При построении нейросетевых моделей очень важным являются вопросы оценки их качества. Для качественной модели нужное минимальное значение ошибки модели.
Как мера ошибки в моделях регрессии может рассматриваться стандартная среднеквадратичная ошибка, коэффициент множественной корреляции, судьба естественной дисперсии прогнозируемого признака, который не достал объяснения в рамках модели.
В моделях классификации как мера ошибки может быть избрана судьба случаев правильно классифицированных моделью.
В связи с высокими потенциальными возможностями обучения нейросетевых моделей важную роль при оценке адекватности модели играет вопрос «переобучение» модели. В связи с этим рассмотрим процесс построения модели подробнее.
Итак, нужно, чтобы на основании конечного набора параметров X, названных учебным множеством, была построена модель Mod некоторого объекта Obj. Процесс получения Mod из имеющихся отрывистых экспериментальных сведений о системе Obj может рассматриваться, как обучение модели поведению Obj согласно заданному критерию, настолько близко, насколько это возможно. Алгоритмически, обучение означает подстраивание внутренних параметров модели (весов синаптических связей в случае нейронной сети) с целью минимизации ошибки модели, которая описывает некоторым образом отклонения поведения модели от системы - E = |Obj - Mod |.
Прямое измерение указанной ошибки модели на практике невозможно, поскольку функция Obj при произвольных значениях аргумента неизвестная. Однако возможное получение ее оценки:
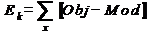 ,
,
где суммирование проводится по учебному множеству X. При использовании базы данных наблюдений за системой, для обучения может отводиться некоторая ее часть, названная в этом случае учебной выборкой. Для учебных примеров X отклики системы Obj известные. Таким образом, EX - ошибка обучения для модели.
В приложениях пользователя обычно интересуют предвиденные свойства модели. При этом главным является вопрос, каким будет отклик системы на новое влияние, пример которого отсутствует в базе данных наблюдений - N. Неизвестная ошибка, которая допускается моделью Mod на данных, которые не использовались при обучении, называется ошибкой обобщения модели EN.
Основной целью при построении информационной модели является уменьшение именно ошибки обобщения, поскольку минимальная ошибка обучения гарантирует адекватность модели лишь в заранее избранных точках (а в них значение отклика системы известно и без всякой модели). Проводя аналогии с обучением в биологии, можно сказать, что минимальная ошибка обучения отвечает прямому запоминанию учебной информации, а минимальная ошибка обобщения - формированию понятий и привычек, которые разрешают распространить полученный из обучения опыт на новые условия. Последнее значительно более ценное при проектировании нейросетевых систем, так как для непосредственного запоминания информации лучше приспособлены другие, не нейронные устройства компьютерной памяти.
Важно отметить, что минимальная ошибка обучения не гарантирует минимальную ошибку обобщения. Классическим примером является построение модели функции (аппроксимация функции) по нескольким заданным точкам полиномом высокого порядка. Значения полинома (модели) при довольно высокой его степени являются точными в учебных точках, т.е. ошибка обучения равняется нулю. Однако значение в промежуточных точках могут значительно отличаться от аппроксимирующей функции, ведь ошибка обобщения такой модели может быть неприемлемо большой.
Поскольку истинное значение ошибки обобщения не доступно, на практике используется ее оценка. Для ее получения анализируется часть примеров из имеющейся базы данных, для которых известны отклики системы, но которые не использовались при обучении. Эта выборка примеров называется тестовой выборкой. Ошибка обобщения оценивается, как отклонение модели на множестве примеров из тестовой выборки.
Оценка ошибки обобщения является принципиальным моментом при построении модели. На первый взгляд может показаться, что сознательный отказ от использования части примеров при обучении может только ухудшить итоговую модель. Однако без этапа тестирования единой оценкой качества модели будет лишь ошибка обучения, которая, как уже отмечалось, мало связана с предвиденными способностями модели. В профессиональных исследованиях могут использоваться несколько независимых тестовых выборок, этапы обучения и тестирования повторяются многократно с вариацией начального распределения весов нейросети, ее топологии и параметров обучения. Окончательный выбор "наилучшей" нейросети делается с учетом имеющегося объема и качества данных, специфики задачи, с целью минимизации риска большой ошибки обобщения при эксплуатации модели.
Построение нейронной сети (после выбора входных переменных) состоит из следующих шагов:
- Выбор начальной конфигурации сети.
Проведение экспериментов с разными конфигурациями сетей. Для каждой конфигурации проводиться несколько экспериментов, чтобы не получить ошибочный результат из-за того, что процесс обучения попал в локальный минимум. Если в очередном эксперименте наблюдается недообучение (сеть не выдает результат приемлемого качества), необходимо прибавить дополнительные нейроны в промежуточный пласт. Если это не помогает, попробовать прибавить новый промежуточный пласт. Если имеет место переобучение (контрольная ошибка постоянно возрастает), необходимо удалить несколько скрытых элементов.
- Отбор данных
Для получения качественных результатов учебное, контрольное и тестовое множества должны быть репрезентативными (представительными) с точки зрения сути задачи (больше того, эти множества должны быть репрезентативными каждая отдельно). Если учебные данные не репрезентативны, то модель, как минимум, будет не очень красивой, а в худшем случае - непригодной.
- Обучение сети
Обучение сети лучше рассмотреть на примере многослойного персептрона. Уровнем активации элемента называется взвешенная сумма его входов с добавленным к ней предельным значением. Таким образом, уровень активации представляет собой простую линейную функцию входов. Эта активация потом превратится с помощью сигмавидной (что имеет S-Образную форму) кривой.
Комбинация линейной функции нескольких сменных и скалярной сигмавидной функции приводит к характерному профилю "сигмавидного склона", который выдает элемент первого промежуточного пласта сети. При изменении весов и порогов изменяется и поверхность отклика. При этом может изменяться как ориентация всей поверхности, так и крутизна склона. Большим значением весов отвечает более крутой склон. Если увеличить все веса в два раза, то ориентация не изменится, а наклон будет более крутым.
В многослойной сети подобные функции отклика комбинируются одна из одной с помощью построения их линейных комбинаций и применения нелинейных функций активации. Перед началом обучения сети весам и порогам случайным образом присваиваются небольшие по величине начальные значения. Тем самым отклики отдельных элементов сети имеют малый наклон и ориентированы хаотически - фактически они не связаны друг с другом. По мере того, как происходит обучение, поверхности отклика элементов сети поворачиваются и смещаются в нужное положение, а значение весов увеличиваются, поскольку они должны моделировать отдельные участки целевой поверхности отклика.
В задачах классификации исходный элемент должен выдавать сильный сигнал в случае, если данное наблюдение принадлежит к классу, который нас интересует, и слабый - в противоположном случае. Иначе говоря, этот элемент должен стремиться смоделировать функцию, равную единице в той области пространства объектов, где располагаются объекты из нужного класса, и равную нулю вне этой области. Такая конструкция известная как дискриминантная функция в задачах распознавания. "Идеальная" дискриминантная функция должна иметь плоскую структуру, так чтобы точки соответствующей поверхности располагались или на нулевом уровне.
Если сеть не содержит скрытых элементов, то на выходе она может моделировать только одинарный "сигмавидный склон": точки, которые находятся по одну его сторону, располагаются низко, по другую - высоко. При этом всегда будет существовать область между ними (на склоне), где высота принимает промежуточные значения, но по мере увеличения веса эта область будет суживаться.
Теоретически, для моделирования любой задачи довольно многослойного персептрона с двумя промежуточными пластами (этот результат известный как теорема Колмогорова). При этом может оказаться и так, что для решения некоторой конкретной задачи более простой и удобной будет сеть с еще большим числом пластов. Однако, для решения большинства практических задач достаточно всего одного промежуточного пласта, два пласта применяются как резерв в особых случаях, а сети с тремя пластами практически не применяются.