem→$Stek_if);
y4: снять вершину стека $Stek_if в переменную $r ($r ← $Stek_if), присвоить значение $Number_Lexem+1 лексеме c номером $r [THEN→ELSE+1] ($Tab_Lexems[$r]->Value=$Number_Lexem+1), занести в $Stek_if значение $Number_Lexem ($Number_Lexem→$Stek_if);
y5: снять вершину стека $Stek_if в переменную $r ($r←$Stek_if), присвоить значение $Number_Lexem+1 лексеме c номером $r [THEN→ENDIF+1, ELSE→ENDIF+1] ($Tab_Lexems[$r]->Value=$Number_Lexem+1) занести в $Stek_if значение $Number_Lexem ($Number_Lexem→$Stek_if);
y6: Значение $Number_Lexem занести в стек $Stek_for ($Number_Lexem→$Stek_for);
y7: Снять вершину стека $Stek_for в переменную $r ($r←$Stek_for). Лексеме с номером $Number_Lexem присвоить значение $r ($Tab_Lexems[$Number_Lexem]->Value=$r) [ENDFOR→TO]. Значение $Number_Lexem+1 присвоить лексеме с номером $r ($Tab_Lexems[$r]->Value=$Number_Lexem+1) [TO→ENDFOR+1];
y8: Значение $Number_Lexem занести в стек $Stek_switch ($Number_Lexem→$Stek_ switch);
y9: Снять вершину стека $Stek_switch в переменную $r ($r←$Stek_switch). Снять вершину стека $Stek_switch в переменную $s ($s ← $Stek_switch). Значение $r присвоить лексеме с номером $s ($Tab_Lexems[$s]->Value=$r) [: →CASE,: →DEFAULT]. Значение $Number_Lexem занести в стек $Stek_switch ($Number_Lexem→$Stek_switch);
y10: Снять вершину стека $Stek_switch в переменную $r ($r←$Stek_switch). Присвоить значение $Number_Lexem лексеме с номером $r ($Tab_Lexems[$r]->Value=$Number_Lexem)[: →}];
y11: $Number_Lexem++, прочитать очередную лексему с номером $Number_Lexem;
y12: завершить работу.
После процесса расстановки ссылок таблица лексем из примера 1 (таблица 3) примет вид таблицы 6.
Таблица 6
Таблица лексем после расстановки ссылок
| номер | ||||||||||
| 1,0 | 19,1 | 16,0 | 20,1 | 12,0 | 19,2 | 16,0 | 20,1 | 12,0 | ||
| WHILE | ||||||||||
| 19,3 | 16,0 | 9,0 | 12,0 | 19,4 | 16,0 | 19,3 | 12,0 | 11,0 | 19,1 | |
| DO | IF | |||||||||
| 13,0 | 20,1 | 2,42 | 19,3 | 16,0 | 19,3 | 15,1 | 20,2 | 12,0 | 7,0 | |
| THEN | ELSE | |||||||||
| 19,3 | 13,0 | 20,3 | 10,38 | 19,1 | 16,0 | 20,3 | 3,41 | 19,2 | 28,0 | |
| ENDIF | ENDDO | FOR | ||||||||
| 6,0 | 5,19 | 12,0 | 8,0 | 17,0 | 19,2 | 18,0 | 12,0 | 24,0 | 19,5 | |
| TO | SWCH | { | CASE | |||||||
| 16,0 | 20,1 | 27,101 | 19,2 | 26,0 | 17,0 | 19,5 | 18,0 | 30,0 | 21,0 | |
| : | ||||||||||
| 20,1 | 29,73 | 19,6 | 16,0 | 19,4 | 14,1 | 17,0 | 19,4 | 15,1 | 20,2 | |
| Продолжение таблицы 6 | ||||||||||
| номер | ||||||||||
| CASE | : | |||||||||
| 18,0 | 15,0 | 20,2 | 21,0 | 20,4 | 29,81 | 19,6 | 16,0 | 19,4 | 15,1 | |
| CASE | : | DEF | ||||||||
| 20,2 | 21,0 | 20,5 | 29,89 | 19,6 | 16,0 | 19,4 | 15,1 | 20,6 | 22,0 | |
| : | } | |||||||||
| 29,94 | 19,6 | 16,0 | 20,7 | 31,0 | 12,0 | 8,0 | 17,0 | 19,6 | 18,0 | |
| ENDFOR | END | |||||||||
| 23,52 | 4,0 |
1.5. Описание интерпретатора модифицированного язык МИЛАН
Задача интерпретатора - распознать конструкции языка и выполнить действия, предписанные входной программой. Учитывая, что синтаксический разбор будет производиться над массивом лексем, уточним грамматику языка МИЛАН, которая будет использована для синтаксического анализа последовательности лексем. Множество терминалов в уточненной грамматике - это множество лексем.
Уточненная грамматика расширенного языка МИЛАН:
1) W → BEGIN L END
2) L → S | S; L
3) S → I:=E | I++ | OUTPUT(E) | WHILE B DO L ENDDO | IF B THEN L ENDIF | IF B THEN L ELSE L ENDIF | FOR I:= E TO E L ENDFOR | FOR I:= E TO E STEP E L ENDFOR | SWITCH(E){V} | SWITCH(E){VX}
4) V → F | FV
5) F → CASE K: L
6) X → DEFAULT: L
7) B → EOE
8) E → T | NT | T N T | N T N T
9) T → P | P M P
10) P → I | I++ | K | READ | (E)
11) I → id(0) |... | id(i)
12) K → int(0) |... | int(j)
13) O → otn(0) |... | otn(5)
14) M → otu(0) | otu(1)
15) N → ots(0) | ots(1)
Здесь i и j - число идентификаторов и констант; нетерминалы обозначают конструкции языка: W - <программа>; L - <последовательность операторов>; S - <оператор>; B - <условие>; E - <выражение>; T - <терм>; P - <множитель>; K - <константа>; O - <знак отношения>; M - <операция типа умножения>; N - <операция типа сложения>; I - <идентификатор>, V - <выбор>, F - <ветвь>, X - <умолчание>.
Обозначения для описания семантических функций синтаксической диаграммы интерпретатора: $Tab_Lexems[…]->Code – массив номеров лексем; $Tab_Lexems[…]->Value – массив значений лексем; $Number_Lexem – номер очередной рассматриваемой лексемы в массиве лексем; $StekRes – стек результатов вычислений; $StekIdent – стек идентификаторов; $StekMul – стек для операций типа умножения; $StekSum – стек для операций типа сложения; $StekRel – стек для операции отношения; $ArrIdent – стек текущих значений идентификаторов; $StekFor – стек для циклов for; $StekSw – стек для развилок switch.
Синтаксическая диаграмма интерпретатора нетерминальных символов W, L, S представлена на рисунке 12, для символов P, B, E, T на рисунке 10 и для символов V, F, X на рисунке 12 соответственно.

Рисунок 10 - R-схема интерпретатора: нетерминальные символы P, B, E, T.

Рисунок 11 - R-схема интерпретатора: нетерминальные символы V, F, X.

Рисунок 12 – R-схема интерпретатора: нетерминальные символы W, L, S.
Семантические функции к R-схеме интерпретатора:
y0: инициализация стеков и переменных;
y1: занесение в стек $StekRes идентификатора $Tab_Lexems[$Number_Lexem]->Value;
y2: удалить вершину стека $StekRes, снять значение лексемы $Number_Lexem-1 в переменную $Ai ($Tab_Lexems[Number_Lexem-1]->Value→$Ai), увеличить значение идентификатора с номером $Ai на 1 ($ArrIdent[$Ai]++); Обновить вершину стека $StekRes новым значением $ArrIdent[$Ai];
y2p: снять значение лексемы $Number_Lexem-1 в переменную $Ai ($Tab_Lexems[Number_Lexem-1]->Value→$Ai), увеличить значение идентификатора с номером $Ai на 1 ($ArrIdent[$Ai]++). Удалить вершину стека $StekIdent;
y3: занесение в стек $StekRes константы $Tab_Lexems[$Number_Lexem]->Value;
y4: чтение следующей лексемы ($Number_Lexem++);
y5: прочитать целое число с терминала в переменную $Cifra и положить его в $StekRes ($Cifra→$StekRes);
y6: занесение в стек $StekMul значение операции типа умножения ($Tab_Lexems[$Number_Lexem]->Value→$StekMul);
y7: в переменную $Bi снять элемент со стека $StekRes ($Bi←$StekRes), в переменную $Ai снять элемент со стека $StekRes ($Ai←$StekRes), в переменную $kmul снять элемент со стека $StekMul ($kmul←$StekMul), выполнить операцию типа умножение $Ai otu($kmul) $Bi и результат занести в стек $StekRes;
y8: занесение в стек $StekSum кода операции типа сложения;
y9: в переменную $ksum снять со стека $StekSum значение лексемы ots ($ksum←$StekSum), если $ksum=1, то снять в переменную $Ai элемент со стека $StekRes ($Ai←$StekRes), сменить знак этого числа и занести его в стек $StekRes (-$Ai→$StekRes);
y10: в переменную $Bi снять элемент со стека $StekRes ($Bi←$StekRes), в переменную $Ai снять элемент со стека $StekRes ($Ai←$StekRes), в переменную $ksum снять элемент со стека $StekSum ($ksum←$StekSum), вы полнить операцию типа сложение $Ai ots($ksum) $Bi и результат занести в стек $StekRes;
y11: добавление в стек $StekRel значения операции типа отношение ($Tab_Lexems[$Number_Lexem]->Value→$StekRel);
y12: в переменную $Bi снять элемент со стека $StekRes ($Bi←$StekRes), в переменную $Ai снять элемент со стека $StekRes ($Ai←$StekRes), в переменную $krel снять элемент со стека $StekRel ($krel←$StekRel), выполнить операцию сравнения $Ai otn($krel) $Bi и результат занести в стек $StekRes ([0, 1] →$StekRes);
y13: добавить значение лексемы с номером Number_Lexem в стек StekIdent ($Tab_Lexems[$Number_Lexem]->Value→$StekIdent);
y14: в переменную $Ai снять элемент со стека $StekRes ($Ai←$StekRes), в переменную $Bi снять со стека $StekIdent значение лексемы ident ($Bi←$StekIdent), идентификатору с номером $Bi, присвоить значение $Ai ($ArrIdent[$Bi]=$Ai);
y15: в переменную $Ai снять элемент со стека $StekRes ($Ai←$StekRes), на печатать переменную $Ai;
y16: в переменную $Ai снять элемент со стека $StekRes ($Ai←$StekRes), если $Ai=1, то это истина, иначе - ложь;
y17: перейти на лексему номер $Tab_Lexems[$Number_Lexem]->Value;
y18: перейти на лексему номер $Tab_Lexems[$Number_Lexem]->Value-1;
y19: снять вершину стека $StekRes в переменную $Ai ($Ai←$StekRes), прочесть вершину стека $StekIdent (без удаления) в переменную $Bi ($Bi←$StekIdent), присвоить идентификатору с номером $Bi значение $Ai ($ArrIdent[$Bi] ←$Ai), занести в стек $StekFor значение лексемы $Number_Lexem ($StekFor←$Tab_Lexems[$Number_Lexem]->Value), занести в стек $StekFor значение 1 ($StekFor←1);
y20: снять вершину стека $StekRes в переменную $Bi ($Bi ←$StekRes), скопировать вершину стека $StekIdent (без удаления) в переменную $Ai ($Ai←$StekIdent), выполнить операцию сравнения £ между значением идентификатора с номером $Ai и значением $Bi ($ArrIdent[$Ai] £$Bi), если условие выполняется – истина, иначе – ложно;
y21: снять вершину стека $StekRes в переменную $Ai ($Ai←$StekRes), удалить вершину стека $StekFor, занести в стек $StekFor значение $Ai ($StekFor←$Ai);
y22: скопировать вершину стека $StekFor (без удаления) в переменную $Bi ($Bi←$StekFor), скопировать вершину стека $StekIdent (без удаления) в переменную $Ai ($Ai←$StekIdent), увеличить значение идентификатора с номером $Ai на величину $Bi ($ArrIdent[$Ai]+= $Bi);
y23: удалить вершины стеков $StekFor и $StekIdent, снять вершину стека $StekFor в переменную $Ai ($Ai←$StekFor), перейти на лексему с номером $Ai;
y24: снять вершину стека $StekRes в переменную $Ai ($Ai←$StekRes), занести в стек $StekSw значение 0 ($StekSw←0), занести значение $Ai в стек $StekSw ($StekSw←$Ai);
y25: снять со стека $StekSw вершину (удалить) 2 раза
y26: снять значение текущей константы в переменную $Ai, скопировать вершину стека $StekSw (без удаления) в переменную $Bi ($Bi←$StekSw), выполнить операцию сравнения между переменной $Ai и $Bi ($Ai = $Bi), если равенство выполняется, то истина, иначе – ложь;
у27: снять вершину стека $StekSw в переменную $Ai ($Ai←$StekSw), удалить вершину стека $StekSw, поместить в стек $StekSw значение 1 ($StekSw←1), поместить в стек $StekSw значение $Ai ($StekSw←$Ai);
у28: снять вершину стека $StekSw в переменную $Ai ($Ai←$StekSw), скопировать в переменную $Bi (без удаления) значение со стека $StekSw ($Bi←$StekSw), если $Bi=1, то истина, иначе – ложно, поместить в стек $StekSw переменную $Ai обратно ($StekSw←$Ai);
у29: завершение работы;
ИССЛЕДОВАТЕЛЬСКАЯ ЧАСТЬ
2.1. Программная реализация интерпретатора модифицированного языка МИЛАН
<?php
//Описание классов
/* элемент массива лексем */
class Element_Lexems
{
/* код лексемы */
public $Code = 0;
/* значение лексемы */
public $Value = 0;
}
/* Элемент таблицы ключевых [зарезервированных] слов */
class Element_Key_Words
{
/* Ключевое слово */
public $Key_Word = '';
/* Код ключевого слова */
public $Code_Key_Word = 0;
}
//Описание констант
/* Количество ключевых слов языка МИЛАН */
define("MAX_KEY_WORDS",11);
/* Кода ключевых слов языка МИЛАН */
define("_BEGIN_", 1);
define("_DO_", 2);
define("_ELSE_", 3);
define("_END_", 4);
define("_ENDDO_", 5);
define("_ENDIF_", 6);
define("_IF_", 7);
define("_OUTPUT_", 8);
define("_READ_", 9);
define("_THEN_", 10);
define("_WHILE_", 11);
/* Кода лексем языка МИЛАН */
define("_SEMICOLON_",12); /*; */
define("_RELATION_",13); // операция типа отношение
/* значения операции типа отношение */
define("_EQUAL_", 0); /* = */
define("_NOTEQUAL_", 1); /* <> */
define("_GT_", 2); /* > */
define("_LT_", 3); /* < */
define("_GE_", 4); /* >= */
define("_LE_", 5); /* <= */
define("_SUMM_", 14); /* операция типа сложение */
/* значения операции типа сложение */
define("_PLUS_", 0); /* + */
define("_MINUS_", 1); /* - */
define("_MUL_", 15); /* операция типа умножение */
/* значения операции типа сложение */
define("_STAR_", 0); /* * */
define("_SLASH_", 1); /* / */
define("_ASSIGNMENT_", 16); /* присваивание */
define("_LPAREN_", 17); /* (*/
define("_RPAREN_", 18); /*) */
define("_IDENTIFIER_", 19); /* идентификатор */
define("_CONSTANT_", 20); /* константа */
/* Таблица ключевых [зарезервированных] слов языка МИЛАН */
/* Ключевые слова в массиве должны быть упорядочены, т.к. */
/* поиск в массиве осуществляется методом "бинарного поиска" */
$Table_Key_Words = Array();
function ct_AddElement($Key_Word, $Code_Key_Word)
{
$ct_Element = new Element_Key_Words;
$ct_Element->Key_Word = $Key_Word;
$ct_Element->Code_Key_Word = $Code_Key_Word;
return $ct_Element;
}
//создаём новый массив
$Table_Key_Words[1] = ct_AddElement('BEGIN', _BEGIN_);
$Table_Key_Words[2] = ct_AddElement('DO', _DO_);
$Table_Key_Words[3] = ct_AddElement('ELSE', _ELSE_);
$Table_Key_Words[4] = ct_AddElement('END', _END_);
$Table_Key_Words[5] = ct_AddElement('ENDDO', _ENDDO_);
$Table_Key_Words[6] = ct_AddElement('ENDIF', _ENDIF_);
$Table_Key_Words[7] = ct_AddElement('IF', _IF_);
$Table_Key_Words[8] = ct_AddElement('OUTPUT', _OUTPUT_);
$Table_Key_Words[9] = ct_AddElement('READ', _READ_);
$Table_Key_Words[10]= ct_AddElement('THEN', _THEN_);
$Table_Key_Words[11]= ct_AddElement('WHILE', _WHILE_);
/* максимально допустимое количество идентификаторов в программе */
define("MAX_IDENTIFIERS", 15);
/* максимально допустимое количество констант в программе */
define("MAX_CONSTANTS", 15);
/* максимально допустимое количество лексем в программе */
define("MAX_LEXEMS", 500);
/* массив сообщений об ошибках в программе на МИЛАНе */
$Error_Message = Array(
/* 1 */ 'Неизвестный символ в программе.',
/* 2 */ 'Превышение максимального количества идентификаторов.',
/* 3 */ 'Превышение максимального количества констант.',
/* 4 */ 'Переполнение массива лексем.',
/* 5 */ 'Переполнение стека Stek_do.',
/* 6 */ 'Нехватка элементов в стеке Stek_do.',
/* 7 */ 'Неправильное обращение к функции для работы со стеком Stek_do.',
/* 8 */ 'Переполнение стека Stek_if.',
/* 9 */ 'Нехватка элементов в стеке Stek_if.',
/* 10 */ 'Неправильное обращение к функции для работы со стеком Stek_if.',
/* 11 */ 'Несоответствие в операторах WHILE-DO-ENDDO.',
/* 12 */ 'Несоответствие в операторах IF-THEN-ELSE-ENDIF.',
/* 13 */ 'Конструкция <программа>. Нет BEGIN.',
/* 14 */ 'Конструкция <программа>. Нет END.',
/* 15 */ 'Переполнение стека StekIdent.',
/* 16 */ 'Конструкция <оператор>. Неверное присваивание.',
/* 17 */ 'Нехватка элементов в стеке StekRes.',
/* 18 */ 'Нехватка элементов в стеке StekIdent.',
/* 19 */ 'Конструкция <оператор>. Неверный оператор OUTPUT.',
/* 20 */ 'Конструкция <оператор>. Неверный оператор WHILE.',
/* 21 */ 'Конструкция <оператор>. Отсутствует THEN в операторе IF.',
/* 22 */ 'Конструкция <оператор>. Отсутствует ENDIF в операторе IF.',
/* 23 */ 'Конструкция <оператор>. Отсутствует ELSE или ENDIF в операторе IF.',
/* 24 */ 'Конструкция <условие>. Неверная операция отношения.',
/* 25 */ 'Переполнение стека StekRel.',
/* 26 */ 'Нехватка элементов в стеке StekRel.',
/* 27 */ 'Переполнение стека StekRes.',
/* 28 */ 'Нехватка элементов в стеке StekMul.',
/* 29 */ 'Переполнение стека StekMul.',
/* 30 */ 'Деление на ноль.',
/* 31 */ 'Конструкция <множитель>. Нет закрывающей скобки.',
/* 32 */ 'Переполнение стека StekSum.',
/* 33 */ 'Нехватка элементов в стеке StekSum.');
/* массив лексем */
$Tab_Lexems = Array ();
/* массив идентификаторов */
$Tab_Identifiers = Array ();
/* массив констант */
$Tab_Constants = Array ();
/* Имя программы на языке МИЛАН */
$Input_Programm = '';
/* Входной файл программы на языке МИЛАН */
/* Входной символ программы на языке МИЛАН */
$Input_Letter = '';
/* Номер очередного символа в программе */
$Number_Letter = 0;
/* Код ошибки */
$Code_Error = -1;
/* Номер строки и позиции в которой ошибка */
$Number_String = 0;
$Position = 0;
/* Номер очередной лексемы в программе */
$Number_Lexem = 0;
/* Сформированная Лексическим Анализатором лексема */
$Current_Lexem = new Element_Lexems;
/* Количество лексем в программе */
$Number_Lexems_Programm = 0;
/* Номер очередного идентификатора в программе */
$Number_Identifiers = 0;
/* Номер очередной константы в программе */
$Number_Constants = 0;
/*******************************************************************/
/* Stek_Integer(...) */
/* Функция для работы со стеками типа Integer. */
/* Аргументы: */
/* Operation - код операции (0 - инициализация стека; */
/* 1 - извлечение элемента из стека */
/* в Element; */
/* 2 - добавление элемента */
/* в стек Element; */
/* $Current_Stek - массив из 50 элементов; */
/* $Top - вершина стека; */
/* $Element - элемент который кладется в стек или в который */
/* возвращается вершина стека. */
/* Функция возвращает значение TRUE, если операция работы со стеком */
/* выполнена успешно, FALSE - в противном случае. */
/*******************************************************************/
function Stek_Integer($Operation,
&$Current_Stek,
&$Top,
&$Element)
{
global $Code_Error;
switch ($Operation):
/* Инициализация стека */
Case 0:
$Top=0;
for ($i=1;$i<=50;$i++)
{
$Current_Stek[$i]=0;
}
break;
/* Извлечение элемента со стека */
Case 1:
if ($Top<=0)
{
return FALSE;
}
else
{
$Element=$Current_Stek[$Top];
$Top--;
}
break;
/* Добавление элемента в стек */
Case 2: