В системе UNIX некоторые команды ожидают ввод только с клавиатуры (стандартный ввод) и большинство команд отображают свой вывод на экране терминала (стандартный вывод). Однако система UNIX позволяет вам перенаправлять ввод и вывод в файлы и программы, т.е. вы можете сказать shell:
- взять ввод из файла, а не с клавиатуры;
- послать вывод в файл, а не на терминал;
- использовать программу как исходные данные для другой программы.
Перенаправить ввод: знак <
Чтобы перенаправить ввод, укажите в командной строке после знака "меньше чем" (<) имя файла:
command < имя_файла<CR>
Перенаправить вывод: знак >
Чтобы перенаправить вывод, укажите в командной строке после знака "больше чем" (>) имя файла:
command > имя_файла<CR>
Примечание: если вы перенаправите вывод в уже существующий файл, то вывод вашей команды заменит содержимое существующего файла.
Перед тем, как перенаправить вывод команды в конкретный файл убедитесь, что этот файл не существует. shell не предупреждает, что выполняет перезапись существующего файла.
Чтобы убедиться, что файл с запланированным именем не существует, воспользуйтесь командой ls с аргументом "имя_файла". Если этот файл не существует, то ls выдаст сообщение, что файл не найден в текущем справочнике. Например, проверка существования файлов temp и junk даст следующий результат:
$ ls temp<CR>
temp
$ ls junk<CR>
junk: no such file or directiry
$
Это означает, что вы можете назвать свой файл junk, но не можете использовать в качестве имени temp, если не хотите потерять содержимое существующего файла.
Добавить вывод в существующий файл
Чтобы добавить вывод в существующий файл и не разрушить его, вы можете воспользоваться символом >>:
command >> имя_файла<CR>
В результате выполнения команды вывод будет добавлен в конец существующего файла. Если файл не существует, то он будет создан. Например, рассмотрим, как добавить вывод с помощью команды cat. Команда cat печатает содержимое файлов, имена которых являются ее аргументами, в стандартный вывод. Если нет аргументов, то она печатает стандартный ввод в стандартный вывод. Сначала выполните команду cat без перенаправления вывода. Затем содержимое файла trial2 добавляем после последней строки в файл trial1 при выполнении команды cat над файлом rtial2, перенаправив вывод в файл trial1:
$ cat trial1<CR>
This is the first line of trial1.
Hello.
This is the last line of trial1.
$
$ cat trial2<CR>
This is the beginning of trial2.
Hello.
This is the end of trial2.
$ cat trial2 >> trial1<CR>
$ cat trial1<CR>
This is the first line of trial1.
Hello.
This is the last line of trial1.
This is the beginning of trial2.
Hello.
This is the end of trial2.
$
Некоторые применения перенаправления вывода
Перенаправление вывода очень удобно в том случае, если вы не хотите, чтобы вывод появлялся на экране немедленно, или хотите сохранить его. Рассмотрим две команды: spell и sort.
Команда spell.
Команда spell сравнивает каждое слово в файле со своим словарем и печатает список всех потенциальных орфографических ошибок на экране. Если в словаре spell нет какого-либо слова (например, персональное имя), то она также выдает его как орфографическую ошибку. Если вы подадите на ввод spell большой файл, то его обработка займет много времени и список ошибок может быть очень большим. Команда spell распечатывает весь список ошибок сразу. Поэтому лучше всего перенаправить вывод spell в файл. Например, spell осуществляет поиск файла memo и помещает список орфографических ошибок в файл misspell:
$ spell memo > misspell<CR>
Команда sort.
Команда sort размещает строки указанного файла в алфавитном или цифровом порядке. Прежде чем перенаправить вывод команды в файл убедитесь, что имя этого файла не существует. Команда sort сначала очищает файл, который будет содержать вывод, затем выполняет сортировку и помещает вывод в пустой файл.
Комбинирование фонового режима и перенаправления вывода
Когда команда запущена в фоновом режиме, то вывод ее печатается на экране терминала. И если вы используете терминал в то же время для выполнения других задач, то вывод фоновой задачи будет прерывать вашу работу. Однако, если перенаправить вывод в файл, то вы сможете спокойно работать.
Предположим, что вы хотите найти все появления слова " test " в файле schedule. Запустите команду grep в фоновом режиме и перенаправьте вывод в файл testfile:
$ grep test schedule > testfile<CR>
Теперь вы можете использовать терминал для других работ и просмотреть файл testfile позднее.
Перенаправление вывода команде
Символ | называется каналом. Канал является мощным средством, которое позволяет вам брать вывод одной команды и использовать его в качестве ввода для другой команды без создания временных файлов. Таким образом построенная последовательность команд называется конвейером. Общий формат конвейера:
command1 | command2 | command3... <CR>
Вывод command1 используется как ввод для command2. Вывод command2 используется как ввод для command3.
Чтобы понять насколько эффективен конвейер, рассмотрим 2 способа, которые дают одинаковый результат:
- использование метода перенаправления ввода/вывода. Запустим одну команду и перенаправим ее вывод во временный файл. Затем запустим вторую команду, которая берет содержимое временного файла как ввод. И в конце удалим временный файл;
- использование метода конвейера. Например, предположим вы хотите послать сообщение happy birthday с помощью команды banner владельцу david. Выполним сначала по первому методу:
1. Введите команду banner и перенаправьте ее вывод во временный файл:
banner happy birhday > message.tmp
2. Введите команду mail и в качестве ввода воспользуйтесь файлом message. tmp:
mail david < message.tmp
3. Удалите временный файл:
rm message.tmp
Вторым методом это можно сделать быстрее:
banner happy birthday | mail david<CR>
Подстановка вывода в качестве аргумента
Вывод большинства команд может использоваться как аргумент в командной строке. Для этого команду заключите между знаками "слабое ударение" (`...`) и поместите ее в командной строке в том месте, где вывод будет трактоваться как аргумент.
Например, вы можете подставить вывод конвейера команд date и cut в качестве аргумента в команде banner:
$ banner `date | cut -c12-19`<CR>
Обратите внимание на результат: система печатает banner с текущим временем.
Программные фильтры
В UNIX существуют программы, получающие данные из стандартного потока ввода (stdin) и выводящие результаты свое работы в стандартный поток вывода (stdout). Общее название таких программ – программы-фильтры (или просто фильтры). Фильтр обычно (но не всегда) умеет также читать данные из файлов, имена которых были переданы ему в качестве аргументов, причем в этом случае чтение из файлов происходит именно в том порядке, в каком имена файлов были указаны в качестве параметров. Совместно с возможностью перенаправления стандартных потоков (stdin, stdout и stderr), использование программ-фильтров предоставляет пользователю большие возможности по обработке информации в командной строке или скриптах.
Фильтр cat
Программа cat является классическим представителем фильтров. То, что прочитано из stdin или из файлов, выводится в stdout. Несмотря на кажущуюся простоту такого действия, использование cat позволяет пользователю быстро и эффективно решать необходимые задачи. Например, если необходимо просмотреть содержимое файла, нет нужды запускать пейджер или, тем более, редактор:
$ cat /etc/fstab
# Device Mountpoint FStype Options Dump Pass#
/dev/ad0s1b none swap sw 0 0
/dev/ad0s1a / ufs rw 1 1
/dev/ad0s1e /tmp ufs rw 2 2
/dev/ad0s1f /usr ufs rw 2 2
/dev/ad0s1d /var ufs rw 2 2
/dev/acd0 /cdrom cd9660 ro,noauto 0 0
Для добавления строки в конец файла file1:
$ cat >> file1
new line
Опции, используемые с командой cat можно увидеть на странице man.
Показать последние строки файла — tail
Программа tail выводит на stdout последние строки файла (без опции n выводится 10 строк):
Последние 5 строк:
$ tail -n 5 /var/log/messages
Последние строки, начиная с 10-й:
$ tail -n +10 /var/log/messages
Динамически отслеживать запись в файл:
$ tail -F /var/log/messages
Показать первые строки файла — head
Программа head выводит на stdout первые строки файла (без опции n выводится 10 строк):
Первые 5 строк:
$ head -n 5 /var/log/messages
Выбор фрагментов строк — cut
Программа cut вырезать из входного потока или файла фрагменты строк, соответствующие определенным позициям символов в строке (опция с) или определенным полям (опция f). В последнем случае считается, что файл имеет табличную структуру (т. е. разбит на колонки) и программе требуется указать разделитель полей с помощью опции d (разделитем по умолчанию является символ табуляции, в этом случае опция d не нужна).
Примеры:
$ cut -d: -f1 /etc/passwd
$ cut -d: -f1,7 /etc/passwd
$ cut -d: -f13 /etc/passwd
$ cut -c1-5 /etc/passwd
Сортировка файлов — sort
Программа sort позволяет сортировать данные в алфавитном или числовом порядке (опция -n). Подробно с опциями sort можно ознакомится на странице справочного руководства.
Пример сортировки пользователей в системе по алфавиту:
$ grep -v '^#' /etc/passwd | sort
Пример сортировки пользователей в системе по значению UID:
$ grep -v '^#' /etc/passwd | sort t: -k3 -n
Конвейеры команд
Конвейер — некоторое множество процессов, для которых выполнено следующее перенаправление ввода-вывода: то, что выводит на поток стандартного вывода предыдущий процесс, попадает в поток стандартного ввода следующего процесса. Запуск конвейера реализован с помощью системного вызова pipe ().
Оператор конвейера позволяет соединить две UNIX-команды для выполнения нужных программ непосредственно в командной строке. Однако конвейер похож на черный ящик, скрывающий процесс передачи данных от одной утилиты к другой. Программа PipeViewer позволяет взглянуть на поток данных, проходящих через конвейер.
С помощью конвейера команд можно конструировать импровизированные программы непосредственно в командной строке. Конвейер собирает команды в цепочки, в которых стандартный вывод одной команды становится стандартным вводом для следующей команды.
Но у конвейера есть один серьезный недостаток: он похож на черный ящик. Когда вы соединяете две команды, единственным признаком хода выполнения процесса является вывод, генерируемый последней в последовательности командой. Можно вставить в последовательность команду tee, а также наблюдать за ростом выходного файла с помощью tail, но эти решения отлично работают только при однократном применении в команде, в противном случае стандартные потоки вывода (stdout) и стандартные потоки ошибок (stderr) различных фаз перемешиваются. К тому же оба эти решения являются грубыми индикаторами, которые, вероятно, не покажут, сколько в действительности вычислений требуется на каждом шаге.
Конечно, можно разбить сложную последовательность команд на множество отдельных шагов, каждый из которых будет генерировать свой собственный выходной файл. В самом деле, если вы хотите проверять результат работы на каждом интервале, декомпозиция является идеальным решением. Создайте сценарий, в котором на каждом шаге генерируйте отдельный файл с данными и используйте его в качестве входных данных для следующего шага и т.д. В результате вы получите файл с итоговыми результатами. Однако такая практика плохо подходит к импровизационной природе командной строки.
То, что нам нужно – это индикатор прогресса выполнения задачи, который можно встраивать в командную строку для измерения скорости передачи данных. В идеале хорошо было бы использовать этот индикатор повторно, чтобы сравнивать производительность на каждом шаге. Ну и, поскольку нет предела совершенству, хорошо бы, чтобы это был инструмент с открытым кодом, который бы работал с различными вариантами UNIX, такими как Linux и Mac OS X.
Всем нашим пожеланиям удовлетворяет программа Pipe Viewer (pv), написанная системным администратором Эндрю Вудом и улучшаемая на протяжении последних четырех лет многими другими разработчиками. Она позволяет заглянуть внутрь "трубопровода" командной строки. «Можно вставлять в конвейер между двумя процессами для получения визуальной индикации того, как быстро передаются между ними данные, как много времени прошло и насколько близко завершение работы". Заметим, что для измерения относительной производительности можно использовать pv несколько раз в одной последовательности команд.
Конвейеры UNIX: трубопровод для процессов
На рисунке 1 показаны этапы создания конвейера, соединяющего два независимых процесса.
Рисунок 1. Создание конвейера, соединяющего два процесса
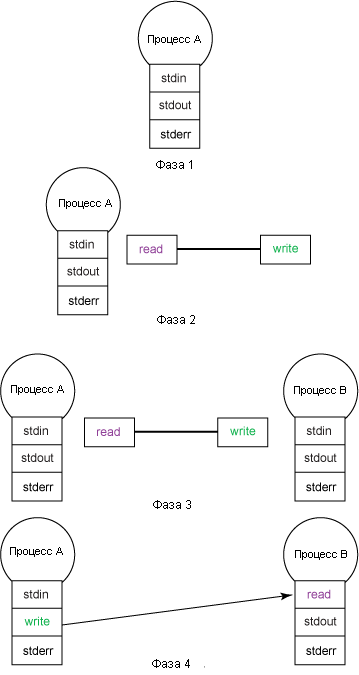
В начале, на фазе 1, процесс-инициатор читает данные из stdin, выводит результат в stdout, а ошибки в stderr. stdin,stdout и stderr являются файловыми дескрипторами. Каждая операция, выполняемая с файловым дескриптором, например open, read, write, rewind, truncate или close, изменяет состояние файла.
Затем в фазе 2 процесс-инициатор создает конвейер. Конвейер состоит из очереди и двух файловых дескрипторов. Один нужен, чтобы помещать данные в очередь, другой - чтобы извлекать их из очереди. Конвейер представляет собой структуру данных типа FIFO (первым пришел - первым вышел).
Сам по себе конвейер мало полезен; он предназначен для того, чтобы соединять процесс-поставщик и процесс-потребитель (данных). Поэтому процесс-инициатор в фазе 3 ответвляет или создает себе процесс, с которым будет работать в паре.
В фазе 4 (предполагая, что новый процесс является потребителем данных), исходный процесс заменят свой stdout дескриптором, помещающим данные в конвейер, а stdin только что созданного процесса - дескриптором, считывающим данные из конвейера. После этих манипуляций каждая операция write исходного процесса (поставщика) будет помещена в очередь и впоследствии прочитана новым процессом (потребителем).
Фазы 1-4 иллюстрируют то, как оболочка соединяет с помощью конвейера (|) две утилиты одну с другой в командной строке. Заметим только, что оболочка создает для каждой утилиты новый процесс, а сама занимается управлением ходом работы.
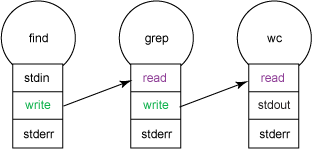
Например, на рисунке 2 показано, как можно с помощью конвейеров соединить команды find, grep и wc, чтобы найти и подсчитать количество файлов, имена которых начинаются с буквы a в нижнем регистре. Оболочка остается независимой; вывод find служит входным потоком для grep, результат работы которого в свою очередь направляется команде wc. wc обрабатывает полученные от grep данные и выводит результат своей работы в stdout. Обычно оболочка выводит stdout на терминал, но его также можно перенаправить в файл.
Рисунок 2. Соединяем команды с помощью конвейеров
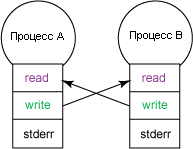
Если вы хотите изучить работу двух UNIX-процессов, создайте два конвейера и переопределите файловые дескрипторы процессов так, чтобы они являлись друг для друга и поставщиком и потребителем данных. На рисунке 3 показан обмен данными между процессами, в котором для обоих процессов переопределяются потоки stdin и stdout.
Рисунок 3. Исследуем два UNIX-процесса
На примере конвейеров команд хорошо виден так называемый путь UNIX (UNIX way). В UNIX редко встречаются универсальные программы, которые умеют делать все. Существует большое количество небольших программ. Каждая программа хорошо делает определённое действие: хорошо сортирует файлы, хорошо фильтрует данные и т.д. Все программы умеют работать со стандартными вводом и выводами. Объединяя эти программы в конвейер команд, в результате мы получаем обработку данных без написания новой программы. Таким образом, по-разному комбинируя программы в конвейере, можно получить различные результаты.
Заключение
UNIX завоевала такую высокую степень популярности, на которую, возможно, даже не рассчитывали ее разработчики. Одной из главных причин успеха являлся способ распространения системы. Корпорация AT&T, ограниченная законами в своих возможностях, продавала лицензии и исходные коды системы по достаточно низкой цене, поэтому UNIX стала популярной среди многих пользователей по всему миру. Так как в комплект поставки входили и исходные коды, пользователи имели возможность экспериментировать с ними, улучшать их, а также обмениваться друг с другом созданными изменениями. Корпорация AT&T встраивала многие из новшеств в следующие версии системы.
Развитие системы UNIX оказалось очень открытым процессом. Добавления поступали из учебных заведений, коммерческих организаций и от хакеров-энтузиастов из разных континентов и стран мира. Даже после коммерциализации UNIX многие производители ОС поддержали концепцию открытых систем и сделали свои разработки доступными для других, создавая спецификации открытых систем, такие как NFS.
Оригинальная версия UNIX имела хороший дизайн, который являлся базисом последующего успеха более поздних реализаций и вариантов системы. Одну из сильнейших сторон системы можно охарактеризовать выражением «красота в краткости».Ядро небольшого размера имело минимальный набор основных служб. Утилиты небольшого размера производили малый объем манипуляций с данными. Механизм конвейера совместно с программируемой оболочкой позволял пользователям комбинировать эти утилиты различными способами, создавая мощные, производительные инструменты.
Еще одной особенностью системы UNIX стал простой унифицированный интерфейс с устройствами ввода-вывода. Представляя все устройства как файлы, система позволяет пользователям применять один и тот же набор команд и системных вызовов для доступа и работы с различными устройствами, равно как и для работы с файлами. Разработчики могут создавать программы, производящие ввод-вывод, не заботясь, с чем именно производится обмен, с файлом, терминалом пользователя, принтером или другим устройством. Таким образом, используемый совместно с перенаправлением данных интерфейс ввода-вывода системы UNIX — простой и одновременно мощный.
Причиной успеха и распространения UNIX стала ее высокая степень переносимости. Большая часть ядра системы написана на языке С. Это позволило относительно легко адаптировать UNIX к новым аппаратным платформам. Первая реализация системы появилась на популярной тогда машине PDP-11 и затем была перенесена на VAX-11, имевшую не меньшую популярность. Многие производители «железа» после создания новых компьютеров имеют возможность просто перенести на них уже имеющуюся систему UNIX вместо того, чтобы создавать для своих разработок операционную систему заново.