Часть 1. Сортировка слиянием.
Сортировка слиянием – алгоритм сортировки, который упорядочивает списки в определённом порядке. Эта сортировка — хороший пример использования принципа «разделяй и властвуй». Сначала задача разбивается на несколько подзадач меньшего размера. Затем эти задачи решаются с помощью рекурсивного вызова или непосредственно, если их размер достаточно мал. Наконец, их решения комбинируются, и получается решение исходной задачи.
Алгоритм:
1. Определяем кол-во элементов в массиве.
2. Определяем кол-во элементов в массиве, которое необходимо слить, путем постоянного деления кол-ва элементов на 2. Сначала мы сортируем по 2 элемента, потом по 4 и так далее пока кол-во сортируемых элементов не будет равно 1.
3. Сортируем все оставшиеся элементы (если таковые имеются) с уже отсортированной частью.
Схема алгоритма:
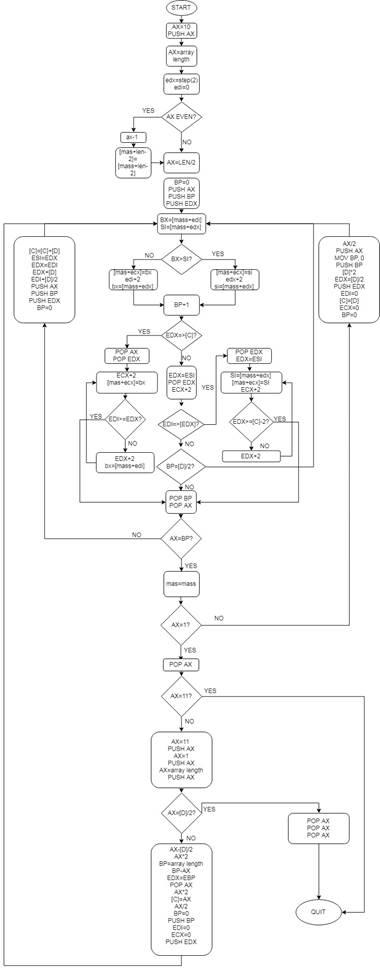
Пример работы программы:
| № | mass |
Код программы:
1. mov ax, 10
2. push ax
3. mov ecx, 0
4. mov bp, 0
5. mov edi,0
6. mov edx,2; длина шага
7. mov ax, len
8. sub ax, 8
9. rcr ax, 2
10. test ax, 1
11. jp B
12. A: rcl ax, 1
13. mov si, [mass+eax-2]
14. mov [mas+eax-2], si
15. rcr ax, 1
16. sub ax, 1
17. B: rcr ax, 1; кол-во элементов, которые необходимо отсортировать
18. push ax
19. push bp
20. push edx
21. jmp C
22. B1: mov edi, edx; после сортировки каждого элемента
23. mov edx, edi
24. add edx, [d]
25. push edx
26. mov edx, [d]
27. rcr edx, 1
28. add edi, edx
29. add ecx,2
30. pop edx
31. push ax
32. push bp
33. push edx
34. mov ax, [d]
35. rcr ax, 1
36. mov bp, 0
37. jmp C
38. B2: rcr ax, 1; кол-во элементов, которые необходимо отсортировать
39. push ax
40. mov bp, 0
41. mov [c],bp
42. push bp
43. mov bp, [d]
44. imul bp, 2
45. mov [d],bp
46. mov bp, 0
47. mov edx, [d]
48. rcr edx, 1
49. mov edi, 0
50. push edx
51. mov ecx, 0
52. mov bp, [d]
53. add [c], bp
54. mov ax, [d]
55. rcr ax, 1
56. mov bp, 0
57. C: mov bx, [mass+edi]
58. mov si, [mass+edx]
59. C2: cmp bx, si
60. jg C3;bx больше si?
61. jmp C4
62. C3: mov [mas+ecx], si
63. add edx, 2
64. mov si, [mass+edx]
65. jmp C5
66. C4: mov [mas+ecx], bx
67. add edi, 2
68. mov bx, [mass+edi]
69. C5: push ax
70. push edx
71. mov eax, [c]
72. cmp edx,eax
73. jae C6
74. pop edx
75. pop ax
76. add bp,1
77. add ecx, 2
78. cmp ax, bp
79. je D
80. mov esi, edx
81. pop edx
82. push edx
83. cmp edi,edx
84. jae C9
85. mov edx, esi
86. mov si, [mass+edx]
87. jmp C2
88. C6: pop edx
89. pop ax
90. pop edx
91. sub edx, 2
92. jmp C8
93. C7: pop ecx
94. C8: add ecx, 2
95. mov [mas+ecx], bx
96. cmp edi,edx
97. jae C12
98. add edi, 2
99. mov bx, [mass+edi]
100. push ecx
101. loop C7
102.C9: pop edx
103. mov edx, esi
104. jmp C11
105.C10:inc ecx
106.C11:mov si, [mass+edx]
107. mov [mas+ecx], si
108. add ecx, 2
109. mov ebx, [c]
110. sub ebx, 2
111. cmp edx,ebx
112. jae C13
113. add edx, 2
114. loop C10
115.C12:add edx, 2
116. jmp D
117.C13:sub edx, 2
118.sub ecx, 2
119.D: mov ax, [d]
120. add [c], ax
121. pop bp
122. pop ax
123. add bp, 1
124. cmp ax, bp
125. je E
126. jmp B1
127.E: mov ecx, 0
128. mov bx, len
129. sub bx, 8
130. rcr bx, 2
131. mov bp, 0
132.E1: mov si, [mas+ecx]
133. mov [mass+ecx], si
134. add bp,1
135. cmp bx, bp
136. je F
137. add ecx, 2
138. jmp E1
139.F: cmp ax, 1
140. je CHECK1
141. jmp B2
142.CHECK1:
143. pop ax
144. cmp ax, 11
145. je QUIT
146.CHECK:
147. mov ax, 11
148. push ax
149. mov ax, 1
150. push ax
151. mov ax, len
152. sub ax, 8
153. rcr ax, 2
154. push ax
155. mov di, [d]
156. rcr di, 1
157. cmp ax, di
158. je CHECKOUT
159. sub ax, di
160. rcl eax, 1
161. mov ebp, len
162. sub ebp, 8
163. rcr ebp, 1
164. sub ebp, eax
165. mov edx, ebp
166. pop ax
167. rcl ax, 1
168. mov [c],ax
169. rcr ax, 1
170. mov bp, 0
171. push bp
172. mov edi,0
173. mov ecx,0
174. push edx
175. jmp C
176.CHECKOUT:
177. pop ax
178. pop ax
179. pop ax
180.QUIT: ret
181. section.data
182.mass dw 0003, 0001, 0033,
183.mas dw 0000, 0000, 0000,
184.c dd 2
185.d dd 4
186.len equ $-mass
Трассировочная таблица:
| № | mass | mas | C | D | EAX | EBX | EDX | ECX | EDI | EBP | ESI |
| ? | ? | ||||||||||
| № | mass | mas | C | D | EAX | EBX | EDX | ECX | EDI | EBP | ESI |
Анализ сложности алгоритма:
Худшее время: O(n log n)
Лучшее время: O(n log n)
Среднее время: O(n log n)
Отчёт:
Сложность алгоритма будет одинаковая в любом случае, поэтому на «почти отсортированных» массивах программа работает столь же долго, как и на хаотичных. Так же для сортировки методом слияния требуется дополнительная память по размеру основного массива.
Часть 2. Двоичные деревья поиска.
Структуры данных:
Двоичное дерево поиска записывается в один массив. Будет использовать двойные слова. В первом байте будет храниться номер предка, во втором значение узла дерева, в третьем левый потомок и в четвертом соответственно правый. С учетом обратного порядка байтов:
0x00(правый потомок)00(левый потомок)00(значение узла)00(предок).
Программа работает следующим образом:
1. Вводим значение в консоль.

2. Выполняется поиск значения. В случае успешного нахождения выводит: “Value founded”, в противном случае добавляет данное значение к нужному узлу и выводит: “Value added”.
3. Выполняется обход дерева в порядке возрастания элементов и выводится упорядоченный массив.

Схемы алгоритмов:









 |
Код программы:
GET_DEC 2, esi
mov ebx, 1
A1: mov al, [mass+ebx]
cmp eax, esi
je B2
cmp eax, esi
jb A
mov al, [mass+ebx+1]
jmp B
A: mov al, [mass+ebx+2]
B: cmp al, 0
je C
mov cl, al
call go
jmp A1
B2 PRINT_STRING "Value founded. "
jmp SORT
C: mov ebp, len
rcr ebp, 2
mov al, [mass+ebx]
cmp eax, esi
jb C2
mov [mass+ebx+1], bp
jmp C3
C2: mov [mass+ebx+2], bp
C3: imul ebp, 4
mov ebx, 0
mov [mass+ebp+2], ebx
mov [mass+ebp], ebx
mov [mass+ebp+1], si
mov [mass+ebp], cl
PRINT_STRING "Value added. "
SORT:
mov edx, 0
mov ebx, 1
PRINT_STRING "Inferential massive: "
call checkL
call concl
call checkR
xor eax, eax
ret
checkL:
mov al, [mass+ebx+1]
cmp al, 0
je A0
call go
call checkL
jmp B0
A0: mov al, [mass+ebx]
cmp edx, eax
jae B4
call concl
call checkR
jmp B0
B4: call back
jmp A0
B0: ret
go: mov ebx, 1
imul eax, 4
add ebx, eax
ret
concl:
mov al, [mass+ebx];вывод значения
mov edx, eax
PRINT_DEC 2, al
PRINT_STRING ", "
ret
checkR:
mov al, [mass+ebx+2]
cmp al, 0
je C0
call go
call checkL
jmp D0
C0: call back
cmp al, 0
je D0
mov al, [mass+ebx]
cmp edx, eax
jae D1
call concl
call checkR
jmp D0
D1: call back
D0: ret
back:
mov al, [mass+ebx-1]
call go
ret
section.data
mass dd 0x02010400, 0x00000200, 0x00000600,
len equ $-mass
Трассировочная таблица для дерева( на вход посылаем значение 4):

| № | EAX | EDX | EBX | EBP | ESI | ВЫВОД |
| Value founded. | ||||||
| Value founded. Inferential massive: | ||||||
| Value founded. Inferential massive: 2, | ||||||
| Value founded. Inferential massive: 2,4 | ||||||
| Value founded. Inferential massive: 2,4,6 | ||||||
Отчёт:
Основным преимуществом двоичного дерева поиска перед другими структурами данных является возможная высокая эффективность реализации основанных на нём алгоритмов поиска и сортировки. Если же говорить о времени выполнения операций, то оно зависит от формы дерева. Если оно похоже на список - имеем O(n), как в списке, если на дерево - то O(log n). Можно доказать, что при последовательном включении в дерево случайных данных получается именно среднее время выполнения операций(O(log n)). Однако, если входные данные, например, образуют возрастающую последовательность, то получается список и все преимущество дерева потеряно.