МЕТОДИЧЕСКИЕ УКАЗАНИЯ К ВЫПОЛНЕНИЮ КОНТРОЛЬНЫХ РАБОТ ПО СТАТИСТИКЕ
ВВЕДЕНИЕ
Контрольная работа является элементом учебного процесса при изучении дисциплины «Статистика» для заочной формы обучения.
Контрольная работа выполняется самостоятельно в межсессионный период. Она предназначена для углубления и расширения знаний по дисциплине «Статистика». Кроме того, эта работа является формой контроля самостоятельной индивидуальной работы учащихся.
Работа должна быть аккуратно оформлена в рукописном или печатном виде, удобна для проверки и хранения. Оформление контрольной работы должно соответствовать определённым нормам. Текст пишется черным шрифтом Times New Roman 14-й кегль или читабельным почерком на одной стороне стандартного листа (А4) белой односортной бумаги через 1,5 интервал. Поля: слева – 30 мм, справа – 15 мм, сверху – 20 мм и снизу – 20 мм. Страницы работы должны быть пронумерованы в правом верхнем углу страницы. Нумерация начинается с титульного листа, номер страницы на титульном листе не ставится. Далее следует оглавление с указанием номеров страниц, с которых начинаются решения приведенных задач.
В конце работы приводится список использованной литературы, ставится дата выполнения и подпись студента.
Работа представляется для проверки, как правило, не позднее, чем за 10 дней до начала экзаменационной сессии.
Контрольная работа, выполненная по неправильно выбранному варианту, возвращается учащемуся без проверки.
Преподаватель проверяет работу в течение 7 дней. Незачтенная работа возвращается учащемуся для доработки в соответствии с замечаниями. Основные причины, по которым работа может быть не зачтена:
1) выполнение заданий, не соответствующих своему варианту (таблица 1);
2) грубое нарушение оформления;
3) неверно примененная методология расчетов;
4) отсутствие промежуточных расчетов, т.е. содержатся только формула и окончательный ответ;
5) отсутствие комментариев по поводу рассчитанных значений статистических показателей там, где требует условие задачи;
6) отсутствие решения одной или более задач;
7) наличие двух и более ошибок в расчетах.
Учащиеся, не представившие контрольную работу или работа которых не зачтена преподавателем, не допускаются к сдаче экзамена (зачета) по дисциплине «Статистика».
C целью оказания помощи студентам-заочникам в освоении важнейших вопросов Общей теории статистики (задачи 1-6) и Социально-экономической статистики (задачи 7-10).
Перед решением каждой задачи следует написать ее условие. Решение задач должны содержать формулы, развернутые расчеты, а также объяснение полученных результатов.
Контрольная работа разработана в 10 вариантах. Варианты контрольной работы устанавливаются в зависимости от начальной буквы фамилии студента.
Таблица 1.
Порядок выбора варианта, соответствующего фамилии студента
| Первая буква фамилии студента | Вариант |
| А, Б, Ч | |
| В, Г | |
| Д, Е, Ш | |
| Ж, Х, З | |
| И, К, Я | |
| Л, М | |
| Н, Ю, П | |
| О, Р, Ц | |
| С, Щ, Т | |
| У, Ф, Э |
Методические указания к решению задач
Указания к задаче № 1
Задача № 1 выполняется по теме «Сводка и группировка».
При решении вопроса о числе групп важно руководствоваться не формальными соображениями, а тем, какие в действительности имеются характерные типичные группы. Количество образуемых групп в некоторых случаях определяется признаком, положенным в основании группировки. Так, выбор в качестве группировочных некоторых атрибутивных признаков сам по себе предопределяет решение вопроса о числе групп. Если же в основание группировки положен количественный признак, то возникает вопрос не только о числе групп, но и об интервалах – их характере (равные, неравные, прогрессивно возрастающие или убывающие) и величине (разности между нижней и верхней границами). Число единиц в выделенных группах должно быть достаточным, чтобы характеристики, рассчитанные для отдельных групп, были статистически устойчивыми. Количество выделенных групп зависит от вариации признака, числа наблюдений. Группировку с неравными интервалами надо использовать, если размах вариации признака в совокупности велик. В этом случае границы каждого интервала устанавливаются исследователем.
Величина интервала (h) при равных интервалах группировки определяется по формуле:
 ,
,
где хmax и xmin - максимальное и минимальное значение данного признака;
n – число групп.
Затем определяются границы каждого интервала:
для 1-го интервала от xmin до (xmin + h);
для 2-го интервала от (xmin + h) до (xmin + 2h) и т.д.
После того, как образованы группы, необходимо отобрать показатели, которыми будут характеризоваться группы, и определить их величину по каждой группе.
Для выявления наличия или отсутствия связи между указанными признаками следует рассчитать средние показатели признака-фактора и признака-результата в каждой группе. Если изменение величины признака-фактора в определенном направлении вызывает изменение величины результативного признака в том же направлении, то связь прямая, а в противном случае – связь обратная.
Результаты статистической сводки и группировки всегда излагаются в виде статистических таблиц. По результатам группировки необходимо сделать выводы, характеризующие взаимосвязи между представленными показателями.
Указания к задаче № 2
Задача № 2 выполняется по темам «Средние величины» и «Показатели вариации».
Средняя величина есть обобщенная характеристика единиц совокупности по определенному признаку. Средние величины теснейшим образом связаны с существом рассматриваемых общественных явлений.
В статистике используются различные виды средних величин, который подразделяются на два класса: степенные и структурные. К первой группе относят: арифметическую, гармоническую, геометрическую, квадратическую. К структурным средним относят моду и медиану.
Все виды средних могут быть исчислены как по индивидуальным значениям осредняемого признака (простые), так и по сгруппированным, с указанием статистических весов (взвешенные).
Невзвешенная средняя вычисляется в тех случаях, когда веса всех вариантов осредняемого признака равны между собой. Средняя арифметическая невзвешенная (простая) вычисляется по формуле:
 ,
,
где хi - индивидуальные значения (варианты) осредняемого признака;
i – порядковый номер варианта;
n - число вариантов.
Средняя арифметическая взвешенная вычисляется по формуле
 ,
,
где f – статистический вес (частота или частость повторений соответствующих вариантов признаков).
В ряде случаев исходные данные приводят к необходимости применения средней гармонической – когда в исходных данных веса вариантов осредняемого признака непосредственно не заданы, а входят как сомножитель в один из имеющихся показателей. Рассчитывается по следующим формулам:
 – простая;
– простая;
 – взвешенная.
– взвешенная.
где: w - сложный показатель, представленный произведением осредняемого признака на другой показатель (w = х f).
Для характеристики структуры вариационных рядов применяются структурные средние – мода и медиана.
Мода (Мо) – это значение варьирующего признака, наиболее часто встречающееся в данном ряду. Модой в дискретном ряду является вариант, имеющий наибольшую частоту. В интервальном же вариационном ряду моду определяют по формуле:
 ,
,
где xМО – нижняя граница модального интервала, т.е. интервала, имеющего наибольшую частоту;
h – величина модального интервала;
 – частота модального интервала;
– частота модального интервала;
 - частота предшествующего модальному интервала;
- частота предшествующего модальному интервала;
 - частота следующего за модальным интервала.
- частота следующего за модальным интервала.
Медиана (Ме) - это численное значение признака у той единицы изучаемой совокупности, которая находится в середине ранжированного ряда.
Численное значение медианы можно определить по ряду накопленных частот. Накопленная частота для медианы равна половине объема совокупности. Для интервального ряда в этом случае определяется только интервал, само значение определяется по формуле:
 ,
,
где: Хme – нижняя граница медианного интервала;
hme – величина медианного интервала;
N – объем совокупности (N = Σ f);
Sme-1 – накопленная частота в интервале, предшествующем медианному;
fme – частота медианного интервала.
Медианный интервал – интервал, в котором накопленная частота первый раз превысит середину совокупности, т.е. в данном интервале находится центр совокупности. Накопленная частота рассчитывается последовательным суммированием индивидуальных частот. Например, если частоты соответствующих интервалов равны 5, 9, 17, 6, то соответствующие накопленные частоты равны 5, 14, 31, 37, середина совокупности – 18,5, медианный интервал – третий.
Чтобы судить о типичности средней величины ее следует дополнить показателями, характеризующими вариацию (колеблемость) признака. Наиболее распространенными из них являются:
̶ среднее линейное отклонение ( );
);
̶ дисперсия (σ2),
̶ среднее квадратическое отклонение (σ);
̶ коэффициент вариации (v).
Они определяются по формулам:
 ;
;
 =
=  ;
;
 ;
;
 .
.
Коэффициент вариации часто используется для сравнения степени вариации по разным совокупностям, а также для характеристики степени однородности совокупности. Так, если коэффициент равен более 33% – совокупность признается как неоднородная, т.е. в совокупности действуют множество разнонаправленных факторов. Для дальнейшего анализа такие совокупности преобразуются.
Указания к задаче № 3
Задача № 3 выполняется по теме «Выборочное наблюдение».
Выборочное наблюдение – наиболее распространенный вид несплошного наблюдения, при котором исследуется только специальным образом отобранная часть совокупности, результаты исследования затем распространяются на всю совокупность при определенной вероятности.
Так как при оценке характеристик используется только выборочная совокупность – велика вероятность появления ошибок, т.е. расхождений между характеристиками выборки и генеральной совокупности. Такие ошибки получили название ошибки репрезентативности. Она определяется по ниже приведенным формулам.
Предельная ошибка выборки для выборочной средней:
 ;
;
где  – коэффициент доверия, определяется по специальным таблицам и соответствует выбранной вероятности и размеру выборки;
– коэффициент доверия, определяется по специальным таблицам и соответствует выбранной вероятности и размеру выборки;
 – средняя квадратическая ошибка.
– средняя квадратическая ошибка.
Если размер выборочной совокупности более 30 единиц, значение коэффициента доверия определяется по таблице интегральной функции Лапласа (приводятся в конце всех учебников по Теории статистики). Наиболее часто используют следующие вероятности и соответствующие им значение коэффициентов доверия:
̶ 95% – t = 1,98;
̶ 95,45% – t = 2;
̶ 99% – t = 2,58;
̶ 99,7% – t = 3;
̶ 99,9% – t = 3,28;
Если выборка менее 30 единиц – коэффициент определяется по таблице распределения Стюдента и зависит не только от задаваемой вероятности, но и от числа степеней свободы (размера выборки).
Средняя квадратическая ошибка рассчитывается:
 - для повторного отбора;
- для повторного отбора;
 - для бесповторного отбора,
- для бесповторного отбора,
где σ2 – дисперсия средней, т.е. количественного признака;
n – размер выборочной совокупности;
N – размер генеральной совокупности.
Обычно, если выборка составляет менее 5% от генеральной совокупности – множитель  в расчетах опускается.
в расчетах опускается.
Доверительный интервал определяется:
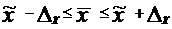 .
.
Предельная ошибка для выборочной доли:
 .
.
 - для повторного отбора;
- для повторного отбора;
 - для бесповторного отбора.
- для бесповторного отбора.
где w – доля единиц, обладающих изучаемым признаком в выборке;
w(1-w) – дисперсия доли, т.е. качественного признака.
Доверительный интервал определяется:
 ,
,
где р - доля единиц, обладающих изучаемым признаком в генеральной совокупности.
Указания к задаче № 4
Задача № 4 выполняется по теме «Статистические методы анализа взаимосвязей».
Связь – такое явление, при котором изменение одного признака определяется изменением другого (других) признака. Признаки, испытывающие влияние – эндогенные, внутренние, результаты; признаки, оказывающие влияние – экзогенные, внешние, факторы.
По степени тесноты связи подразделяют на:
1) функциональные (жестко детерминированные) – одному значению фактора соответствует строго определенное значение результата;
2) статистические (стохастические, случайные, корреляционные) – одному и тому же значению признака-фактора могут соответствовать разные значения результативного признака и наоборот. Связь проявляется при большом числе наблюдений в среднем изменении фактора и результата.
По направлению выделяют связь прямую и обратную. По аналитическому выражению обычно выделяют связи прямолинейные (линейные) и криволинейные.
Для оценки тесноты связей применятся ряд показателей, одни из которых называются эмпирическими или непараметрическими, другие – теоретическими.
В задаче № 4 следует рассчитать непараметрические показатели и показатели тесноты связи качественных признаков.
Коэффициент корреляции знаков (коэффициент Фехнера) вычисляется на основании определения знаков отклонений вариантов двух взаимосвязанных признаков от средних величин.
Если число совпадений знаков обозначить через а, число несовпадений - через в, а сам коэффициент – через Ф, то формулу можно написать так:
 .
.
Коэффициент корреляции рангов (коэффициент Спирмена) рассчитывается по рангам двух взаимосвязанных признаков следующим образом:
 ,
,
где:  - квадраты разности рангов;
- квадраты разности рангов;
 - число наблюдений (число пар рангов).
- число наблюдений (число пар рангов).
Например, имеется информация о местах, занятыми 10 спортсменами на чемпионате Европы и Олимпийских играх:
| Номер спортсмена | ИТОГО | ||||||||||
| Место (ранг) на чемпионате | - | ||||||||||
| Место (ранг) на играх | - | ||||||||||
| d | -5 | -3 | -2 | ||||||||
| d2 |
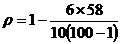 = 0,649
= 0,649
Для определения тесноты связи между тремя и более признаками применяется ранговый коэффициент согласия – коэффициент конкордации, который вычисляется по формуле:
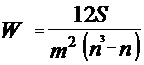 ,
,
где:  - количество факторов;
- количество факторов;
- число наблюдений;
 - сумма квадратов отклонений рангов.
- сумма квадратов отклонений рангов.
Например, 8 предприятий ранжированы по уровню рентабельности, уровню качества и уровню спроса на продукцию:
| Номер предприятия | Ранг по | Сумма рангов | Квадрат суммы рангов | ||
| рентабельности | качеству | спросу | |||
| ИТОГО |

Коэффициент конкордации:
 .
.
Для вычисления коэффициентов ассоциации и контингенции строится таблица, которая показывает связь между двумя явлениями, каждое из которых должно быть альтернативным.
| I | II | ||
| а | b | а+b | |
| с | d | с+d | |

| а+с | b+d |
Коэффициент ассоциации:
 .
.
Коэффициент контингенции:
 .
.
Если каждый из качественных признаков состоит более чем из двух групп, то для определения тесноты связи возможно применение коэффициентов взаимной сопряженности Пирсона и Чупрова. Эти коэффициенты вычисляются по формулам:
 ,
,
 ,
,
где:  2 - показатель взаимной сопряженности;
2 - показатель взаимной сопряженности;
К 1 - число значений (групп) первого признака;
К 2 - число значений (групп) второго признака.
Расчет коэффициента взаимной сопряженности производится по следующей схеме:
| Группы признака А | Группы признака В | Итого | ||
| В 1 | В2 | В 3 | ||
| А1 А2 А3 | f 1 f 4 f 7 | f 2 f 5 f 8 | f 3 f 6 f 9 | n 1 n 2 n 3 |
| m 1 | m 2 | m 3 |
Расчет  производится так:
производится так:
̶ по первой строке  ;
;
̶ по второй строке  ;
;
̶ по третьей строке  .
.

Непараметрические коэффициенты связи могут изменяться от 0 до 1. Чем ближе абсолютные значения к 1, тем теснее связь между исследуемыми признаками.
Указания к задаче № 5
Задача № 5 выполняется по теме «Ряды динамики».
Ряд динамики – это ряд значений статистического показателя, расположенных в хронологической последовательности, т.е. характеризующих изменения явления во времени. Таким образом, ряд включает два основных элемента: момент или интервал времени, к которому относятся данные, и значение показателя, которые чаще всего называют уровни ряда.
Уровни ряда могут быть выражены абсолютными, относительными или средними величинами.
Динамические ряды могут быть интервальными и моментными.
Изучение динамических рядов предполагает определение показателей интенсивности отдельных изменений уровней и их усреднение, расчет среднего уровня ряда динамики, анализ закономерностей изменения уровней ряда.
Изменение динамического ряда характеризуют с помощью показателей динамики. К ним относятся: абсолютный прирост, коэффициент роста, темп роста, темп прироста, абсолютное значение одного процента прироста.
В зависимости от базы сравнения различают базисные и цепные показатели динамики. Базисные показатели динамики – это результат сравнения текущих уровней с одним фиксированными уровнем, принятым за базу (обычно начальным). Цепные показатели динамики - это результат сравнения текущих уровней с предшествующими. Формулы расчета представлены ниже:
1) Абсолютный прирост
| базисный | цепной |

| 
|
2) Коэффициент роста
| базисный | цепной |

| 
|
3) Темп роста  ;
;
4) Темп прироста  ;
;
5) Абсолютное значение одного процента прироста  ;
;
6) Средний абсолютный прирост
 =
=  ;
;
7) Средний темп роста
 ;
;
8) Средний темп роста 
9) Средний темп прироста 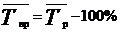 .
.
Метод определения среднего уровня зависит от типа динамического ряда. Средний уровень интервального ряда определяется как средняя арифметическая простая:
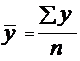 ,
,
где: y – значение соответствующего уровня;
n – число уровней ряда.
Средний уровень моментного ряда определяется:
а) для ряда с разноотстоящими моментами наблюдения – по формуле:
 ,
,
где ti – интервал времени между моментами;
Σ ti – общая продолжительность ряда.
б) для ряда с равноотстоящими моментами наблюдения – по формуле средней хронологической:

Для выявления закономерностей (тенденции) динамического ряда используют эмпирическое и аналитическое выравнивание.
Среди методов эмпирического выравнивания следует выделить метод укрупнения интервалов (замена дневных данных недельными, недельных – декадными или месячными и т.д.) и метод скользящей средней (последовательное усреднение соседних уровней).
При аналитическом выравнивании эмпирические уровни заменяются теоретическими, рассчитанными на основе математической функции:
 ,
,
где в качестве независимой переменной выступает фактор времени.
Выравнивание ряда сводится к определению параметров функции. Наиболее точный результат позволяет получить метод наименьших квадратов. Часто используется так называемый метод отсчета от условного нуля – все порядковые номера уровней заменяются условными таким образом, чтобы 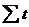 = 0, а шаг между уровнями сохранялся неизменным.
= 0, а шаг между уровнями сохранялся неизменным.
Наиболее простая функция – прямая типа  .
.
При выравнивании с помощью линейной функции параметры определяются следующим образом:
 ,
,  .
.
Указания к задаче № 6
Задача № 6 выполняется по теме «Индексы».
Индексы – это относительные показатели, которые выражают соотношение величин какого-либо явления во времени, в пространстве или сравнение фактических данных с любым эталоном (план, прогноз, норматив и т.д.)
В зависимости от степени охвата единиц изучаемой совокупности индексы подразделяются на индивидуальные (частные) и агрегатные (общие).
Индивидуальные индексы характеризуют изменение отдельных единиц статистической совокупности и определяются по формулам для показателей:
а) физического объема работ или услуг  ;
;
где  - соответственно физический объем произведенной (реализованной) продукции в отчетном и базисном периоде;
- соответственно физический объем произведенной (реализованной) продукции в отчетном и базисном периоде;
б) цены  ;
;
где  - соответственно цена единицы продукции в отчетном и базисном периоде.
- соответственно цена единицы продукции в отчетном и базисном периоде.
Агрегатные индексы – сложные относительные показатели, которые характеризуют среднее изменение социально-экономического явления, состоящего из непосредственно несоизмеримых элементов.
Для приведения показателей к соизмеримому виду используют веса.
Формулы для расчета агрегатных индексов выглядят следующим образом:
а) стоимости 
б) физического объема  - Ласпейреса;
- Ласпейреса;  - Пааше;
- Пааше;
б) цен 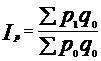 - Ласпейреса;
- Ласпейреса;  - Пааше.
- Пааше.
Индексный метод позволяет также представить абсолютный прирост стоимости продукции как результат влияния различных факторов: изменения цен и количества продукции.
Так, общее изменение стоимости продукции в текущем периоде по сравнению с базисным определяется по формуле:
 ;
;
в том числе:
̶ за счет изменения цен на отдельные виды продукции
 ;
;
̶ за счет изменения количества производимой продукции
 .
.
Часто на практике в силу некоторых особенностей учета отсутствуют данные о количестве и цене реализованной продукции – учитывается только стоимость. В этом случает расчет условной стоимости  и
и  непосредственно невозможен – условную стоимость рассчитывают с использованием индивидуальных индексов следующим образом:
непосредственно невозможен – условную стоимость рассчитывают с использованием индивидуальных индексов следующим образом:


Агрегатный индекс может быть определен как средний из индивидуальных индексов, например:
а) физического объема Ласпейреса
 ;
;
б) цены Ласпейреса
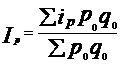 ;
;
в) цены Пааше
 .
.
Индексный метод используется для изучения динамики средних величин. Индекс средней величины определяется как отношение ее значений в текущем и базисном периоде. Например, индекс средней цены определится так:
 ;
;
Индекс средней цены называют индексом переменного состава. При этом на величину средней влияет как изменение цены, так и изменение структуры продукции, для которой определялась средняя цена.
Если принять  , то
, то  ,
,
где q – количество продукции, реализованной по соответствующей цене;
∑ q – общее количество реализованной продукции по всем ценам;
dq – доля продукции, реализованной по соответствующей цене.
Для оценки влияния непосредственного изменения цены применяют индекс фиксированного (постоянного) состава:
 или
или  .
.
Данный индекс характеризует изменение средней цены только в результате изменения индивидуальных цен на продукцию.
Для оценки влияния на изменение средней цены структуры совокупности (продукции) используют индекс структурных сдвигов:
 или
или  .
.
Данный индекс характеризует изменение средней цены только в результате изменения структуры реализованной продукции.
Указания к задаче № 7
Задача № 7 выполняется по теме «Статистика населения».
Население – совокупность людей, проживающих на данной территории. Выделяют следующие категории населения:
̶ постоянное – проживающее на данной территории длительное время (обычно 6 месяцев и более), в том числе временно отсутствующие;
̶ наличное – лица, находящиеся на момент переписи на данной территории, в то числе временно присутствующие;
̶ юридическое (приписное) – лица, юридически «прикрепленные» к данной территории в силу действующих юридических норм (прописка или регистрация).
Для характеристики населения первичными показателями являются показатели численности, в том числе:
̶ численность населения на определенный момент времени;
̶ средняя численность – полусумма населения на начало и конец периода;
̶ численность демографических событий (рождений, смертей, браков и т.д.).
На основе абсолютных показателей рассчитывают целую систему относительных – коэффициентов, производят различные сопоставления (ВВП на душу населения, средний доход на душу населения, обеспеченность средствами связи и т.п.), строятся демографические балансы:
| Численность населения на конец периода | = | Численность на начало | + | Число родившихся за период | - | Число умерших за период | + | Число прибывших на территорию | - | Число покинувших территорию |
Такие балансы широко используются для прогнозов и для анализа влияния факторов на изменение численности населения.
Состав населения (структура) – распределение населения на группы по различным признакам. Наиболее широко применяются следующие типы структур.
1) Половая – распределение на мужчин и женщин. При этом выделяют:
̶ первичное соотношение полов – по населению в целом;
̶ вторичное соотношение – количество мальчиков на 100 девочек при рождении;
̶ третичное – соотношение в определенном возрасте.
2) Возрастная – распределение по возрастам среди мужчин и среди женщин. Для характеристики возрастной структуры используются следующие коэффициенты (измеряются в промиллях, т.е. в расчете на 1000):
| Коэффициент нагрузки детьми | = | Число детей в возрасте от 0 до 14 лет | ÷ | Число взрослого населения от 15 до 54 для женщин и 59 для мужчин |
| Коэффициент нагрузки пожилыми | = | Число населения в возрасте 55 лет и старше для женщин и 60 и старше для мужчин | ÷ | Число взрослого населения от 15 до 54 для женщин и 59 для мужчин |
| Коэффициент общей нагрузки | = | Коэффициент нагрузки детьми | + | Коэффициент нагрузки пожилыми |
Средний возраст – по формуле средней арифметической по рядам распределения.
3) Брачная – распределение по отношению к браку на следующие группы:
̶ состоящие в браке, в том числе в гражданском;
̶ никогда не состоявшие в браке;
̶ вдовые;
̶ разведенные;
̶ разошедшиеся (для лиц, состоявших в гражданском браке).
4) Миграционная – распределение по срокам проживания в данном месте.
Широкое распространение в статистике населения получили распространение демографические коэффициенты. При этом применяют следующие виды коэффициентов:
̶ общие – отношение числа демографических событий к общей (средней) численности населения;
̶ специальные – отношение числа демографических событий к численности населения, способного их продуцировать;
̶ возрастные (частные) – отношение числа событий у населения данной группы к численности данной группы.
В задаче №7 требуется рассчитать следующие демографические коэффициенты:
1) общий коэффициент рождаемости

2) специальный коэффициент рождаемости

3) общий коэффициент смертности

4) коэффициент естественного прироста

5) коэффициент жизненности

6) коэффициент интенсивности миграции по прибытию
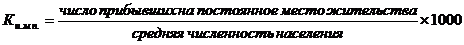
7) коэффициент интенсивности миграции по выбытию

8) общий коэффициент интенсивности миграции населения (миграционного прироста)
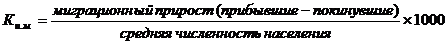
9) коэффициент интенсивности миграционного оборота

10) коэффициент эффективности миграции

11) коэффициент общего прироста населения

Указания к задаче № 8
Задача № 8 выполняется по темам «Статистика численности работников» и «Статистика использования рабочего времени».
Все лица, занятые в экономике, распределяются по видам зан