Сначала краткая постановка задачи, возникшая как подзадача для задачи планирования траектории: есть статическое изображение, полученное с помощью камеры мобильного робота:

это изображение можно рассматривать как среду с препятствиями (сцена), представляющую собой совокупность объектов различных цветов и размеров, причем заранее неизвестно какой из объектов полезный (цель), а какой является препятствием (помехой). Так же предполагается, что каждый объект на изображении (препятствия, фон и дорожное покрытие) описывается своими цветами – основной признак, по которому можно его классифицировать. Так вот необходимо уметь выделять любой из объектов представленных на изображении.
Буквально кратко напомню, что такое кластеризация данных, в общем случае кластерный анализ (англ. Data clustering) — задача разбиения заданной выборки объектов (ситуаций) на подмножества, называемые кластерами, так, чтобы каждый кластер состоял из схожих объектов, а объекты разных кластеров существенно отличались. Задача кластеризации относится к статистической обработке, а также к широкому классу задач обучения без учителя. Кластерный анализ — это многомерная статистическая процедура, выполняющая сбор данных, содержащих информацию о выборке объектов, и затем упорядочивающая объекты в сравнительно однородные группы (кластеры)(Q-кластеризация, или Q-техника, собственно кластерный анализ). Кластер — группа элементов, характеризуемых общим свойством, главная цель кластерного анализа — нахождение групп схожих объектов в выборке.
И зачем это вообще надо и без кластеризации можно жить? Тоже никто так и не осветил, попробую снять завесу с назначения этого понятия.
- Понимание данных путём выявления кластерной структуры. Разбиение выборки на группы схожих объектов позволяет упростить дальнейшую обработку данных и принятия решений, применяя к каждому кластеру свой метод анализа (стратегия «разделяй и властвуй»).
- Сжатие данных. Если исходная выборка избыточно большая, то можно сократить её, оставив по одному наиболее типичному представителю от каждого кластера.
- Обнаружение новизны (англ. novelty detection). Выделяются нетипичные объекты, которые не удаётся присоединить ни к одному из кластеров.
В первом случае число кластеров стараются сделать поменьше. Во втором случае важнее обеспечить высокую степень сходства объектов внутри каждого кластера, а кластеров может быть сколько угодно. В третьем случае наибольший интерес представляют отдельные объекты, не вписывающиеся ни в один из кластеров. Во всех этих случаях может применяться иерархическая кластеризация, когда крупные кластеры дробятся на более мелкие, те в свою очередь дробятся ещё мельче, и т. д. Такие задачи называются задачами таксономии. Результатом таксономии является древообразная иерархическая структура. При этом каждый объект характеризуется перечислением всех кластеров, которым он принадлежит, обычно от крупного к мелкому. Классическим примером таксономии на основе сходства является биноминальная номенклатура живых существ, предложенная Карлом Линнеем в середине XVIII века. Аналогичные систематизации строятся во многих областях знания, чтобы упорядочить информацию о большом количестве объектов.
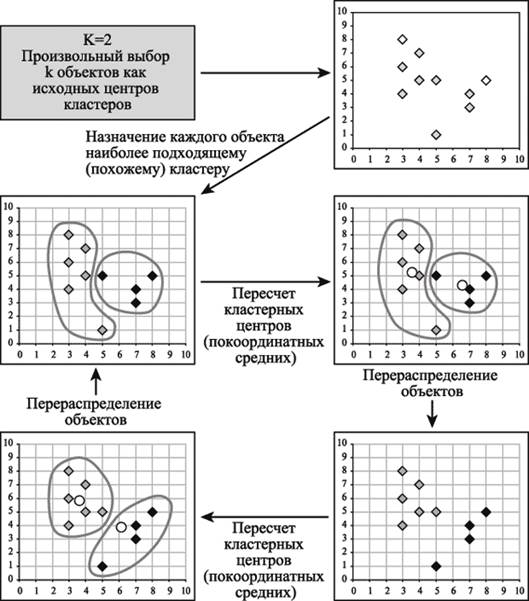
С головой хватит пока теории, вернемся к проблеме, теперь, когда кто-то познакомился с термином, кто-то освежил в голове, а кто и совсем пропустил, будем решать задачу. Для решения взят метод кластеризации к-средних (k-means), потому что данный метод не требует предварительных предположений относительно числа кластеров, для возможности использования этого метода необходимо иметь гипотезу о наиболее вероятном количестве кластеров. Общая идея алгоритма: заданное фиксированное число k кластеров наблюдения сопоставляются кластерам так, что средние в кластере (для всех переменных) максимально возможно отличаются друг от друга. Для любителей картинок и попытка «объяснить на пальцах» (при количестве кластеров равно двум):
Основные достоинства алгоритма k-средних:
- простота использования;
- быстрота использования;
- понятность и прозрачность алгоритма.
Недостатки алгоритма k-средних:
- алгоритм слишком чувствителен к выбросам, которые могут искажать среднее. Возможным решением этой проблемы является использование модификации алгоритма — алгоритм k-медианы;
- алгоритм может медленно работать на больших базах данных. Возможным решением данной проблемы является использование выборки данных.