Задание 1. Ответить на следующие вопросы:
- В чем суть эффективного статистического кодирования?
Задание 2. Решить следующие задачи:
Задача 1. Разработать код с использованием метода Шеннона-Фано для входного алфавита Z = {z1,...z8} и выходного алфавита В = {0,1}, если вероятность использования знаков входного алфавита:
| Знаки | Вероятность |
| Z1 | 0,22 |
| Z2 | 0,20 |
| Z3 | 0,16 |
| Z4 | 0,16 |
| Z5 | 0,10 |
| Z6 | 0,10 |
| Z7 | 0,04 |
| Z8 | 0,02 |
Определить коэффициент избыточности полученного кода и среднее число символов на знак сообщения.
Задача 2. Разработать код с использованием метода Хаффмена для входного алфавита Х = {x1,...x8} и выходного алфавита В = {0,1}, если
р(х1)= 0,19; р(х2)= р(х3)= 0,16; р(х4)= 0,15; р(х5)= 0,12; р(х6)= 0,11; р(х7)= 0,09; р(х8)= 0,02,
и определить коэффициент избыточности полученного кода.
Задача 3. Алфавит сообщений состоит всего из двух знаков Z1 и Z2 с вероятностями появления соответственно p(z1) = 0,9 и p(z2) = 0,1.
Рассчитать и сравнить эффективность кодов, полученных при побуквенном кодировании, при кодировании блоков, содержащих по две буквы, при кодировании блоков, содержащих по три буквы.
Так как знаки статистически не связаны, вероятности блоков определяются как произведение вероятностей составляющих знаков.
Решение.
Задание 1.
В чем суть эффективного статистического кодирования?
Эффективное (статистическое) кодирование осуществляется с целью повышения скорости передачи информации и приближения её к пропускной способности канала.
Теорема Шеннона для эффективных кодов: для канала без помех всегда можно создать систему эффективного кодирования дискретных сообщений, у которой среднее количество двоичных кодовых сигналов на один символ сообщения будет приближаться как угодно близко к энтропии источника сообщений.
Задание 2. Решить следующие задачи:
Задача 1. Разработать код с использованием метода Шеннона-Фано для входного алфавита Z = {z1,...z8} и выходного алфавита В = {0,1}, если вероятность использования знаков входного алфавита:
| Знаки | Вероятность |
| Z1 | 0,22 |
| Z2 | 0,20 |
| Z3 | 0,16 |
| Z4 | 0,16 |
| Z5 | 0,10 |
| Z6 | 0,10 |
| Z7 | 0,04 |
| Z8 | 0,02 |
Определить коэффициент избыточности полученного кода и среднее число символов на знак сообщения.
Решение:
Метод Шеннона-Фано:
Знаки алфавита сообщений выписывают в таблицу в порядке убывания вероятностей их использования. Затем их разделяют на 2 группы так, чтобы суммы вероятностей в каждой из них были по возможности одинаковы. Всем знакам верхней половины в качестве первого символа приписывают единицу, а всем нижним - ноль. Каждую из полученных групп, в свою очередь, разбивают на 2 подгруппы с одинаковыми суммарными вероятностями и так далее, процесс повторяется до тех пор, пока в каждой подгруппе не останется по одному знаку.
Проделаем следующие действия:
| Знаки | Вер. | Код |
| Z1 | 0,28 | |
| Z3 | 0,16 | |
| Z5 | 0,10 | |
| Z8 | 0,02 |
| Знаки | Вер. | Код |
| Z2 | 0,20 | |
| Z4 | 0,16 | |
| Z6 | 0,10 | |
| Z7 | 0,04 |
| Знаки | Вер. | Код |
| Z1 | 0,28 | |
| Z8 | 0,02 |
| Знаки | Вер. | Код |
| Z3 | 0,16 | |
| Z5 | 0,10 |
| Знаки | Вер. | Код |
| Z1 | 0,28 |
| Знаки | Вер. | Код |
| Z8 | 0,02 |
| Знаки | Вер. | Код |
| Z3 | 0,16 |
| Знаки | Вер. | Код |
| Z5 | 0,10 |
| Знаки | Вер. | Код |
| Z4 | 0,16 | |
| Z6 | 0,10 |
| Знаки | Вер. | Код |
| Z4 | 0,16 |
| Знаки | Вер. | Код |
| Z6 | 0,10 |
| Знаки | Вер. | Код |
| Z2 | 0,20 | |
| Z7 | 0,04 |
| Знаки | Вер. | Код |
| Z2 | 0,20 |
| Знаки | Вер. | Код |
| Z7 | 0,04 |












| Знаки | Вероятность | Код |
| Z1 | 0,22 | |
| Z2 | 0,20 | |
| Z3 | 0,16 | |
| Z4 | 0,16 | |
| Z5 | 0,10 | |
| Z6 | 0,10 | |
| Z7 | 0,04 | |
| Z8 | 0,02 |
Запишем полученный код
Среднее число символов на знак сообщения считается по следующей формуле: 
где p(zi) – вероятность использования знака zi
n(zi) – число символов в кодовой комбинации, соответствующей знаку zi
Рассчитаем:


Hmax(z) – максимально возможная энтропия, равная log L, где L – количество знаков в алфавите сообщений. Рассчитывается по уже известной формуле Хартли;
H(Z) – энтропия кода. Рассчитывается по формуле Шеннона.
Произведем расчет:



Задача 2.
Разработать код с использованием метода Хаффмена для входного алфавита Х = {x1,...x8} и выходного алфавита В = {0,1}, если р(х1)= 0,19; р(х2)= 0,17; р(х3)= р(х4)= 0,15; р(х5)= 0,12; р(х6)= 0,11; р(х7)= 0,09; р(х8)= 0,02, и определить коэффициент избыточности полученного кода.
Решение:
Методика Хаффмена для построения двоичных эффективных кодов:
Знаки алфавита сообщений выписывают в таблицу в порядке убывания вероятностей их использования. Две последние буквы объединяют в одну вспомогательную букву, которой приписывают суммарную вероятность, объединенные буквы обозначают 1 и 0. Затем вероятности снова располагают в порядке убывания, учитывая и суммарную вероятность. Две последние буквы объединяют, обозначают 1 и 0. Процесс продолжается до тех пор, пока не получат единственную вспомогательную букву с вероятностью, равной единице - это "корень" дерева, знаки сообщения - "листья" дерева. Символы 0 и 1, встречающиеся на пути от "корня" к некоторому "листу" дерева, составляют кодовую комбинацию, соответствующего "листу" сообщения.
Составим таблицу:
| Знаки | Вероятность |
| x1 | 0,19 |
| x2 | 0,17 |
| x3 | 0,15 |
| x4 | 0,15 |
| x5 | 0,12 |
| x6 | 0,11 |
| x7 | 0,09 |
| x8 | 0,02 |
Теперь применим методику Хаффмена:
| Знаки | Вероятность | |
| x1 | 0,19 | |
| x2 | 0,17 | |
| x3 | 0,15 | |
| x4 | 0,15 | |
| x5 | 0,12 | |
| x6 | 0,11 | |
| x7 | 0,09 | |
| x8 | 0,02 |
| Знаки | Вероятность | |
| x1 | 0,19 | |
| x2 | 0,17 | |
| x3 | 0,15 | |
| x4 | 0,15 | |
| x5 | 0,12 | |
| x6 | 0,11 | |
| x78 | 0,11 |
| Знаки | Вероятность | |
| х678 | 0,22 | |
| x1 | 0,19 | |
| x2 | 0,17 | |
| x3 | 0,15 | |
| x4 | 0,15 | |
| x5 | 0,12 |
| Знаки | Вероятность | |
| х45 | 0,27 | |
| х678 | 0,22 | |
| x1 | 0,19 | |
| x2 | 0,17 | |
| x3 | 0,15 |
| Знаки | Вероятность | |
| х32 | 0,32 | |
| х45 | 0,27 | |
| х678 | 0,22 | |
| x1 | 0,19 |
| Знаки | Вероятность | |
| х1678 | 0,41 | |
| х32 | 0,32 | |
| х45 | 0,27 |
| Знаки | Вероятность | |
| х2345 | 0,59 | |
| х1678 | 0,41 |
Теперь запишем полученные коды для всех знаков алфавита:
| Знаки | Вероятность | Код |
| x1 | 0,19 | |
| x2 | 0,17 | |
| x3 | 0,15 | |
| x4 | 0,15 | |
| x5 | 0,12 | |
| x6 | 0,11 | |
| x7 | 0,09 | |
| x8 | 0,02 |
Среднее число символов на знак сообщения считается по следующей формуле:
 ,
,
где p(zi) – вероятность использования знака zi
n(zi) – число символов в кодовой комбинации, соответствующей знаку zi

Избыточность кода определяется по формуле:
 ,
,
где
Hmax(z) – максимально возможная энтропия, равная log L, где L – количество знаков в алфавите сообщений. Рассчитывается по формуле Хартли;
H(Z) – энтропия кода. Рассчитывается по формуле Шеннона
Произведем расчет:



Задача 3. Алфавит сообщений состоит всего из двух знаков Z1 и Z2 с вероятностями появления соответственно p(z1) = 0,9 и p(z2) = 0,1.
Рассчитать и сравнить эффективность кодов, полученных при побуквенном кодировании, при кодировании блоков, содержащих по две буквы, при кодировании блоков, содержащих по три буквы. Так как знаки статистически не связаны, вероятности блоков определяются как произведение вероятностей составляющих знаков.
Решение:
В качестве меры эффективности кодов можно использовать энтропию. Энтропия является мерой неопределенности, соответственно, чем она ниже тем выше определенность, что и говорит об эффективности кода.
1. Побуквенное кодирование:
| Знаки | Вероятность |
| z1 | 0,9 |
| z2 | 0,1 |
Рассчитаем энтропию:

2. Кодирование блоков, содержащих по две буквы:
| Знаки | Вероятность |
| z1z1 | 0,81 |
| z1z2 | 0,09 |
| z2z1 | 0,09 |
| z2z2 | 0,01 |
Рассчитаем энтропию:
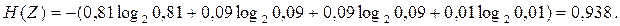
3. Кодирование блоков, содержащих по три буквы:
| Знаки | Вероятность |
| z1z1z1 | 0,729 |
| z1z1z2 | 0,081 |
| z1z2z1 | 0,081 |
| z1z2z2 | 0,009 |
| z2z1z1 | 0,081 |
| z2z1z2 | 0,009 |
| z2z2z1 | 0,009 |
| z2z2z2 | 0,001 |
Рассчитаем энтропию:
 Как видно из вышеприведенных расчетов самым эффективным является побуквенное кодирование, т.к. при таком кодировании энтропия минимальна.
Как видно из вышеприведенных расчетов самым эффективным является побуквенное кодирование, т.к. при таком кодировании энтропия минимальна.