Проблемы масштабируемости -проблема непротиворечивости ресурса. На масштабируемость может плохо повлиять один существенный недостаток кэширования и репликации.
Поскольку мы получаем множество копий ресурса, модификация одной копии делает ее отличной от остальных. Соответственно, кэширование и репликация вызывают проблемы непротиворечивости (consistency). Допустимая степень противоречивости зависит от степени загрузки ресурсов. Так, множество пользователей Web считают допустимым работу с кэшированным документом через несколько минут после его помещения в кэш без дополнительной проверки. Однако существует множество случаев, когда необходимо гарантировать строгую непротиворечивость. Например, при игре на электронной бирже Проблема строгой непротиворечивости ресурса состоит в немедленном распространении изменений во все копии.
При одновременном изменении двух или более копий необходимо строго соблюдать порядок внесения изменений во все копии. Практически обеспечить это бывает довольно сложно, а иногда – невозможно.
Это означает, что репликация может включать и отдельные не масштабируемые решения.
14. Модель клиент-сервер.
«Клиент — сервер» (англ. client–server) — вычислительная или сетевая архитектура, в которой задания или сетевая нагрузка распределены между поставщиками услуг, называемыми серверами, и заказчиками услуг, называемыми клиентами. Фактически клиент и сервер — это программное обеспечение. Обычно эти программы расположены на разных вычислительных машинах и взаимодействуют между собой через вычислительную сеть посредством сетевых протоколов, но они могут быть расположены также и на одной машине. Программы-серверы ожидают от клиентских программ запросы и предоставляют им свои ресурсы в виде данных (например, загрузка файлов посредством HTTP, FTP, BitTorrent, потоковое мультимедиа или работа с базами данных) или в виде сервисных функций (например, работа с электронной почтой, общение посредством систем мгновенного обмена сообщениями или просмотр web-страниц во всемирной паутине). Поскольку одна программа-сервер может выполнять запросы от множества программ-клиентов, её размещают на специально выделенной вычислительной машине, настроенной особым образом, как правило, совместно с другими программами-серверами, поэтому производительность этой машины должна быть высокой. Из-за особой роли такой машины в сети, специфики её оборудования и программного обеспечения, её также называют сервером, а машины, выполняющие клиентские программы, соответственно, клиентами.
Преимущества
Отсутствие дублирования кода программы-сервера программами-клиентами.
Так как все вычисления выполняются на сервере, то требования к компьютерам, на которых установлен клиент, снижаются.
Все данные хранятся на сервере, который, как правило, защищён гораздо лучше большинства клиентов. На сервере проще организовать контроль полномочий, чтобы разрешать доступ к данным только клиентам с соответствующими правами доступа.
Недостатки
Неработоспособность сервера может сделать неработоспособной всю вычислительную сеть. Неработоспособным сервером следует считать сервер, производительности которого не хватает на обслуживание всех клиентов, а также сервер, находящийся на ремонте, профилактике и т. п.
Поддержка работы данной системы требует отдельного специалиста — системного администратора.
Высокая стоимость оборудования.
15. Расскажите, зачем нужен уровень обработки данных.
Уровень обработки данных:
1. Объединяет части, реализующие бизнес-логику приложения,
2. Является посредником между уровнем представления данных и уровнем их хранения. Через него проходят все данные и претерпевают в нем изменения, обусловленные решаемой задачей (см. рис. 2).

Рис. 2. Основные уровни архитектуры распределенного приложения
К функциям этого уровня относятся следующие:
обработка потоков данных в соответствии с бизнес-правилами;
взаимодействие с уровнем представления данных для получения запросов и возвращения ответов;
взаимодействие с уровнем хранения данных для передачи запросов и получения ответов.
Чаще всего уровень обработки данных отождествляют с промежуточным ПО распределенного приложения.
Такая ситуация в полной мере верна для "идеальной" системы и лишь отчасти - для реальных приложений (см. рис. 3).
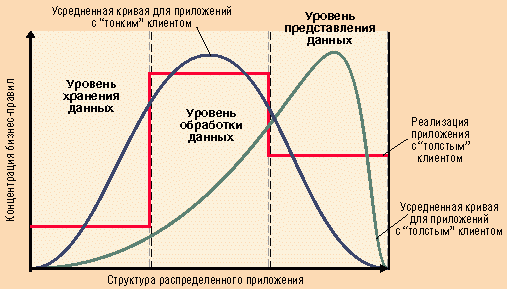
Рис. 3. Распределение бизнес-логики по уровням распределенного приложения
Что касается реальных приложений, то промежуточное ПО для них содержит большую долю правил обработки данных, но часть из них реализована в серверах SQL в виде хранимых процедур или триггеров, а часть включена в состав клиентского ПО.
16. Расскажите, как работает RPC.
Удалённый вызов процедур, реже Вызов удалённых процедур (от англ. Remote Procedure Call, RPC) — класс технологий, позволяющих компьютерным программам вызывать функции или процедуры в другом адресном пространстве (как правило, на удалённых компьютерах). Обычно реализация RPC технологии включает в себя два компонента: сетевой протокол для обмена в режиме клиент-сервер и язык сериализации объектов (или структур, для необъектных RPC). Различные реализации RPC имеют очень отличающуюся друг от друга архитектуру и разнятся в своих возможностях: одни реализуют архитектуру SOA, другие CORBA или DCOM. На транспортном уровне RPC используют в основном протоколы TCP и UDP, однако, некоторые построены на основе HTTP (что нарушает архитектуру ISO/OSI, так как HTTP изначально не транспортный протокол).
Идея вызова удалённых процедур состоит в расширении хорошо известного и понятного механизма передачи управления и данных внутри программы, выполняющейся на одной машине, на передачу управления и данных через сеть. Средства удалённого вызова процедур предназначены для облегчения организации распределённых вычислений и создания распределенных клиент-серверных информационных систем. Наибольшая эффективность использования RPC достигается в тех приложениях, в которых существует интерактивная связь между удалёнными компонентами с небольшим временем ответов и относительно малым количеством передаваемых данных. Такие приложения называются RPC-ориентированными.
Характерными чертами вызова удалённых процедур являются:
Асимметричность, то есть одна из взаимодействующих сторон является инициатором;
Синхронность, то есть выполнение вызывающей процедуры приостанавливается с момента выдачи запроса и возобновляется только после возврата из вызываемой процедуры.
Реализация удалённых вызовов существенно сложнее реализации вызовов локальных процедур. Можно обозначить следующие проблемы и задачи, которые необходимо решить при реализации RPC:
Так как вызывающая и вызываемая процедуры выполняются на разных машинах, то они имеют разные адресные пространства, и это создает проблемы при передаче параметров и результатов, особенно если машины находятся под управлением различных операционных систем или имеют различную архитектуру (например, используется прямой или обратный порядок байтов). Так как RPC не может рассчитывать на разделяемую память, то это означает, что параметры RPC не должны содержать указателей на ячейки нестековой памяти и что значения параметров должны копироваться с одного компьютера на другой. Для копирования параметров процедуры и результата выполнения через сеть выполняется их сериализация.
В отличие от локального вызова удалённый вызов процедур обязательно использует транспортный уровень сетевой архитектуры (например TCP), однако это остается скрытым от разработчика.
Выполнение вызывающей программы и вызываемой локальной процедуры в одной машине реализуется в рамках единого процесса. Но в реализации RPC участвуют как минимум два процесса — по одному в каждой машине. В случае, если один из них аварийно завершится, могут возникнуть следующие ситуации: при аварии вызывающей процедуры удалённо вызванные процедуры станут «осиротевшими», а при аварийном завершении удалённых процедур станут «обездоленными родителями» вызывающие процедуры, которые будут безрезультатно ожидать ответа от удалённых процедур.
Существует ряд проблем, связанных с неоднородностью языков программирования и операционных сред: структуры данных и структуры вызова процедур, поддерживаемые в каком-либо одном языке программирования, не поддерживаются точно так же во всех других языках. Таким образом имеется проблема совместимости, до сих пор не решённая ни с помощью введения одного общепринятого стандарта, ни с помощью реализации нескольких конкурирующих стандартов на всех архитектурах и во всех языках.
Транспортная подсистема
— управление исходящими и входящими соединениями.
— поддержка понятия «граница сообщения» для транспортных протоколов, не поддерживающих его непосредственно (TCP).
— поддержка гарантированной доставки для транспортных протоколов, не поддерживающих её непосредственно (UDP).
Пул потоков (только для вызываемой стороны). Предоставляет контекст выполнения для вызванного по сети кода.
Маршалинг (аналог «сериализации»). Упаковка параметров вызовов в поток байт стандартным образом, не зависящим от архитектуры (в частности, от порядка байт в слове). В частности, ему могут подвергаться массивы, строки и структуры, на которые указывают параметры-указатели.
Шифрование пакетов и наложение на них цифровой подписи.
Аутентификация и авторизация. Передача по сети информации, идентифицирующей субъект, осуществляющий вызов.
В некоторых реализациях RPC (.NET Remoting) границы подсистем являются открытыми полиморфными интерфейсами, и возможно написать свою реализацию почти всех перечисленных подсистем. В других реализациях (DCE RPC в Windows) это не так.
17. Асинхронный вызов RPC.
См. 16.
18. Работа с распределёнными объектами.Перемещение объектов в распределённой системе.
Ключевая особенность объекта состоит в том, что он инкапсулирует данные, называемые состоянием (state), и операции над этими данными, называемые методами (methods). Доступ к методам можно получить через интерфейс. Важно понять, что единственно правильным способом доступа или манипулирования состоянием объекта является использование методов, доступ к которым осуществляется через интерфейс этого объекта. Объект может реализовывать множество интерфейсов. Точно так же для данного описания интерфейса может существовать несколько объектов, предоставляющих его реализацию.
Это подразделение на интерфейсы и объекты, реализующие их, очень важно для распределенных систем. Четкое разделение позволяет нам помещать интерфейс на одну машину при том, что сам объект находится на другой. Структура, показанная на рис. 2.16, обычно и называется распределенным объектом (distributed object).

Рис. 2.16. Обобщенная организация удаленных объектов с использованием заместителя клиента
Когда клиент выполняет привязку к распределенному объекту, в адресное пространство клиента загружается реализация интерфейса объекта, называемая заместителем (proxy). Заместитель клиента аналогичен клиентской заглушке в системах RPC. Единственное, что он делает, — выполняет маршалинг параметров в сообщениях при обращении к методам и демаршалинг данных из ответных сообщений, содержащих результаты обращения к методам, передавая их клиенту. Сами объекты находятся на сервере и предоставляют необходимые клиентской машине интерфейсы. Входящий запрос на обращение к методу сначала попадает на серверную заглушку, часто именуемую скелетоном (skeleton). Скелетон преобразует его в правильное обращение к методу через интерфейс объекта, находящегося на сервере. Серверная заглушка также отвечает за маршалинг параметров в ответных сообщениях и их пересылку заместителю клиента.
Характерной, но немного противоречащей интуитивному представлению особенностью большинства распределенных объектов является то, что их состояние (данные) не распределяется — оно локализовано на одной машине. С других машин доступны только интерфейсы, реализованные в объекте. Такие объекты еще называют удаленными (remote object). Тем не менее, при работе с распределенными объектами, их состояние может быть физически распределено по нескольким машинам, но это распределение также скрывается от клиентов за интерфейсами объектов.
19. Проблемы и технологии обмена сообщениями.
Обмен сообщениями — это технология высокоскоростного асинхронного взаимодействия между программами с гарантией доставки информации. Программы взаимодействуют между собой обмениваясь сообщениями.
Система обмена сообщениями — это некоторый программный комплекс, который обеспечивает хранение и передачу двоичных данных (в большинстве случаев) между различными участниками системы. Использование системы обмена сообщениями обладает такими важными преимуществами:
независимость взаимодействующих приложений через общий интерфейс;
экономия и рациональное использование ресурсов;
надежность, благодаря возможности накапливать сообщения, а так же благодаря независимости компонентов;
возможность доставки сообщений, после сбоя одного из компонентов после “восстановления”;
гарантия доставки сообщения.
Канал или очередь — это логический маршрут, объединяющий программы и использующийся для транспортировки сообщений, он также напоминает массив сообщений, который доступный для многих приложений одновременно. Приложения, объединенные с помощью технологии обмена сообщениями, передают данные по каналам сообщений. Изначально система обмена сообщениями не содержит каналов, они создаются по мере определения потребностей.
Сообщение — это наименьшая единица данных, которая может быть передана по каналу сообщений. Для передачи данных отправитель должен разбить их на пакеты, которые затем будут упакованы в сообщения и помещены в канал. Обычно сообщение состоит их двух основных частей:
Заголовок сообщения содержит информацию для выполнения адресации в системе обмена сообщениями;
Тело сообщения содержит полезные данные и как правило игнорируются системой обмена сообщениями.
Отправитель или поставщик — программа, отправляющая сообщение путем его размещения в канале.
Получатель или потребитель — программа, получающая сообщение путем его считывания из канала и удаляет это сообщение на определенном этапе (обычно после считывания).
Функционирование обмена сообщениями обеспечивается отдельной программной системой — системой обмена сообщениями (message-oriented middleware). Необходимость наличия такой системы обусловлена ненадежностью сетей, различные сбои, необходимостью ускорения процесса принятия решений (итоговое решение формируется из нескольких источников, например: система управления складом, финансовая система, система доставки и другие.). Процедура передачи сообщения состоит из 5 основных этапов:
Создание сообщения;
Отправка сообщения;
Доставка сообщения;
Получение сообщения;
Обработка сообщения.
"Отправить и забыть" (Send and forget) — поместив сообщение в канал (этап 2), отправитель может не заботится о судьбе сообщения, доставку обеспечит система обмена сообщениями.
Преимущества обмена сообщениями
Обмен сообщениями позволяет наладить взаимодействие между приложениями. Можно конечно возразить, что все инструменты есть в платформе 1С, но не один не гарантирует доставку;
Интеграция разнородных систем и технологий. Использовать для все и вся платформу 1С очень плохая идея, при том, что быстродействие платформы низкое, а масштабирование — дорогое;
Взаимодействия между приложениями происходят асинхронно. Для платформы 1С так же верно, пока не закончатся лицензии на подключение;
При синхронном взаимодействии отправитель должен дождаться завершения обработки вызова получателем прежде, чем сделать новый вызов. Таким образом, если посмотреть на пример в начале статьи, у касс не будет очередей при использовании "заявок на выплату". Асинхронное взаимодействие позволяет размещать и обрабатывать вызовы с разной скоростью. Другими словами можно балансировать лицензиями на подключение к «1С:Предприятие 8», можно балансировать нагрузку на сервер 1С, создать кэширование на уровне очереди и т. п.;
Возможность балансирования нагрузки, система обмена сообщениями формирует очередь запросов, позволяя получателю контролировать скорость их обработки;
Надежное взаимодействие между системами;
Возможность работы без подключения к сети, например, торговые агенты, которые периодически выполняют синхронизацию с сервером;
Приложение может быть интегрировано с множеством приложений используя только — систему обмена сообщениями;
Асинхронное взаимодействие позволяет приложению не ожидать результата выполнения задачи другим приложением, когда задача будет выполнена, приложение может быть оповещено о результатах.
Недостатки обмена сообщениями
Довольно сложная реализация;
Довольно сложно отлаживать и тестировать;
Порядок доставки сообщений неизвестен. Необходимо дополнительно восстанавливать порядок сообщений, если он необходим;
Дополнительные задержки при использовании обмена сообщениями, в сравнении с использованием прямого вызова приложения;
Ограниченная поддержка закрытыми, старыми (legacy) системами.
20. Потоки данных и качество обслуживания в распределённой системе.
Надеюсь, этот вопрос никому не попадется!)
21. Именование сущностей в распределённых системах.
Тоже самое(.
22. Организация ссылок в распределённых системах.
Да что такое с ними не так?
23. Службы каталогов X.500 и LDAP.
Технология X.500 является самым распространенным протоколом управления каталогами. Существует два стандарта X.500: версии 1988 и 1993 гг. Служба каталогов Windows относится к реализации стандарта 1993 года.
В модели X.500 используется иерархический подход к размещению объектов в пространстве имен. Пространство имен начинается с корневого раздела верхнего уровня и потомков, происходящих от этого раздела. Домены Windows именуются с помощью службы DNS (например, microsoft.com является именем домена, а legal.microsoft.com —дочерним доменом для домена microsoft.com).
Предположим, что каждая страна является дочерним доменом корневого раздела (например, usa.root.com, england.root.com). Каждый дочерний домен можно разделить на несколько организаций, а организации —на организационные подразделения. Различные настройки и политики доступа относятся к разным подразделениям. Каждое подразделение содержит несколько объектов, например, пользователей, компьютеры и группы.
Хотя служба каталогов Windows основывается на модели X.500, в качестве механизма доступа используется протокол LDAP, созданный для решения некоторых проблем, связанных с X.500.
Технология X.500 представляет собой часть модели OSI (Open System Interconnection), однако реализация OSI на базе стека протоколов TCP/IP сопряжена с немалыми трудностями. Именно по этой причине протокол LDAP использует TCP/IP в качестве коммуникационной среды. Протокол LDAP сокращает количество функций универсальной модели X.500, тем самым предоставляя многофункциональную службу каталогов, обеспечивающую хорошее быстродействие и обратную поддержку общей структуры X.500.
Протокол LDAP применяется для взаимодействия с Active Directory, то есть для проведения основных операций чтения, записи и изменения данных.
24. Организация поиска мобильных сущностей.
Опять нет четкого ответа
25. Проблема и технология синхронизации часов в распределённой системе.
Алгоритм синхронизации логических часов
В централизованной однопроцессорной системе, как правило, важно только относительное время и не важна точность часов. В распределенной системе, где каждый процессор имеет собственные часы со своей точностью хода, ситуация резко меняется: программы, использующие время (например, программы, подобные команде make в UNIX, которые используют время создания файлов, или программы, для которых важно время прибытия сообщений и т.п.) становятся зависимыми от того, часами какого компьютера они пользуются. В распределенных системах синхронизация физических часов (показывающих реальное время) является сложной проблемой, но с другой стороны очень часто в этом нет никакой необходимости: то есть процессам не нужно, чтобы во всех машинах было правильное время, для них важно, чтобы оно было везде одинаковое, более того, для некоторых процессов важен только правильный порядок событий. В этом случае мы имеем дело с логическими часами.
Введем для двух произвольных событий отношение "случилось до". Выражение a ® b читается "a случилось до b" и означает, что все процессы в системе считают, что сначала произошло событие a, а потом - событие b. Отношение "случилось до" обладает свойством транзитивности: если выражения a ® b и b ® c истинны, то справедливо и выражение a ® c. Для двух событий одного и того же процесса всегда можно установить отношение "случилось до", аналогично может быть установлено это отношение и для событий передачи сообщения одним процессом и приемом его другим, так как прием не может произойти раньше отправки. Однако, если два произвольных события случились в разных процессах на разных машинах, и эти процессы не имеют между собой никакой связи (даже косвенной через третьи процессы), то нельзя сказать с полной определенностью, какое из событий произошло раньше, а какое позже.
Ставится задача создания такого механизма ведения времени, который бы для каждого события а мог указать значение времени Т(а), с которым бы были согласны все процессы в системе. При этом должно выполняться условие: если а ® b, то Т(а) < Т(b). Кроме того, время может только увеличиваться и, следовательно, любые корректировки времени могут выполняться только путем добавления положительных значений, и никогда - путем вычитания.
Рассмотрим алгоритм решения этой задачи, который предложил Lamport. Для отметок времени в нем используются события. На рисунке 3.6 показаны три процесса, выполняющихся на разных машинах, каждая из которых имеет свои часы, идущие со своей скоростью. Как видно из рисунка, когда часы процесса 0 показали время 6, в процессе 1 часы показывали 8, а в процессе 2 - 10. Предполагается, что все эти часы идут с постоянной для себя скоростью.
В момент времени 6 процесс 0 посылает сообщение А процессу 1. Это сообщение приходит к процессу 1 в момент времени 16 по его часам. В логическом смысле это вполне возможно, так как 6<16. Аналогично, сообщение В, посланное процессом 1 процессу 2 пришло к последнему в момент времени 40, то есть его передача заняла 16 единиц времени, что также является правдоподобным.

Рис. 3.6. Синхронизация логических часов
а - три процесса, каждый со своими собственными часами;
б - алгоритм синхронизации логических часов
Ну а далее начинаются весьма странные вещи. Сообщение С от процесса 2 к процессу 1 было отправлено в момент времени 64, а поступило в место назначения в момент времени 54. Очевидно, что это невозможно. Такие ситуации необходимо предотвращать. Решение Lamport'а вытекает непосредственно из отношений "случилось до". Так как С было отправлено в момент 60, то оно должно дойти в момент 61 или позже. Следовательно, каждое сообщение должно нести с собой время своего отправления по часам машины-отправителя. Если в машине, получившей сообщение, часы показывают время, которое меньше времени отправления, то эти часы переводятся вперед, так, чтобы они показали время, большее времени отправления сообщения. На рисунке 3.6,б видно, что С поступило в момент 61, а сообщение D - в 70.
Этот алгоритм удовлетворяет сформулированным выше требованиям.
26. Логическое время. Отметки времени Лампорта.
Логические часы — механизм определения хронологической и причинно-следственной связи событий в распределённых системах, не имеющих единых физических часов. Алгоритмы логических часов позволяют получать частичное упорядочение событий по времени и обнаруживать нарушения причинно-следственных связей.
Для синхронизации логических часов Lamport определил отношение "произошло до". Выражение a->b читается как "a произошло до b" и означает, что все процессы согласны, что сначала произошло событие "a", а затем "b". Это отношение может в двух случаях быть очевидным:
Если оба события произошли в одном процессе.
Если событие a есть операция SEND в одном процессе, а событие b - прием этого сообщения другим процессом.
Отношение -> является транзитивным.
Если два события x и y случились в различных процессах, которые не обмениваются сообщениями, то отношения x->y и y->x являются неверными, а эти события называют одновременными.
Введем логическое время С таким образом, что если a->b, то C(a) < C(b)
Алгоритм:
Часы Ci увеличивают свое значение с каждым событием в процессе Pi: Ci=Ci+d (d > 0, обычно равно 1)
Если событие a есть посылка сообщения m процессом Pi, тогда в это сообщение вписывается временная метка tm=Ci(a). В момент получения этого сообщения процессом Pj его время корректируется следующим образом: Cj = max(Cj,tm+d)

Сначала рассмотрим поведение данной системы безотносительно физического времени. Процесс X взаимодействует с процессом Y (например, направив ему сообщение). Можно утверждать, что отправка сообщения процессом X происходит до его получения процессом Y. Затем процесс Y взаимодействует с процессом Z.
Теперь предположим, что у каждого процесса имеются локальные часы, показания которых, могут расходиться. Для записи времени событий в каждом отдельном процессе можно использовать локальные часы, но при этом нужно выработать определенные соглашения о том, какое из событий побеждает (то есть происходит первым) при совпадении отметок времени. Например, для этого отметку времени можно дополнять идентификатором процесса.
Общая последовательность событий в системе будет соблюдаться, если сможем гарантировать, что сдвиг частоты не вызовет нарушения ограничений. Предположим, что процесс X включает в отправляемое процессу Y сообщение отметку времени (отправка (m, tx)). Когда процесс Y получает это сообщение (получение (m, tx)), его собственные часы показывают ty (рис.5.2).
-Если Ty > Tx, то все в порядке
-Если Ty < Tx, то имеет место нарушение ограничения на порядок событий.

Процесс Y может установить на своих часах время tx+ 1, и все будет в порядке, хотя системное время будет все больше и больше расходиться с реальным. Главное, что порядок событий в системе будет соблюдаться.
27. Методы голосования. Алгоритм забияки.
Координатор – один из процессов, который должен выполнить специальные функции по инициации, координации.
Многие распределенные алгоритмы требуют, чтобы один из процессов выполнял функции координатора, инициатора или некоторую другую специальную роль. Выбор такого специального процесса будем называть выбором координатора. При этом очень часто бывает не важно, какой именно процесс будет выбран. Можно считать, что обычно выбирается процесс с самым большим уникальным номером. Могут применяться разные алгоритмы, имеющие одну цель - если процедура выборов началась, то она должна закончиться согласием всех процессов относительно нового координатора.
Алгоритм "задиры"
Если процесс обнаружит, что координатор очень долго не отвечает, то инициирует выборы. Процесс P проводит выборы следующим образом:
P посылает сообщение "ВЫБОРЫ" всем процессам с большими, чем у него номерами.
Если нет ни одного ответа, то P считается победителем и становится координатором.
Если один из процессов с большим номером ответит, то он берет на себя проведение выборов. Участие процесса P в выборах заканчивается.
В любой момент процесс может получить сообщение "ВЫБОРЫ" от одного из коллег с меньшим номером. В этом случае он посылает ответ "OK", чтобы сообщить, что он жив и берет проведение выборов на себя, а затем начинает выборы (если к этому моменту он уже их не вел). Следовательно, все процессы прекратят выборы, кроме одного - нового координатора. Он извещает всех о своей победе и вступлении в должность сообщением "КООРДИНАТОР".
Если процесс выключился из работы, а затем захотел восстановить свое участие, то он проводит выборы (отсюда и название алгоритма).
28. Распределённые транзакции.
Транза́кция (англ. transaction) — группа последовательных операций с базой данных, которая представляет собой логическую единицу работы с данными. Транзакция может быть выполнена либо целиком и успешно, соблюдая целостность данных и независимо от параллельно идущих других транзакций, либо не выполнена вообще, и тогда она не должна произвести никакого эффекта. Транзакции обрабатываются транзакционными системами, в процессе работы которых создаётся история транзакций.
Различают последовательные (обычные), параллельные и распределённые транзакции. Распределённые транзакции подразумевают использование более чем одной транзакционной системы и требуют намного более сложной логики (например, two-phase commit — двухфазный протокол фиксации транзакции). Также в некоторых системах реализованы автономные транзакции, или под-транзакции, которые являются автономной частью родительской транзакции.
29. Репликация как метод масштабирования.
Репликация — одна из техник масштабирования баз данных. Состоит эта техника в том, что данные с одного сервера базы данных постоянно копируются (реплицируются) на один или несколько других (называемые репликами). Для приложения появляется возможность использовать не один сервер для обработки всех запросов, а несколько. Таким образом появляется возможность распределить нагрузку с одного сервера на несколько.
30. Строгая непротиворечивость.
Модель строгой непротиворечивости определяется следующим условием: всякое чтение элемента данных х возвращает значение, соответствующее результату последней записи х.
Это определение естественно и очевидно, хотя подразумевает существование абсолютного глобального времени, в котором определение «последней» однозначно. Однопроцессорные системы традиционно соблюдают строгую непротиворечивость, и программисты таких систем склонны рассматривать такое поведение, как естественное. Рассмотрим следующую программу:
а = 1; а = 2; print(a);
Система, в которой эта программа напечатает 1 или любое другое значение, кроме 2, приведет к явному недовольству программистов.
Для системы, в которой данные разбросаны по нескольким машинам, а доступ к ним имеет несколько процессов, все сильно усложняется. Допустим, что х — элемент данных, хранящийся на машине В. Представим, что процесс, работающий на машине А, читает х в момент времени t1, то есть посылает В сообщение с требованием возвратить х. Чуть позже, в момент времени t2, процесс с машины В производит запись х. Если строгая непротиворечивость сохраняется, чтение должно всегда возвращать прежнее значение, которое не зависит от того, где находятся машины и насколько мал интервал между t1 и t2. Однако если t2 - t1 = 1 нс., а машины расположены в трех метрах друг от друга, то чтобы запрос на чтение от А к В дошел до машины раньше В с правления запроса на запись, он должен двигаться в 10 раз быстрее скорое света, а это противоречит теории относительности Эйнштейна.
Для детального изучения непротиворечивости будем использовать специальную нотацию, при помощи которой отобразим операции процессов на ось времени. Ось времени рисуется горизонтально, время увеличивается слева направо. Символы Wi(x)a и Ri(x)b означают соответственно, что выполнены запись процессом Р в элемент данных х значения а и чтение из этого элемента процессом Р, возвратившее b. Мы полагаем, что каждый элемент данных первоначально был инициализирован нулем. Если с процессом доступа к данным не было никаких проблем, мы можем опустить индексы у символов W и R.
На схеме (а) процесс Р1 осуществляет запись в элемент данных х, изменяя его значение на а. Отметим, что в принципе эта операция, W1(x)a, сначала производит копирование значения в локальное хранилище данных Р1, а затем распространяет его и на другие локальные копии. В нашем примере Р2 позже читает значение х из его локальной копии в хранилище и обнаруживает там значение а. Такое поведение характерно для хранилища данных, сохраняющего строгую непротиворечивость. В противоположность ему, на схеме (б) процесс Р2 производит чтение после записи (возможно, лишь на наносекунду позже, но позже) и получает нуль (NIL). Последующее чтение возвращает а. Такое поведение для хранилища данных, сохраняющего строгую непротиворечивость, некорректно.
31. Потенциальная непротиворечивость.
Степень, в которой процессы действительно работают параллельно, и степень,
вкоторой действительно должна быть гарантирована непротиворечивость, могут быть разными. Существует множество случаев, когда параллельность нужна лишь
вурезанном виде. Так, например, во многих системах управления базами данных большинство процессов не производит изменения данных, ограничиваясь лишь операциями чтения. Изменением данных занимается лишь один, в крайнем слу чае несколько процессов. Вопрос состоит в том, как быстро эти изменения могут стать доступными процессам, занимающимся только чтением данных.
Вкачестве другого примера рассмотрим глобальную систему именования, та кую как DNS. Пространство имен DNS разделено на домены, каждый домен имеет источник именования, который действует, как владелец этого домена. Только этот источник может обновить свою часть пространства имен. Соответственно, конфликт двух операций, которые хотели бы одновременно обновить одни и те же данные (то есть конфликт двойной записи), невозможен. Единственная си туация, которую может потребоваться решать, — это конфликт чтения-записи.
Втом случае, когда он происходит, часто распространение изменений может про изводиться постепенно, в том смысле, что процессы чтения могут обнаружить произошедшие изменения только через некоторое время после того, как они на самом деле произойдут.
Еще один пример — World Wide Web. Фактически web-страницывсегда из меняются одним человеком —web-мастеромили настоящим владельцем страницы. В результате разрешать конфликты двойной записи обычно не требуется. С дру гой стороны, для повышения эффективности браузеры ипрокси-серверычасто конфигурируются так, чтобы сохранять загруженные страницы в локальном кэ ше и возвращать при следующем запросе именно их. Важный момент обоих ти пов системweb-кэшированиясостоит в том, что они могут возвращать устарев шиеweb-страницы.Другими словами, кэшированные страницы, возвращаемые в ответ на запрос клиента, могут не соответствовать более новым версиям страниц, хранящимся наweb-сервере.Но даже при этом многие пользователи lyioryT счесть такое несоответствие приемлемым.
Эти примеры могут рассматриваться как случаи распределенных и реплицируемых баз данных (крупных), нечувствительных к относительно высокой степени нарушения непротиворечивости. Обычно в них длительное время не происходит изменения данных, и все реплики постепенно становятся непротиво речивыми. Т